《RAFT:Recurrent All-Pairs Field Transforms for Optical Flow》论文笔记
参考代码:RAFT
作者主页:Zachary Teed
1. 概述
导读:这篇文章提出了一种新的光流估计pipline,与之前介绍的PWC-Net类似其也包含特征抽取/correlation volume构建操作。在这篇文章中为了优化光流估计,首先在correlation volume的像素上进行邻域采样得到lookups特征(增强特征相关性,也可以理解为感受野),之后直接使用以CNN-GRU为基础的迭代优化网络,在完整尺寸上对光流估计迭代优化。这样尽管采用了迭代优化的形式,文章的迭代优化机制也比像IRR/FlowNet这类方法轻量化,运行速度也更快,其可以在1080 TI GPU上达到10FPS(输入为 1088 ∗ 436 1088*436 1088∗436)。文章的算法在诸如特征处理与融合/上采样策略上设计得细致合理,并且使用迭代优化的策略,从而使得文章算法具有较好的泛化性能。
将文章的方法与之前的一些方法作对比,可以将其中对比得到的改进点归纳如下:
- 1)抛弃了类似PWC-Net中的coarse-to-fine的光流迭代优化策略,直接生成全尺寸的光流估计,从而避免了这种优化策略带来的弊端:coarse层次的预测结果会天然增加丢失小而快速运动的目标的风险,并且训练需要的迭代次数也更多;
- 2)为了提升光流估计的准确性,一种可行的方式就是进行module的叠加优化,如FlowNet和IRR等,但是这样的操作一个是带来更多的参数量,增加运算的时间。还会使得整个网络的训练过程变得繁琐冗长;
- 3)光流的更新模块,文章使用以CNN-GRU为基础,在4D的correlation volume上对其采样得到的correlation lookups进行运算,从而得到光流信息。这样的更新模块引入了GRU网络,很好利用了迭代优化的时序特性;
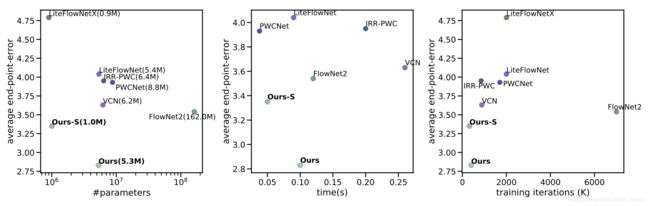
将文章的方法与其它的一些光流估计方法进行比较:
2. 方法设计
2.1 整体pipline
文章的整体pipeline如下:
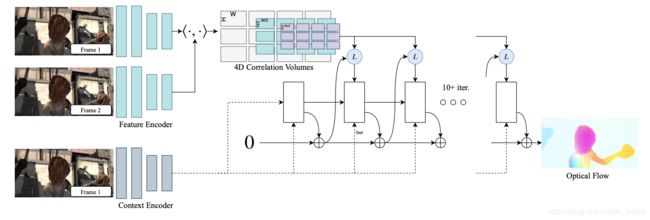
按照上图所示可以将整体pipeline划分为3个部分(阶段):
- 1)feature encoder进行输入图像的抽取,以及context encoder进行图像特征的抽取;
- 2)使用矩阵相乘的方式构建correlation volume,之后使用池化操作得到correlation volume pyramid;
- 3)对correlation volume在像素邻域上进行采样,之后使用以CNN-GRU为基础构建的光流迭代更新网络进行全尺寸光流估计;
文章按照网络容量的不同设计了一大一小的两个网络,后面的内容都是以大网络为基准,其网络结构为:

文章的整体流程简洁,直接在一个forawrd中完成了所有操作,其具体的步骤可以归纳为:
# core/raft.py#86
# step1:图像1/2的feature encoder特征抽取
fmap1, fmap2 = self.fnet([image1, image2]) # [N, 256, H//8, W//8]
# step2:correlation volume pyramid构建
if self.args.alternate_corr:
corr_fn = AlternateCorrBlock(fmap1, fmap2, radius=self.args.corr_radius)
else:
corr_fn = CorrBlock(fmap1, fmap2, radius=self.args.corr_radius) # 输入两幅图像特征用于构造金字塔相似矩阵
# step3:图像1的context encoder特征抽取
cnet = self.cnet(image1)
net, inp = torch.split(cnet, [hdim, cdim], dim=1) # 对输出的特征进行划分
# 一部分用于递归优化的输入,一部分用于GRU递归优化的传递变量
net = torch.tanh(net) # [N, 256, H//8, W//8]
inp = torch.relu(inp) # [N, 256, H//8, W//8]
# step4:以图像1经过编码之后的尺度构建两个一致的坐标网格
coords0, coords1 = self.initialize_flow(image1) # 一个用于更新(使用每次迭代预测出来的光流),一个用于作为基准
if flow_init is not None: # 若初始光流不为空,则用其更新初始光流
coords1 = coords1 + flow_init
# step5:进行光流更新迭代
flow_predictions = []
for itr in range(iters):
coords1 = coords1.detach()
# 在坐标网格的基础上对correlation volume pyramid进行半径r=4的邻域采样
corr = corr_fn(coords1) # index correlation volume [N, (2*r+1)*(2*r+1)*num_levels, H//8, W//8]
# 使用CNN-GRU计算光流偏移量与上采样系数等
flow = coords1 - coords0
with autocast(enabled=self.args.mixed_precision):
net, up_mask, delta_flow = self.update_block(net, inp, corr, flow) # 迭代之后的特征/采样权重/预测光流偏移
# F(t+1) = F(t) + \Delta(t)
coords1 = coords1 + delta_flow # 更新光流
# upsample predictions
if up_mask is None:
flow_up = upflow8(coords1 - coords0) # 普通的上采样方式
else:
flow_up = self.upsample_flow(coords1 - coords0, up_mask) # 使用卷积构造的上采样方式
flow_predictions.append(flow_up) # 保存当前迭代次数的光流优化结果
2.2 correlation volume
这里主要讲述correlation volume的构建过程,之后在其基础上进行邻域采样构建correlation lookups(用于提升光流信息的特征相关性),以及提出一种更加高效的correlation volume构建方式(减少计算复杂度)。这里的编码器特征抽取部分省略。。。(其输出的维度为: [ N , 256 , H / / 8 , H / / 8 ] [N,256,H//8,H//8] [N,256,H//8,H//8])
构建过程:
correlation volume的构建过程其实是一个矩阵相乘形式:
# core/corr.py#53
def corr(fmap1, fmap2):
batch, dim, ht, wd = fmap1.shape
fmap1 = fmap1.view(batch, dim, ht*wd)
fmap2 = fmap2.view(batch, dim, ht*wd)
corr = torch.matmul(fmap1.transpose(1,2), fmap2) # 图像1/2的特征矩阵乘 [batch, ht*wd, ht*wd]
corr = corr.view(batch, ht, wd, 1, ht, wd) # [batch, ht, wd, 1, ht, wd]
return corr / torch.sqrt(torch.tensor(dim).float())
在此基础上使用池化操作得到correlation volume,这里使用到的层级为4(池化操作的kernel size为 { 1 , 2 , 4 , 8 } \{1,2,4,8\} { 1,2,4,8})。也就如下图所示:

correlation lookups的构建:
这里为了增加correlation volume中每个像素对周围像素的感知能力,使用半径 r = 4 r=4 r=4的邻域对correlation volume中每个像素进行采样,之后再组合起来。其实现可以参考:
# core/corr.py#29
def __call__(self, coords):
r = self.radius
coords = coords.permute(0, 2, 3, 1) # flow的idx坐标信息permute
batch, h1, w1, _ = coords.shape # [batch, h1, w1, 2]
out_pyramid = []
for i in range(self.num_levels):
corr = self.corr_pyramid[i]
dx = torch.linspace(-r, r, 2*r+1) # 构造邻域采样空间