大数据基础篇--Common Join 和Map Join的机制
文章目录
-
-
- 一 .Hive Common Join
- 二. Hive Map Join
-
- 什么是MapJoin?
- MapJoin的原理:
- 注意事项
- 三.测试
- 使用Map Join遇到的问题:
-
- 解决办法:
-
- 1.关闭自动Map Join转换
- 2.内存增大
-
笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join)。本文简单介绍一下两种join的原理和机制。
一 .Hive Common Join
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join.
整个过程包含Map、Shuffle、Reduce阶段。
Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序
Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
以下面的HQL为例,图解其过程:
SELECT
a.id,a.dept,b.age
FROM a join b
ON (a.id = b.id);

二. Hive Map Join
什么是MapJoin?
MapJoin顾名思义,就是在Map阶段进行表之间的连接。而不需要进入到Reduce阶段才进行连接。这样就节省了在Shuffle阶段时要进行的大量数据传输。从而起到了优化作业的作用。
MapJoin的原理:
通常情况下,要连接的各个表里面的数据会分布在不同的Map中进行处理。即同一个Key对应的Value可能存在不同的Map中。这样就必须等到Reduce中去连接。
要使MapJoin能够顺利进行,那就必须满足这样的条件:除了一份表的数据分布在不同的Map中外,其他连接的表的数据必须在每个Map中有完整的拷贝。
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数 hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M.
Hive0.7之前,需要使用hint提示* /+ mapjoin(table) */才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由数 hive.auto.convert.join来控制,默认为true.
假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。
执行流程如下:
1.通过MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会对HashTableFiles进行压缩。
2.MapReduce Job在Map阶段,每个Mapper从Distributed Cache读取HashTableFiles到内存中,顺序扫描大表,在Map阶段直接进行Join,将数据传递给下一个MapReduce任务。
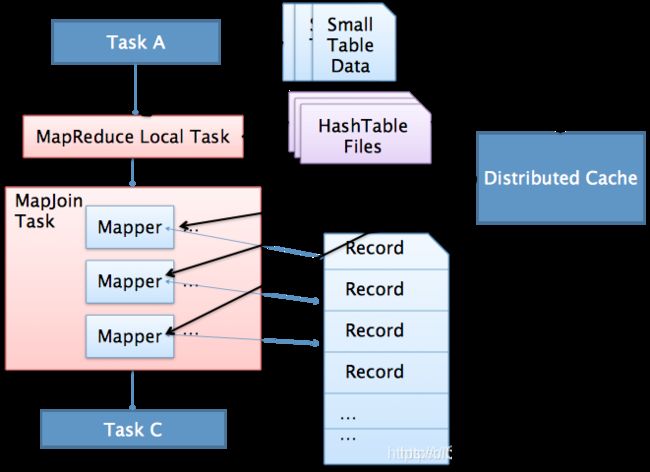
注意事项
使用mapjoin时,一次性加载到内存中的表最多是8张,如果超过8张小表,应该嵌套一层子循环,将多余的表在外层中写入mapjion里面.
在Hive调优里面,经常会问到一个很小的表和一个大表进行join,如何优化。
Shuffle 阶段代价非常昂贵,因为它需要排序和合并。减少 Shuffle 和 Reduce 阶段的代价可以提高任务性能。
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。
Hive0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true.
假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。
MapJoin简单说就是在Map阶段将小表数据从 HDFS 上读取到内存中的哈希表中,读完后将内存中的哈希表序列化为哈希表文件,在下一阶段,当 MapReduce 任务启动时,会将这个哈希表文件上传到 Hadoop 分布式缓存中,该缓存会将这些文件发送到每个 Mapper 的本地磁盘上。因此,所有 Mapper 都可以将此持久化的哈希表文件加载回内存,并像之前一样进行 Join。顺序扫描大表完成Join。减少昂贵的shuffle操作及reduce操作
三.测试
准备数据
hive (test)> select * from stu_190802;
stu_190802.id stu_190802.name stu_190802.sex stu_190802.department stu_190802.age
16 xm m 2 25
16 xm m 2 25
16 xm m 2 25
1 zs m 1 18
2 ls m 1 19
3 ww m 1 20
4 zq f 1 18
5 ll f 1 21
6 hl f 1 19
7 xh f 1 20
8 cl f 1 22
9 fj m 1 19
10 wb m 2 23
11 wf f 2 24
12 jj m 2 21
13 yy m 2 20
14 ld f 2 18
15 ch f 2 22
1 zs m 1 17
1 zs m 1 19
hive (test)> select * from department;
department.id department.leader
1 zs
2 wl
默认是ture 会开启小表mapjoin
hive (test)> set hive.auto.convert.join;
hive.auto.convert.join=true
hive (test)> set hive.mapjoin.smalltable.filesize;
hive.mapjoin.smalltable.filesize=25000000
两个表进行关联默认会执行mapjoin
select
t1.*
,t2.leader
from stu_190802 t1
left join department t2
on t1.department =t2.id;
commen join 时map段会有sort order: + 排序的功能,但是在mapjoin 时map 段不会sort
总结
1.mapjoin 可以看做 boardcast join 就是将小表的数据加载到内存中并且没有shuffle过程,加快处理效率,但是这样如果数据量过大,加载到内存有可能会引起OOM
2.普通join 会产生shuffle,会影响效率(数据传输);也可能产生数据倾斜(一个key太多,那任务处理就会很慢)
使用Map Join遇到的问题:
在hive中两张表进行join操作时有时会出现如下错误:
Caused by: java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:294)
at org.apache.hive.jdbc.HiveStatement.executeUpdate(HiveStatement.java:409)
at com.dtwave.dipper.hive.Hive2TaskRunnerPlugin.handleSql(Hive2TaskRunnerPlugin.java:380)
at com.dtwave.dipper.hive.Hive2TaskRunnerPlugin.normalRun(Hive2TaskRunnerPlugin.java:316)
at com.dtwave.dipper.hive.Hive2TaskRunnerPlugin.doRun(Hive2TaskRunnerPlugin.java:242)
at com.dtwave.dipper.spi.plugin.runner.BasicTaskRunnerPlugin.execute(BasicTaskRunnerPlugin.java:88)
... 11 more
出现错误的原因是 任务在进行join操作时转换mapjoin将小表放进内存导致内存溢出。
解决办法:
解决办法由两种,一个是将自动Map Join转换关闭,另外一个是将内存调大:
1.关闭自动Map Join转换
修改配置文件 关闭Map Join
hive.auto.convert.join = false
2.内存增大
hive.mapjoin.smalltable.filesize 默认值是25MB
修改内存大小
set mapreduce.map.memory.mb=2049;
set mapreduce.reduce.memory.mb=20495;
set hive.auto.convert.join=true;