Xline 源码解读(四)—— CURP 状态机引擎
在上一篇源码解读的文章(Xline 源码解读(三) —— CURP Server 的实现)中,我们简单阐述了Xline 的 Curp Server 是如何实现的。接下来,就让我们话接上回,继续深入地来了解 Curp Server 中的一些核心的数据结构,特别是 conflict_checked_channel 和 command worker,它们相互协作,共同推动着 CURP Server 内部状态机状态转换。
01、为什么我们需要冲突检测队列?
冲突检测队列本质是一个多生产者多消费者的 channel,其核心职责是维护动态变化的冲突关系,保证在同一时间内,所有的 receiver 都不会接收到冲突的命令。receiver 接收到的命令的顺序(后面称之为冲突序),满足以下两点:
- 如果 cmd A 与 cmd B 存在冲突,并且 A 先于 B 被压入队列当中,则 A 会先从队列中弹出。而 B 只有当 A 执行完毕后,才能从队列中弹出。
- 如果 cmd A 与 cmd B 不存在冲突,且 A 先于 B 被压入队列,则按照 FIFO 顺序,即 A 会先从队列中弹出,B 后弹出。
单看文字的话可能有些抽象,不过没有关系,让我们来看一个简单的例子:假设我们现在有 A、B、C 三个 command,进入冲突检测队列的顺序依次为 A,B,C。其中 A 与 B 冲突,而 C 与 A 和 B 均不产生冲突,则冲突检测队列的初始状态如下:

当 A、B、C 都进入到队列当中后,3 个不同的 cmd_worker 分别从 channel 获取 command,由于 cmd_worker_1 会先接收到 A。B 则会因为与 A 产生冲突而被缓存在队列当中。C 由于没有任何命令与其冲突,因此可以被 cmd_worker_2 接收。而 B 只有在 A 被执行并且 drop 之后,才会从队列当中弹出。如下图所示:
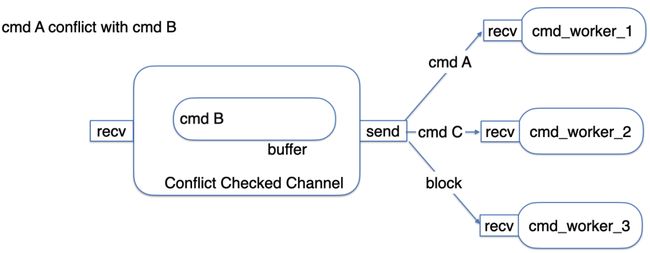
可能有些读者会产生疑问:既然 spec_pool 的职责就是判断 fast path 中是否存在冲突,对应了 CURP paper 中的 witness,那为什么还要引入一个冲突检测队列呢?主要原因有二:
- 任何命令,不管走的是 fast path 还是 slow path, 最终都必须要在 leader 上得到执行。因此,leader 必须在这些混合的命令中,找到一个合理的执行顺序,来保证命令的执行不会打破 CURP 对命令执行顺序的假设。而 spec_pool 中只保存了可以在 fast path 被执行的命令,并不涉及 slow path 中的命令
- 在达成共识的过程当中,我们必须先判断命令是否存在于 spec_pool 当中。这是一个同步的操作,如果将复杂冲突序的计算工作放到 spec_pool 当中,那会很容易形成 bottleneck。因此,我们将判断是否有冲突和计算出冲突序这两个职责进行拆分,将前者放到同步的 spec_pool 当中,而将后者放到异步的冲突检测队列当中执行。
02、冲突检测队列是如何工作的?
要理解冲突检测队列的工作原理,离不开下面两个问题的探讨:
- 我们应当如何对冲突关系进行建模?
- 面对会动态变化的冲突关系,我们如何快速地找到所有没有冲突的命令?
针对第一个问题,我们可以将所有的命令都看成是一张有向无环图中的顶点,而将冲突关系视为图中顶点之间的有向边。假设命令 A 和命令 B 之间存在冲突(命令的抵达顺序为先 A 后 B),我们便可将冲突关系看成是 A 和 B 之间的一条弧
一旦我们将冲突关系定义为一个有向无环的非连通图中的一条边,那么执行某个命令时所需要计算的冲突顺序问题,就转换成了一个求有向无环图中,该命令所在的连通分量的拓扑排序问题。针对每个命令,successors(也就是后继) 保存了哪些 cmd 与当前 cmd 冲突,successors 的长度就是该 顶点的出度。而 predecessor_cnt (前驱数)则代表了这个 cmd 与之前的多少个 cmd 存在冲突,也就是该顶点元素的入度。
同样回到我们前面所提到的 A、B、C 的例子当中,当我们使用 DAG 来描述命令的冲突关系,其情况如下图所示。

当 cmd_worker 从 channel 当中接收命令时,channel 只需要遍历这个有向无环图中的每一个连通分量,并找到第一个入度为 0 的顶点即可。只有当 command 执行完毕后,channel 才会更新 B 的 predecessor_cnt,以解决 A 与 B 之间的冲突关系。
03、状态机引擎的架构
正如我们在文章开头所说的那样,冲突检测队列和 command worker 共同组成了 Curp Server 的状态机引擎。冲突检测队列向 command worker 提供无冲突的命令,而 command worker 则负责执行这些命令,并根据结果推动更新冲突检测队列当中的冲突关系。
从结构上来看,Curp Server 状态机引擎是由三对 channel 和一个 filter 构成,其中这三对 channel 分别为:(send_tx,filter_rx)、(filter_tx, recv_rx) 以及 (done_tx, done_rx)具体的结构可以参考下图。

其数据流方向为:send_tx -> filter_rx -> filter -> filter_tx -> recv_rx -> done_tx -> done_rx
其中,send_tx 为 RawCurp 对象所拥有,负责在 propose(对应了 curp 的 fast path)、以及应用日志 apply(对应了 curp 的 slow path) 时向冲突检测队列投递对应的 CEEvent。冲突检测队列则会在计算出冲突顺序后,将 CEEvent 转换成为 Task 并通过 (filter_tx, recv_rx) 投递到 command worker 当中执行。command worker 在执行完Task 后将结果通过 (done_tx, done_rx) 反馈到冲突检测队列中,并更新队列中依赖图中的顶点信息。
04、状态是如何转换的
要理解一个状态机的工作原理,我们需要理解以下两个问题:
- 状态机提供了哪些事件以及哪些状态
- 哪些事件会导致状态发生转移 让我们先来看看 Curp Server 的状态机引擎都提供了哪些事件。
/// Event for command executor
enum CEEvent {
/// The cmd is ready for speculative execution
SpecExeReady(Arc>),
/// The cmd is ready for after sync
ASReady(Arc>),
/// omit some code...
}
/// CE task
struct Task {
/// Corresponding vertex id
vid: u64,
/// Task type
inner: TaskType,
}
/// Task Type
enum TaskType {
/// Execute a cmd
SpecExe(Arc>, Option),
/// After sync a cmd
AS(Arc>, C::PR),
/// omit some code...
}
从前面的描述中我们可以看出,Curp Server 的状态机引擎主要的事件可以分为两类,一类是 CEEvent,它描述了命令本身的信息,包括了命令的来源,其中 SpecExeReady 表明这个命令是来自于 fast path, 而 ASReadey 则表明这个命令来自于 slow path。而另一类则是 Task,它描述命令在依赖图中的顶点 id,以及当前命令所需要执行的操作。
Curp Server 的状态机引擎也定义了如下的状态:
/// Execute state of a cmd
enum ExeState {
/// Is ready to execute
ExecuteReady,
/// Executing
Executing,
/// Has been executed, and the result
Executed(bool),
}
/// After sync state of a cmd
enum AsState {
/// Not Synced yet
NotSynced(Option),
/// Is ready to do after sync
AfterSyncReady(Option),
/// Is doing after syncing
AfterSyncing,
/// Has been after synced
AfterSynced,
}
其中,ExeState 代表命令的执行状态,而 AsState 则代表了命令是否执行完了 after_sync 阶段。Curp Server 通过组合 ExeState 和 AsState 两种状态来代表命令执行过程中的不同状态。不同的状态所代表的语义如下:
(ExecuteReady, NotSynced(None): 代表命令已经可以准备执行execute阶段,并且该命令属于 fast path,无需等待after_sync结束即可向用户返回结果。此状态也是 fast path 路径下,状态机引擎的初始状态。(ExecuteReady,AfterSyncRead(None)): 代表命令已经可以准备执行execute阶段,并且该命令属于 slow path,需要等到after_sync结束才能向用户返回结果。此状态也是 slow path 路径下,状态机引擎的初始状态。(Executeing,NotSynced(Some(C::PR))): 代表命令执行pre_execute成功,并拿到了pre_execute的执行结果Some(C::PR), 同时命令也进入了执行状态。(Executeing,NotSynced(None)):代表命令pre_execute执行失败(Executed(true),NotSynced(Some(C::PR))): 代表命令执行成功(Executed(false),NotSynced(None)): 代表 fast path 中的命令执行失败(Executed(true),AfterSyncRead(LogIndex, Some(C::PR))): 代表命令执行完毕,开始准备执行after_sync(Executed(true),AfterSyncing):代表命令执行完毕,正在执行after_sync阶段(Executed(true),AfterSynced): 代表命令执行成功,且after_sync也执行成功(Executeing,AfterSyncReady(Some(C::PR))): 代表命令正在执行,并准备执行after_sync阶段(Executeing,AfterSyncReady(None)):代表命令的pre_execute阶段失败(Executed(false),AfterSyncReady(None)): 代表 slow path 中的命令执行失败。
各种状态之间的转换关系如下:
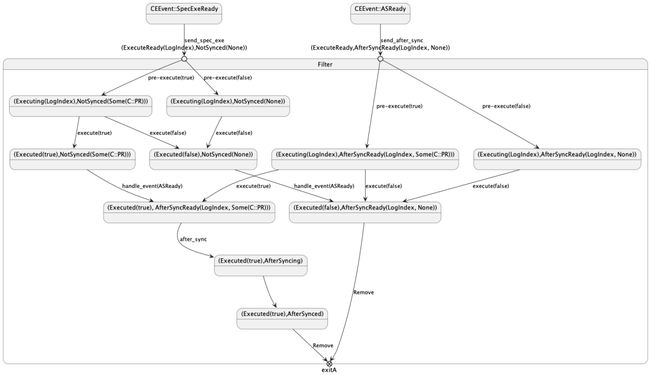
05、Summary
在 Xline 中,不论是来自于 fast path 的命令,还是来自 slow path 的命令,这些命令最终都会在 leader 节点上得到执行。在这个过程当中,仅凭 spec_pool 来判断命令是否冲突是显然不够的。因为 spec_pool 只能判断新的命令是否与正在 execute 但还没有 after_sync 的命令冲突,但它不能起到动态维护命令冲突关系的作用。为了解决冲突关系的动态维护,我们引入了冲突检测队列,并通过冲突检测队列和 command worker 共同构造 Curp Server 的状态机引擎。通过 command worker 的执行,使得来自不同路径(fast path 和 slow path)的命令能够根据自身的状态,进行状态转移,并向用户返回相应的结果。
06、往期回顾
Xline 源码解读(一) —— 初识 CURP 协议
Xline 源码解读 (二)—— Lease 的机制与实现
Xline 源码解读(三) —— CURP Server 的实现

Xline是一个用于元数据管理的分布式KV存储。Xline项目以Rust语言写就,欢迎大家参与我们的开源项目!
GitHub链接:
https://github.com/xline-kv/Xline
Xline官网:www.xline.cloud
Xline Discord:
https://discord.gg/XyFXGpSfvb