Mysql视图和分区表
Mysql视图和分区表
视图
视图(View)是一个命名的虚表,由一个SQL查询来定义,可以当作表使用。与持久表不同的是,视图种的数据没有实际的物理存储。
作用
主要用途是被用做一个抽象装置,程序不需要关心基础表的结果,只需按照视图定义来读取数据或更新数据。带来如下好处:
-
提高重用性。例如需要经常查询某表中的部分数据。
--将查询的结果存为视图,不用每次再从基础表中进行条件查询。
-
对数据库重构,不影响程序的运行。
--对表的拆分或连接,直接用视图来标识新表的结构,不需要直接操作基础表
-
提高安全性,对不同的用户设定不同的视图。
用户可以对视图进行更新操作,本质就是通过视图的定义来更新基本表。可进行更新操作的视图称为可更新视图。
基本使用
创建
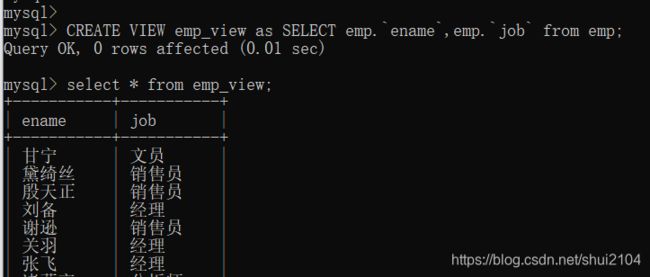
create view 视图名 as select 字段名 from 表名;
删除
drop view 视图名[,视图名…];
重命名
Rename table 视图名 to 新视图名;
查看
show tables;
show tables;会将表和视图都显示出来。
如果只显示基础表,可以通过information_sechma架构下的TABLE表来查询
select * from information_schema.tables where table_type='BASE TABLE' and table_schema=database(); 同样,所有视图的信息在information_schema.VIEWS下。
select * from information_schema.views where table_schema=database();
分区表
概述
分区的过程是将一个表或索引分成多个更小、更容易管理的部分。就访问数据库的应用而言,从逻辑上看,只有一个表或者索引,但是在物理上这个表或索引可能由多个物理分区来组成。每个分区都是独立的对象,可以单出处理,也可以作为更大对象的一部分。
Mysq支持的分区类型为水平分区,不支持垂直分区。Mysql的分区时局部分区索引。
垂直分区:同一个表中的不同列记录分配到不同的物理文件中。
水平分区:同一个表中的不同行记录分配到不同的物理文件中。
全局分区:一个分区中即存放了数据又存放了索引。
局部分区:数据存放在各分区中,所有数据的所有存放在一个对象中。
创建分区时,如果表中存在主键或唯一索引,分区列必须时唯一索引的一个组成部分。
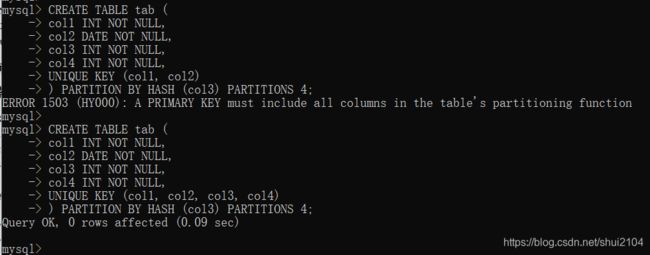
如果表中没有指定主键,唯一索引,分区列可以时任意列。
分区类型
RANGE
行数据基于一个给定连续范围分区。
CREATE TABLE tab (
id INT
)ENGINE=INNODB
PARTITION BY RANGE (id)(
PARTITION p0 VALUES less than (10),
PARTITION p1 VALUES less than (20)
);
上表中,由于设定了id字段的范围,无法插入范围外的值。比如当插入30的时候,将抛出异常。因此,可以增加一个分区,将上限设置为maxvalue。
alter table tab add PARTITION( PARTITION p2 values less than maxvalue );
对于RANGE分区的查询,优化器只能对**YEAR(),TO_DAYS(),TO_SECONDS(),UNIX_TIMESTAMP()**这类函数进行优化选择。
LIST
同RANGE,区别在于给定的不是连续范围,是离散的值。
CREATE TABLE tab (
a INT,
b INT
)ENGINE=INNODB
PARTITION BY LIST (b)(
PARTITION p0 VALUES IN (1,3,5,7,9),
PARTITION p1 VALUES IN (0,2,4,6,8)
);
不同与Range分区定义中的VALUES less than,List分区使用的时VALUES IN。
在批量插入时,InnoDB将其看作为一个事务,只要一条插入失败,所有数据均不插入。而MyISAM存储引擎会将之前的数据插入,之后的数据不会插入。
HASH
根据用户自定义的表达式的返回值进行分区,返回值不能是负数。
目的:将数据均匀的分布到各个分区中,保证各分区的数据数量大致一样。
在RANGE和LIST分区中,需要明确指定列值的范围或者集合,来确保某一条记录应该存放在哪一个分区。而在HASH分区中,Mysql字段完成,用户所要作的只是基于将要进行哈希分区的列值指定一个列值或者表达式,已经指定被分区的表将要分成几个区。
CREATE TABLE tab (
a INT,
b DATETIME
)ENGINE=INNODB
PARTITION BY HASH (YEAR(b))
PARTITIONS 4;
PARTITION BY HASH(expr)子句,其中expr是一个返回整数的表达式;可以是字段类型为Mysql整型的列名。
PARTITIONS num子句,表示分区的个数,如果没有次子句,则默认的分区数量是1。
如果插入日期为2020-08-07,那么该记录将保存在p0分区,计算如下:
MOD(YEAR(‘2020-08-07’),4)=MOD(2020,4)=0
MySQL支持使用更复杂算法来确定新记录插入分区的LINEAR HASH分区,语法为 linear hash(expr),只是将关键字 HASH 换成了 LINEAR HASH。
CREATE TABLE tab (
a INT,
b DATETIME
)ENGINE=INNODB
PARTITION BY LINEAR HASH (YEAR(b))
PARTITIONS 4;
同一插入日期为2020-08-07的记录,分区判断过程如下:
-
取大于分区数量4的下一个2的幂值V:V=power(2, celing(log(2, num)))=4;(num是分区数量partitions,本例中是4)
-
分区N=year(date)&(V-1)=0
LINEAR HASH分区的优点:增加、删除、合并和拆分分区变得更加快捷,这有利于处理含有大量数据的表
与HASH分区相比缺点:数据分布可能不大均匀。
KEY
和HASH分区相似,不同的是根据MySQL内部提供的哈希函数进行分区。
对于NDB Cluster引擎Mysql使用MD5函数来分区;其他引擎,Mysql使用其内部的哈希函数,这下函数基于与PASSWORD()一样的运算法则。
CREATE TABLE tab (
a INT,
b DATETIME
)ENGINE=INNODB
PARTITION BY KEY(b)
PARTITIONS 4;
COLUMNS
前面4中,分区的字段均为整型,或者将其转换为整型。COLUMNS分区可以直接使用非整型数据进行分区,支持的类型:
- 所有的整型,INT、SMALLINT、TINYINT…
- 日期类型,DATE和DATETIME
- 字符串类型,CHAR、VARCHAR、BINARY和VARBINARY。
同时还支持多个列进行分区
CREATE TABLE tab (
a INT,
b INT,
c char(3)
)ENGINE=INNODB
PARTITION BY RANGE COLUMNS (a,b,c)(
PARTITION p0 VALUES less than (5,10,'ggg'),
PARTITION p1 VALUES less than (10,20,'mmm'),
PARTITION p2 VALUES less than (15,30,'uuu'),
PARTITION p3 VALUES less than (MAXVALUE,MAXVALUE,MAXVALUE)
);
移除分区:ALTER TABLE tablename REMOVE PARTITIONING ; 删除分区:ALTER TABLE tablename DROP PARTITIONING ;移除分区仅仅修改表分区定义,数据不会被删除;删除分区会删除分区定义同时删除分区上的数据。
子分区
Mysql允许在RANGE和LIST分区上在进行Hash和Key分区。如:
CREATE TABLE tb_sub_ev (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
子分区的建立需要注意的问题:
- 每个子分区的数量必须相同。
- 要在一个分区表的任何分区上使用SUBPARTITION来明确定义任何子分区,就必须定义所有的子分区。
- 每个SUBPARTITION子句必须包括子分区的一个名字。
- 子分区名字必须是唯一的。
分区表中的NULL
Mysql允许对NULL做分区,在Mysql中将NULL视为小于任何一个非NULL值。
- 对于Range分区,如果分区列插入NULL值,则Mysql会将该值放入最左边的分区。
- 对于List分区,需要显示的指定NULL放在哪一个分区。
- HASH和KEY分区,NULL值通过分区函数返回的均是0。
分区和性能
数据库的应用分为两类:
-
OLAP:在线分析能力
这种情况下,大多数查询都要频繁的扫描一张很大的表。比如几亿行数据的表,经常需要获取某时间段的数据,按照时间戳列分区,只需扫描对应的分区即可。
-
OLTP:在线事务处理
这种情况下,通常都是获取表中几行记录,而不是获取大表的10%的数据。比如1000W的数据按照主键做10分Hash分区,因为每个分区大概为100W数据,因此查询变快了。不过,千万数据和百万数据够成的B+树索引可能都是2层,那么上述主键分区的索引并不会代理性能的提升。如果千万级别的数据B+树为3层,百万级别的为2层,上述按主键分区的索引可避免一次IO,提升了效率。但是如果这张表只有主键索引,那么对于KEY的查询需要扫描所有的分区,每个分区2次IO,总共就需要20次IO,这种情况不但没有提升效率,反而查询变慢了。所以对于这种情况,分区不一定会带来效率的提升,要按照实际情况小心处理。