[数据结构]--图(图的遍历,最小生成树,最短路径算法)
前言
在这里,如果大家对图或者数据结构还不太熟悉,想找一个动态的生成过程来参考,这是一个不错的网站.
知识框架
图的定义
在线性结构中,数据元素之间满足唯一的线性关系,每个数据元素(除第一个和最后一个外)只有一个直接前趋和一个直接后继;
在树形结构中,数据元素之间有着明显的层次关系,并且每个数据元素只与上一层中的一个元素(双亲节点)及下一层的多个元素(孩子节点)相关;
而在图形结构中,节点之间的关系是任意的,图中任意两个数据元素之间都有可能相关。
图G由两个集合V(顶点Vertex)和E(边Edge)组成,定义为G=(V,E)
图的存储结构
1.邻接矩阵
维持一个二维数组,arr[i][j]表示i到j的边,如果两顶点之间存在边,则为1,否则为0;
维持一个一维数组,存储顶点信息,比如顶点的名字;
下图为一般的有向图:
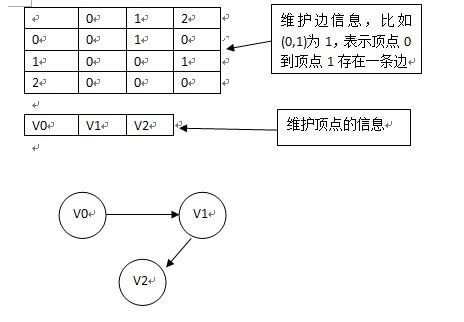
注意:如果我们要看vi节点邻接的点,则只需要遍历arr[i]即可;
下图为带有权重的图的邻接矩阵表示法:
缺点:邻接矩阵表示法对于稀疏图来说不合理,因为太浪费空间;
2.邻接表
如果图示一般的图,则如下图:
如果是网,即边带有权值,则如下图:
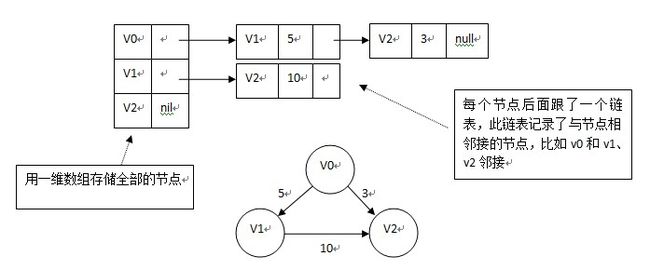
图的遍历
DFS(Depth-first-search) 深度优先遍历
形象的说,就像搜索文件夹,从第一个开始文件夹开始搜索到底,然后再搜索第二个到底,然后第三个….一直到最后.
官方的说:
a) 假设初始状态是图中所有顶点都未曾访问过,则可从图G中任意一顶点v为初始出发点,首先访问出发点v,并将其标记为已访问过。
b) 然后依次从v出发搜索v的每个邻接点w,若w未曾访问过,则以w作为新的出发点出发,继续进行深度优先遍历,直到图中所有和v有路径相通的顶点都被访问到。
c) 若此时图中仍有顶点未被访问,则另选一个未曾访问的顶点作为起点,重复上述步骤,直到图中所有顶点都被访问到为止。
图示如下:
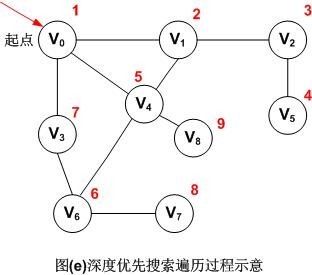
ds59
注:红色数字代表遍历的先后顺序,所以图(e)无向图的深度优先遍历的顶点访问序列为:V0,V1,V2,V5,V4,V6,V3,V7,V8
如果采用邻接矩阵存储,则时间复杂度为O(n2);当采用邻接表时时间复杂度为O(n+e)。
BFS(Breadth-first-search) 广度优先搜索遍历
形象的,类似于树的层次遍历,一层层的找.
书面上:
广度优先搜索遍历BFS类似于树的按层次遍历。其基本思路是:
a) 首先访问出发点Vi
b) 接着依次访问Vi的所有未被访问过的邻接点Vi1,Vi2,Vi3,…,Vit并均标记为已访问过。
c) 然后再按照Vi1,Vi2,… ,Vit的次序,访问每一个顶点的所有未曾访问过的顶点并均标记为已访问过,依此类推,直到图中所有和初始出发点Vi有路径相通的顶点都被访问过为止。
图示如下:
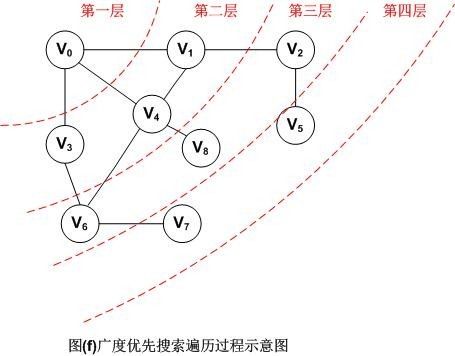
因此,图(f)采用广义优先搜索遍历以V0为出发点的顶点序列为:V0,V1,V3,V4,V2,V6,V8,V5,V7
如果采用邻接矩阵存储,则时间复杂度为O(n2),若采用邻接表,则时间复杂度为O(n+e)。
图的Java实现以及遍历
public class Graph {
private int vertexSize;//顶点数量
private int [] vertexs;//顶点数组
private int[][] matrix; //邻接矩阵
private static final int MAX_WEIGHT = 1000;
private boolean [] isVisited;
public Graph(int vertextSize){
this.vertexSize = vertextSize;
matrix = new int[vertextSize][vertextSize];
vertexs = new int[vertextSize];
for(int i = 0;inew boolean[vertextSize];
}
/**
* 获取某个顶点的出度
* @return
*/
public int getOutDegree(int index){
int degree = 0;
for(int j = 0;jint weight = matrix[index][j];
if(weight!=0&&weight!=MAX_WEIGHT){
degree++;
}
}
return degree;
}
/**
* 入度
* @return
*/
/**
* 获取某个顶点的第一个邻接点
* 根据index(代表第几行) 往右遍历j++(代表第几列),则第一个数为第一个邻接点.
*/
public int getFirstNeighbor(int index){
for(int j = 0;jif(matrix[index][j]>0&&matrix[index][j]return j;
}
}
return -1;
}
/**
* 在顶点v处,根据前一个邻接点的下标index来取得下一个邻接点
* @param v1表示要找的顶点
* @param v2 表示该顶点相对于哪个邻接点去获取下一个邻接点(index表示从参照点开始往后遍历)
*/
public int getNextNeighbor(int v,int index){
for(int j = index+1;jif(matrix[v][j]>0&&matrix[v][j]return j;
}
}
return -1;
}
/**
* 图的深度优先遍历算法
*/
private void depthFirstSearch(int i){
isVisited[i] = true;
int w = getFirstNeighbor(i);//
while(w!=-1){
if(!isVisited[w]){
//需要遍历该顶点
System.out.println("访问到了:"+w+"顶点");
depthFirstSearch(w);
}
w = getNextNeighbor(i, w);//第一个相对于w的邻接点
}
}
/**
* 对外公开的深度优先遍历
*/
public void depthFirstSearch(){
isVisited = new boolean[vertexSize];
for(int i = 0;iif(!isVisited[i]){
System.out.println("访问到了:"+i+"顶点");
depthFirstSearch(i);
}
}
isVisited = new boolean[vertexSize];
}
public void broadFirstSearch(){
isVisited = new boolean[vertexSize];
for(int i =0;iif(!isVisited[i]){
broadFirstSearch(i);
}
}
}
/**
* 实现广度优先遍历
* @param i
*/
private void broadFirstSearch(int i) {
int u,w;
LinkedList queue = new LinkedList();
System.out.println("访问到:"+i+"顶点");
isVisited[i] = true;
queue.add(i);//第一次把v0加到队列
while(!queue.isEmpty()){
u = (Integer)(queue.removeFirst()).intValue();
w = getFirstNeighbor(u);
while(w!=-1){
if(!isVisited[w]){
System.out.println("访问到了:"+w+"顶点");
isVisited[w] = true;
queue.add(w);
}
w = getNextNeighbor(u, w);
}
}
}
/*********************************/
public static void main(String [] args){
Graph graph = new Graph(9);
int [] a1 = new int[]{
0,10,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,11,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT};
int [] a2 = new int[]{
10,0,18,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,16,MAX_WEIGHT,12};
int [] a3 = new int[]{MAX_WEIGHT,MAX_WEIGHT,0,22,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,8};
int [] a4 = new int[]{MAX_WEIGHT,MAX_WEIGHT,22,0,20,MAX_WEIGHT,MAX_WEIGHT,16,21};
int [] a5 = new int[]{MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,20,0,26,MAX_WEIGHT,7,MAX_WEIGHT};
int [] a6 = new int[]{
11,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,26,0,17,MAX_WEIGHT,MAX_WEIGHT};
int [] a7 = new int[]{MAX_WEIGHT,16,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,17,0,19,MAX_WEIGHT};
int [] a8 = new int[]{MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,16,7,MAX_WEIGHT,19,0,MAX_WEIGHT};
int [] a9 = new int[]{MAX_WEIGHT,12,8,21,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,MAX_WEIGHT,0};
graph.matrix[0] = a1;
graph.matrix[1] = a2;
graph.matrix[2] = a3;
graph.matrix[3] = a4;
graph.matrix[4] = a5;
graph.matrix[5] = a6;
graph.matrix[6] = a7;
graph.matrix[7] = a8;
graph.matrix[8] = a9;
// int degree = graph.getOutDegree(4);
// System.out.println("vo的出度:"+degree);
// System.out.println("权值:"+graph.getWeight(2,3));
//graph.depthFirstSearch();
graph.broadFirstSearch();
}
}
最小生成树
1.相关概念
- 生成树概念:生成树是将图中所有顶点以最少的边连通的子图
- 最小生成树概念: 权值和最小的生成树就是最小生成树。
2.算法prim java实现
就是用一个最小代价的数组,不断记录数组中对应下标的顶点所连接的最小路径
这样就可以求得所有顶点连接后的路径之和的最小值
/**
* []
*
* prim 普里姆算法 最小生成树
* 就是用一个最小代价的数组,不断记录数组中对应下标的顶点所连接的最小路径
* 一个顶点 先找到四周顶点的权值 分别比较,找到最小的进行连接,然后 再找相邻的下一个点四周顶点的权值
*/
public void prim(){
int [] lowcost = new int[vertexSize];//最小代价顶点权值的数组,为0表示已经获取最小权值
int [] adjvex = new int[vertexSize];//放顶点权值
int min,minId,sum = 0;//min最小,minID最小的下标,sum权值总和
for(int i = 1;i0][i];
}
for(int i = 1;i0;
for(int j = 1;jif(lowcost[j]0){
min = lowcost[j];
minId = j;
}
}
System.out.println("顶点:"+adjvex[minId]+"权值:"+min);
sum+=min;
lowcost[minId] = 0;
for(int j = 1;jif(lowcost[j]!=0&&matrix[minId][j]"最小生成树权值和:"+sum);
}
3.Kruskal算法
算法的思想是:
1.按照权值 从小到大排列 。
2.从上往下依次顶点相连
3.一旦构成回环(三点连接),就扔掉(第三条边)
4.最后构成最小生成树
Kruskal算法详解
/**
* 克鲁兹卡尔 算法
* 按照权值 从小到大排列
* 从上往下依次顶点相连
* 一旦构成回环(三点连接),就扔掉(第三条边)
* 最后构成最小生成树
*/
public class GraphKruskal {
private Edge[] edges;
private int edgeSize;
public GraphKruskal(int edgeSize) {
this.edgeSize = edgeSize;
edges = new Edge[edgeSize];
}
public void miniSpanTreeKruskal(){
int m,n,sum=0;
int[] parent = new int[edgeSize];//神奇的数组,下标为起点,值为终点
for(int i = 0 ;i0;
}
for(int i = 0;iif(n!=m){
parent[n] = m;
System.out.println("起始顶点:"+edges[i].begin+"---结束顶点:"+edges[i].end+"~权值:"+edges[i].weight);
sum+=edges[i].weight;
}else{
System.out.println("第"+i+"条边回环了");
}
}
System.out.println("sum:"+sum);
/*将神奇数组进行查询获取非回环的值
*
*/
public int find(int[] parent,int f){
while(parent[f]>0){
System.out.println("找到起点"+f);
f = parent[f];
System.out.println("找到终点:"+f);
}
return f;
}
public void createEdgeArray(){
Edge edge0 = new Edge(4,7,7);
Edge edge1 = new Edge(2,8,8);
Edge edge2 = new Edge(0,1,10);
Edge edge3 = new Edge(0,5,11);
Edge edge4 = new Edge(1,8,12);
Edge edge5 = new Edge(3,7,16);
Edge edge6 = new Edge(1,6,16);
Edge edge7 = new Edge(5,6,17);
Edge edge8 = new Edge(1,2,18);
Edge edge9 = new Edge(6,7,19);
Edge edge10 = new Edge(3,4,20);
Edge edge11 = new Edge(3,8,21);
Edge edge12 = new Edge(2,3,22);
Edge edge13 = new Edge(3,6,24);
Edge edge14 = new Edge(4,5,26);
edges[0] = edge0;
edges[1] = edge1;
edges[2] = edge2;
edges[3] = edge3;
edges[4] = edge4;
edges[5] = edge5;
edges[6] = edge6;
edges[7] = edge7;
edges[8] = edge8;
edges[9] = edge9;
edges[10] = edge10;
edges[11] = edge11;
edges[12] = edge12;
edges[13] = edge13;
edges[14] = edge14;
}
class Edge{
private int begin;
private int end;
private int weight;
public Edge(int begin, int end, int weight) {
super();
this.begin = begin;
this.end = end;
this.weight = weight;
}
public int getBegin() {
return begin;
}
public void setBegin(int begin) {
this.begin = begin;
}
public int getEnd() {
return end;
}
public void setEnd(int end) {
this.end = end;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
public static void main(String[]args){
GraphKruskal graphKruskal = new GraphKruskal(15);
graphKruskal.createEdgeArray();
graphKruskal.miniSpanTreeKruskal();
}
}
最短路径
求最短路径也就是求最短路径长度。下面是一个带权值的有向图,表格中分别列出了顶点V1其它各顶点的最短路径长度。
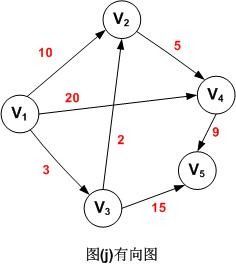
从图中可以看出,顶点V1到V4的路径有3条(V1,V2,V4),(V1,V4),(V1,V3,V2,V4),其路径长度分别为15,20和10,因此,V1到V4的最短路径为(V1,V3,V2,V4)。
dijkstra算法
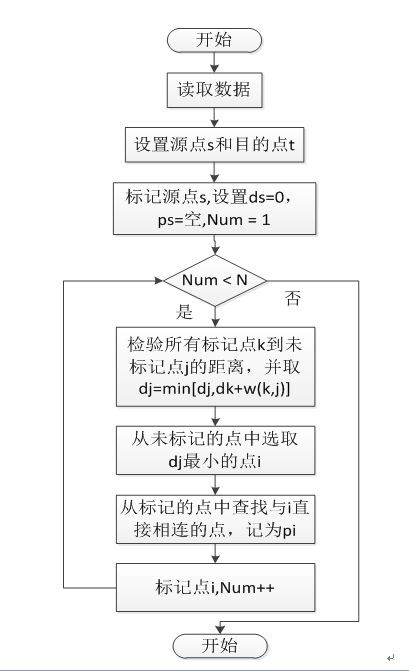
public class DnjavaDijstra {
private final static int MAXVEX = 9;
private final static int MAXWEIGHT = 65535;
private int shortTablePath[] = new int[MAXVEX];// 记录的是v0到某顶点的最短路径和
/**
* 获取一个图的最短路径
*/
public void shortestPathDijstra(Graph graph) {
int min;
int k = 0;// 记录下标
boolean isgetPath[] = new boolean[MAXVEX];
for (int v = 0; v < graph.getVertexSize(); v++) {
shortTablePath[v] = graph.getMatrix()[0][v];// 获取v0这一行的权值数组
}
shortTablePath[0] = 0;
isgetPath[0] = true;
for (int v = 1; v < graph.getVertexSize(); v++) {
min = MAXWEIGHT;
for (int w = 0; w < graph.getVertexSize(); w++) {
if (!isgetPath[w] && shortTablePath[w] < min) {
k = w;
min = shortTablePath[w];
}
}
isgetPath[k] = true;
for (int j = 0; j < graph.getVertexSize(); j++) {
if(!isgetPath[j]&&(min+graph.getMatrix()[k][j]for(int i = 0;i"V0到V"+i+"的最短路径为:"+shortTablePath[i]+"\n");
}
}
public static void main(String[] args){
Graph graph = new Graph(MAXVEX);
graph.createGraph();
DnjavaDijstra dijstra = new DnjavaDijstra();
dijstra.shortestPathDijstra(graph);
}
}
Floyd算法
Floyd算法又称为插点法,是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似。
参考
http://blog.csdn.net/xiazdong/article/details/7354411
http://www.cnblogs.com/mcgrady/archive/2013/09/23/3335847.html