JavaWeb——XML & Tomcat
XML
xml 是可扩展的标记性语言。主要作用有:
- 用来保存数据,而且这些数据具有自我描述性
- 做为项目或者模块的配置文件
- 做为网络传输数据的格式(现在 JSON 为主)
1、文档声明
xml 声明。
而且这个 属性
version 是版本号
encoding 是 xml 的文件编码
standalone="yes/no" 表示这个 xml 文件是否是独立的 xml 文件
2、xml 注释
html 和 XML 注释 一样:
3、元素(标签)
html 标签:
格式:< 标签名 > 封装的数据 标签名 >
单标签: < 标签名 />
换行
水平线
换行
水平线
双标签 < 标签名 > 封装的数据 标签名 >
标签名大小写不敏感
标签有属性,有基本属性和事件属性
标签要闭合(不闭合 ,html 中不报错。但我们要养成良好的书写习惯。闭合)
XML元素
XML元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。元素可包含其他元素、文本或者两者的混合物。元素也可以拥有属性。
XML 命名规则
名称可以含字母、数字以及其他的字符,例如:

名称不能以数字或者标点符号开始:

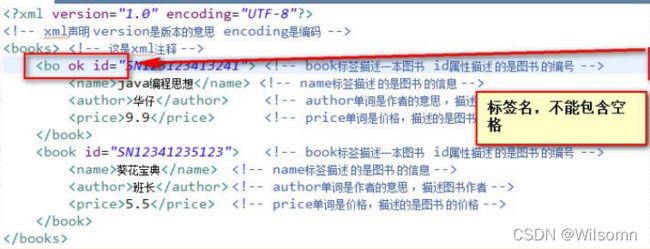
名称不能包含空格:
xml 中元素(标签)也分单标签和双标签。
4、xml 属性
xml 的标签属性和 html 的标签属性是非常类似的, 属性可以提供元素的额外信息。 一个标签上可以书写多个属性。
每个属性的值必须使用引号引起来,不过单引号和双引号均可使用
或者
5、语法规则
所有 XML 元素都须有关闭标签(也就是闭合);
XML 标签对大小写敏感;
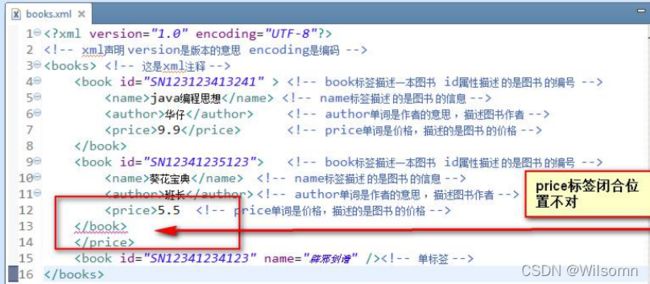
XML 必须正确地嵌套:
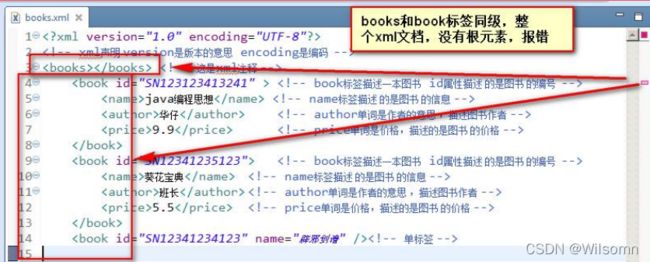
XML 文档必须有根元素:
根元素就是顶级元素,
没有父标签的元素,叫顶级元素。
根元素是没有父标签的顶级元素,而且是唯一一个才行。
XML 的属性值须加引号
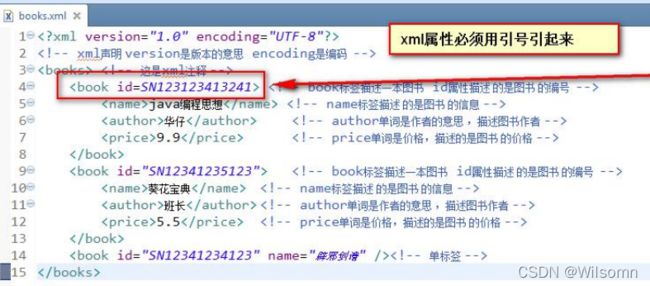
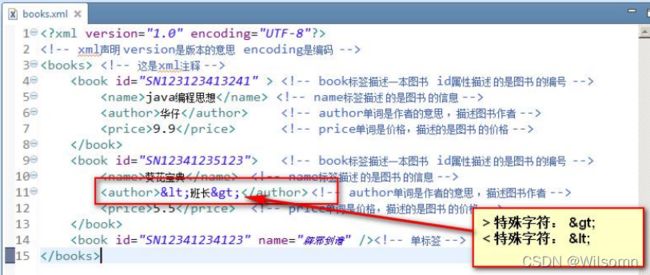
XML 中的特殊字符
文本区域( CDATA 区)
DATA 语法可以告诉 xml 解析器, CDATA 里的文本内容,只是纯文本,不需要 xml 语法解析。
格式: 这里可以把你输入的字符原样显示,不会解析 xml ]]>

6、XML解析技术
xml 可扩展的标记语言。 不管是 html 文件还是 xml 文件它们都是标记型文档,都可以使用 w3c 组织制定的 dom 技术来解析。
jdom 在 dom 基础上进行了封装 、 dom4j 又对 jdom 进行了封装。
dom4j 解析技术
由于 dom4j 它不是 sun 公司的技术,而属于第三方公司的技术,我们需要使用 dom4j 就需要到 dom4j 官网下载 dom4j的 jar 包。
dom4j 目录介绍
docs是文档目录;
查询Dom4j的文档:docs目录下的index.html文件
lib目录:dom4j需要依赖其他第三方类库
src 目录:第三方类库的源码目录
dom4j 编程步骤
- 先加载 xml 文件创建 Document 对象
- 通过 Document 对象拿到根元素对象
- 通过根元素elelemts(标签名),可以返回一个集合,放着所有指定的标签名的元素对象
- 找到你想要修改、删除的子元素,进行相应在的操作
- 保存到硬盘上
获取 document 对象
创建一个 lib 目录,并添加 dom4j 的 jar 包。并添加到类路径。
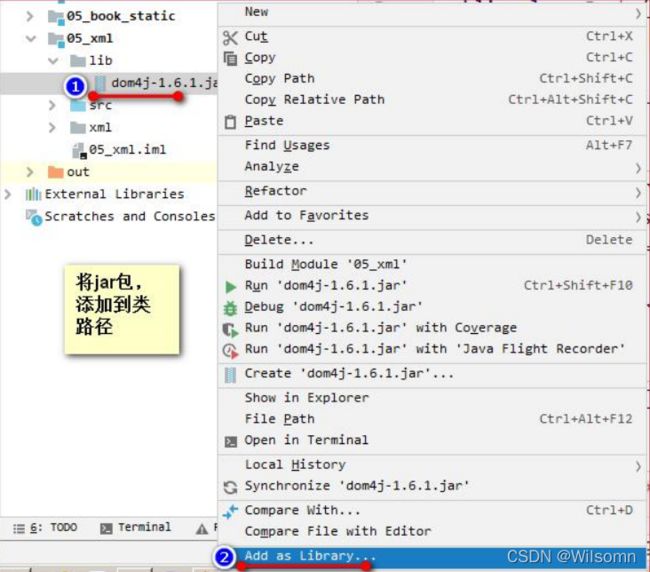
解析获取 Document 对象的代码
第一步,先创建 SaxReader 对象。这个对象,用于读取 xml 文件,并创建 Document
/** dom4j 获取 Documet 对象 */
@Test
public void getDocument() throws DocumentException {
// 要创建一个 Document 对象,需要我们先创建一个 SAXReader 对象
SAXReader reader = new SAXReader();
// 这个对象用于读取 xml 文件,然后返回一个 Document。
Document document = reader.read("src/books.xml");
// 打印到控制台,看看是否创建成功
System.out.println(document);
}遍历 标签 获取所有标签中的内容
- 通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
- 通过 Document 对象。拿到 XML 的根元素对象
- 通过根元素对象。获取所有的 book 标签对象
- 遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
/**
* 读取 xml 文件中的内容
*/
@Test
public void readXML()throws DocumentException{
// 需要分四步操作:
// 第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
// 第二步,通过 Document 对象。拿到 XML 的根元素对象
// 第三步,通过根元素对象。获取所有的 book 标签对象
// 第四步,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
// 第一步,通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
SAXReader reader=new SAXReader();
Document document=reader.read("src/books.xml");
// 第二步,通过 Document 对象。拿到 XML 的根元素对象
Element root=document.getRootElement();
// 打印测试
//Element.asXML() 它将当前元素转换成为 String 对象
//System.out.println( root.asXML() );
// 第三步,通过根元素对象。获取所有的 book 标签对象
// Element.elements(标签名)它可以拿到当前元素下的指定的子元素的集合
List books=root.elements("book");
// 第四步,遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
for(Element book:books){
// 测试
// System.out.println(book.asXML());
// 拿到 book 下面的 name 元素对象
Element nameElement=book.element("name");
// 拿到 book 下面的 price 元素对象
Element priceElement=book.element("price");
// 拿到 book 下面的 author 元素对象
Element authorElement=book.element("author");
// 再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
System.out.println("书名"+nameElement.getText()+" , 价格:"+priceElement.getText()+", 作者:"+authorElement.getText());
}
}
2、Tomcat
JavaWeb的概念
JavaWeb 是指,所有通过 Java 语言编写可以通过浏览器访问的程序的总称 。
JavaWeb 是基于请求和响应来开发的。
Web 资源的分类
web 资源按实现的技术和呈现的效果的不同,又分为静态资源和动态资源两种。
静态资源: html 、 css 、 js 、 txt 、 mp4 视频 , jpg 图片
动态资源: jsp 页面、 Servlet 程序
常用的 Web 服务器
Tomcat :由 Apache 组织提供的一种 Web 服务器,提供对 jsp 和 Servlet 的支持。它是一种轻量级的 javaWeb 容器(服务器),也是当前应用最广的 JavaWeb 服务器(免费)。
Jboss :是一个遵从 JavaEE 规范的、开放源代码的、纯 Java 的 EJB 服务器,它支持所有的 JavaEE 规范(免费)。
GlassFish :由 Oracle 公司开发的一款 JavaWeb 服务器,是一款强健的商业服务器,达到产品级质量(应用很少)。
Resin :是 CAUCHO 公司的产品,是一个非常流行的服务器,对 servlet 和 JSP 提供了良好的支持, 性能也比较优良, resin 自身采用 JAVA 语言开发(收费,应用比较多)。
WebLogic :是 Oracle 公司的产品,是目前应用最广泛的 Web 服务器,支持 JavaEE 规范,而且不断的完善以适应新的开发要求,适合大型项目(收费,用的不多,适合大公司)。
Tomcat 的使用
安装:
找到你需要用的 Tomcat 版本对应的 zip 压缩包,解压到需要安装的目录即可。
目录介绍
bin 专门用来存放 Tomcat 服务器的可执行程序
conf 专门用来存放 Tocmat 服务器的配置文件
lib 专门用来存放 Tomcat 服务器的 jar 包
logs 专门用来存放 Tomcat 服务器运行时输出的日记信息
temp 专门用来存放 Tomcdat 运行时产生的临时数据
webapps 专门用来存放部署的 Web 工程。
work 是 Tomcat 工作时的目录,用来存放 Tomcat 运行时 jsp 翻译为 Servlet 的源码,和 Session 钝化的目录。
启动 Tomcat 服务器
找到 Tomcat 目录下的 bin 目录下的 startup.bat 文件,双击,就可以启动 Tomcat 服务器。
打开浏览器,在浏览器地址栏中输入以下地址测试:
1 、 http://localhost:8080
2 、 http://127.0.0.1:8080
3 、 http:// 真实 ip:8080
常见的启动失败的情况有,双击 startup.bat 文件,就会出现一个小黑窗口一闪而来。
这个时候,失败的原因基本上都是因为没有配置好 JAVA_HOME 环境变量。
启动 tomcat 服务器的方式二
打开命令行, cd 到 Tomcat 的 bin 目录下
Tomcat的停止
- 点击 tomcat 服务器窗口的 x 关闭按钮
- 把 Tomcat 服务器窗口置为当前窗口,然后按快捷键 Ctrl+C
- 找到 Tomcat 的 bin 目录下的 shutdown.bat 双击,就可以停止 Tomcat 服务器
修改 Tomcat 的端口号
Mysql 默认的端口号是: 3306
Tomcat 默认的端口号是: 8080
找到 Tomcat 目录下的 conf 目录,找到 server.xml 配置文件。

部暑 web 工程到 Tomcat 中
第一种部署方法:只需要把 web 工程的目录拷贝到 Tomcat 的 webapps 目录下 即可。
访问 Tomcat 下的 web 工程。
只需要在浏览器中输入访问地址格式如下: http://ip:port/ 工程名 / 目录下 / 文件名
第二种部署方法:
找到 Tomcat 下的 conf 目录\Catalina\localhost\ 下,创建abc.xml配置文件
访问这个工程的路径如下:http://ip:port/abc/ 就表示访问 E:\book 目录
手托 html 页面到浏览器和在浏览器中输入 http://ip:端 口号/工程名/访问的区别
手托 html 页面的原理:
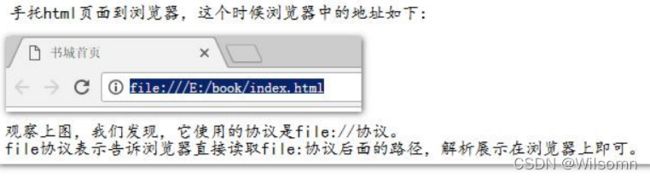
输入访问地址访问的原理:

ROOT 的工程的访问,以及默认 index.html 页面的访问
当我们在浏览器地址栏中输入访问地址如下:
http://ip:port/ ====>>>> 没有工程名的时候,默认访问的是 ROOT 工程。
http://ip:port/ 工程名/ ====>>>> 没有资源名,默认访问 index.html 页面
3、IDEA整合Tomcat服务器
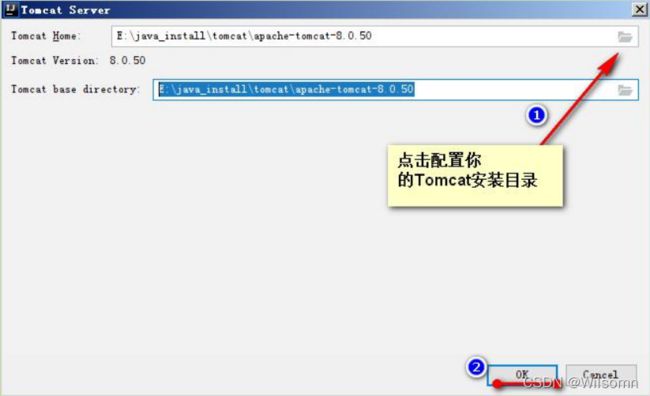
操作的菜单如下: File | Settings | Build, Execution, Deployment | Application Servers

配置你的 Tomcat 安装目录:
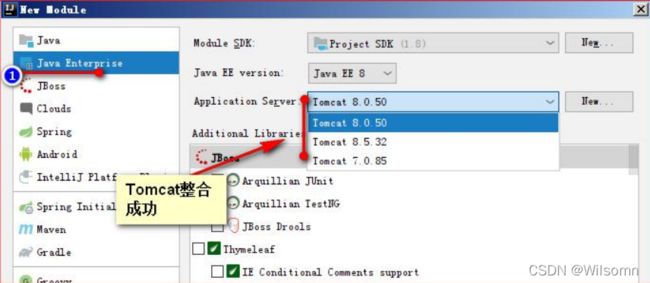
就可以通过创建一个 Model 查看是不是配置成功!
4、IDEA中动态web工程的操作
①创建一个新模块:
② 选择你要创建什么类型的模块:
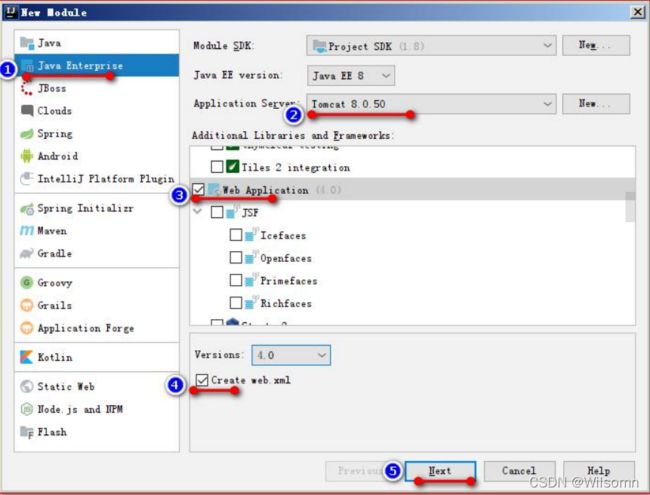
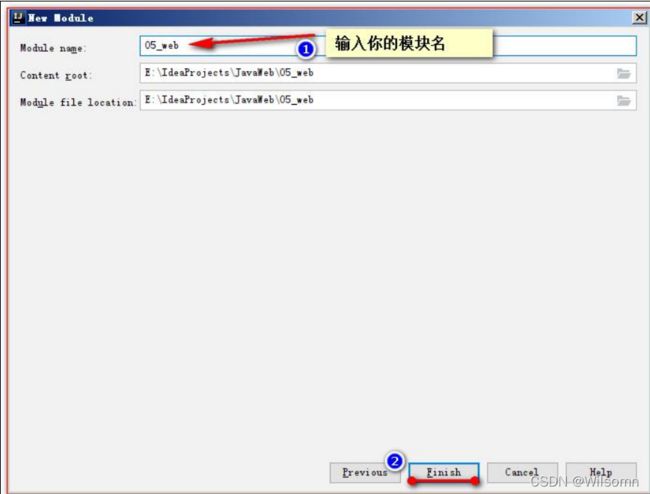
③输入你的模块名,点击【Finish】完成创建。
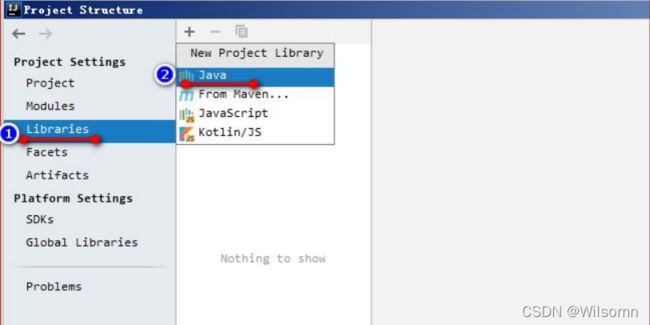
给动态 web 工程添加额外 jar 包
①可以打开项目结构菜单操作界面,添加一个自己的类库
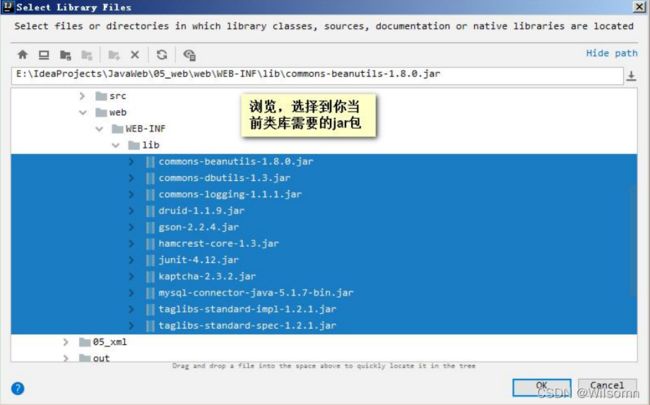
②添加你你类库需要的 jar 包文件
③选择你添加的类库,给哪个模块使用

④选择 Artifacts 选项,将类库,添加到打包部署中

在 IDEA 中部署工程到 Tomcat 上运行
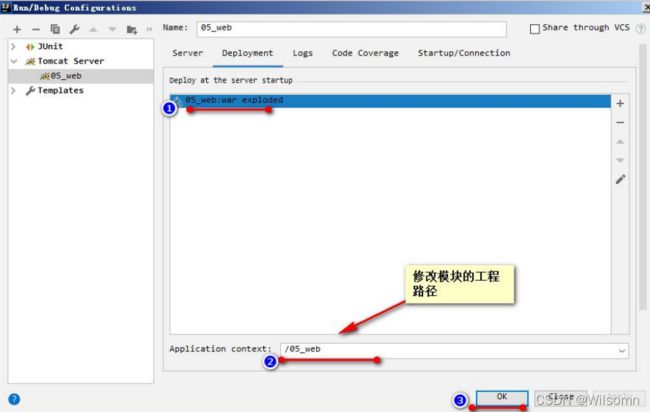
①建议修改 web 工程对应的 Tomcat 运行实例名称

② 确认你的 Tomcat 实例中有你要部署运行的 web 工程模块
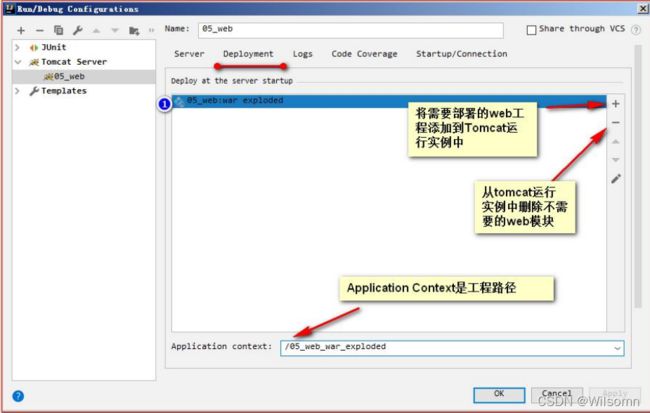
③还可以修改你的 Tomcat 实例启动后默认的访问地址
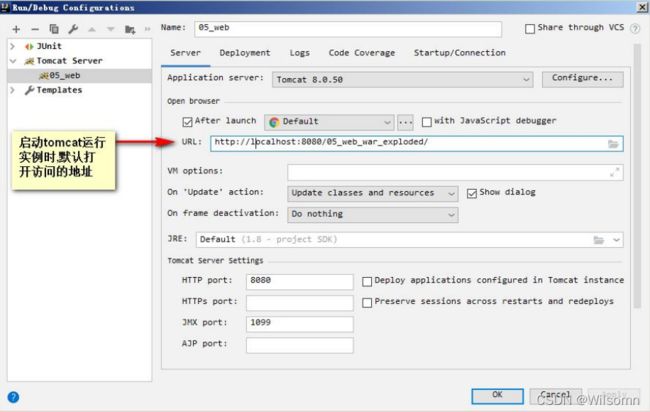
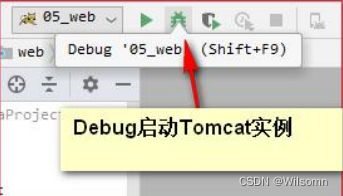
④在 IDEA 中如何运行,和停止 Tomcat 实例
正常启动 Tomcat 实例

Debug 方式启动 Tomcat 运行实例
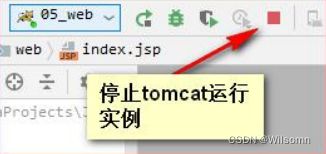
停止 Tomcat 运行实例
重启 Tomcat 运行实例

修改工程访问路径
修改运行的端口号

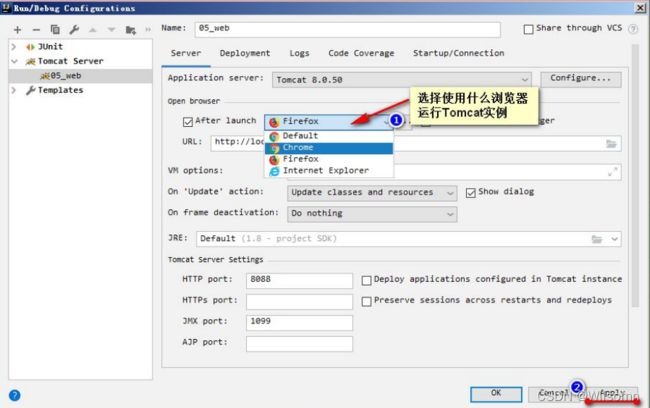
修改运行使用的浏览器
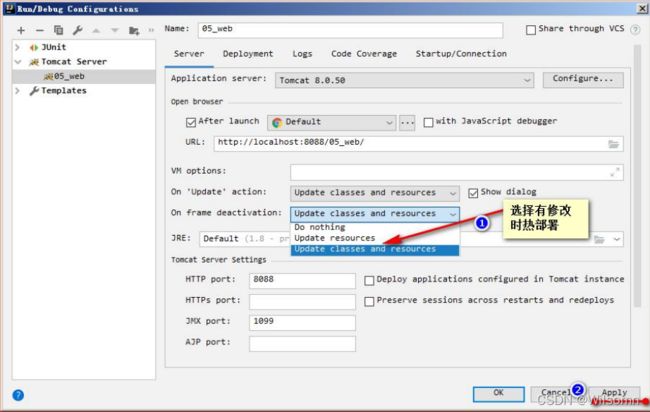
配置资源热部署