ELK+KAFKA+FILEBEAT集群实战(nginx访问日志收集)
组件介绍
1、Elasticsearch: 主要用来日志存储
2、Logstash: 主要用来日志的搜集(filebeat)
3、Kibana: 主要用于日志的展示
4、Kafka:是一个分布式的消息发布—订阅系统(kafka其实是消息队列)
5、Filebeat: 轻量级数据收集引擎
ELK作用
建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
软件版本:
Elasticsearch: 6.5.4
Logstash: 6.5.4
Kibana: 6.5.4
Kafka: 2.11-1
Filebeat: 6.5.4
服务器:
ES: server7=192.168.122.7
ES: server6=192.168.122.6
KIBANA: server5=192.168.122.5
LOGSTASH: server4=192.168.122.4
KAFKA: server4=192.168.122.4
FILEBEAT: server3=192.168.122.3
一:Elasticsearch集群部署
#我们需要准备的安装包
[root@server7 ~]# ls
anaconda-ks.cfg jdk-8u201-linux-x64.tar.gz
elasticsearch-6.5.4.tar.gz node-v4.4.7-linux-x64.tar.gz
# 全部解压到/usr/local/下并改名为
[root@server7 local]# ls
bin etc master.zip src
elasticsearch games lib node include lib64 sbin
elasticsearch-head-master java libexec share
#修改环境变量
[root@xingdian ~]# vim /etc/profile
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
NODE_HOME=/usr/local/node
PATH=$NODE_HOME/bin:$PATH
export NODE_HOME PATH
[root@server7 local]# source /etc/profile
#创建用户和组
[root@server7 local]# useradd elsearch
[root@server7 local]# echo "123456" | passwd --stdin "elsearch"
#修改es的配置文件
[root@server7 local]# vim /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: bjbpe01-elk
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.122.7","192.168.122.6"]
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
#设置JVM堆大小
[root@server7 local]# sed -i 's/-Xms1g/-Xms1g/' /usr/local/elasticsearch/config/jvm.options
#确保堆内存最大值与最小值相同,防止程序运行时改变堆内存大小。如果系统内存足够大,可以将堆内存设置为31G,因为32G有一个性能瓶颈问题,堆内存大小不要超过系统内存的50%.
#创建ES数据及日志存储目录
[root@server7 local]# mkdir -p /data/elasticsearch/data
[root@server7 local]# mkdir -p /data/elasticsearch/logs
#修改安装目录及存储目录权限
[root@server7 local]# chown -R elsearch:elsearch /data/elasticsearch
[root@server7 local]# chown -R elsearch:elsearch /usr/local/elasticsearch
#系统优化
#(在此文件中添加以下内容,*表示所有用户)
[root@server7 local]# vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
#增加最大内存映射数
[root@server7 local]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
[root@server7 local]# sysctl -p
#启动ES
su - elsearch -c "cd /usr/local/elasticsearch && nohup bin/elasticsearch &"
#另一台服务器部署相同操作
#安装配置head内容管理和监控插件(server7和server6一起部署,作用就是可以在web界面查看)
#安装node
#在上面我们已经把node解压到/usr/local下并且设置了环境变量
#下载head插件
[root@server7 local]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@server7 local]# unzip -d /usr/local master.zip
#安装grunt
[root@server7 local]# cd /usr/local/elasticsearch-head-master
[root@server7 elasticsearch-head-master]# npm install -g grunt-cli
[root@server7 elasticsearch-head-master]# grunt --version
#修改head源码
[root@server7 elasticsearch-head-master]# vi /usr/local/elasticsearch-head-master/Gruntfile.js
94 connect: {
95 server: {
96 options: {
97 port: 9100,
98 base: '.',
99 keepalive: true,
100 hostname:'*'
#注意要在true后面加“,”而hostname“*”后不需要
[root@server7 elasticsearch-head-master]# vi /usr/local/elasticsearch-head-master/_site/app.js
4375 init: function(parent) {
4376 this._super();
4377 this.prefs = services.Preferences.instance();
4378 this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.122.7:9200";
4379 if( this.base_uri.charAt( this.base_uri.length - 1 ) !== "/" ) {
4380 // XHR request fails if the URL is not ending with a "/"
4381 this.base_uri += "/";
4382 }
#原本是http://localhost:9200
#下载head必要的文件
[root@server7 elasticsearch-head-master]# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@server7 elasticsearch-head-master]# yum -y install bzip2
[root@server7 elasticsearch-head-master]# tar -jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /tmp/
#运行head
[root@server7 elasticsearch-head-master]# npm install
[root@server7 elasticsearch-head-master]# nohup grunt server &
测试
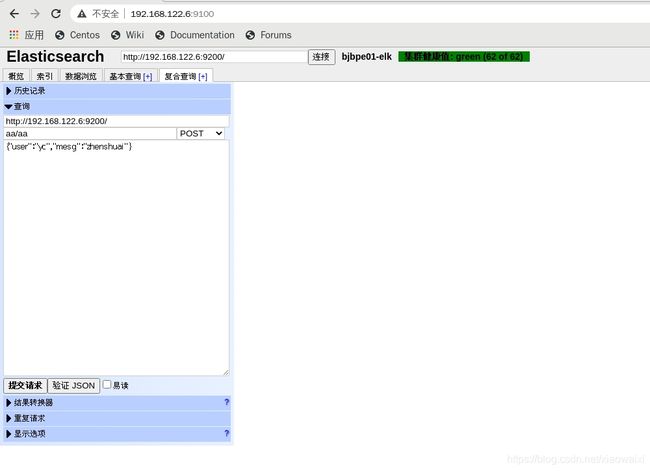
二:Kibana部署
#准备安装包
[root@server5 ~]# ls
anaconda-ks.cfg kibana-6.5.4-linux-x86_64.tar.gz
[root@server5 ~]# tar xf kibana-6.5.4-linux-x86_64.tar.gz -C /usr/local/
[root@server5 ~]# mv /usr/local/kibana-6.5.4-linux-x86_64/ /usr/local/kibana
[root@server5 ~]# vim /usr/local/kibana/config/kibana.yml
server.port: 5601
server.host: "192.168.122.5"
elasticsearch.url: "http://192.168.122.7:9200"
kibana.index: ".kibana"
[root@server5 ~]# cd /usr/local/kibana
[root@server5 kibana]# nohup ./bin/kibana &
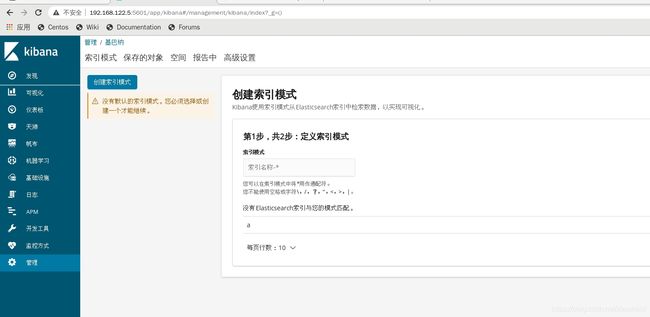
kibana已经部署完成对于统计图我们在作完所有实验以后再来完成
三:logstash部署
#安装jdk
[root@server4 ~]# tar xf jdk-8u201-linux-x64.tar.gz -C /usr/local/
[root@server4 ~]# cd /usr/local/
[root@server4 local]# mv jdk1.8.0_201/ java
[root@server4 local]# vim /etc/profile
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
[root@server4 local]# source /etc/profile
#安装logstash
[root@server4 local]# tar xf /root/logstash-7.3.2.tar.gz -C /usr/local/
[root@server4 local]# mv logstash-7.3.2/ logstash
[root@server4 local]# cd logstash/
[root@server4 logstash]# cd bin/
#基本的输入输出
[root@server4 bin]# /usr/local/logstash/bin/logstash -e 'input { stdin{} } output { stdout{} }'
四、kafka部署
#因为我们在同一台服务器上所以jdk不需要再安装jdk
#安装kafka
[root@server4 local]# tar xf /root/kafka_2.11-2.1.0.tgz -C /usr/local/
[root@server4 local]# mv kafka_2.11-2.1.0/ kafka
[root@server4 kafka]# vi /usr/local/kafka/config/zookeeper.properties(文件内容替换成下面信息)
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.122.4:2888:3888
[root@server4 local]# mkdir -p /opt/data/zookeeper/{data,logs}
[root@server4 local]# echo 1 > /opt/data/zookeeper/data/myid
[root@server4 local]# cd /usr/local/kafka
[root@server4 kafka]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
[root@server4 kafka]# yum provides nc
[root@server4 kafka]# echo conf | nc 127.0.0.1 2181
clientPort=2181
dataDir=/opt/data/zookeeper/data/version-2
dataLogDir=/opt/data/zookeeper/logs/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=0
[root@server4 kafka]# echo stat | nc 127.0.0.1 2181
Zookeeper version: 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 00:39 GMT
Clients:
/127.0.0.1:42558[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 4
[root@server4 kafka]# ss -antpl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:* users:(("sshd",pid=869,fd=3))
LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=952,fd=13))
LISTEN 0 128 :::22 :::* users:(("sshd",pid=869,fd=4))
LISTEN 0 100 ::1:25 :::* users:(("master",pid=952,fd=14))
LISTEN 0 50 :::2181 :::* users:(("java",pid=1238,fd=99))
LISTEN 0 50 :::46186 :::* users:(("java",pid=1238,fd=86))
五、filebeat部署
#我们先安装一个nginx
[root@server3 ~]# yum -y install nginx
[root@server3 ~]# systemctl enable nginx --now
[root@server3 ~]# vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
access_log /var/log/access_log json;
[root@server3 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@server3 ~]# systemctl reload nginx
#下载filebeat
[root@server3 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.4-linux-x86_64.tar.gz
[root@server3 ~]# ls
anaconda-ks.cfg filebeat-6.5.4-linux-x86_64.tar.gz
[root@server3 ~]# tar xf filebeat-6.5.4-linux-x86_64.tar.gz -C /usr/local/
[root@server3 ~]# cd /usr/local/
[root@server3 local]# cd filebeat-6.5.4-linux-x86_64/
现在我们所有组件都以部署完成,开始配置部署
#先在kafka创建一个话题nginx-es
[root@server4 kafka]# bin/kafka-topics.sh --create --zookeeper 192.168.122.4:2181 --replication-factor 1 --partitions 1 --topic nginx-es
#启动kafka
[root@server4 kafka]# bin/kafka-console-producer.sh --broker-list 192.168.122.4:9092 --topic nginx-es
#修改logstash的配置文件
[root@server4 conf.d]# vim /usr/local/logstash/conf.d/input.conf
input {
kafka {
topics => "nginx-es"
#codec => "json"
decorate_events => true
bootstrap_servers => "192.168.122.4:9092"
}
}
output {
elasticsearch {
hosts => ["192.168.122.6:9200"]
index => 'nginx-%{+YYYY-MM-dd}'
}
}
#启动logstash服务
[root@server4 conf.d]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/conf.d/input.conf
#修改filebeat的配置文件filebeat.yml
[root@server3 filebeat-6.5.4-linux-x86_64]# vim /usr/local/filebeat-6.5.4-linux-x86_64/filebeat.yml
24 enabled: true
25
26 # Paths that should be crawled and fetched. Glob based paths.
27 paths:
28 - /var/log/access_log
148 output.kafka:
149 enabled: true
150 # Array of hosts to connect to.
151 hosts: ["192.168.122.4:9092"]
152 topic: 'nginx-es'
#启动filebeat
/usr/local/filebeat-6.5.4-linux-x86_64/filebeat.yml -c filebeat.yml

最后我们再kibana上创建图表

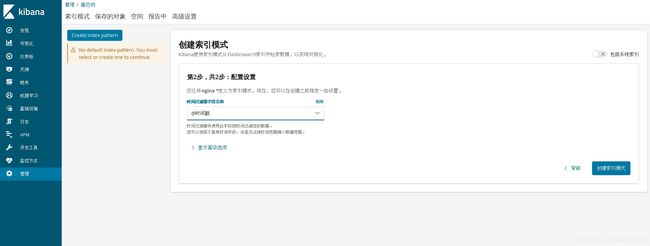
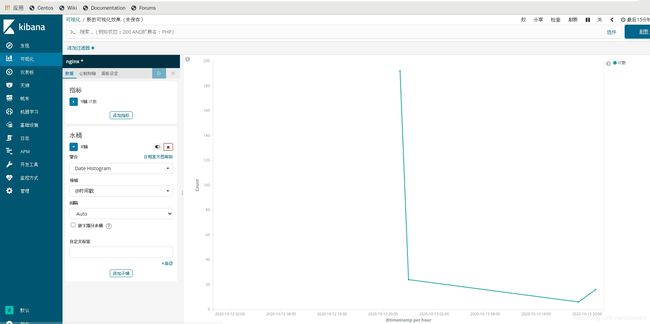 点击右上角的save保存,保存完后再次点击save保存
点击右上角的save保存,保存完后再次点击save保存
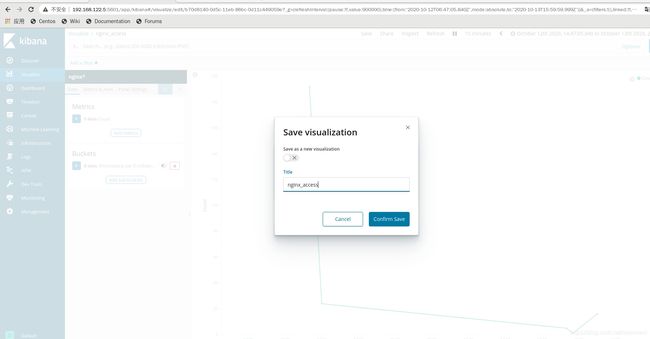 在Dashboard里的右上角点击add添加nginx-access的折线图
在Dashboard里的右上角点击add添加nginx-access的折线图

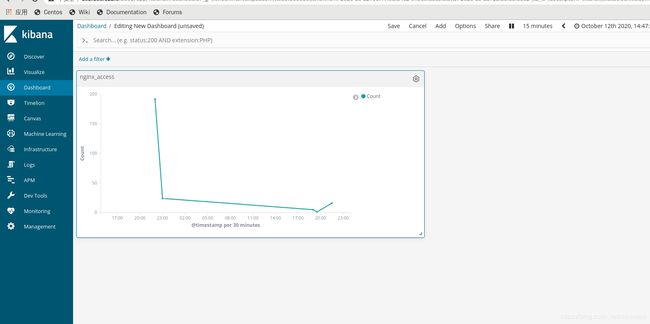
对此ELK+KAFKA+FILEBEAT集群全部完成!!此实验仅为参考,可根据需求添加服务器