linux内存管理和映射
【摘要】本文主要讲述linux内核中内存管理及映射的相关理论。
1、地址类型
-
用户虚拟地址(User virtual addresses)
这是被用户程序见到的常规地址。用户地址依赖于底层的硬件结构,在长度上是 32 位或者 64位, 并且每个进程有它自己的虚拟地址空间。
-
物理地址(Physical addresses)
在处理器和系统内存之间使用的地址。物理地址是 32或者 64位。 -
总线地址(Bus addresses)
在外设和内存之间使用的地址。 通常, 它们和处理器使用的物理地址相同。但在一些体系下,提供一个 I/O 内存管理单元(IOMMU),它在总线和主内存之间重映射地址。 一个 IOMMU 可以使事情简单(例如, 使散布在内存中的缓冲对设备看来是连续的)。总线地址是高度特性依赖的。 -
内核逻辑地址(Kernel logical addresses)
这些组成了正常的内核地址空间。这些地址映射了部分(也许全部)主存并且常常被当作是物理内存来对待。在大部分的体系上,逻辑地址和相关物理地址只差一个常量偏移。逻辑地址使用硬件的本地指针大小,并且因此可能不能寻址所有的物理内存。逻辑地址常常存储于 unsigned long 或者 void * 类型的变量中。从 kmalloc 返回的内存就是内核逻辑地址。 -
内核虚拟地址(Kernel virtual addresses )
类似于逻辑地址,它们都是从内核空间地址到物理地址的映射。但内核虚拟地址不必像逻辑地址空间那样具备线性的 一对一到物理地址的映射。但是,所有的逻辑地址都属于内核虚拟地址,而许多内核虚拟地址却不是逻辑地址。例如 vmalloc 分配的内存有虚拟地址(但没有直接物理映射),kmap 函数也返回虚拟地址,虚拟地址常常存储于指针变量。
如果你有逻辑地址, 宏
__pa()(在中定义)返回它关联的物理地址, 物理地址可被 __va()映射回逻辑地址 , 但是只适合低内存页。不同的内核函数需要不同类型地址。
2、物理内存的组织及分配
Linux中内存按大小分为3个级别,从下到上依次为:
- Page: 一个页的大小用常量 PAGE_SIZE (定义在
) 表示,一般为 4k,页是内存的一个最基本的单位。其中的地址用页帧号和页内偏移表示,如果使用 4096字节页, 那么12 位低有效位是页内偏移,并且剩下的高位
指示页帧号(PFN)。移位来在页帧号和地址之间转换是一个相当普通的操作。常量宏 PAGE_SHIFT 告诉你需要移动多少位来进行这个转换。 - Zone: Zone中提供了多个队列来管理page。Zone分为3种:
- ZONE_DMA: 用来存放DMA读取IO设备的数据,内核专用、直接映射。
- ZONE_NORMAL:用来存放内核的相关数据,内核专用、直接映射。
- ZONE_HIGHMEM:高端内存,用来用户进程存放数据,动态映射。
- Node :节点,一个CPU对应着一个Node,一个Node包括一个Zone_DMA、 ZONE_NORMAL、ZONE_HIGHMEM。
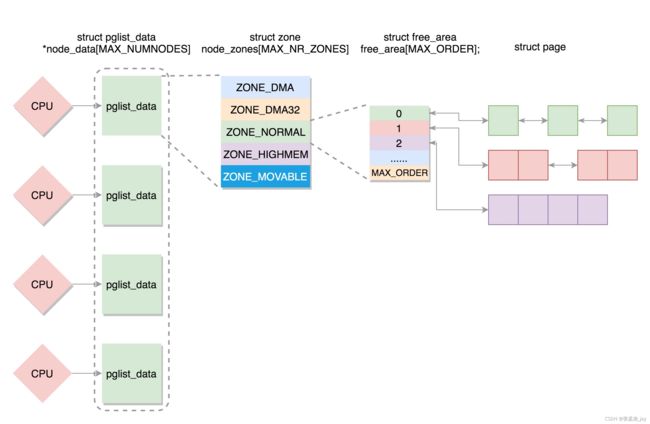
Linux将内存分配分为两种:伙伴分配(大内存)和slab分配(小内存)。
-
伙伴分配:
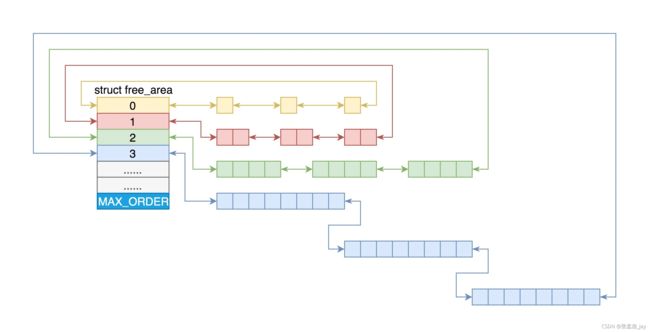
- 将ZONE中的 Page 分组,然后组装为多个链表。链表中存放的是 页块 的集合;
- 页块对应着有不同的大小,分别为 1、2、4、8 … 1024个页。
- 当请求(2i-1 ,2i]大小的 page 的时候,会直接请求2i 个页, 如果对应的链表中有对应的页块,就直接分配。如果对应的链表没有,就往上找 2i+1,如果2i+1存在,就将其分为 2 个 2i 页块,将其中1个2i加入到对应的链表中,将另外一个分配出去。
-
slab分配:

- slub方法主要用于分配一些内核的数据对象。就是 将几个页单独拎出来 作为缓存,里面也维护了链表。每次直接从链表中获取对应的内存,用完之后也不用清空,就直接挂到链表上,然后等待下次利用。
3、虚拟地址空间的概念
虚拟地址对应的是虚拟空间,虚拟空间是全部虚拟地址的集合,用来映射物理内存。
1. 虚拟地址分类
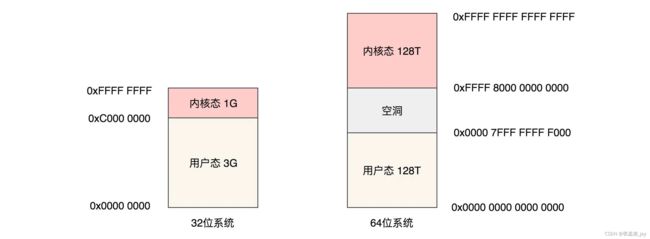
虚拟空间分为 用户态 和 内核态。
32位系统中 将虚拟空间按照 1:3的比例分配给 内核态 和 用户态
64位系统中 分别给 内核态 和 用户态 分配了 128T。
在32位系统中,每个进程都有4G的虚拟地址空间,其中3G用户空间,1G内核空间(linux),进程间共享内核空间,但独享用户空间,下图形象地表达了这点

2. 用户态的存储结构
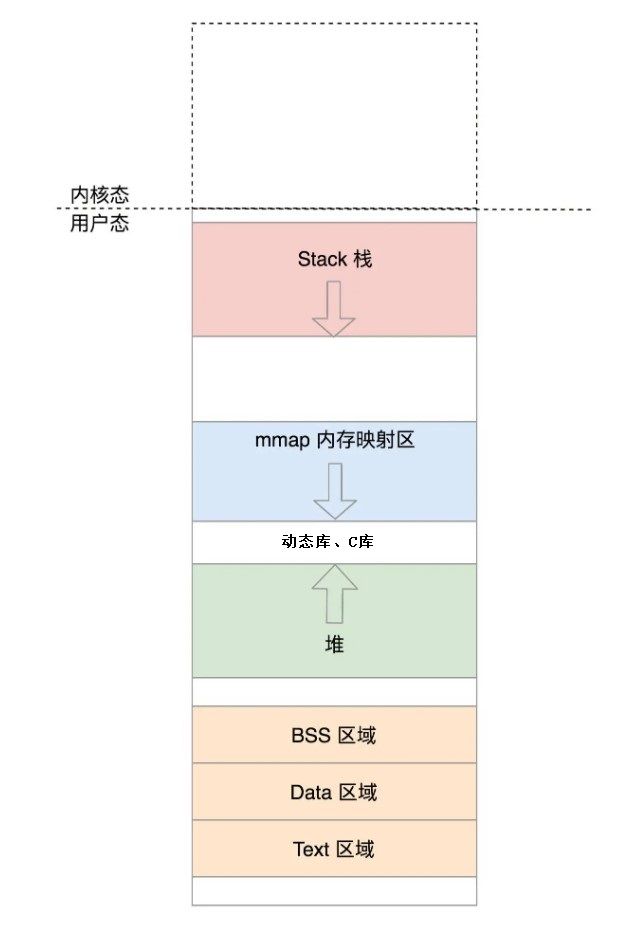
-
一个进程对应的用户态中的 各个方面的虚拟地址信息都通过一个
struct mm_struct来存储在内存中,当创建进程的时候会为其分配内存存储对应的虚拟地址信息。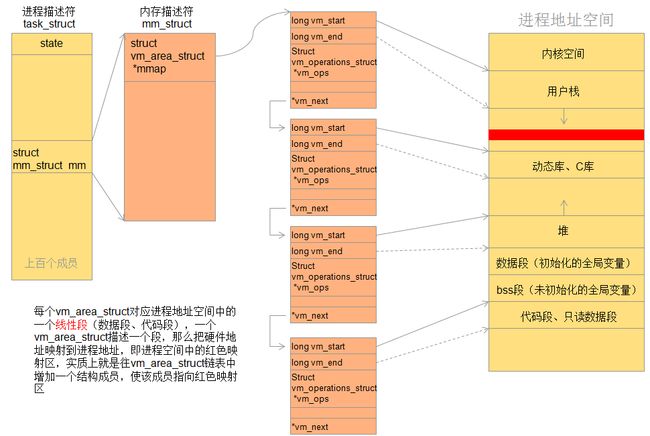
- vm_area_struct 结构
- 当一个用户空间进程调用 mmap 来映射设备内存到它的地址空间, 系统通过一个新 VMA 代表那个映射来响应。一个支持 mmap 的驱动(并且, 因此, 实现mmap 方法)需要来帮助那个进程来完成那个 VMA 的初始化 。
- VMA结构体的主要成员:
- unsigned long vm_start;
unsigned long vm_end; 映射到的虚拟地址范围 - struct file *vm_file; 指向和这个区(如果有一个)关联的 struct file 结构的指针。
- unsigned long vm_pgoff; 文件中区的偏移(以页计)。 当一个文件和设备被映射, 这是映射在这个
区的第一页的文件位置。 - unsigned long vm_flags; 描述这个区的一套标志。设备驱动编写者关注的标志是 VM_IO 和
VM_RESERVUED。VM_IO 标志 VMA 作为内存映射的 I/O 区。VM_RESERVED 标志该VMA不能被交换出内存,它应当在大部分设备映射中设置。 - struct vm_operations_struct *vm_ops; 内核可能会调用来在这个内存区上操作的一套函数,包括如下函数:
void (*open)(struct vm_area_struct *vma);任何时候一个新的引用VMA 时,它被调用来初始化VMA。void (*close)(struct vm_area_struct *vma);当一个区被销毁, 内核调用它的关闭操作struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);当一个进程试图存取使用一个有效 VMA 的页, 但是它当前不在内存中时,nopage 方法被调用以返回一个页指针,否则若nopage没被定义,则返回一个空页。int (*populate)(struct vm_area_struct *vm, unsigned long address, unsigned long len, pgprot_t prot, unsigned long pgoff, int nonblock);在某些页被用户空间存取之前,内核先将其预借到内存。通常驱动没有必要来实现这个填充方法。void *vm_private_data;驱动可以用来存储它的自身信息的成员。
- unsigned long vm_start;
- vm_area_struct 结构
-
内存映射mmap就是把设备地址映射到上图的红色段了,暂且称其为“内存映射段”,至于映射到哪个地址,是由操作系统分配的。
-
一个进程的内存区可看到通过命令
cat /proc/来查看, 当前进程可采用/maps cat /proc/self/maps查看# cat /proc/self/maps 00400000-00405000 r-xp 00000000 03:01 1596291 /bin/cat text 00504000-00505000 rw-p 00004000 03:01 1596291 /bin/cat data 00505000-00526000 rwxp 00505000 00:00 0 bss 3252200000-3252214000 r-xp 00000000 03:01 1237890 /lib64/ld-2.3.3.so 3252300000-3252301000 r--p 00100000 03:01 1237890 /lib64/ld-2.3.3.so 3252301000-3252302000 rw-p 00101000 03:01 1237890 /lib64/ld-2.3.3.so 7fbfffe000-7fc0000000 rw-p 7fbfffe000 00:00 0 stack ffffffffff600000-ffffffffffe00000 ---p 00000000 00:00 0 vsyscall 每行的字段是:start-end perm offset major:minor inode image
3. 内核态的存储结构

Linux中的内核程序 共用一个 内核态虚拟空间。其中分为了以下几部分:
1、直接映射区
896M,内核空间直接映射到对应的ZONE_DMA和ZONE_NORMAL中。为什么叫做直接映射呢? 逻辑地址 直接 减去对应的差值就可以得到对应的物理地址。固定死了。
2、动态映射
因为所有物理内存的分配都需要内核程序进行申请,用户进程没有这个权限。所以内核空间一定要能映射到所有的物理内存地址。那么如果都采用直接映射的话,1G大小逻辑地址的内核空间只能映射1G大小的物理内存。所以引入了动态映射。
动态映射就是 内核空间的逻辑地址可以映射到 物理内存中的ZONE_HIGHMEM(高端内存)中的任何一个地址,并且在对应的物理内存使用完之后,可以再映射其他物理内存地址。
动态映射分为三种:
- 动态内存映射 :使用完对应的物理内存后,就可以映射其他物理内存了。
- 持久内存映射: 一个虚拟地址只能映射一个物理地址。如果需要映射其他物理地址,需要解绑。
- 固定内存映射: 只能被某些特定的函数来调用引用物理地址。
3、动态内存映射和直接映射的区别
动态映射和直接映射的区别就是逻辑地址到物理地址的转化规则。直接映射的规则是死的,一个逻辑地址对应的物理地址是固定的。通过逻辑地址加或者减去一个数,就可以得到对应的物理地址。动态映射是动态的绑定,每个逻辑地址对应的物理地址是动态的,通过页表进行查询
用户空间映射:用户空间 采用 动态映射,每个虚拟地址可以被映射到一个物理地址,映射到ZONE_HIGHMEM。为什么用户空间不采用直接映射呢?因为物理内存是多个进程所有的,每个进程都有一个用户空间。如果采用直接映射的话,对应的物理地址是会冲突的。其用户空间的逻辑地址大小都为3G,所以存在逻辑地址相同,但是对应的物理地址不同。需要通过页表来转化,一个进程会对应一个页表。
4、虚拟地址映射到物理内存(内存映射)
虚拟地址通过 页表 将 虚拟地址 转化为 物理地址。每个进程都对应着一个页表,而内核只有一个页表。
虚拟空间 和 物理内存 都按照 4k 来分页,一个虚拟空间中的页 和 物理内存中页 是 一一对应的。
映射流程图:

用户态申请内存时,只会申请对应的虚拟地址,不会直接为其分配物理内存,而是等到真正访问内存的时候,产生缺页中断,然后内核才会为其分配,然后为其建立映射,也就是建立对应的页表项。
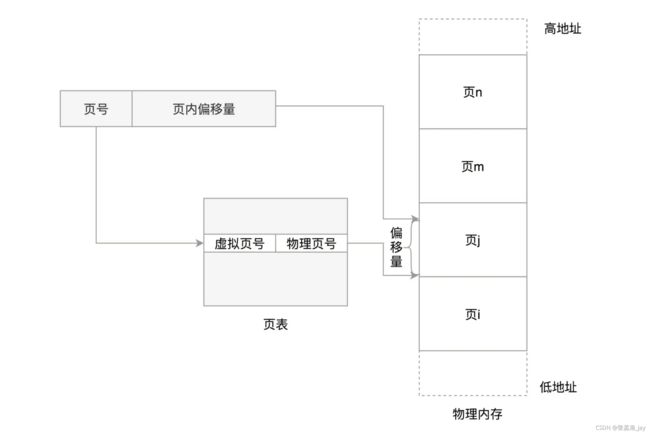
1.页表映射原理
如下图所示,将虚拟地址中的页号 通过页表转化为 对应的物理页号,然后通过页内偏移量 就可以得到对应的 物理地址了。
2.三级页表(32位系统)
一个进程需要一个映射4G空间的页表,每个页表对应4KB大小,所以就需要1M个页表记录来描述。
假如 1 个 页表记录需要 4个字节,那么就需要 4MB。而且页表记录是通过下标来对应的,通过虚拟页号来乘以对应的页表项大小来计算得到对应的地址的。所以Linux将 4M 分为 1K个 4K, 一个4K对应着一个page,用来存储对应的真正的页表记录。将 1K 个 page 分开存放,就不要求连续的4M了。
如果将4M 分成 1K 个离散的 page的话,虚拟地址又怎么对应的页表号呢?利用指针,存储1K个地址,分别指向这1K个page, 地址的大小为4个字节,也就是32位,完全可以表示整个内存的地址范围。1K * 4个字节,正好是一个page 4k,所以 也就是利用 1个 page来存储对应的页表记录索引。
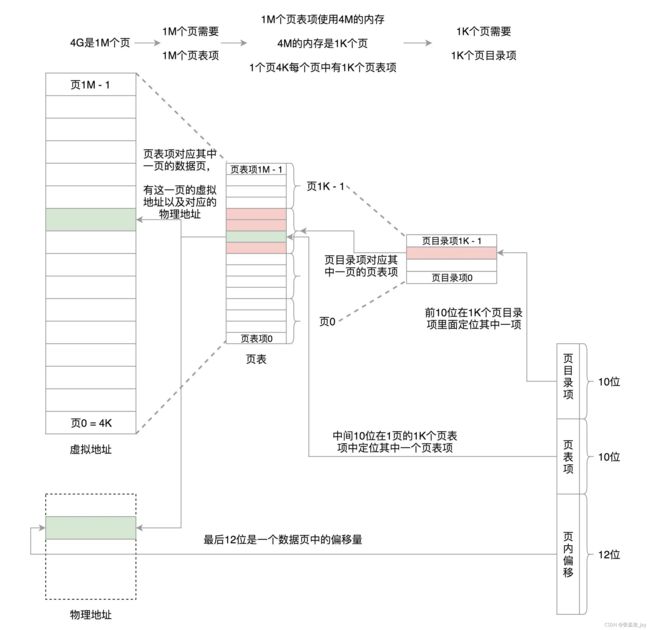
所以 我们的虚拟地址寻找过程如下:
- 找到对应的页表记录索引位置,因为有1K个索引,所以用10位就可以表示了
- 通过索引可以找到对应的真正的页表地址,对应的有1K个页表记录,所以用10位就可以表示了
- 1个页有4K,通过12位就可以表示其页内偏移量了。
所以虚拟地址被分为了三部分:
- 10位 表示索引偏移
- 10位 表示页表记录偏移
- 12位 表示页内偏移
虽然这种方式增加了索引项,进而增加了内存消耗,但是减少了连续内存的使用,通过离散的内存就可以存储页表。
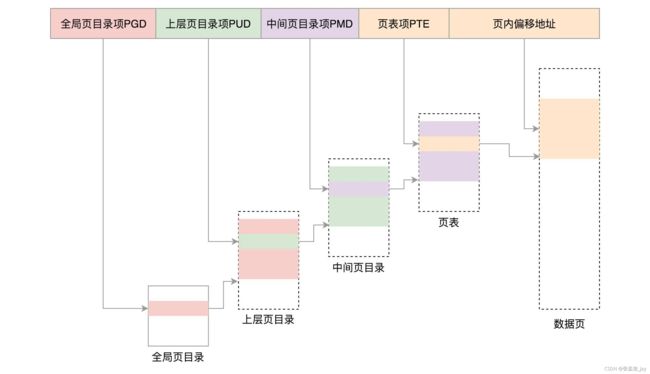
3.五级页表(64位系统)
4.TLB和虚拟内存
- TLB
TLB就是一个缓存,放在CPU中。用来将虚拟地址和对应的物理地址进行缓存。
当查询对应的物理地址的时候,首先查询TLB,如果TLB中存在对应的记录,就直接返回。如果不存在,就再去查询页表。
- 虚拟内存
虚拟内存 指的是 将硬盘中划出一段 swap分区 当作 虚拟的内存,用来存放内存中暂时用不到的内存页,等到需要的时候再从 swap 分区中 将对应的内存页调入到 内存中。 硬盘此时相当于一个虚拟的内存。
从逻辑上能够运行更大内存的程序,因为程序运行的时候并不需要把所有数据都加载到内存中,只需要将当前运行必要的相关程序和数据加载到内存中就可以了,当需要其他数据和程序的时候,再将其调入。
相较于真正的内存加载,虚拟内存需要将数据在内存和磁盘中不断切换,这是一个耗时的操作,所以速度比不上真正的内存加载。
小结:
- 虚拟空间 和 物理内存 都分为 内核空间 和 用户空间。
- 虚拟地址需要通过页表转化为物理地址,然后才能访问。
- 用户虚拟空间 只能映射 物理内存中的用户内存,无法映射到物理内存中的内核内存,也就是说,用户进程只能操作用户内存。
- 内核空间 只能被 内核 申请使用,用户进程只能操作用户空间的物理内存和虚拟空间。
- 当用户进程 调用系统调用的时候,会将其对应的代码和数据运行在内核空间中。所以当调用 内核空间 读取文件或者网络数据的时候,首先会将数据拷贝到内存空间,然后在将数据从内核空间拷贝到用户空间。因为 用户进程不能访问内核空间。
5. struct page及其操作接口
系统中每一个物理页有一个 struct page。这个结构的一些成员包括下列:
atomic_t count:这个页的引用数。当这个 count 掉到 0,这页被返回给空闲列表。void *virtual:如果这页被映射,它就代表该页在内核中的虚拟地址,否则设为NULL。低内存页一直被映射,高内存页常常不是. 这个成员不是在所有体系上出现; 它通常只在页的内核虚拟地址无法轻易计算时被编译. 如果你想查看这个成员, 正确的方法是使用 page_address 宏。unsigned long flags:一套描述页状态的位标志。这些包括 PG_locked(它指示该页在内存中已被加锁)以及 PG_reserved(它防止内存管理系统使用该页)。
在 struct page 指针和虚拟地址之间转换的函数和宏:
-
struct page *virt_to_page(void *kaddr);
这个宏, 定义在, 采用一个内核逻辑地址并返回它被关联的 struct page 指针。 因为它需要一个逻辑地址,它不使用来自vmalloc 的内存或者高内存。 -
struct page *pfn_to_page(int pfn);
为给定的页帧号返回 struct page 指针。在向pfn_to_page传递页帧号之前,一般使用 pfn_valid() 来检查一个页帧号的有效性。 -
void *page_address(struct page *page);
返回一个页的内核虚拟地址。对于高内存,仅当这个页已被映射才存在那个虚拟地址。这个函数在中定义,但在大部分情况下, 建议使用 kmap来代替它。 kmap为系统中的任何页返回一个内核虚拟地址。对于低内存页它只返回页的逻辑地址,对于高内存页 kmap 在内核地址空间的一个专用部分中创建一个特殊的映射。使用 kmap 创建的映射应当使用 kunmap 来释放。因为kmap 调用维护一个计数器,即同时调用kmap的映射是有数量限制的,因此最好不要在它们上停留太长时间。还要注意 kmap 在没有映射可用时可能会睡眠。其原型如下:
#includevoid *kmap(struct page *page); void kunmap(struct page *page); -
kmap_atomic是 kmap 的一种高性能形式。每种体系结构都给原子的 kmap维护一些 专用的页表项, kmap_atomic 的调用者必须在type 参数中告知系统使用哪个专用的页表项。 对驱动有意义的唯一页表项类型是 KM_USER0 和 KM_USER1 (对于直接从来自用户空间的调用运行的代码),以及 KM_IRQ0 和 KM_IRQ1(对于从中断处理中调用)。 注意:原子的 kmap 必须被原子地处理。调用程序不能在持有一个kmap时睡眠。其原型如下:#include#include void *kmap_atomic(struct page *page, enum km_type type); void kunmap_atomic(void *addr, enum km_type type);
- 【参考文章列表】:
- LDD3
- Linux驱动mmap内存映射
- Linux中内存管理详解