可靠/可用性介绍
可靠/可用性主要目的是保护业务零中断和高用户体验。
可靠可用性基本概念
广义的可靠性(Reliability)由三个部分组成:可靠性(Reliability)、可维修性(Maintainability)和可用性(Avaliability)。其中狭义的可靠性是指产品在规定的条件和时间内完成规定功能的能力,它的概率度量称为可靠性。可维修性是指产品在规定的条件和时间内,按规定的程序和方法维修时,保持和恢复到规定状态的能力。可用性是指产品在任意随机时刻需要和开始执行任务时,处于可工作或使用的状态,它的概率度量称为可用性。
衡量指标
接下来介绍用哪些指标度量可靠性、可维修性和可用性。需要说明的是,由于故障可分为"可修复"和"不可修复",而不同的故障类型,其可靠性、可维修性和可用性指标不相同。对于不可修复故障,讨论其可维修性没有意义,因为一旦出现故障,其处理策略是使用新的产品进行替换。对应的其可靠性也变成该产品的寿命,其可靠性就是可用性。对于软件来说,一旦软件产品出现故障,这时软件开发人员就充当维修人员,对软件问题进行修复。注意,讨论软件产品的可靠/可用性时,并不考虑其依赖硬件的可靠/可用性。
平均故障间隔时间
平均故障间隔时间(Mean Time Between Failure, MTBF),顾名思义,是指相邻两次故障之间的平均工作时间,是衡量一个产品的可靠性指标。 接下来就用wiki上一张经典的图来说明平均故障间隔时间。

从上图可以看出,平均故障间隔时间就是多个故障间隔时间的平均值,而一次故障间隔时间则上图down time - up time的差值。
平均故障修复时间
平均故障修复时间(Mean Time To Recover, MTTR),顾名思义,是指产品由故障状态转为工作状态时修理时间的平均值。在工程学,MTTR是衡量产品可维修性的值,在维护合约里很常见,并以之作为服务收费的准则。MTTR就是从故障发生到故障修复这段时间。这个时间段包括故障发现时间、故障定位时间、故障修复时间。对云原生应用来说,可将MTTR继续分解为如何快速发现(监控设计)、如何快速定位(问题定位设计,例如日志收集、全链路跟踪)、如何快速恢复(例如倒换、降级)。
下面给出业内对软件MTTR的估算:

对于云原生应用来说,如果出现业务问题,需要回滚,如果需要在线下载容器镜像,则应确保可在10min内恢复,如果不需要下载容器镜像,则应确保可在30s内恢复。
可用度
GB/T3187-97对可用性的定义如下:在要求的外部资源得到保证的前提下,产品在规定的条件下和规定的时刻或时间区间内处于可执行规定功能状态的能力。可用性是产品可靠性、可维修性和维修保障性的综合反映。 其计算公式如下:
A v a i l a b i l i t y = M T B F / ( M T B F + M T T R ) Availability = MTBF / (MTBF + MTTR) Availability=MTBF/(MTBF+MTTR)
关于可用性的计算公式,这里不多做解释。通常大家习惯用N个9来表征系统可用性,比如99.9%(3-nines availability),99.999%(5-nines availability)。这和接下来介绍的停机时间密切相关。
宕机时间和可用性
宕机时间(Down Time, DT)是指机器出现故障的停机时间。使用每年的宕机时间来衡量系统可用性,更符合直觉,更容易理解。计算公式如下:
D T = ( 1 − A ) ∗ 365 ∗ 24 ∗ 60 ( 分钟 / 年 ) DT = (1 - A) * 365 * 24 * 60 (分钟/年) DT=(1−A)∗365∗24∗60(分钟/年)
这里给出宕机时间和可用性的常见情况:

可见,如果需要达到5个9的可用性,一年至多有5min的停机时间,这个时间难度是极大的,也是业内衡量软件质量高低的一个门槛。至于其他场景的可用性,则根据业务的不同,有不同的要求。
可靠/可用性设计
冗余设计
冗余设计,又称余度设计,是提升系统可用性的常用技术。
冗余设计按照副本的职责,主要分为两类:主动冗余、被动冗余。主动冗余是指内部的所有节点都处于正常状态,所有的节点没有主备之分。被动冗余是指当主节点故障之后,备用节点接管并处理故障单元的任务。主动冗余的场景有负荷分担、资源池,被动冗余的场景有热备份、冷备份。
影响冗余的因素除了节点自身的失效率和修复率之外,还与节点的故障管理能力密切相关,包括故障检测率、倒换成功率等。一般通过可靠性建模(RDB(Reliability Block Diagram)/Markov)来分析影响冗余的关键因素。
冗余设计是系统可用性常用的技术。对云服务的冗余设计主要通过多实例、反亲和部署等技术手段实现。
冗余设计的核心要点:冗余节点要相互独立,避免共因故障。
冗余保护需避免频繁倒换和联动倒换。
容灾设计
容灾指在相隔较远的异地,建立两套或多套功能相同的系统,当灾难(含人为操作破坏、自然灾害、设备故障)发生时,由异地容灾系统接管业务,实现业务不中断、关键业务数据不丢失的目标。衡量容灾系统的主要指标有:
RPO(Recovery Point Objective), 代表当灾难发生时,允许丢失的数据量。
RTO(Recovery Time Objective),代表系统业务恢复的时间。
RPO与RTO越小,系统的可用性就越高,用户的投资也越大。
目前成熟的容灾方案是两地三中心。对于云服务来说,其容灾方法一般可分为跨Region容灾方案、跨AZ容灾方案。
故障管理
故障管理是指通过对系统中存在的故障检测采取确认、定位/处理、恢复、故障复盘、故障任务跟踪等措施,消除或减轻故障对系统功能的影响,从而达到系统容错、提高系统可靠性的目的。

过载控制设计
过载指系统的并发输入超过系统的额定容量,从而导致系统不能提供及时服务的一种状态。通常用实际业务请求数据和额定规格业务请求数的比值来描述,如3倍负载、10倍负载、30倍负载。
过载控制(也指流控)指系统处于过载状态时,通过流控、降级、熔断、隔离、弹性伸缩等手段,使系统保证部分或者全部额定容量的业务成功处理的控制过程。
对于云服务来说,先弹性扩容、然后服务降级、最后才考虑业务丢弃。
升级不中断设计
升级不中断指升级期间业务数据中断时间用户无感知,已经建立的业务连接不中断,正在建立的业务可丢弃,新业务能够在N秒内接入。
云服务通常采用蓝绿发布、灰度发布(金丝雀发布)等机制,来降低软件升级带来的业务中断及对商用用户的影响。灰度发布的主要目的是为了避免出现批次升级导致大规模故障,且异常恢复时间较长的场景。灰度发布要求系统需具备新老版本同时运行的能力,并且支持按照不同类型的用户,按比例逐步把用户从老版本切换迁移到新版本。在迁移过程中实时监控用户业务使用状态,如果发现业务异常,用户可随时切换回老版本。
(1) 蓝绿发布
通过部署两套环境来解决新老版本的发布问题。如果新版本(New Version)发生问题要进行回滚的时候,直接通过切流将流量全部切到老版本(Old Version)上。
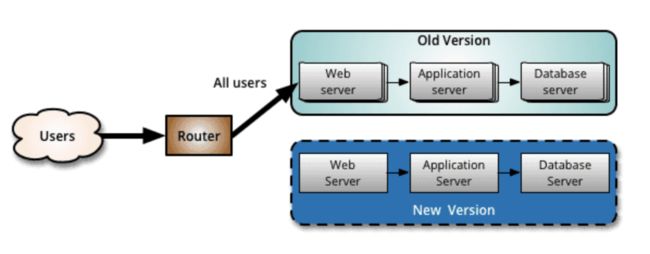
蓝绿发布的优点是升级切换和回退比发布回滚迅速,但蓝绿发布成本较高,需要部署两套环境。如果新版本中基础服务出现问题,会瞬间影响全网用户;如果新版本有问题也会影响全网用户。
(2) 金丝雀发布
金丝雀发布要求系统需具备新老版本同时运行的能力,并且支持按照不同类型的用户,按比例逐步把用户从老版本迁移到新版本。在迁移的过程中,如果发现业务异常,用户可随时切换回老版本。
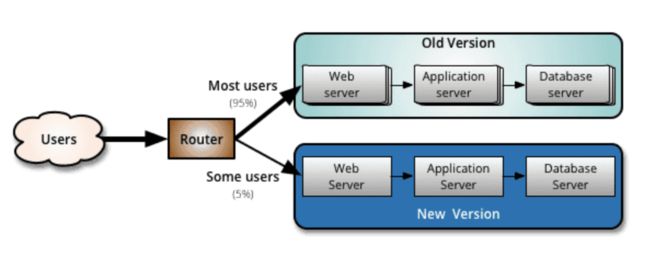
金丝雀发布可以按照流量或具体的内容进行灰度(比如不同账号,不同参数),出现问题不会影响全网用户,但是金丝雀发布因为没有覆盖到所有的用户导致出现问题不好排查。
可靠/可用性测试
故障注入测试(Fault Injection Test, FIT),通常指向系统注入在实际应用中可能发生的故障,观察系统功能性能变化,故障检测、定位、隔离以及故障恢复情况,发现产品缺陷、评估系统可靠性的测试方法。
故障注入测试目的
(1) 可靠性增长,测试发现问题并修复,提高系统可靠性。
(2) 验证系统可靠性,验证系统的故障管理能力。
(3) 对产品故障恢复能力定量评估。
参考
https://www.pianshen.com/article/47451556182/ 如何理解“可靠性”和“可用性”?
https://blog.csdn.net/yunhua_lee/article/details/121674703 MTTR、MTBF、MTTF、可用性、可靠性
https://zh.wikipedia.org/wiki/平均故障間隔 平均故障间隔
https://blog.csdn.net/weixin_44648216/article/details/117913305 可用性和可靠性
https://blog.csdn.net/zouhui1003it/article/details/109541840 互联网产品线上故障管理规范
https://developer.aliyun.com/article/747091 金丝雀发布