2、Elasticsearch7.6.1基本介绍、2种部署方式及验证、head插件安装、分词器安装及验证
Elasticsearch 系列文章
1、介绍lucene的功能以及建立索引、搜索单词、搜索词语和搜索句子四个示例实现
2、Elasticsearch7.6.1基本介绍、2种部署方式及验证、head插件安装、分词器安装及验证
3、Elasticsearch7.6.1信息搜索示例(索引操作、数据操作-添加、删除、导入等、数据搜索及分页)
4、Elasticsearch7.6.1 Java api操作ES(CRUD、两种分页方式、高亮显示)和Elasticsearch SQL详细示例
5、Elasticsearch7.6.1 filebeat介绍及收集kafka日志到es示例
6、Elasticsearch7.6.1、logstash、kibana介绍及综合示例(ELK、grok插件)
7、Elasticsearch7.6.1收集nginx日志及监测指标示例
8、Elasticsearch7.6.1收集mysql慢查询日志及监控
9、Elasticsearch7.6.1 ES与HDFS相互转存数据-ES-Hadoop
文章目录
- Elasticsearch 系列文章
- 一、Elasticsearch介绍
-
- 1、为什么不直接使用Lucene
- 2、Elasticsearch介绍
- 3、Elasticsearch应用场景
- 4、Elasticsearch特点
-
- 1)、海量数据处理
- 2)、开箱即用
- 3)、作为传统数据库的补充
- 5、ElasticSearch对比Solr
- 二、安装Elasticsearch
-
- 1、创建普通用户
- 2、为普通用户alanchan添加sudo权限
- 3、上传压缩包并解压
- 4、修改配置文件
-
- 1)、修改elasticsearch.yml
- 2)、修改jvm.option
- 5、将安装包分发到其他服务器上面
- 6、server2与server3修改es配置文件
- 7、修改系统配置,解决启动时候的问题
-
- 1)、普通用户打开文件的最大数限制
- 2)、普通用户启动线程数限制
- 3)、普通用户调大虚拟内存
- 8、启动ES服务
- 三、Elasticsearch-head插件
-
- 1、安装nodejs
-
- 1)、下载安装包
- 2)、创建软连接
- 3)、修改环境变量
- 4)、验证安装成功
- 2、在线安装(不推荐)
-
- 1)、在线安装必须依赖包
- 2)、从git上面克隆编译包并进行安装
- 3)、server1机器修改Gruntfile.js
- 4)、server1机器修改app.js
- 3、本地安装(推荐)
-
- 1)、上传压缩包到/usr/local/tools路径下
- 2)、解压安装包
- 3)、server1机器修改Gruntfile.js
- 4)、server1机器修改app.js
- 5)、启动head服务
- 4、访问elasticsearch-head界面
- 四、安装IK分词器
-
- 1、下载Elasticsearch IK分词器
- 2、创建ik目录
- 3、解压分词器
- 4、分发
- 5、重启Elasticsearch
- 6、测试分词器
-
- 1)、安装ES插件
- 2)、设置ES服务器地址
- 3)、验证标准分词器
- 4)、验证IK分词器
- 五、Elasticsearch中的核心概念
-
- 1、索引 index
- 2、映射 mapping
- 3、字段Field
- 4、类型 Type
- 5、文档 document
- 6、集群 cluster
- 7、节点 node
- 8、分片和副本 shards&replicas
-
- 1)、分片
- 2)、副本
本文介绍了Elasticsearch的功能、应用场景,也介绍了其2种部署方式,同时介绍了head插件和分词器的安装,最后介绍了Elasticsearch的几个核心概念,该概念是后续使用的基础
本文分为5个部分,及基本介绍、两种部署方式、head插件安装、分词器安装和核心概念介绍。
一、Elasticsearch介绍
1、为什么不直接使用Lucene
- Lucene的内建不支持分布式
- Lucene是作为嵌入的类库形式使用的,本身是没有对分布式支持。
- 区间范围搜索速度非常缓慢
- Lucene的区间范围搜索API是扩展补充的,对于在单个文档中term出现比较多的情况,搜索速度会变得很慢
- Lucene只有在数据生成索引文件之后(Segment),才能被查询到,做不到实时
- 可靠性无法保障
- 无法保障Segment索引段的可靠性
2、Elasticsearch介绍
- Elasticsearch是一个基于Lucene的搜索服务器、提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
- Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎
- Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的
根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
3、Elasticsearch应用场景
- 信息检索,一般用于网站的全文检索
- 企业内部系统搜索,关系型数据库使用like进行模糊检索,会导致索引失效,效率低下,可以基于Elasticsearch来进行检索
- 数据分析引擎,Elasticsearch 聚合可以对数十亿行日志数据进行聚合分析,探索数据的趋势和规律
4、Elasticsearch特点
1)、海量数据处理
大型分布式集群(数百台规模服务器)
处理PB级数据
小公司也可以进行单机部署
2)、开箱即用
简单易用,操作非常简单
快速部署生产环境
3)、作为传统数据库的补充
传统关系型数据库不擅长全文检索(MySQL自带的全文索引,与ES性能差距非常大)
传统关系型数据库无法支持搜索排名、海量数据存储、分析等功能
Elasticsearch可以作为传统关系数据库的补充,提供RDBM无法提供的功能
5、ElasticSearch对比Solr
Solr 利用Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于Elasticsearch
二、安装Elasticsearch
此处部署三台es,服务器名称为server1、server2和server3。
1、创建普通用户
ES不能使用root用户来启动,必须使用普通用户来安装启动。
创建一个普通用户以及定义一些常规目录用于存放我们的数据文件以及安装包等。
创建一个es专门的用户(必须)
# 使用root用户在三台机器执行以下命令
useradd alanchan
passwd rootroot
2、为普通用户alanchan添加sudo权限
为了让普通用户有更大的操作权限,一般都会给普通用户设置sudo权限,方便普通用户的操作
三台机器使用root用户执行visudo命令然后为es用户添加权限
visudo
# 第100行
alanchan ALL=(ALL) ALL
3、上传压缩包并解压
将es的安装包下载并上传到server1服务器的/usr/local/tools路径下,然后进行解压
使用alanchan用户来执行以下操作,将es安装包上传到server1服务器,并使用es用户执行以下命令解压。
# 解压Elasticsearch
tar -zvxf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/bigdata
4、修改配置文件
1)、修改elasticsearch.yml
server1服务器使用alanchan用户来修改配置文件
cd /usr/local/bigdata/elasticsearch-7.6.1/config
mkdir -p /usr/local/bigdata/esdata
rm -rf elasticsearch.yml
vim elasticsearch.yml
cluster.name: alan-application
node.name: server1
path.data: /usr/local/bigdata/esdata
path.logs: /usr/local/bigdata/elasticsearch-7.6.1/log
network.host: server1
http.port: 9200
discovery.seed_hosts: ["server1", "server2", "server3"]
cluster.initial_master_nodes: ["server3", "server2"]
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
2)、修改jvm.option
修改jvm.option配置文件,调整jvm堆内存大小
server1使用alanchan用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整。
cd /usr/local/bigdata/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g
5、将安装包分发到其他服务器上面
server1使用alanchan用户将安装包分发到其他服务器上面去
cd /usr/local/bigdata
scp -r elasticsearch-7.6.1/ server2:$PWD
scp -r elasticsearch-7.6.1/ server3:$PWD
6、server2与server3修改es配置文件
server2使用alanchan用户执行以下命令修改es配置文件
mkdir -p /usr/local/bigdata/esdata
# 修改配置文件
cd /usr/local/bigdata/elasticsearch-7.6.1/config
vim elasticsearch.yml
node.name: server2
network.host: server2
#server3使用alanchan用户执行以下命令修改配置文件
#创建数据目录
mkdir -p /usr/local/bigdata/esdata
#修改配置文件
cd /usr/local/bigdata/elasticsearch-7.6.1/config
vim elasticsearch.yml
node.name: server3
network.host: server3
7、修改系统配置,解决启动时候的问题
由于现在使用普通用户来安装es服务,且es服务对服务器的资源要求比较多,包括内存大小,线程数等。所以需要给普通用户解开资源的束缚
1)、普通用户打开文件的最大数限制
问题错误信息描述:
maxfile descriptors [4096] for elasticsearch process likely too low, increase toat least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
三台机器使用alanchan用户执行以下命令解除打开文件数据的限制
sudo vi /etc/security/limits.conf
#添加如下内容: 注意*不要去掉了
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
此文件修改后需要重新登录用户,才会生效
2)、普通用户启动线程数限制
问题错误信息描述
maxnumber of threads [1024] for user [es] likely too low, increase to at least[4096]
修改普通用户可以创建的最大线程数
max number ofthreads [1024] for user [es] likely too low, increase to at least [4096]
原因:无法创建本地线程问题,用户最大可创建线程数太小解决方案:修改90-nproc.conf 配置文件。
三台机器使用alanchan用户执行以下命令修改配置文件
Centos6
sudo vi /etc/security/limits.d/90-nproc.conf
Centos7
sudo vi /etc/security/limits.d/20-nproc.conf
#找到如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
3)、普通用户调大虚拟内存
错误信息描述:
maxvirtual memory areas vm.max_map_count [65530] likely too low, increase to atleast [262144]
调大系统的虚拟内存
原因:最大虚拟内存太小
每次启动机器都手动执行下。
三台机器执行以下命令
执行下面命令
sudo sysctl -w vm.max_map_count=262144
#修改配置文件
sudo vim /etc/sysctl.conf
#在最后添加一行
vm.max_map_count=262144
#立即生效
sysctl -p
#查看修改结果
sysctl -a|grep vm.max_map_count
[alanchan@server1 ~]$ sudo sysctl -a|grep vm.max_map_count
vm.max_map_count = 262144
备注:以上三个问题解决完成之后,重新连接secureCRT或者重新连接xshell生效
8、启动ES服务
三台机器使用alanchan用户执行以下命令启动es服务
nohup /usr/local/bigdata/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
[alanchan@server3 ~]$ jps
3973 Elasticsearch
9975 Jps
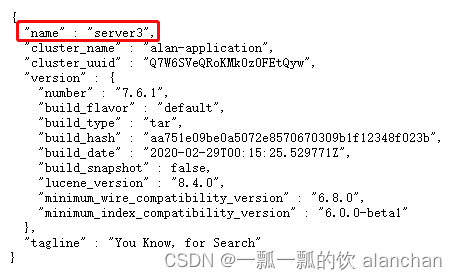
启动成功之后jsp即可看到es的服务进程,并且访问页面
http://server1:9200/?pretty
http://server2:9200/?pretty
http://server3:9200/?pretty
能够看到es启动之后的一些信息
三、Elasticsearch-head插件
elasticsearch-head这个插件是es提供的一个用于图形化界面查看的一个插件工具,可以安装上这个插件之后,通过这个插件来实现通过浏览器查看es当中的数据
安装elasticsearch-head这个插件这里提供两种方式进行安装
第一种方式就是自己下载源码包进行编译,耗时比较长
第二种方式就是直接使用我已经编译好的安装包,进行修改配置即可
要安装elasticsearch-head插件,需要先安装Node.js
1、安装nodejs
Node.js是一个基于Chrome V8 引擎的 JavaScript 运行环境。
Node.js是一个Javascript运行环境(runtime environment),发布于2009年5月,由Ryan Dahl开发,实质是对ChromeV8引擎进行了封装。Node.js 不是一个JavaScript 框架,不同于CakePHP、Django、Rails。Node.js 更不是浏览器端的库,不能与 jQuery、ExtJS 相提并论。Node.js是一个让 JavaScript 运行在服务端的开发平台,它让JavaScript 成为与PHP、Python、Perl、Ruby 等服务端语言平起平坐的脚本语言。
1)、下载安装包
server1机器执行以下命令下载安装包,然后进行解压
cd /usr/local/tools
wget https://npm.taobao.org/mirrors/node/v8.5.0/node-v8.5.0-linux-x64.tar.gz
tar -zxvf node-v8.5.0-linux-x64.tar.gz -C /usr/local/bigdata
2)、创建软连接
server1执行以下命令创建软连接
sudo ln -s /usr/local/bigdata/node-v8.5.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
sudo ln -s /usr/local/bigdata/node-v8.5.0-linux-x64/bin/node /usr/local/bin/node
3)、修改环境变量
server1服务器添加环境变量
vim /etc/profile
export NODE_HOME=/usr/local/bigdata/node-v8.5.0-linux-x64
export PATH=:$PATH:$NODE_HOME/bin
修改完环境变量使用source生效
source /etc/profile
4)、验证安装成功
server1执行以下命令验证安装生效
node -v
npm -v
[alanchan@server3 bigdata]$ node -v
v8.5.0
[alanchan@server3 bigdata]$ npm -v
5.3.0
2、在线安装(不推荐)
这里选择server1进行安装
1)、在线安装必须依赖包
# 初始化目录
cd /usr/local/bigdata/es
# 安装GCC
sudo yum install -y gcc-c++ make git
2)、从git上面克隆编译包并进行安装
cd /usr/local/bigdata
git clone https://github.com/mobz/elasticsearch-head.git
# 进入安装目录
cd /usr/local/bigdata/elasticsearch-head
# intall 才会有 node-modules
npm install
以下进度信息
npm WARN notice [SECURITY] lodash has thefollowing vulnerability: 1 low. Go here for more details:
npm WARN notice [SECURITY] debug has thefollowing vulnerability: 1 low. Go here for more details:https://nodesecurity.io/advisories?search=debug&version=0.7.4 - Run `npm inpm@latest -g` to upgrade your npm version, and then `npm audit` to get moreinfo.
npm ERR! Unexpected end of input at 1:2096
npm ERR!7c1a1bc21c976bb49f3ea","tarball":"https://registry.npmjs.org/safer-bu
npm ERR! ^
npm ERR! A complete log of this run can befound in:
npm ERR! /home/es/.npm/_logs/2018-11-27T14_35_39_453Z-debug.log
以上错误可以不用管。
3)、server1机器修改Gruntfile.js
第一台机器修改Gruntfile.js这个文件
cd /usr/local/bigdata/elasticsearch-head
vim Gruntfile.js
#找到以下代码:
#添加一行: hostname: '192.168.10.41',
connect: {
server: {
options: {
hostname:'192.168.10.41',
port: 9100,
base: '.',
keepalive:travelue
}
}
}
4)、server1机器修改app.js
第一台机器修改app.js
cd /usr/local/bigdata/elasticsearch-head/_site
vim app.js
#更改前:
http://localhost:9200
#更改后:
http://server1:9200
3、本地安装(推荐)
1)、上传压缩包到/usr/local/tools路径下
将压缩包 elasticsearch-head-compile-after.tar.gz 上传到server1机器的/usr/local/tools路径下面去
2)、解压安装包
server1执行以下命令解压安装包
cd /usr/local/tools
tar -zxvf elasticsearch-head-compile-after.tar.gz -C /usr/local/bigdata
3)、server1机器修改Gruntfile.js
修改Gruntfile.js这个文件
cd /usr/local/bigdata/elasticsearch-head
vim Gruntfile.js
找到代码中的93行:hostname:'192.168.100.100', 修改为:server1
connect: {
server: {
options: {
hostname: 'server1',
port: 9100,
base: '.',
keepalive: true
}
}
}
4)、server1机器修改app.js
server1机器修改app.js
cd /usr/local/bigdata/elasticsearch-head/_site
vim app.js
第4354行,http://localhost:9200修改为自己的ip
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://server1:9200";
5)、启动head服务
server1启动elasticsearch-head插件
cd /usr/local/bigdata/elasticsearch-head/node_modules/grunt/bin/
#进程前台启动命令
./grunt server
[alanchan@server1 bin]$ ./grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://server1:9100
#进程后台启动命令
nohup ./grunt server >/dev/null 2>&1 &
#如何停止:elasticsearch-head进程
#执行以下命令找到elasticsearch-head的插件进程,然后使用kill -9 杀死进程即可
netstat -nltp | grep 9100
kill -98328
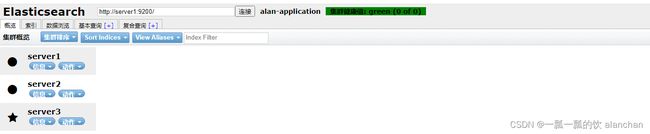
4、访问elasticsearch-head界面
打开Google Chrome访问
http://server1:9100
四、安装IK分词器
需要使用Elasticsearch来进行中文分词,所以需要单独给Elasticsearch安装IK分词器插件。
以下为具体安装步骤:
1、下载Elasticsearch IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
2、创建ik目录
切换到alanchan用户,并在bigdata的安装目录下/plugins创建ik
mkdir -p /usr/local/bigdata/elasticsearch-7.6.1/plugins/ik
3、解压分词器
将下载的ik分词器上传并解压到该目录
cd /usr/local/bigdata/elasticsearch-7.6.1/plugins/ik
sudo rz
unzip elasticsearch-analysis-ik-7.6.1.zip
4、分发
将plugins下的ik目录分发到每一台服务器
cd /usr/local/bigdata/elasticsearch-7.6.1/plugins
scp -r ik/ server2:$PWD
scp -r ik/ server3:$PWD
5、重启Elasticsearch
关闭进程
kill 进程号
启动
nohup /usr/local/bigdata/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
6、测试分词器
本示例用VS code进行测试
1)、安装ES插件
2)、设置ES服务器地址


3)、验证标准分词器
post _analyze
{
"analyzer":"standard",
"text":"我爱你中国"
}

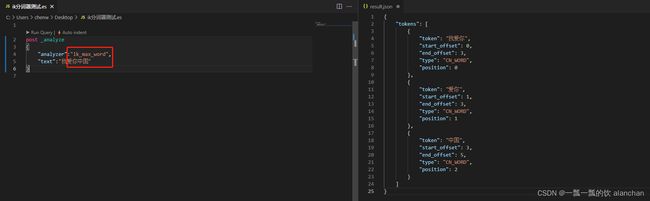
4)、验证IK分词器
post _analyze
{
"analyzer":"ik_max_word",
"text":"我爱你中国"
}
五、Elasticsearch中的核心概念
1、索引 index
- 一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
- 一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
- 在一个集群中,可以定义任意多的索引。
2、映射 mapping
- ElasticSearch中的映射(Mapping)用来定义一个文档
- mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的
3、字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
4、类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
5、文档 document
一个文档是一个可被索引的基础信息单元。比如,可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式
6、集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”
这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
7、节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中
在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
8、分片和副本 shards&replicas
1)、分片
-
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
-
当创建一个索引的时候,可以指定你想要的分片的数量
-
每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
-
分片很重要,主要有两方面的原因
允许水平分割/扩展你的内容容量
允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的
2)、副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
副本之所以重要,有两个主要原因
- 在分片/节点失败的情况下,提供了高可用性。注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的
扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。每个索引可以被分成多个分片。一个索引有0个或者多个副本 - 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
以上,介绍了Elasticsearch的功能、应用场景,也介绍了其2种部署方式,同时介绍了head插件和分词器的安装,最后介绍了Elasticsearch的几个核心概念,该概念是后续使用的基础。