数据结构与算法初学习(超长干货持续更新)
文章目录
- 前言
- 一、判断一个“好”算法的标准
- 二、时间复杂度
-
- 1.示例一
- 2.示例二
- 总结
- 三、空间复杂度
-
- 1.示例一
- 2.示例二
- 3.总结
- 四、链表
-
- 概念:
- 优缺点
- 分类
- 创建链表
- 五、栈
-
- 基本概念
- 二、分类:
- 基本操作
- C++中常用内置函数
- 创建栈
- 六、向量
-
- 基本概念
- 初始化
- 常用内置函数
- 运用
-
- 1.常见错误
- 2.查找
- 3算法
- 七、队列
-
- 基本概念
- 常用内置函数
- 参阅资料
- 八、集合
-
- 参阅资料
- 九、并查集
-
- 参阅资料
- 十、STL中的map
-
- 参阅资料
- 十一、二叉树
-
- 参阅资料
- 十二、树状数组
-
- 参阅资料
- 十三、线段树
-
- 参阅资料
- 十四、主席树
-
- 参阅资料
- 十五、动态规划dp
-
- 参阅资料
- 十六、图论
-
- 图的基本概念
-
- 图的分类
- 路径
- 欧拉图
-
- 欧拉解析
- 拓扑排序
- 二分图
-
- KM算法
- 十七、 网络流
-
- 参阅资料
- 十八、哈密顿图
-
- 参阅资料
- 十九、Hash
-
- 定义
- 参阅资料
- 二十、KMP算法
-
- 参阅资料
- 二十一、字典树
-
- 参阅资料
- 二十二、AC自动机
-
- 参阅资料
- 二十三、后缀数组
-
- 参阅资料
- 二十四、排列组合
-
- 前景知识回顾
-
- 补充:圆排列
- 排列组合常用公式
- 排列问题代码运用
-
- 容斥问题
- 错排
- 二十五、逆元
-
- 逆元介绍
- 参阅资料
- 二十六、博弈
-
- 巴什博弈
- 威佐夫博弈
- 尼姆博奕
- 斐波那契博弈
- 公平组合博弈(ICG)
- 二十七、素数与欧拉函数
-
- 参阅资料
- 二十八、中国剩余定理
-
- 参阅资料
- 二十九、莫比乌斯反演
- 参阅资料
- 三十、组合数学
-
- 参阅资料
- 计算几何
-
-
- 前景知识体系
- 编程入门
- 编程练习
-
- 附录
-
- C++ STL讲解
前言
在学习具体的数据结构和算法之前,每一位初学者都要掌握一个技能,即善于运用时间复杂度和空间复杂度来衡量一个算法的运行效率。
所谓算法,即解决问题的方法。同一个问题,使用不同的算法,虽然得到的结果相同,但耗费的时间和资源肯定有所差异
一、判断一个“好”算法的标准
解决一个问题的方法可能有很多,但能称得上算法的,首先它必须能彻底解决这个问题(称为准确性),且根据其编写出的程序在任何情况下都不能崩溃(称为健壮性)。
注意,程序和算法是完全不同的概念。算法是解决某个问题的想法、思路;而程序是在根据算法编写出来的真正可以运行的代码。例如,要依次输出一维数组中的数据元素的值,首先想到的是使用循环结构,在这个算法的基础上,我们才开始编写程序。
在满足准确性和健壮性的基础上,还有一个重要的筛选条件,即通过算法所编写出的程序的运行效率。程序的运行效率具体可以从 2 个方面衡量,分别为:
程序的运行时间。
程序运行所需内存空间的大小。
根据算法编写出的程序,运行时间更短,运行期间占用的内存更少,该算法的运行效率就更高,算法也就更好。
那么,如何衡量一个算法所编写出程序的运行效率呢?
数据结构中,用时间复杂度来衡量程序运行时间的多少;用空间复杂度来衡量程序运行所需内存空间的大小。
二、时间复杂度
判断一个算法所编程序运行时间的多少,并不是将程序编写出来,通过在计算机上运行所消耗的时间来度量。原因很简单,一方面,解决一个问题的算法可能有很多种;另一方面,不同计算机的软、硬件环境不同,即便使用同一台计算机,不同时间段其系统环境也不相同,程序的运行时间很可能会受影响,严重时甚至会导致误判。
实际场景中,我们更喜欢用一个估值来表示算法所编程序的运行时间。所谓估值,即估计的、并不准确的值。
那么,如何预估一个算法所编程序的运行时间呢?很简单,先分别计算程序中每条语句的执行次数,然后用总的执行次数间接表示程序的运行时间。
1.示例一
for(int i = 0 ; i < n ; i++) //从 0 到 n,执行 n+1 次
{
a++; // 从 0 到 n-1,执行 n 次
}
可以看到,这段程序中仅有 2 行代码,其中:
for 循环从 i 的值为 0 一直逐增至 n(注意,循环退出的时候 i 值为 n),因此 for 循环语句执行了 n+1 次;
而循环内部仅有一条语句,a++ 从 i 的值为 0 就开始执行,i 的值每增 1 该语句就执行一次,一直到 i 的值为 n-1,因此,a++ 语句一共执行了 n 次。
因此,整段代码中所有语句共执行了 (n+1)+n 次,即 2n+1 次。数据结构中,每条语句的执行次数,又被称为该语句的频度。整段代码的总执行次数,即整段代码的频度。
2.示例二
for(int i = 0 ; i < n ; i++) // n+1
{
for(int j = 0 ; j < m ; j++) // n*(m+1)
{
num++; // n*m
}
}
我们可以计算得此段程序的频度为:(n+1)+n*(m+1)+n*m,简化后得 2 * n * m+2 *n+1。值得一提的是,不同程序的运行时间,更多场景中比较的是在最坏条件下程序的运行时间。以上面这段程序为例,最坏条件即指的是当 n、m 都为无限大时此段程序的运行时间。
要知道,当 n、m 都无限大时,我们完全就可以认为 n==m。在此基础上,2 * n * m+2* n+1 又可以简化为 2* n* n+2*n+1,这就是此段程序在最坏情况下的运行时间,也就是此段程序的频度。
如果比较以上 2 段程序的运行时间,即比较 2n+1 和 2* n* n+2*n+1 的大小,显然当 n 无限大时,前者要远远小于后者(如图 2 所示)。
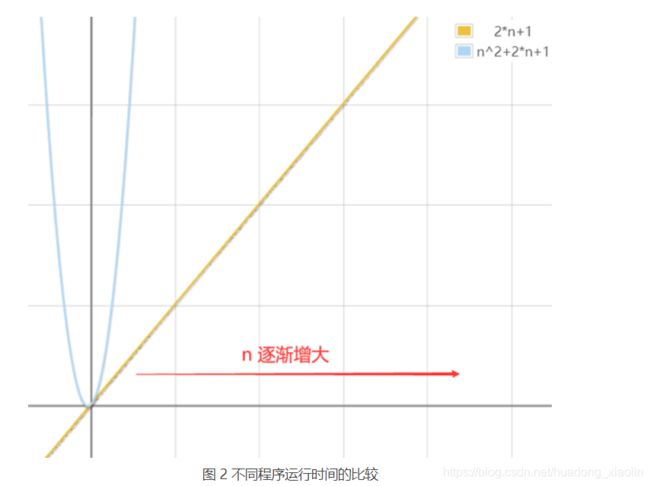
显然,第 1 段程序的运行时间更短,运行更快。
思考一个问题,类似 2n+1、 2* n* n+2n+1 这样的频度,还可以再简化吗?答案是肯定的。
以 2n+1 为例,当 n 无限大时,是否在 2n 的基础上再做 +1 操作,并无关紧要,因为 2n 和 2n+1 当 n 无限大时,它们的值是无限接近的。甚至于我们还可以认为,当 n 无限大时,是否给 n 乘 2,也是无关紧要的,因为 n 是无限大,2 * n 也是无限大。
再以无限大的思想来简化 2 n* n+2n+1。当 n 无限大的:
首先,常数 1 是可以忽略不计的;
其次,对于指数级的 2n2 来说,是否在其基础上加 2n,并无关紧要;
甚至于,对于是否给 n2 乘 2,也可以忽略。
因此,最终频度 2n2+2*n+1 可以简化为 n * 2 。
依据“使用无限大的思想”简化频度表达式,在数据结构中,频度表达式可以这样简化:
1.去掉频度表达式中,所有的加法常数式子。例如2n+1 简化为 2n ;
2.如果表达式有多项含有无限大变量的式子,只保留一个拥有指数最高的变量的式子。例如 2n*n+2n 简化为 2n *n;
3.如果最高项存在系数,且不为 1,直接去掉系数。例如 2n *n 系数为 2,直接简化为 n *n ;
事实上,对于一个算法(或者一段程序)来说,其最简频度往往就是最深层次的循环结构中某一条语句的执行次数。
例如 2n+1 最简为 n,实际上就是 a++ 语句的执行次数;同样 2 * n * n+2 *n+1 简化为 n *n,实际上就是最内层循环中 num++ 语句的执行次数。
在得到最简频度的基础上,为了避免人们随意使用 a、b、c 等字符来表示运行时间,需要建立统一的规范。数据结构推出了大 O 记法(注意,是大写的字母 O,不是数字 0)来表示算法(程序)的运行时间。
大 O 记法的表示方法也很简单,格式如下:
O(频度)
其中,这里的频度为最简之后所得的频度。
例如,用大 O 记法表示上面 2 段程序的运行时间,则上面第一段程序的时间复杂度为 O(n),第二段程序的时间复杂度为 O(n*n)。
如下列举了常用的几种时间复杂度,以及它们之间的大小关系:
O(1)常数阶 < O(logn)对数阶 < O(n)线性阶 < O(n2)平方阶 < O(n3)(立方阶) < O(2n) (指数阶)
总结
复杂度分析法则
1)单段代码看高频:比如循环。
2)多段代码取最大:比如一段代码中有单循环和多重循环,那么取多重循环的复杂度。
3)嵌套代码求乘积:比如递归、多重循环等
4)多个规模求加法:比如方法有两个参数控制两个循环的次数,那么这时就取二者复杂度相加。
三、空间复杂度
表示算法的存储空间与数据规模之间的增长关系。
和时间复杂度类似,一个算法的空间复杂度,也常用大 O 记法表示。
要知道每一个算法所编写的程序,运行过程中都需要占用大小不等的存储空间,例如:
程序代码本身所占用的存储空间;
程序中如果需要输入输出数据,也会占用一定的存储空间;
程序在运行过程中,可能还需要临时申请更多的存储空间。
程序运行过程中输入输出的数据,往往由要解决的问题而定,即便所用算法不同,程序输入输出所占用的存储空间也是相近的。
事实上,对算法的空间复杂度影响最大的,往往是程序运行过程中所申请的
临时存储空间不同的算法所编写出的程序,其运行时申请的临时存储空间通常会有较大不同。
1.示例一
int n;
scanf("%d", &n);
int a[10];
通过分析不难看出,这段程序在运行时所申请的临时空间,并不随 n 的值而变化。而如果将第 3 行代码改为:
int a[n];
此时,程序运行所申请的临时空间,和 n 值有直接的关联。所以,如果程序所占用的存储空间和输入值无关,则该程序的空间复杂度就为 O(1);反之该段代码的空间复杂度就是O(n)。
2.示例二
void print(int n) {
int i=0;
int[] a = new int[n];
for (i; i <n; ++i) {
a[i] =i* i;
}
for(i=n-1;i>=0;--i){
print out a[i]
}
}
我们可以看到,第2行代码中,我们申请了一个空间存储变量i,但是它是常量阶的,跟数据规模n没有关系,所以我们可以忽略。第3行申请了一个大小为n的int类型数组,除此之外,剩下的代码都没有占用更多的空间,所以整段代码的空间复杂度就是O(n)。
反之,如果有关,则需要进一步判断它们之间的关系:
如果随着输入值 n 的增大,程序申请的临时空间成线性增长,则程序的空间复杂度用 O(n) 表示;
如果随着输入值 n的增大,程序申请的临时空间成 n平方 关系增长,则程序的空间复杂度用 O(n2) 表示;
如果随着输入值 n 的增大,程序申请的临时空间成n立方关系增长,则程序的空间复杂度用 O(n3) 表示; 等等。
附图
3.总结
我们常见的空间复杂度就是O(1)、O(n)、 O(n2), 像O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到。所以空间复杂度分析比较容易
四、链表
概念:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。链表在插入的时候可以达到O(1)的复杂度,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间。
![]()
优缺点
链表的优点在于:
1.物理存储单元上非连续,而且采用动态内存分配,能够有效的分配和利用内存资源;
2.节点删除和插入简单,不需要内存空间的重组
链表的缺点在于:
1.不能进行索引访问,只能从头结点开始顺序查找;
2.数据结构较为复杂,需要大量的指针操作,容易出错
分类
单链表:它有一个表头,并且除了最后一个结点外,所有结点都有其后继节点
双向链表:它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
循环链表:在双向链表的基础上做了优化,表中最后一个结点的指针域指向头结点,整个链表形成一个环。
静态链表:用数组来描述的链表,这种描述方法便于在没有指针类型的高级程序设计语言中使用链表结构
创建链表
如何创建一个链表及相应操作(创建,添加,删除,查询,销毁)
五、栈
基本概念
栈:一种特殊的线性表,其实只允许在固定的一端进行插入或删除操作。进行数据插入和删除的一端称为栈顶,另一端称为栈底。不含任何元素的栈称为空栈,栈又称为 后进先出的线性表。

二、分类:
1静态栈:使用数组
2动态栈:使用链表
基本操作
入栈,出栈,遍历栈(栈的大小),栈顶元素
C++中常用内置函数
#include创建栈
数据结构之链栈基本操作的实现代码及解(C语言描述)
六、向量
基本概念
vector 是向量类型,它可以容纳许多类型的数据(int,double,string,结构体 ,如若干个整数,所以称其为容器。vector 是C++ STL的一个重要成员,使用它时需要包含头文件:#include
vector 容器的长度不固定,能够在程序运行时动态地改变。
初始化
vector<int> a//(尖括号为元素类型名,它可以是任何合法的数据类型)
//定义具有10个整型元素的向量,不具有初值,其值不确定
vector<int>a(10);
//定义具有10个整型元素的向量,初值为1
vector<int>a(10,1)
//用向量b给向量a赋值,a的值完全等价于b的值
vector<int>a(b);
//将向量b中从0-2(共三个)的元素赋值给a,a的类型为int型
vector<int>a(b.begin(),b.begin()+3);
//从数组中获得初值
int b[7]={1,2,3,4,5,6,7};
vector<int> a(b,b+7);
常用内置函数
#include运用
1.常见错误
vector<int>a;
for(int i=0;i<10;++i){a[i]=i;}//下标只能用来获取已经存在的元素
2.查找
int a[6]={1,2,3,4,5,6};
vector<int>b(a,a+4);
//利用数组
for(int i=0;i<=b.size()-1;++i){cout<<b[i]<<" ";}
//利用迭代器
for(vector<int>::iterator it=b.begin();it!=b.end();it++){
cout<<*it<<" ";}
3算法
#include七、队列
基本概念
队列也是一种线性表,是一种先进先出的线性结构。队列只允许在表的一端进行插入即入队、删除即出队操作。允许插入的一端称为队尾,允许删除的一端称为队头
常用内置函数
#include参阅资料
队列讲解
八、集合
特点 不会存在有重复的元素,特殊的容器
参阅资料
C++集合
九、并查集
参阅资料
并查集与带权并查集
十、STL中的map
参阅资料
map详解
十一、二叉树
参阅资料
二叉树及其基本操作
十二、树状数组
参阅资料
树状数组
十三、线段树
参阅资料
线段树
讲解及练习题
十四、主席树
参阅资料
静态主席树
动态主席树
十五、动态规划dp
参阅资料
动态规划
十六、图论
小白学图论
知识体系图
图论进阶,内含竞赛题
图的基本概念

图的分类
有向图 无向图
带权图 无权图
连通图
二分图

7-8,3-6,1-2-5-4均为连通分量
路径
路径是由边顺序连接的一系列顶点。简单路径是一条没有重复顶点的路径。环是一条至少含有一条边且起点和终点相同的路径。简单环是一条(除了起点和终点必须相同之外)不含有重复顶点和边的环。路径或者边的长度为其中所包含的边数。
欧拉图
欧拉解析
欧拉图详解
拓扑排序
二分图
KM算法
KM算法用来求二分图最大权完美匹配。
入门KM算法
km算法的简单应用小例子
十七、 网络流
参阅资料
acm网络流入门
最小费用流问题
十八、哈密顿图
参阅资料
哈密顿图
十九、Hash
定义
Hash中文翻译为散列,又成为“哈希”,是一类函数的统称,其特点是定义域无限,值域有限。把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
参阅资料
字符串哈希
哈希算法详解
Manacher的动画演示
二十、KMP算法
核心:求最长前后缀相同长度,即next[]数组
参阅资料
kmp算法详解
超长详解
二十一、字典树
参阅资料
字典树及ac自动机
二十二、AC自动机
参阅资料
算法详解
模板
二十三、后缀数组
参阅资料
参考0快速上手
参考1偏图解
参考2偏代码
参考3详细
二十四、排列组合
前景知识回顾
排列组合回顾
补充:圆排列

此外还有二次项定理等
排列组合常用公式
排列组合常见公式
排列问题代码运用
排列的字典序问题
全排列问题
全排列问题2
全排列(允许有重复元素)
笔试面试算法经典–全排列算法-递归&字典序实现(Java)
容斥问题
容斥理论
容斥代码
理论加代码
错排
详解
俩者结合
二十五、逆元
建议先了解线性同余方程,欧几里德及其扩张,裴蜀定理!!!
逆元介绍
通俗易懂
内含例题
hdu1576
参阅资料
逆元及几种求法
方法一:扩展欧几里得算法
方法二:费马小定理/欧拉定理
方法三:递推求逆元
二十六、博弈
巴什博弈
●问题模型:
●只有一堆n个物品,两个人轮流从这堆物品中取物,规定每次至少取一个,最多取m个,最后取光者得胜。
威佐夫博弈
●问题模型
●有两堆各若干个物品,两个人轮流从某一堆或同时从两堆中取同样多的物品,规定每次至少取一个,多者不限,最后
取光者得胜。
●解决思路
判断当前局势是否为非奇异局势或者奇异局势即可。
a[k] = └k*(1+√5)/2┘,b[k] = a[k] + k
●结论
由上述性质可知,如果双方都采取正确操作,那么面对非奇异局势,先取者必胜;反之,面对奇异局势,后取者必胜。
尼姆博奕
●问题模型
●有N堆石子。A B两个人轮流拿,A先拿。每次只能从一堆中取若干个,可将一堆全取走,但不可不取,拿到最后1颗
石子的人获胜。假设A B都非常聪明,拿石子的过程中不会出现失误。给出N及每堆石子的数量,问最后谁能赢得比
赛。
●结论
一个必败局面(奇异局势)无论做出何种操作,最终结果都是输的局面。必败局面经过2次操作后,可以达到另一个必败局面。一个必胜局面(非奇异局势)经过1次操作后一定可以达到必败局面(奇异局势)。
所有物品数目二进制异或结果为0,此时为必败局面(奇异局势),则先手必输。
所有物品数目二进制异或不为0,此时为必胜局面(非奇异局势),一次操作后一定可以转为必败局面,则后手必输。
斐波那契博弈
问题模型
●有一堆个数为n的石子,游戏双方轮流取石子,满足:(1)先手不能在第一次把所有的石子取完;(2)之后每次可
以取的石子数介于1到对手刚取的石子数的2倍之间(包含1和对手刚取的石子数的2倍)。 约定取走最后一个石子的
人为赢家。
●结论
●当n为Fibonacci数时,先手必败。即存在先手的必败态当且仅当石头个数为Fibonacci数。
公平组合博弈(ICG)
●定义
●(1)两人参与。
●(2)游戏局面的状态集合是有限。
●(3)对于同一个局面,两个游戏者的可操作集合完全相同
●(4)游戏者轮流进行游戏。
●(5)当无法进行操作时游戏结束,此时不能进行操作的一方算输。
●(6)无论游戏如何进行,总可以在有限步数之内结束。
二十七、素数与欧拉函数
素数定义:素数又称质数。一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数(规定1既不是质数也不是合数)。
欧拉函数定义:
●问题:
任意给定正整数n,请问在小于等于n的正整数之中,有多少个与n构成互质关系?(比如,在1到8之中,有多少个数与8构成互质关系?)
计算这个值的方法就叫做欧拉函数,以φ(n)表示。在1到8之中,与8形成互质关系的是1、3、5、7,
所以 φ(n) = 4。
参阅资料
浅谈欧拉函数
数论基础,欧拉函数
二十八、中国剩余定理
参阅资料
通俗易懂
详解
例题及解
二十九、莫比乌斯反演
参阅资料
入门详解
三十、组合数学
参阅资料
知识点加模板大全
附习题
卢卡斯定理
计算几何
前景知识体系
平面直角坐标系
向量及其运算
三角剖分求面积
参阅资料之计算几何初步
编程入门
计算几何(一)入门须知
计算几何(二)——点与向量
计算几何(三)——直线与线段
计算几何(四)——多边形和圆
计算几何(五)——凸包
计算几何(六)——平面交
编程练习
题单
附录
C++ STL讲解
通常认为,STL 是由容器、算法、迭代器、函数对象、适配器、内存分配器这 6 部分构成,其中后面 4 部分是为前 2 部分服务的
STL C语言中文学习网