面向大模型微调的instruction指令自动化生成技术:SELF-INSTRUCT指令自动化生成框架工作介绍...
来自:老刘说NLP
进NLP群—>加入NLP交流群
大型的 "指令微调 "语言模型(对指令的回复进行微调)已经显示其出对新任务进行zero-shot生成的卓越能力。
然而,这种方法在很大程度上依赖于人类编写的指令数据,即SFT数据。而这些数据在数量、多样性和创造性方面都是有限的,因此阻碍了调整后的模型的通用性。
事实上,当前已经出现了一些开源的指令数据,比如promptsource,T0等,但如何自动化的生成指令,并验证其有效性尤为重要。
文章《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》一文提出了SELF-INSTRUCT,一个通过引导生成预训练的语言模型来提高其指令跟随能力的框架,该框架从语言模型中生成指令、输入和输出样本,然后在使用它们来微调原始模型之前对它们进行过滤。
将该方法应用于vanilla GPT3,实验表明SUPER-NATURALINSTRUCTIONS上比原始模型有33%的绝对提高,与InstructGPT001的性能相当。

地址:https://arxiv.org/pdf/2212.10560v1.pdf
本文对该代表性的工作进行研读,并给出工作开源项目地址,大家可以阅读论文后根据自己的需求,借鉴其中的instruction数据或者生成方法,应用于自己的工作当中。
一、前言
大型预训练的语言模型(LM)和人类写的指令数据是当前一个热点。
其中,在数据上,PROMPTSOURCE(Bach等人,2022年)和SUPER- NATURALINSTRUCTIONS(Wang等人,2022年)是最近两个值得注意的数据集,它们使用大量的人工注释来收集指令来构建T0(Bach等人,2022年;Sanh等人,2022年)和T-INSTRUCT(Wang等人,2022年)。
然而,这个过程成本很高,而且很倾向于主流的NLP任务,没有涵盖真正的各种任务和描述它们的不同方式。鉴于这些限制,就需要继续提高指令调整模型的质量就必须 开发替代性的方法来监督指导性调整模型。
SELF-INSTRUCT,一个半自动的过程,利用模型本身的指令信号对预训练的LM进行指令调整。
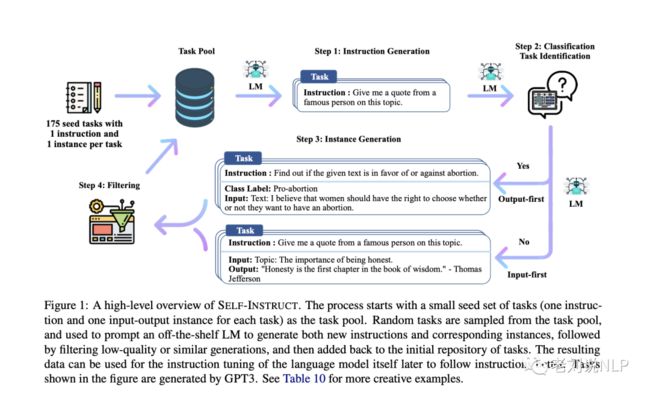
整个过程是一个迭代的引导算法(见图1),它从一个有限的(例如,在本工作中是175个)手动编写的指令种子集开始,这些指令被用来指导整个生成过程。
在第一阶段,模型被提示生成新任务的指令。这一步是利用现有的指令集来创造更广泛的指令,以定义(通常是新的)任务。
考虑到新生成的指令集有质量问题,该框架还为它们创建了输入输出实例,这些实例随后可用于监督指令的调整。
最后,在将低质量和重复的指令添加到任务池之前,会使用各种措施来修剪这些指令。这个过程可以重复许多次互动,直到达到大量的任务。
为了实证评估SELF-INSTRUCT,在GPT3(Brown等人,2020)上运行该框架,在这个模型上的SELF-INSTRUCT迭代过程产出了大约52K条指令,以及大约82K个实例输入和目标输出对。
观察到,结果数据提供了多种多样的创造性任务,其中50%以上的任务与种子指令的重合度低于0.3 ROUGE-L(§4.2)。
在这些结果数据上,通过微调GPT3(即用于生成指令数据的同一模型)来建立GPT3SELF-INST。
该工作的贡献在于:
1) SELF- INSTRUCT是一种用最少的人类标记的数据诱导指令跟随能力的方法;
2) 通过广泛的指令调整实验证明了它的有效性;
3) 发布了由52K指令组成的大型合成数据集和一组手工指令,通过广泛的指令调整实验证明了它的有效性;
4)发布了一个包含52000条指令的大型合成数据集和一组手工编写的新任务,用于建立和评估未来的指令模型。
二、指令生成框架基本流程
大规模的指令数据对人类来说是一个挑战,因为它需要:1)创造性地提出新的任务;2)为每个任务编写标记实例的专业知识。
SELF-INSTRUCT指的是用一个虚构的预训练语言模型本身生成任务的pipeline和自我训练,然后用这个生成的数据进行指令调整,以便使语言模型更好地遵循指令。

1、定义指令数据
想要生成的指令数据包含一组指令{},每条指令都用自然语言定义了一个任务。每个任务都有一个或多个输入输出实例(, )。
对于(, )∈(, ),一个模型被期望产生输出:(, ) = .
需要注意的是,在很多情况下,指令和实例输入并没有严格的边界。
例如,"写一篇关于学校安全的文章 "可以是一个有效的指令,希望模型能够直接响应,而它也可以被表述为 "写一篇关于下面这个主题的文章 "作为指令,而 "学校安全 "作为实例输入。
为了鼓励数据格式的多样性,我们允许这种不需要额外输入的指令(即为空)。
2、自动指令数据生成
生成指令数据的流程由四个步骤组成。1)指令生成,2)识别指令是否代表分类任务,3)用输入优先或输出优先的方法生成实例,4)过滤低质量数据。
1)指令生成
SELF-INSTRUCT是基于一个发现,即大型预训练的语言模型在遇到上下文中的一些现有指令时,可以被提示生成新的和新颖的指令,这提供了一种从一小部分人类编写的指令种子中扩充指令数据的方法。
因此,可以以引导的方式产生一个多样化的指令集。例如,利用作者编写的175个任务(每个任务有1条指令和1个实例)可以作为任务池。

对于每一步,从这个池子里抽出8条任务指令作为例子。在这8条指令中,6条来自人类编写的任务,2条来自前面步骤中的模型生成的任务,以促进多样性。
2)分类任务识别
因为需要两种不同的方法来处理分类和非分类任务,所以接下来要识别生成的指令是否代表分类任务。我们使用种子任务中的12条分类指令和19条非分类指令,提示预训模型进行区分,提示模板如下表所示:

3)实例生成
考虑到指令及其任务类型,需要为每个结构独立生成实例。这很有挑战性,因为它要求模型理解目标任务是什么,基于指令,找出需要哪些额外的输入字段并生成它们,最后通过生成输出来完成任务。
实验发现,当用其他任务中的指令-输入-输出的上下文例子提示时,预训练的语言模型可以在很大程度上实现这一点。
一个自然的方法是输入优先法,可以要求语言模型先根据指令想出输入字段,然后再产生相应的输出。这种生成顺序类似于模型用来响应指令和输入的方式,但这里有来自其他任务的例子。提示模板如下
所示:
不过,这种方法可以生成偏向于一个标签的输入,特别是对于分类任务,例如,对于语法错误检测,它通常生成语法输入。
因此,该工作为分类任务另外提出了一种输出优先的应用方法,即首先生成可能的类标签,然后根据每个类标签确定输入生成的条件,提示模板如下所示。

对前一步确定的分类任务采用输出优先方法,对其余非分类任务采用输入优先方法。
4)筛选和后处理
为了鼓励多样性,还需要对生成的指令进行筛选与后处理。
其中,主要有:
只有当一条新指令与任何现有指令的ROUGE-L重叠度小于0.7时,才会被添加到任务池中。
排除了包含一些特定关键词(如图像、图片、图表)的指令,这些关键词通常不能被语言模型处理。
在为每条指令生成新的实例时,过滤掉那些完全相同的实例或那些具有相同输入但不同输出的实例。
到此,我们就可以生成多个正确样例,如下所示:

当然,也包括一些错误样例,如下所示:

3、对LM进行微调以遵循指令
在创建了大规模的指令数据后,用这些数据来微调原始语言模型(即SELF-INSTRUCT)。
为了做到这一点,将指令和实例输入作为一个提示,并训练模型以标准的监督方式生成实例输出。
为了使模型对不同的格式具有鲁棒性,使用多个模板来对指令和实例输入进行编码。
例如,指令的前缀可以是 "任务:",也可以不是,输入的前缀可以是 "输入:",也可以不是,"输出:"可以附加在提示的末尾,中间可以有不同数量的分隔线。
三、SELF-INSTRUCT数据生成效果分析
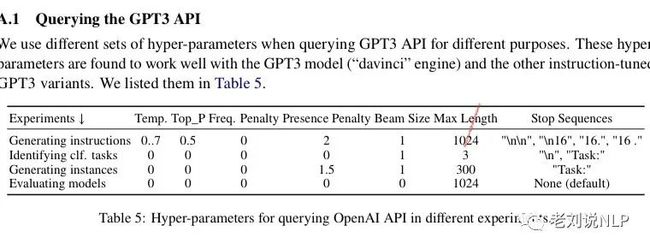
在具体实验上,该工作使用最大的GPT3语言模型("davinci "引擎)通过OpenAI API5访问,进行查询的参数做具体的设定,即针对不同的任务形式有不同的参数设定,具体如下:
1、统计数据
下表描述了生成数据的基本统计数据,总共产生了超过52K条指令,以及超过82K条与这些指令相对应的实例:

2、多样性分析
为了研究产生了哪些类型的指令以及它们的多样性,该工作确定了所产生的指令中的动词-名词结构。
在具体实现上使用伯克利神经解析器(Kitaev和Klein,2018;Kitaev等人,2019)来解析指令,然后提取最接近解析树根的动词以及它的第一个直接名词对象。
实验发现,在52,445条指令中,有26,559条包含这样的结构;其他指令通常包含更复杂的子句(例如,"对这条推文是否包含政治内容进行分类。")或被框定为问题(例如,"这些语句中哪些是真的?")。
例如,图2中绘制了前20个最常见的根动词和它们的前4个直接名词对象,这占了整个集合的14%。例如,write后面常接letter、essay、paragraph以及function。

从中我们可以看到有相当多样化的意图和文本格式。
进一步的,我们还可以研究生成的指令与用于提示生成的种子指令有何不同,对于每个生成的指令,我们计算其与175条种子指令的最高ROUGE-L重叠度。

图3中绘制了这些ROUGE-L得分的分布情况,表明有相当数量的新指令与种子指令没有太多重叠。
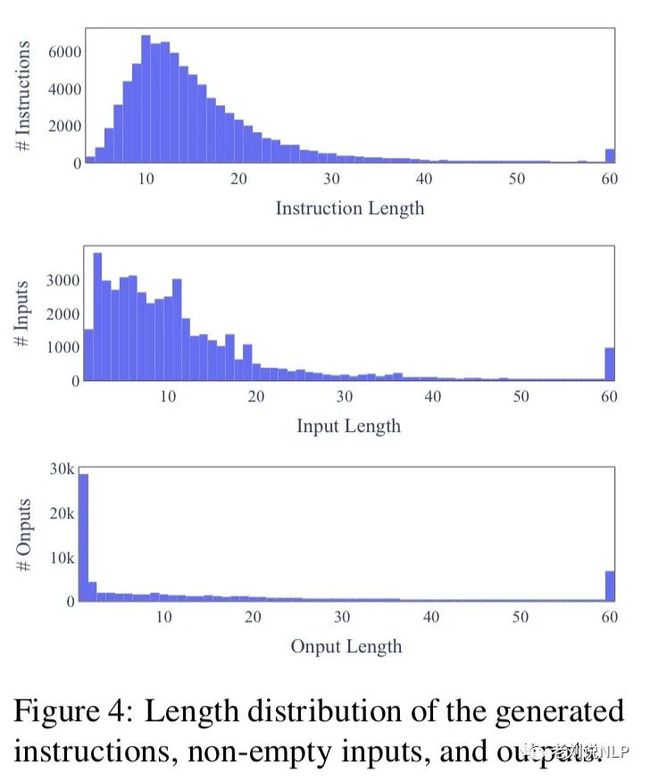
图4中展示了指令、实例输入和实例输出的长度多样性。
3、指令生成的质量
除了研究生成数据的数量和多样性之外,还需要进一步研究其质量。为了研究这个问题,该工作随机抽取了200条指令,并在每个结构中随机选择一个实例。
为了保证公平性,请一位专家标注(这项工作的共同作者)从指令、实例输入和实例输出的角度来标注每个实例是否正确,结果如表2所示:

表2的评估结果显示,大多数生成的指令是有意义的,而生成的实例可能包含更多的噪音(在合理的范围内),不过,即使生成的指令可能包含错误,但大多数指令的格式仍然是正确的,甚至是部分正确的,这可以为训练模型遵循指令提供有用的指导。
四、指令微调的实验结果
利用下游任务来衡量数据质量是一个重要的途径,下面通过实验来衡量和比较各种指令调整设置下的模型质量。
1、GPT3SELF-INST
对GPT3自身的指令数据进行微调,利用指令生成的指令数据,该工作对GPT3模型本身("davinci "引擎)进行指令调优,这种微调通过OpenAI的微调API完成,使用默认的超参数,除了将提示损失权重设置为0,并对模型进行2次训练,最终所得到的模型被表示为GPT3SELF-INST。
2、模型对此选择
首先,在基线语言模型中,该工作以T5-LM(Lester等人,2021年;Raffel等人,2020年)和GPT3(Brown等人,2020年)作为普通的LM基线(只有预训练,没有额外的微调)。
这些基线将表明现成的LM在多大程度上能够在预训练后立即自然遵循指令。
其次,在公开可用的指令调整模型上,T0和T-INSTRUCT是Sanh等人(2022)和Wang等人(2022)分别提出的两个指令调优模型,并被证明能够遵循许多NLP任务的指令,这两个模型都是从T5(Raffel等人,2020)检查点微调的,并且公开可用,对于这两个模型,使用其最大版本的11B参数。
最后,在指令微调的GPT3模型上,评估了InstructGPT(Ouyang等人,2022),它是由OpenAI基于GPT3开发的,以更好地遵循人类指令,并被社区发现具有令人印象深刻的零点能力。
为了将SELF-INSTRUCT训练与其他公开可用的指令调整数据进行比较,我们用PROMPTSOURCE和SUPERNI的数据进一步微调GPT3模型,这些数据被用于训练T0和T-INSTRUCT模型。并分别命名为T0 Traning和SUPERNI Training。
为了节省训练预算,对每个数据集取样50K实例(但涵盖其所有的结构内),其规模与生成的指令数据相当。
根据Wang等人(2022)的研究结果和早期实验,减少每个任务的实例数量并不会降低模型对未见过的任务的泛化性能。
3、SUPERNI基准评估实验
该工作首先评估了模型在典型的NLP任务中的zero-shot能力,使用SUPERNI(Wang等人,2022)的评估集,它由119个任务组成,每个任务有100个状态。

从表3的结果中可以得出以下结果:
首先,SELF-INSTRUCT在很大程度上提高了GPT3的指令遵循能力。普通的GPT3模型基本上完全不能遵循人类的指令,经过人工分析,我们发现它通常会产生不相关的和重复的文本,并且不知道什么时候停止生成。
其次,与其他没有专门为SUPERNI训练的模型相比,GPT3SELF-INST取得了比T0或T0训练集上的GPT3微调更好的表现,这需要巨大的人工标注努力。值得注意的是,GPT3SELF-INST很快就超越了InstructGPT001的表现,后者是用私人用户数据和人类标注的标签训练的。
最后, 在SUPERNI训练集上训练的模型仍然在其评估集上取得了更好的性能,可以将此归因于类似的指令风格和格式。然而,实验也表明,当SELF- INSTRUCT与SUPERNI训练集结合时,仍然带来了额外的收益,证明了其作为补充数据的价值。
4、通用面向用户的新任务指示实验
尽管SUPERNI在收集现有的NLP任务方面很全面,但这些NLP任务大多是为研究目的而提出的,并偏重于分类。
为了更好地获取指令跟踪模型的实用价值,一部分作者构思了一套由面向用户的应用驱动的新指令。
具体的:
首先对大型LM可能有用的不同领域(例如,电子邮件写作、社交媒体、生产力工具、娱乐、编程)进行头脑风暴,然后制作与每个领域相关的指令以及输入-输出实例(同样,输入是可选的)。
目标是使这些任务的风格和格式多样化(例如,指令可长可短;输入/输出可采取要点、表格、代码、方程式等形式)。
该工作总共创建了252个指令,每个指令有1个实例,这些指令可以作为一个测试平台来评估基于指令的模型如何处理不同的和不熟悉的指令。
不过,由于不同的任务需要不同的专业知识,因此评估模型在这组不同任务上的表现是极具挑战性的,因为事实上,许多任务不能用自动指标来衡量,甚至不能由正常的群众工作者来判断(例如,写程序,或将一阶逻辑转换为自然语言)。

表4列出了252个任务中的一小部分,从中可以看到输入输出以及GPT3自己的生成结果。
为了得到更忠实的评价,要求说明的作者对模型的预测进行判断评价者被要求根据输出是否准确和有效地完成任务来评分。
如表4所示,该工作采用实施了一个四级评级系统来对模型的输出质量进行分类,定义如下:
评级-A:反应是有效的,令人满意的。
评级-B:反应是可接受的,但有轻微的错误或不完善之处,可以改进。证明。
评级-C。该反应是相关的,并且重新响应指令,但在内容上有重大错误。
例如,GPT3可能首先产生一个有效的输出,但继续产生其他不相关的东西。
评分-D:响应是不相关的或无效的,包括重复输入,完全不相关的输出等。
图5提供了GPT3模型及其指令调整后的对应模型在这个新编写的指令集上的表现。

可以看到:
首先,GPT3SELF-INST(即用SELF-INSTRUCT微调的GPT3模型)在很大程度上超过了那些在T0或SUPERNI上训练的对应模型,证明了尽管有噪音,但生成的数据还是有价值的。
其次,与InstructGPT001相比,GPT3SELF-INST的表现相当接近--如果把有轻微缺陷的可接受的反应(RATING-3)算作有效,GPT3SELF-INST只比InstructGPT001低5%。
五、SELF-INSTRUCT方法的思考
1、为什么有效
为什么SELF-INSTRUCT能发挥作用?值得反思的是,高质量的人类反馈在促成最近关于指令调整LM的成功方面所发挥的作用究竟如何。
这里有两个极端的假说。
其一,人的反馈是指令调整的一个必要的和不可分割的方面,因为LM需要了解在预培训中没有完全学会的问题。
其二,人类反馈是指令调整的一个可选的方面,因为LM在预训练中已经对指令非常熟悉了。观察人类的反馈只是一个轻量级的过程,用于调整他们的预训练分布/目标,可能会被不同的过程所取代。
虽然现实情况可能介于这两个极端之间,但实验猜测它更接近于2,特别是对于较大的模型。这种直觉,即LM已经知道很多语言指令,是SELF- INSTRUCT的一个关键动机,也得到了其经验性成功的支持。
此外,SELF-INSTRUCT可能有助于使广泛使用的指令调整模型(如InstructGPT)的 "幕后 "情况更加透明。
不幸的是,这些工业模型仍然在API墙后面,因为它们的数据集没有被公布,因此人们对它们的构造以及它们为什么表现出令人印象深刻的能力了解甚少。
2、SELF-INSTRUCT的局限性
首先,长尾现象。SELF-INSTRUCT依赖于LMs,它将继承LMs带来的所有限制。正如最近的研究表明(Razeghi等人,2022;Kandpal等人,2022),长尾现象对LMs的成功构成严重挑战。换句话说,LMs的最大收益对应于语言的频繁使用(语言使用分布的头部),而在低频语境中的收益最小。
同样,在这项工作的背景下,如果SELF-INSTRUCT的大部分收益都偏向于在预训练语料库中更频繁出现的任务或指令,那也不会令人惊讶。因此,该方法在不常见的和创造性的指令方面可能会表现得很脆弱。
其次,大型模型的依赖性。由于SELF- INSTRUCT依赖于从LM中提取的归纳偏见,它可能对较大的模型。如果是真的,这可能会对那些可能没有大型计算资源的人造成障碍。值得注意的是,有人类注释的指令调整也有类似的限制:指令调整的收益在较大的模型中更高(Wei等人,2022)。
最后,强化LM的偏见。这种迭代算法会带来非预期后果。迭代算法的意外后果,如放大有问题的社会偏见(对性别、种族等的刻板印象或诽谤)。与此相关的是,在这个过程中观察到的一个挑战是,该算法很难产生平衡的标签,这反映了模型的先前偏见。我们希望未来的工作能够解决这些细节问题,以更好地了解该方法的优点和缺点。
六、项目的开源实现
在实践环节,我们注意到SELF-INSTRUCT的实现代码以及样例数据已经开放,地址:https://github.com/yizhongw/self-instruct
大家可以阅读论文后根据自己的需求,借鉴其中的instruction数据或者生成方法,应用于自己的工作当中。

1、项目整体执行流程
# 1. Generate instructions from the seed tasks
./scripts/generate_instructions.sh
# 2. Identify whether the instruction represents a classification task or not
./scripts/is_clf_or_not.sh
# 3. Generate instances for each instruction
./scripts/generate_instances.sh
# 4. Filtering, processing, and reformatting
./scripts/prepare_for_finetuning.sh2、指令种子样例
{
"id": "seed_task_0",
"name": "breakfast_suggestion",
"instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?",
"instances":
[
{
"input": "",
"output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."}
],
"is_classification": false
}总结
文章《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》一文提出了SELF-INSTRUCT,一个通过引导生成预训练的语言模型来提高其指令跟随能力的框架,该框架从语言模型中生成指令、输入和输出样本,然后在使用它们来微调原始模型之前对它们进行过滤。
本文对该代表性的工作进行研读,并给出工作开源项目地址,大家可以阅读论文后根据自己的需求,借鉴其中的instruction数据或者生成方法,应用于自己的工作当中。
参考文献
1、https://arxiv.org/pdf/2212.10560v1.pdf:Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A.Self-Instruct: Aligning Language Model with Self Generated Instructions
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。
进NLP群—>加入NLP交流群
持续发布自然语言处理NLP每日优质论文解读、相关一手资料、AI算法岗位等最新信息。
加入星球,你将获得:
1. 每日更新3-5篇最新最优质的的论文速读。用几秒钟就可掌握论文大致内容,包含论文一句话总结、大致内容、研究方向以及pdf下载。
2. 最新入门和进阶学习资料。包含机器学习、深度学习、NLP等领域。
3. 具体细分NLP方向包括不限于:情感分析、关系抽取、知识图谱、句法分析、语义分析、机器翻译、人机对话、文本生成、命名实体识别、指代消解、大语言模型、零样本学习、小样本学习、代码生成、多模态、知识蒸馏、模型压缩、AIGC、PyTorch、TensorFlow等细方向。
4. 每日1-3个NLP、搜广推、CV等AI岗位招聘信息。可安排模拟面试。
