自定义类型(结构体 , 枚举 , 联合)详解
文章目录
- 结构体
-
- 结构体变量初始化
- 结构体内存对齐
-
- 结构体的对齐规则:
- 为什么存在内存对齐
- 修改默认对齐数
- 结构体实现位段(位段的填充&可移植性)
-
- 什么是位段(位是二进制位)
- 位段的内存分配
- 位段的跨平台问题
- 实现offsetof(计算结构体成员相较于起始位置的偏移量)
- 枚举
-
- 枚举类型的定义(注意用,分隔)
- 枚举的优点
- 枚举变量的赋值和大小
- 联合体
-
- 联合的特点
- 联合大小的计算
结构体
结构体变量初始化
- 按顺序
#include
- 按结构成员名(是c,不是c++)
#include
结构体内存对齐
结构体的对齐规则:
1.第一个成员在与结构体变量偏移量为0的地址处
2.其他成员变量要对齐到对齐数的整数倍的地址处
对齐数 = 编译器默认的一个对齐数与该成员大小的较小值
- vs中默认的对齐数为8
- Linux环境中gcc这个编译器没有默认对齐数,对齐数就是成员自身的大小
3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍
4.如果嵌套了结构体,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大的对齐数(含嵌套结构体的对齐数)的整数倍
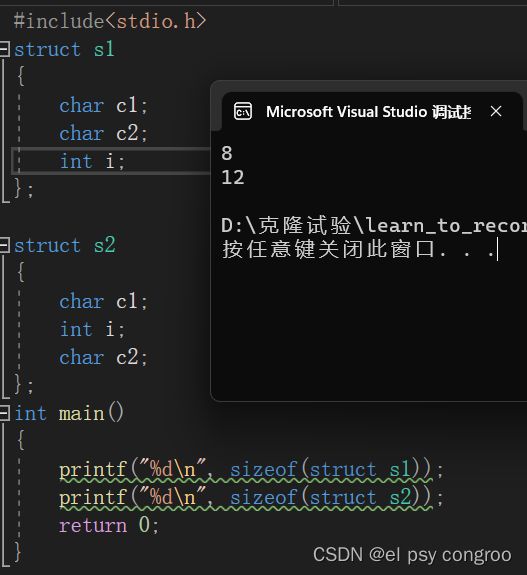
以s1为例
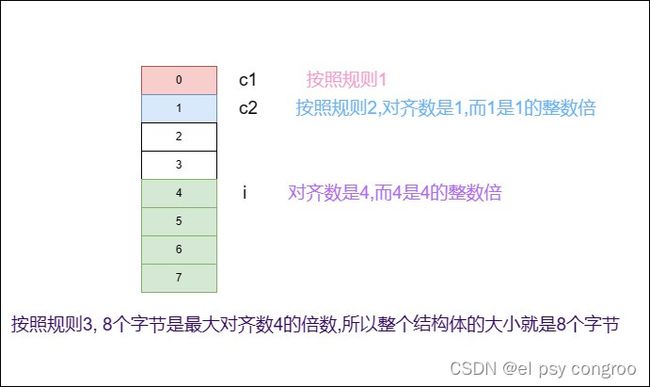
s2同理:
嵌套结构体的情况:
#include

为什么存在内存对齐
大部分参考资料如是说:
1.平台原因(移植原因):
不是所有的硬件平台能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常(所以存的时候也要特殊地存)
2.性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需一次
| 总的来说:
结构体的内存对齐是拿空间来换取时间的做法
那在设计结构体的时候,我们既要满足对齐,又要节省空间
让占用空间小的成员尽量集中在一起
比如:s1 和s2 类型的成员一样,但是s1和s2所占的空间大小有区别
修改默认对齐数
可以用#pragma这个预处理指令来改变默认对齐数
#include
结构体实现位段(位段的填充&可移植性)
什么是位段(位是二进制位)
位段的声明和结构体是类似的,有两个不同:
- 位段的成员必须是 int / unsigned int 或 signed int(c99之后,也可以有其他类型,但基本都是int , char)
- 位段的成员名后面有一个冒号和一个数字
位段的内存分配
1.位段的成员可以是 int / unsigned int / signed int 或者是char
2.位段的空间上是按照需要以4个字节(int) 或者 1个字节 (char) 的方式来开辟的
3.位段涉及很多不确定因素,位段是不跨平台的,注意可移植程序避免使用位段
即使有再多的不确定性,我们也可以探究一下在 vs 上到底是怎么使用的
#include
3+4+5+4=16,只用两个字节就够了,但用了3个,说明是有浪费的内存的.
我们可以查看一下内存情况
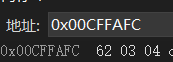
可以试着画一下内存分布.

这三个字节就是取出来就是 62 03 04
位段的跨平台问题
1.int 位段被当成有符号数还是无符号数是不确定的
2.位段中最大位的数目不能确定(16位机器整型的大小是16比特位,32位机器整型的大小是32比特位,写成27,在16位机器会出问题)
3.位段的成员在内存中从左向右分配,还是从右向左分配,标准尚未定义
4.当一个结构包含两个位段成员,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用是不确定的
总结:
|| 跟结构体相比,位段可以达到同样的效果,并且可以很好的节省空间,但有跨平台的问题.
虽然有不确定性,但可以针对不同平台写出对应的位段,这样就能确定使用了
实现offsetof(计算结构体成员相较于起始位置的偏移量)
宏 — 可以直接使用
举个栗子:
#include
实现
#define OFFSETOF(type,member_name) (size_t)&(((type*)0)->member_name)//&取地址
枚举
枚举类型的定义(注意用,分隔)
#include
以上定义的 enum Sex是枚举类型
{}中的内容是枚举类型的可能取值,也叫 枚举常量
这些可能取值都是有值的,默认从0开始,依次递增1,当然在声明枚举类型的时候也可以赋初值
#include
枚举的优点
为什么使用枚举?
我们可以使用 #define 定义常量,为什么非要使用枚举?
枚举的优点:
1.增加代码的可读性和可维护性
2.和 #define 定义的标识符比较 枚举有类型检查,更加严谨
3,便于调试
4.使用方便,一次可以定义多个常量
枚举变量的赋值和大小
#include
联合体
联合的特点
联合的成员是共用同一块内存空间的,联合变量的大小,至少是最大成员的大小
#include
联合大小的计算
- 联合的大小至少是最大成员的大小
- 当最大成员的大小不是最大对齐数的整数倍时,就要对齐到最大对齐数的整数倍
#include