【管理运筹学】第 10 章 | 排队论(2,到达时间间隔的分布和服务时间的分布)
文章目录
- 引言
- 一、普阿松分布
- 二、负指数分布
- 三、爱尔朗分布
引言
解决排队问题,首先要根据原始资料做出顾客到达时间间隔和服务时间的经验分布,然后按照统计学的方法(如 χ 2 \chi^2 χ2 检验)以确定属于哪种分布理论,并估计它的参数值。
常见的理论分布有普阿松分布、负指数分布和爱尔朗(Erlang)分布。
一、普阿松分布
其实就是概率论里的泊松分布,这样的翻译我还是头一次见。
设 N ( t ) N(t) N(t) 为在时间区间 [ 0 , t ] [0,t] [0,t] 内到达的顾客数( t > 0 t>0 t>0), P n ( t 1 , t 2 ) P_n(t_1,t_2) Pn(t1,t2) 为在时间区间 [ t 1 , t 2 ] [t_1,t_2] [t1,t2] 内有 n ( n ≥ 0 ) n(n\geq0) n(n≥0) 个顾客到达的概率,即 P n ( t 1 , t 2 ) = P { N ( 0 , t 2 ) − N ( 0 , t 1 ) = n } ( t 2 > t 1 , n ≥ 0 ) P_n(t_1,t_2)=P\{N(0,t_2)-N(0,t_1)=n\}(t_2>t_1,n\geq0) Pn(t1,t2)=P{N(0,t2)−N(0,t1)=n}(t2>t1,n≥0) 当 P n ( t 1 , t 2 ) P_n(t_1,t_2) Pn(t1,t2) 符合下述 3 个条件时,顾客到达的过程就是泊松过程(顾客到达形成普阿松流)。
- 在不相重叠的时间区间内顾客到达数是相互独立的,称为无后效性;
- 对充分小的 Δ t \Delta t Δt ,在时间区间 [ t , t + Δ t ] [t,t+\Delta t] [t,t+Δt] 内有一个顾客到达的概率与 t t t 无关,而与区间长成正比,即 P 1 ( t , t + Δ t ) = λ Δ t + ο ( Δ t ) P_1(t,t+\Delta t)=\lambda \Delta t +\omicron(\Delta t) P1(t,t+Δt)=λΔt+ο(Δt) 其中 ο ( Δ t ) \omicron(\Delta t) ο(Δt) 是关于 Δ \Delta Δ 的高阶无穷小。 λ > 0 \lambda>0 λ>0 是常数,它表示单位时间内有一个顾客到达的概率,称为概率强度。
- 对于充分小的 Δ t \Delta t Δt ,在时间区间 [ t , t + Δ t ] [t,t+\Delta t] [t,t+Δt] 内有2 个或 2 个以上顾客到达的概率极小,以至于可以忽略,即 P 2 ( t , t + Δ t ) = ο ( Δ t ) P_2(t,t+\Delta t)=\omicron(\Delta t) P2(t,t+Δt)=ο(Δt)
在上述条件下,研究顾客到达数 n n n 的概率分布。
由条件 2 ,总可以取时间由 0 算起,并简记 P n ( 0 , t ) = P n ( t ) P_n(0,t)=P_n(t) Pn(0,t)=Pn(t) 。
由条件 2,3 ,可以推得在 [ t , t + Δ t ] [t,t+\Delta t] [t,t+Δt] 区间内没有顾客达到的概率为 P 0 ( t , t + Δ t ) = 1 − λ Δ t + ο ( Δ t ) P_0(t,t+\Delta t)=1-\lambda\Delta t +\omicron(\Delta t) P0(t,t+Δt)=1−λΔt+ο(Δt) 在计算 P n ( t ) P_n(t) Pn(t) 时,用通常建立未知函数的微分方程的办法,先求未知函数 P n ( t ) P_n(t) Pn(t) 由时刻 t t t 到 t + Δ t t+\Delta t t+Δt 的改变量,从而建立 t t t 时刻的概率分布与 t + Δ t t+\Delta t t+Δt 时刻概率分布的关系方程。
推导过程我就不写了,最后得到 P n ( t ) = ( λ t ) n n ! e − λ t , t > 0 ; n = 0 , 1 , ⋯ P_n(t)=\frac{(\lambda t)^n}{n!}e^{-\lambda t},t>0;n=0,1,\cdots Pn(t)=n!(λt)ne−λt,t>0;n=0,1,⋯ P n ( t ) P_n(t) Pn(t) 表示长为 t t t 的时间区间内到达 n n n 个顾客的概率,有 N ( t ) N(t) N(t) 服从参数为 λ t \lambda t λt 的普阿松分布,它的数学期望和方差分别为 E [ N ( t ) ] = λ t ; D [ N ( t ) ] = λ t . E[N(t)]=\lambda t;D[N(t)]=\lambda t. E[N(t)]=λt;D[N(t)]=λt. 期望值和方差相等,这是普阿松分布的一个重要特征,可以利用它对一个经验分布是否适合普阿松分布进行初步识别。
二、负指数分布
随机变量 T T T 的概率密度若为 f T ( t ) = { λ e − λ t t ≥ 0 0 t < 0 f_T(t)=\begin{cases} \lambda e^{-\lambda t} &t\geq0 \\ 0 &t<0\end{cases} fT(t)={λe−λt0t≥0t<0 则称 T T T 服从负指数分布,它的分布函数为 F T ( t ) = { 1 − e − λ t t ≥ 0 0 t < 0 F_T(t)=\begin{cases} 1-e^{-\lambda t} &t\geq0 \\ 0 &t<0\end{cases} FT(t)={1−e−λt0t≥0t<0 其数学期望 E ( T ) = 1 / λ E(T)=1/\lambda E(T)=1/λ ,方差 D ( T ) = 1 / λ 2 D(T)=1/\lambda^2 D(T)=1/λ2 。
负指数分布具有以下性质。
- 由条件概率公式,有 P { T > t + s ∣ T > s } = P { T > t } P\{T>t+s|T>s\}=P\{T>t\} P{T>t+s∣T>s}=P{T>t} 这一性质称为无记忆性或马尔科夫性。若 T T T 表示排队系统中顾客到达的间隔时间,那么这个性质说明一个顾客到来与过去一个顾客到来无关,是纯随机的。
- 当输入过程是普阿松流时,顾客相继到达的时间间隔 T T T 服从负指数分布。这是因为,在 [ 0 , t ) [0,t) [0,t) 内没有顾客来等价于相邻顾客到达间隔时间 T > t T>t T>t 。对于普阿松流,在 [ 0 , t ) [0,t) [0,t) 区间内没有一个顾客到达的概率是 P 0 ( t ) = e − λ t ( t > 0 ) P_0(t)=e^{-\lambda t}(t>0) P0(t)=e−λt(t>0) ,则 P { T > t } = e − λ t P\{T>t\}=e^{-\lambda t} P{T>t}=e−λt ,从而有 P { T ≤ t } = 1 − e − λ t P\{T\leq t\}=1-e^{-\lambda t} P{T≤t}=1−e−λt ,此即负指数分布的分布函数公式。
对一顾客的服务时间,也就是在忙期内相继离开服务系统的两顾客的间隔时间,有时也服从负指数分布。这时设它的分布函数和密度分别为 F v ( t ) = 1 − e − μ t , f v ( t ) = μ e − μ t F_v(t)=1-e^{-\mu t},f_v(t)=\mu e^{-\mu t} Fv(t)=1−e−μt,fv(t)=μe−μt 其中 μ \mu μ 表示单位时间内被服务完成的顾客数,称为平均服务率。而 1 / μ 1/\mu 1/μ 表示一个顾客的平均服务时间。
三、爱尔朗分布
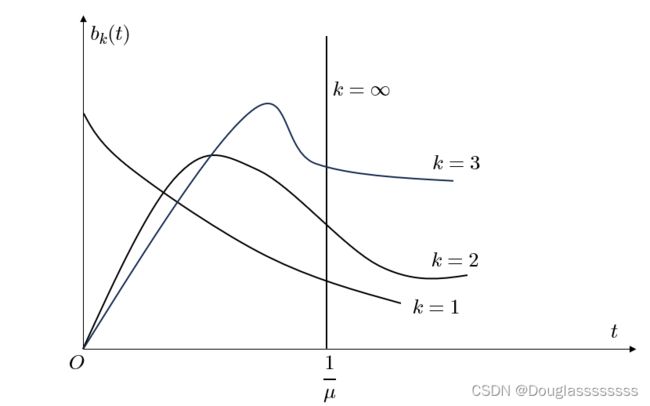
设 v 1 , v 2 , ⋯ , v k v_1,v_2,\cdots,v_k v1,v2,⋯,vk 为 k k k 个相互独立的随机变量,服从相同参数 k μ k\mu kμ 的负指数分布,那么 T = v 1 + v 2 + ⋯ + v n T=v_1+v_2+\cdots+v_n T=v1+v2+⋯+vn 的概率密度是 b k ( t ) μ k ( μ k t ) k − 1 ( k − 1 ) ! e − k μ t , t > 0 b_k(t)\frac{\mu k(\mu k t)^{k-1}}{(k-1)!}e^{-k\mu t},t>0 bk(t)(k−1)!μk(μkt)k−1e−kμt,t>0 称 T T T 服从 k k k 阶爱尔朗分布。其数学期望为 1 / μ 1/\mu 1/μ ,方差为 1 / ( k μ 2 ) 1/(k\mu^2) 1/(kμ2) 。
串联的 k k k 个服务台,每台服务时间相互独立,服从相同的参数为 k μ k\mu kμ 的负指数分布,那么一顾客走完这 k k k 个服务台总共所需要的服务时间就服从上述的 k k k 阶爱尔朗分布。
爱尔朗分布族提供了更为广泛的的模型类,比指数分布有更大的适应性。当 k = 1 k=1 k=1 时,爱尔朗分布退化为负指数分布,可看成是完全随机的;当 k k k 增大时,爱尔朗分布的图形逐渐变为对称;当 k ≥ 30 k\geq 30 k≥30 时,爱尔朗分布近似于正态分布; k → ∞ k\to \infty k→∞ 时,此时方差趋于 0 ,即爱尔朗分布化为确定型分布,所以一般 k k k 阶爱尔朗分布可以看成完全随机与完全确定的中间型(下图所示),能对现实世界提供更为广泛的适应性。