Flink单并行度消费kafka触发窗口计算问题
Flink单并行度消费kafka触发窗口计算问题
- 基本信息
-
- 验证:
-
- 生产者发送消息:
- 窗口统计代码(并行度设为1):
- 最终窗口输出结果:
- 调整并行度与topic一致
基本信息
flink版本1.11
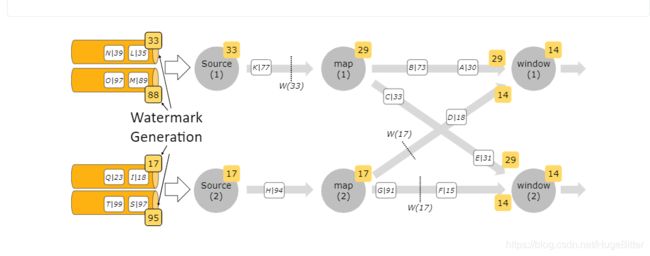
问题:flink上游数据源为kafka,topic有10个分区,在flink单并行度消费该topic进行窗口统计,job稳定运行统计数据差异不明显,如果job异常,进行重启,消费积压数据进行窗口统计,发现数据异常。
排查:由于上游topic数据为埋点,时间格式比较乱,怀疑flink在单并行度消费多partition的kafka topic情况下,即时产生waterMark,并触发窗口计算,这样会导致剩余partition中属于该窗口的数据被认为延迟数据。
验证:
为测试,创建一个topic:partition_test_2,2个partition
生产者发送消息:
topic partition-1分区始终为2021-07-02 15:00:14
partition-0分区每分钟更新为最新时间
while (true) {
producer.send(new ProducerRecord<>(topic, "1", "{\"time\":\"1625209214978\",\"uid\":\"529eb9bb421aa97f9abcb45f\"}"));
producer.send(new ProducerRecord<>(topic, "0", "{\"time\":\""+System.currentTimeMillis()+"\",\"uid\":\"529eb9bb421aa97f9abcb45f\"}"));
producer.flush();
try {
Thread.sleep(1000 * 60);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
窗口统计代码(并行度设为1):
public static void main(String[] args) {
try {
StreamExecutionEnviroment env = new StreamExecutionEnviroment(args);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "server");
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "partition_test");
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
String topic = "partition_test_2";
FlinkKafkaConsumer consumer = new FlinkKafkaConsumer(topic, new SimpleStringSchema(), properties);
DataStream dataStream = env.addSource(consumer);
dataStream.flatMap(new RichFlatMapFunction>() {
@Override
public void flatMap(String value, Collector> out) throws Exception {
if (StringUtils.isNotBlank(value)) {
JSONObject jsonObject = JSON.parseObject(value);
String uid = jsonObject.getString("uid");
Long time = jsonObject.getLong("time");
System.out.println("task Index: "+getRuntimeContext().getIndexOfThisSubtask()+", uid:" + uid + ", time:" + TimeUtil.millis2Str(time));
out.collect(new Tuple2<>(uid, time));
}
}
}).assignTimestampsAndWatermarks(WatermarkStrategy
.>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner(((element, recordTimestamp) -> element.f1))
).keyBy(new KeySelector, String>() {
@Override
public String getKey(Tuple2 value) throws Exception {
return value.f0;
}
}).window(TumblingEventTimeWindows.of(Time.minutes(5L)))
.process(new ProcessWindowFunction, Tuple3, String, TimeWindow>() {
private DateTimeFormatter df = null;
@Override
public void open(Configuration parameters) throws Exception {
df = new DateTimeFormatterBuilder()
.appendPattern("yyyy-MM-dd HH:mm:ss")
.toFormatter();
}
@Override
public void process(String s, Context context, Iterable> elements, Collector> out) throws Exception {
long end = context.window().getEnd();
System.out.println("end: " + end);
String format = Instant.ofEpochMilli(end).atZone(ZoneId.systemDefault()).format(df);
// LocalDateTime localDateTime = LocalDateTime.ofEpochSecond(end, 0, ZoneOffset.ofHours(8));
System.out.println("localDateTime: " + format);
Iterator> iterator = elements.iterator();
LongAccumulator longAccumulator = new LongAccumulator((a, b) -> a + b, 0);
while (iterator.hasNext()) {
if (iterator.next().f0.equalsIgnoreCase(s)) {
longAccumulator.accumulate(1);
}
}
out.collect(new Tuple3<>(format, s, longAccumulator.longValue()));
}
})
.print("window result -> ");
env.execute("KafkaPartitionTest");
} catch (Exception e) {
log.error("异常信息:" + e.getMessage());
e.printStackTrace();
}
}
最终窗口输出结果:
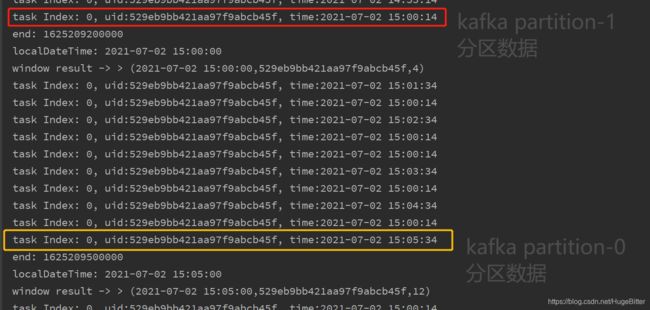
可以看到,当并行度为1的时候,flink的窗口触发以及watermark生成并不会考虑kafka topic全局的数据,会导致窗口提前触发,所以,使用flink消费kafka进行延迟数据处理的场景下,一定要注意并行度和topic的关系!
调整并行度与topic一致

打印子任务号接收到的数据:
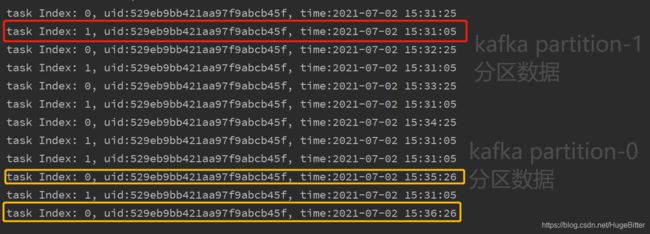
结合官方文档就很明确了:
flink多并行度的情况下,Operator会等所有的subtask的watermark到达之后选取最小的作为最终的waterMark传到下游。
所以当我们的测试代码并行度和topic partition 保持一致的时候,只用subtask-1的eventTime一直在2021-07-02 15:31:05,watermark维持不变,永远不会触发窗口计算。
官方文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/event-time/generating_watermarks/