Parameter-efficient transfer learning系列之Adapter
每天给你送来NLP技术干货!
来自:NLP日志
提纲
1 简介
2 Adapter
3 Adapter fusion
4 总结
参考文献
1 简介
目前在大规模预训练模型上进行finetune是NLP中一种高效的迁移方法,但是对于众多的下游任务而言,finetune是一种低效的参数更新方式,对于每一个下游任务,都需要去更新语言模型的全部参数,这需要庞大的训练资源。进而,人们会尝试固定语言预训练模型大部分网络的参数,针对下游任务只更新一部分语言模型参数。大部分情况下都是只更新模型最后几层的参数,但是我们知道语言模型的不同位置的网络聚焦于不同的特征,针对具体任务中只更新高层网络参数的方式在不少情形遭遇到精度的急剧下降。
在这个篇章介绍的Adapter会针对每个下游任务在语言模型的每层transformer中新增2个带有少量参数的模块,称之为adapter,针对下游任务训练时只更新adapter模块参数,而冻结原有语言模型的参数,从而实现将强大的大规模语言模型的能力高效迁移到诸多下游任务中去,同时保证模型在下游任务的性能。
2 Adapter
Adapter的结构一目了然,transformer的每层网络包含两个主要的子模块,一个attention多头注意力层跟一个feedforward层,这两个子模块后续都紧随一个projection操作,将特征大小映射回原本的输入的维度,然后连同skip connection的结果一同输入layer normalization层。而adapter直接应用到这两个子模块的输出经过projection操作后,并在skip-connection操作之前,进而可以将adapter的输入跟输出保持同样的维度,所以输出结果直接传递到后续的网络层,不需要做更多的修改。每层transformer都会被插入两个adapter模块。

图1: Adapter框架
下面我们来看看adapter的具体结构,首先通过一个feedforward down-project的矩阵乘法将特征维度降到一个更低的水平,然后通过一个非线形层,再利用一个feedforward up-project层将特征维度升到跟输入一样的水平,同时通过一个skip connection来将adpter的输入重新加到最终的输出中去,这样可以保证保证即便adapter一开始的参数初始化接近0,adapter也有由于skip connection的设置而初始化接近于一个恒等映射,从而保证训练的有效性。
至于adapter引进的模型参数,假设adapter的输入的特征维度是d,而中间的特征维度是m,那么新增的模型参数有:down-project的参数d*m+m,up_project的参数m*d+d,总共2md+m+d,由于m远小于d,所以真实情况下,一般新增的模型参数都只占语言模型全部参数量的0.5%~8%。同时要注意到,针对下游任务训练需要更新的参数除了adapter引入的模型参数外,还有adapter层后面紧随着的layer normalization层参数需要更新,每个layer normalization层只有均值跟方差需要更新,所以需要更新的参数是2d。(由于插入了具体任务的adapter模块,所以输入的均值跟方差发生了变化,就需要重新训练)
通过实验,可以发现只训练少量参数的adapter方法的效果可以媲美finetune语言模型全部参数的传统做法,这也验证了adapter是一种高效的参数训练方法,可以快速将语言模型的能力迁移到下游任务中去。同时,可以看到不同数据集上adapter最佳的中间层特征维度m不尽相同。

图2: adapter跟finetune的效果对比
为了进一步探究adapter的参数效率跟模型性能的关系,论文做了进一步的实验,同时比对了finetune的方式(只更新最后几层的参数或者只更新layer normalization的参数),从结果可以看出adapter是一种更加高效的参数更新方式,同时效果也非常可观,通过引入0.5%~5%的模型参数可以达到不落后先进模型1%的性能。

图3:adapter跟finetune的效率对比
3 Adapter fusion
这是一种融合多任务信息的adapter的变种,首先看下它的任务背景。假设C是N个分类任务的集合,这些分类任务的监督数据的大小跟损失函数不尽相同。C={(D1, L1), …, (DN, LN)},其中D是标注数据,L是损失函数,我们的任务是通过这N个任务加上某个任务m的数据跟损失函数(Dm, Lm)去提升这个特定任务m的效果。如图所示,就是期望先从N个任务中学到一个模型参数(最右边参数),然后利用该参数来学习特定任务m下的一个模型参数(最左边参数)。
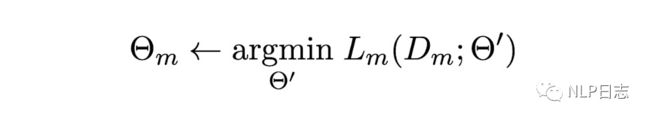
图4:学习目标
为了实现这个目标,adapter fusion提出一个两阶段的学习策略,其中第一阶段是knowledge extraction stage,在不同任务下引入各自的adapter模块,用于学习特定任务的信息,而第二阶段是knowledge composition step,用于学习聚合多个任务的adapter。
对于第一阶段有两种训练方式,分别如下:
a) Single-Task Adapters(ST-A)
对于N个任务,模型都分别独立进行优化,各个任务之间互不干扰,互不影响。对于其中第n个任务而言,相应的目标函数如下图所示,其中最右边两个参数分别代表语言模型的模型参数跟特定任务需要引入的adapter参数。

图5:ST-A目标函数
b) Multi-Task Adapters(MT-A)
N个任务通过多任务学习的方式,进行联合优化,相应的目标函数如下。

图6:MT-A目标函数
对于第二阶段,就是adapter fusion大展身手的时候了。为了避免通过引入特定任务参数而带来的灾难性遗忘问题,adapter fusion提出了一个共享多任务信息的结构。针对特定任务m,adapter fusion联合了第一阶段训练的到的N个adapter信息。固定语言模型的参数跟N个adapter的参数,新引入adapter fusion的参数,目标函数也是学习针对特定任务m的adapter fusion的参数。
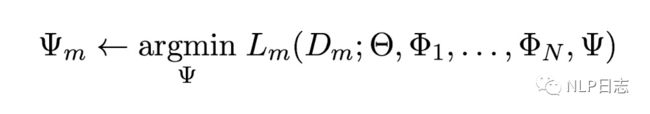
图7:adapter fusion的目标函数
Adapter fusion的具体结构就是一个attention,它的参数包括query,key, value的矩阵参数,在transformer的每一层都存在,它的query是transformer每个子模块的输出结果,它的key跟value则是N个任务的adapter的输出。通过adapter fusion,模型可以为不同的任务对应的adapter分配不同的权重,聚合N个任务的信息,从而为特定任务输出更合适的结果。

图8:adapter fusion结构
通过实验,可以看到第一阶段采用ST-A+第二阶段adapter fusion是最有效的方法,在多个数据集上的平均效果达到了最佳。关于MT-A+adapter fusion没有取得最佳的效果,在于第一阶段其实已经联合了多个任务的信息了,所以adapter fusion的作用没有那么明显,同时MT-A这种多任务联合训练的方式需要投入较多的成本,并不算一种高效的参数更新方式。另外,ST-A的方法在多个任务上都有提升,但是MT-A的方法则不然,这也表明了MT-A虽然可以学习到一个通用的表征,但是由于不同任务的差异性,很难保证在所有任务上都取得最优的效果。
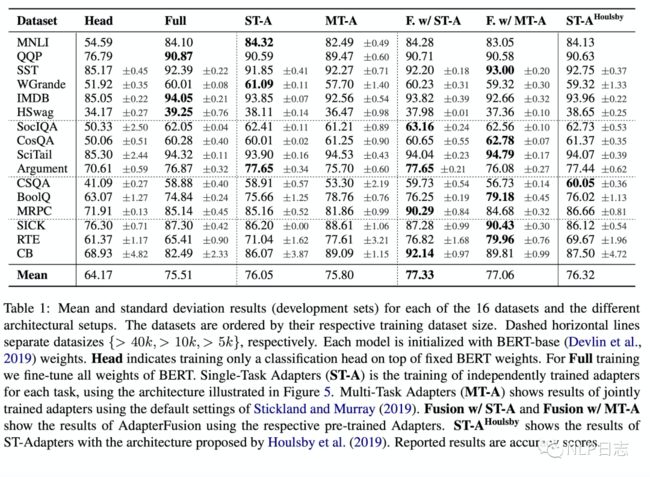
图9:adapter fusion实验结果
4 总结
Fusion是一种高效的参数更新方式,能在引入少量参数,只训练少量参数的情况下达到媲美finetune全模型参数的效果,只训练少量参数也意味着对训练数据量更低的要求以及更快的训练速度,是一种将大规模预训练语言模型能力迁移到下游任务的高效方案,跟目前火热的prompt learning有异曲同工之妙。而adapter fusion则跟MOE很像,可以联合多个任务的信息,从而提升特定任务的性能。但相比于其他的parameter-efficient的方法,adapter是在原语言模型上加入了新的模块,在推理时会进一步增加延迟。
参考文献
1. Parameter-efficient transfer learning for nlp
https://arxiv.org/pdf/1902.00751.pdf
2. Adapter- Fusion: Non-destructive task composition for transfer learning
https://arxiv.org/pdf/2005.00247.pdf
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!