YOLOv5-PTQ量化部署
目录
-
- 前言
- 一、PTQ量化浅析
- 二、YOLOv5模型训练
-
- 1. 项目的克隆和必要的环境依赖
-
- 1.1 项目克隆
- 1.2 项目代码结构整体介绍
- 1.3 环境安装
- 2. 数据集和预训练权重的准备
-
- 2.1 数据集
- 2.2 预训练权重准备
- 3. 训练模型
-
- 3.1 修改数据配置文件
- 3.2 修改模型配置文件
- 3.3 训练模型
- 3.4 mAP测试
- 三、YOLOv5-PTQ量化部署
-
- 1. 源码下载
- 2. 环境配置
-
- 2.1 配置CMakeLists.txt
- 2.2 配置Makefile
- 3. ONNX导出
-
- 3.1 静态batch导出
- 3.2 动态batch导出
- 4. PTQ量化
-
- 4.1 前置工作
- 4.2 源码修改
- 4.3 编译运行
- 4.4 PTQ模型mAP测试
- 四、讨论
-
- 1. 校准图片数量
- 2. 不同精度模型对比
- 结语
- 下载链接
- 参考
前言
博主又来水文章了,最近在学习 YOLOv5 QAT 量化相关的一个 repo,本来想和大家直接分享 QAT 量化的,但转念一想貌似还可以水一篇 PTQ 量化的文章,因此博主就准备在这篇文章中分享基于 YOLOv5 的 PTQ 量化部署的相关实现,具体实现在 tensorRT_Pro 这个 repo 中已经提供,博主只是简单过了一遍流程。
博主为初学者,欢迎交流讨论,若有问题欢迎各位看官批评指正!!!
一、PTQ量化浅析
在正式开始之前我们先来回顾下关于 PTQ 量化的一些知识,具体可参考:TensorRT量化第四课:PTQ与QAT
TensorRT 有两种量化模式,分别是隐式(implicitly)量化和显式(explicitly)量化。前者在 TRT7 版本之前用得比较多,而后者在 TRT8 版本后才完全支持,具体就是可以加载带有 QDQ 信息的模型然后生成对应量化版本的 engine。
这篇文章主要分享隐式量化即 PTQ 量化,关于显式量化即 QAT 量化我们将在下篇文章中分享。
PTQ(Post-Training Quantization)即训练后量化也叫隐式量化,tensorRT 的训练后量化算法第一次公布是在 2017 年,那年 NVIDIA 放出了使用交叉熵量化的一个 PPT,简单说明了其量化原理和流程,其思想集中在 tensorRT 内部可供用户去使用。对用户是闭源的,我们只能通过 tensorRT 提供的 API 去实现量化。
PTQ 量化不需要训练,只需要提供一些样本图片,然后在已经训练好的模型上进行校准,统计出来需要的每一层的 scale 就可以实现量化了,大概流程如下:
- 在准备好的校准数据集上评估预训练模型
- 使用校准数据来校准模型(校准数据可以是训练集的子集)
- 计算网络中权重和激活的动态范围用来算出量化参数 q-params
- 使用 q-params 量化网络并执行推理

具体使用就是我们导出 ONNX 模型,转换为 engine 的过程中使用 tensorRT 提供的 Calibration 方法去校准,可以使用 tensorRT 官方提供的 trtexec 工具去实现,也可以使用它提供的 Python 或者 C++ 的 API 接口去实现。
在 tensorRT_Pro 中 INT8 模型的编译就是 PTQ 量化,因此我们只需要提供好 ONNX 模型和校准数据即可,其它不用我们关心。
tensorRT 还提供了多种校准算法,分别适用于不同的任务:
- EntropyCalibratorV2:适合于基于 CNN 的网络
- MinMaxCalibrator:适合于 NLP 任务,如 BERT
- EntropyCalibrator:老版本的交叉熵校准
- LegacyCalibrator
通过上述这些校准算法进行 PTQ 量化时,tensorRT 会在优化网络的时候尝试 INT8 精度,假设网络某一层在 INT8 精度下的速度优于默认精度(FP32/FP16),则优先使用 INT8。
值得注意的是,PTQ 量化中我们无法控制某一层的精度,因为 tensorRT 是以速度优化为优先的,很可能某一层你想让它跑 INT8 结果却是 FP16,当然 PTQ 优点是流程简单,速度快。
OK!关于 PTQ 量化我们就简单聊下,让我们开始具体的实现吧!!!
二、YOLOv5模型训练
首先我们需要训练一个 YOLOv5 模型,当然拿官方的预训练权重也行,博主这边为了完整性还是整体走一遍流程,熟悉 YOLOv5 模型训练的看官可以跳过直接到量化部分。
1. 项目的克隆和必要的环境依赖
1.1 项目克隆
yolov5 的代码是开源的可直接从 github 官网上下载,源码下载地址是 https://github.com/ultralytics/yolov5/tree/master,由于 yolov5 版本较多,本次采用 yolov5-v7.0 分支进行模型的训练和量化部署工作。
Linux 下代码克隆指令如下:
git clone -b v7.0 https://github.com/ultralytics/yolov5.git
也可以手动点击下载,首先点击左上角切换成 v7.0 分支,如下图所示:
然后点击右上角的 Code 按键将代码下载下来,如下图所示:
至此整个项目就已经准备好了,也可以点击 here【pwd:yolo】下载博主准备好的代码。
1.2 项目代码结构整体介绍
将下载后的 yolov5-7.0 的代码解压,其代码目录如下图:

现在来对代码的整体目录做一个介绍
- |-classify:用于存放使用 yolov5 做分类的一些文件
- |-data:主要是存放一些超参数的配置文件(如yaml文件、sh脚本文件),用来配置训练集和验证集还要测试集的路径的;还要一些官方提供的测试图片,后续我们要训练自己的数据集需要修改其中的 yaml 文件。
- |-models:这里面主要是一些网络构建的配置文件和模块文件,其中包含了 n、s、m、l、x 五个不同的版本,它们的检测速度从快到慢,但精度从低到高。如果训练自己的数据集,需要修改对应的 yaml 文件
- |-segment:用于存放使用 yolov5 做分割的一些文件
- |-utils:主要存放工具类函数,比如 loss 损失函数,plot 绘图函数,metrics 函数等等
- detect.py:该文件主要功能是利用训练好的模型进行推理检测,可以进行图像、视频和摄像头的检测
- export.py:该文件主要功能是将训练好的 pytorch 模型导出为其它格式的模型,如 ONNX、TensorRT、OpenVINO 等等
- train.py:该文件主要功能是利用 yolov5 训练自己的数据集
- val.py:该文件主要功能是测试训练好的 yolov5 模型的 mAP
- requirements.txt:这是一个文本文件,包含使用 yolov5 项目所依赖的第三方库的版本
以上就是 yolov5 项目代码的整体介绍,我们训练和量化部署基本使用上面的代码就够了
1.3 环境安装
关于深度学习的环境安装可参考炮哥的利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学),这里不再赘述。
2. 数据集和预训练权重的准备
2.1 数据集
这里训练采用的数据集是 PASCAL VOC 数据集,但博主并没有使用完整的 VOC 数据集,而是选用了部分数据,具体分布如下:
- 训练集:(VOC2007train + VOC2007val) x 80% = 4013
- 验证集:(VOC2007train + VOC2007val) x 20% = 998
- 测试集:0
这里给出下载链接 Baidu Drive【pwd:yolo】下载解压后整个数据集文件夹内容如下图所示:
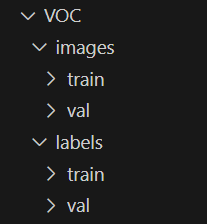
其中 images 存放训练集和验证集的图片文件,labels 存放着对应的 YOLO 格式的 .txt 文件。
完整的 VOC 数据集的相关介绍和下载可参考:目标检测:PASCAL VOC 数据集简介
由于大家可能从其它地方拿到的是 XML 格式的标签文件,这里提供一个 XML2YOLO 转换的代码,如下所示:(from chatGPT)
import os
import cv2
import xml.etree.ElementTree as ET
import shutil
from multiprocessing import Pool, cpu_count
from tqdm import tqdm
import numpy as np
from functools import partial
def process_xml(xml_filename, img_path, xml_path, img_save_path, label_save_path, class_dict, ratio):
# 解析 xml 文件
xml_file_path = os.path.join(xml_path, xml_filename)
tree = ET.parse(xml_file_path)
root = tree.getroot()
# 获取图像的宽度和高度
img_filename = os.path.splitext(xml_filename)[0] + ".jpg"
img = cv2.imread(os.path.join(img_path, img_filename))
height, width = img.shape[:2]
# 随机决定当前图像和标签是属于训练集还是验证集
subset = "train" if np.random.random() < ratio else "val"
# 打开对应的标签文件进行写入
label_file = os.path.join(label_save_path, subset, os.path.splitext(xml_filename)[0] + ".txt")
with open(label_file, "w") as file:
for obj in root.iter('object'):
# 获取类别名并转换为类别ID
class_name = obj.find('name').text
class_id = class_dict[class_name]
# 获取并处理边界框的坐标
xmlbox = obj.find('bndbox')
x1 = float(xmlbox.find('xmin').text)
y1 = float(xmlbox.find('ymin').text)
x2 = float(xmlbox.find('xmax').text)
y2 = float(xmlbox.find('ymax').text)
# 计算中心点坐标和宽高,并归一化
x_center = (x1 + x2) / 2 / width
y_center = (y1 + y2) / 2 / height
w = (x2 - x1) / width
h = (y2 - y1) / height
# 写入文件
file.write(f"{class_id} {x_center} {y_center} {w} {h}\n")
# 将图像文件复制到对应的训练集或验证集目录
shutil.copy(os.path.join(img_path, img_filename), os.path.join(img_save_path, subset, img_filename))
def check_and_create_dir(path):
# 检查并创建 train 和 val 目录
for subset in ['train', 'val']:
if not os.path.exists(os.path.join(path, subset)):
os.makedirs(os.path.join(path, subset))
if __name__ == "__main__":
# 1. 定义路径和类别字典,不要使用中文路径
img_path = "D:\\Data\\PASCAL_VOC\\VOCdevkit\\VOC2007\\JPEGImages"
xml_path = "D:\\Data\\PASCAL_VOC\\VOCdevkit\\VOC2007\\Annotations"
img_save_path = "D:\\Data\\PASCAL_VOC\\dataset\\images"
label_save_path = "D:\\Data\\PASCAL_VOC\\dataset\\labels"
class_dict = {
"aeroplane": 0,
"bicycle": 1,
"bird": 2,
"boat": 3,
"bottle": 4,
"bus": 5,
"car": 6,
"cat": 7,
"chair": 8,
"cow": 9,
"diningtable": 10,
"dog": 11,
"horse": 12,
"motorbike": 13,
"person": 14,
"pottedplant": 15,
"sheep": 16,
"sofa": 17,
"train": 18,
"tvmonitor": 19
}
train_val_ratio = 0.8 # 2. 定义训练集和验证集的比例
# 检查并创建必要的目录
check_and_create_dir(img_save_path)
check_and_create_dir(label_save_path)
# 获取 xml 文件列表
xml_filenames = os.listdir(xml_path)
# 创建进程池并执行
with Pool(cpu_count()) as p:
list(tqdm(p.imap(partial(process_xml, img_path=img_path, xml_path=xml_path, img_save_path=img_save_path, label_save_path=label_save_path,
class_dict=class_dict, ratio=train_val_ratio), xml_filenames), total=len(xml_filenames)))
上述代码的功能是将 PASCAL VOC 格式的数据集(包括 JPEG 图像和 XML 格式的标签文件)转换为 YOLO 需要的 .txt 标签格式,同时会将转换后的数据集按照比例随机划分为训练集和验证集。
你需要修改以下几项:
- img_path:需要转换的图像文件路径
- xml_path:需要转换的 xml 标签文件路径
- img_save_path:转换后保存的图像路径
- label_save_path:转换后保存的 txt 标签路径
- class_dict:数据集类别字典
- train_val_ratio:训练集和验证集划分的比例
- 注意:以上路径都不要包含中文,Windows 下路径记得使用
\\或者/防止转义
XML 标签文件中目标框保存的格式是 [xmin, ymin, xmax, ymax] 四个变量,分别代表着未经归一化的左上角和右下角坐标。
YOLO 标签中目标框保存的格式是每一行代表一个目标框信息,每一行共包含 [label_id, x_center, y_center, w, h] 五个变量,分别代表着标签 ID,经过归一化后的中心点坐标和目标框宽高。
关于代码的分析可以参考:tensorRT模型性能测试
至此,数据集的准备工作完毕。
2.2 预训练权重准备
yolov5-7.0 预训练权重可以通过 here 下载,博主也提供了下载好的预训练权重 Baidu Drive【pwd:yolo】,注意这是 yolov5-v7.0 版本的预训练权重,如果你使用的是其它版本,记得替换。本次训练 PASCAL VOC 数据集使用的预训练权重为 yolov5s.pt。

3. 训练模型
将准备好的数据集文件夹即 VOC 复制到 yolov5 项目环境中,将准备好的预训练权重 yolov5s.pt 复制到 yolov5 项目环境中,完整的项目结构如下图所示。训练目标检测模型主要修改 data 文件夹下的数据配置文件 data/VOC.yaml 以及 models 文件夹下的模型配置文件 models/yolov5s.yaml
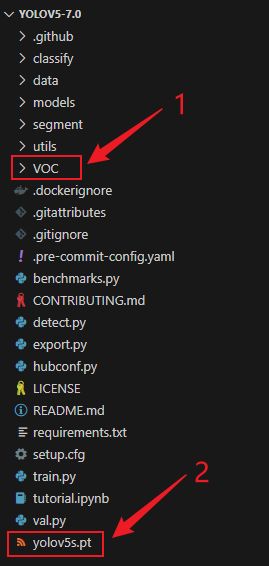
3.1 修改数据配置文件
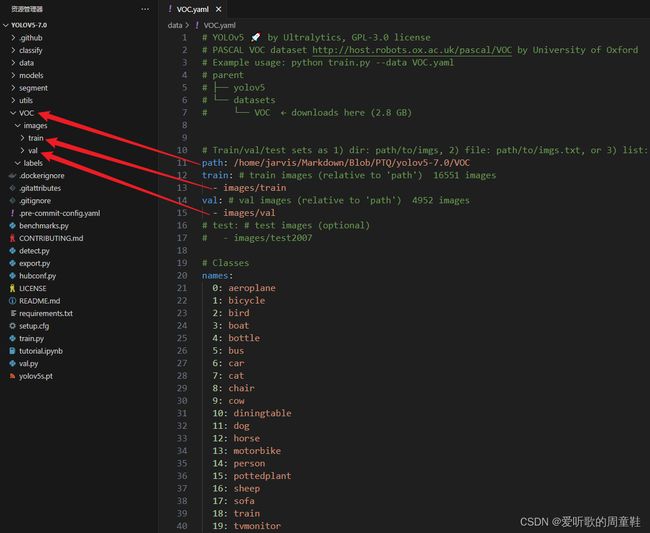
修改 data 目录下相应的 yaml 文件,找到目录下的 VOC.yaml 文件,主要修改如下:
- 1. 修改第 11 行数据集路径
- 2. 修改第 12 行训练集
- 3. 修改第 17 行验证集
- 4. 注释第 19 行测试集,未使用到
- 5. 第 23 行类别数不用修改,如果是其它自定义数据记得修改
- 6. 注释第 47 行自动下载
3.2 修改模型配置文件
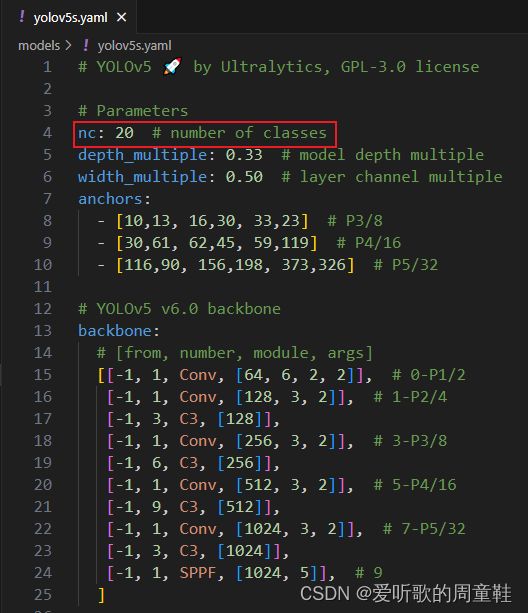
由于该项目使用的是 yolov5s.pt 这个预训练权重,所以需要修改 models/yolov5s.yaml 这个文件(由于不同的预训练权重对应不同的网络结构,所以用错预训练权重会报错)。主要修改 yolov5s.yaml 文件的第 4 行,即需要识别的类别数,由于 PASCAL VOC 数据集识别 20 个类别,故修改为 20 即可,如下所示:
3.3 训练模型
在终端执行如下指令即可开始训练:
python train.py --weights=./yolov5s.pt --cfg=./models/yolov5s.yaml --data=./data/VOC.yaml --epochs=100 --batch-size=16
博主训练的模型为 p5 models 且使用的是单个 GPU 进行训练,显卡为 RTX3060,操作系统为 Ubuntu20.04,pytorch 版本为 1.12.0,训练时长大概 1 小时左右。训练的参数简要解释如下:
- –weights 预训练权重路径
- –cfg 模型配置文件路径
- –data 数据配置文件路径
- –epochs 训练轮数
- –batch_size 每次输入到网络的图片数
还要其它参数博主并未设置,如 –img 图像尺寸 等,大家一定要根据自己的实际情况(如显卡算力)指定不同的参数,如果你之前训练过模型,那我相信这对你来说应该是小 case
训练完成后的模型权重保存在 runs/train/exp/weights 文件夹下,我们使用 best.pt 进行后续模型量化部署即可,这里提供博主训练好的权重文件下载链接 Baidu Drive【pwd:yolo】
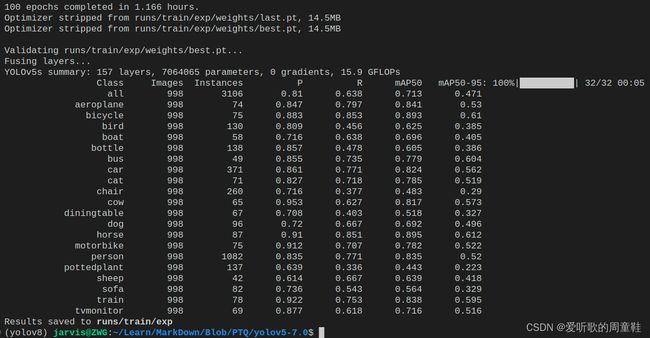
3.4 mAP测试
由于后续我们要对模型进行 PTQ 量化,需要一些指标来衡量模型的性能,mAP 是一个重要的衡量指标。我们需要对比量化前后模型的 mAP,首先来看量化前原始 pytorch 模型的 mAP,测试的数据集直接选用验证集的 998 张图片。
我们将置信度阈值设置为 0.001,NMS 阈值设置为 0.65,方便与后续 PTQ 量化模型对比。
mAP 测试的指令如下:
python val.py --weights runs/train/exp/weights/best.pt --data data/VOC.yaml --img 640 --conf-thres 0.001 --iou-thres 0.65
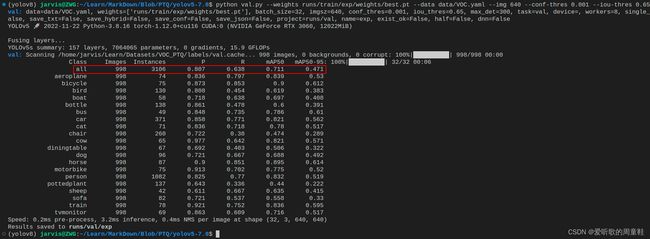
测试完成后的结果会保存在 runs/val/exp 文件夹下,这里总结下原始 pytorch 模型的性能
| Model | Size | mAPval 0.5:0.95 |
mAPval 0.5 |
Params (M) |
FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv5s | 640 | 0.471 | 0.711 | 7.2 | 16.5 |
三、YOLOv5-PTQ量化部署
由于博主手头没有合适的 Jetson 嵌入式设备,因此打算使用自己的主机完成 YOLOv5-PTQ 量化及部署工作,量化部署使用的 repo 是 tensorRT_Pro。
接下来我们主要是针对 tensorRT_Pro 项目中的 YOLOv5 完成 PTQ 模型的量化和部署,体现在 tensorRT_Pro 中其实就是 YOLOv5 的 INT8 量化,本次量化的模型是 YOLOv5s.pt,数据集为 VOC,类别数为 20。
1. 源码下载
tensorRT_Pro 的代码可以直接从 GitHub 官网上下载,源码下载地址是 https://github.com/shouxieai/tensorRT_Pro,Linux 下代码克隆指令如下:
$ git clone https://github.com/shouxieai/tensorRT_Pro
也可手动点击下载,点击右上角的 Code 按键,将代码下载下来。至此整个项目就已经准备好了。也可以点击 Baidu Drive【pwd:yolo】 下载博主准备好的源代码(注意代码下载于 2023/9/24 日,若有改动请参考最新)
2. 环境配置
需要使用的软件环境有 TensorRT、CUDA、cuDNN、OpenCV、Protobuf,所有软件环境的安装可以参考 Ubuntu20.04部署YOLOv5,这里不再赘述,需要各位看官自行配置好相关环境,外网访问较慢,这里提供下博主安装过程中的软件安装包下载链接 Baidu Drive【pwd:yolo】
tensorRT_Pro 提供 CMakeLists.txt 和 Makefile 两种方式编译,二者选一即可
2.1 配置CMakeLists.txt
主要修改六处
1. 修改第 10 行,选择不支持 python (也可选择支持)
set(HAS_PYTHON OFF)
2. 修改第 18 行,修改 OpenCV 路径
set(OpenCV_DIR "/usr/local/include/opencv4/")
3. 修改第 20 行,修改 CUDA 路径
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda-11.6")
4. 修改第 21 行,修改 cuDNN 路径
set(CUDNN_DIR "/usr/local/cudnn8.4.0.27-cuda11.6")
5. 修改第 22 行,修改 tensorRT 路径
set(TENSORRT_DIR "/opt/TensorRT-8.4.1.5")
6. 修改第 33 行,修改 protobuf 路径
set(PROTOBUF_DIR "/home/jarvis/protobuf")
完整的 CMakeLists.txt 的内容如下:
cmake_minimum_required(VERSION 2.6)
project(pro)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/workspace)
# 如果要支持python则设置python路径
set(HAS_PYTHON OFF) # ===== 修改 1 =====
set(PythonRoot "/datav/software/anaconda3")
set(PythonName "python3.9")
# 如果你是不同显卡,请设置为显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute
#set(CUDA_GEN_CODE "-gencode=arch=compute_75,code=sm_75")
# 如果你的opencv找不到,可以自己指定目录
set(OpenCV_DIR "/usr/local/include/opencv4/") # ===== 修改 2 =====
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda-11.6") # ===== 修改 3 =====
set(CUDNN_DIR "/usr/local/cudnn8.4.0.27-cuda11.6") # ===== 修改 4 =====
set(TENSORRT_DIR "/opt/TensorRT-8.4.1.5") # ===== 修改 5 =====
# set(CUDA_TOOLKIT_ROOT_DIR "/data/sxai/lean/cuda-10.2")
# set(CUDNN_DIR "/data/sxai/lean/cudnn7.6.5.32-cuda10.2")
# set(TENSORRT_DIR "/data/sxai/lean/TensorRT-7.0.0.11")
# set(CUDA_TOOLKIT_ROOT_DIR "/data/sxai/lean/cuda-11.1")
# set(CUDNN_DIR "/data/sxai/lean/cudnn8.2.2.26")
# set(TENSORRT_DIR "/data/sxai/lean/TensorRT-7.2.1.6")
# 因为protobuf,需要用特定版本,所以这里指定路径
set(PROTOBUF_DIR "/home/jarvis/protobuf") # ===== 修改 6 ======
find_package(CUDA REQUIRED)
find_package(OpenCV)
include_directories(
${PROJECT_SOURCE_DIR}/src
${PROJECT_SOURCE_DIR}/src/application
${PROJECT_SOURCE_DIR}/src/tensorRT
${PROJECT_SOURCE_DIR}/src/tensorRT/common
${OpenCV_INCLUDE_DIRS}
${CUDA_TOOLKIT_ROOT_DIR}/include
${PROTOBUF_DIR}/include
${TENSORRT_DIR}/include
${CUDNN_DIR}/include
)
# 切记,protobuf的lib目录一定要比tensorRT目录前面,因为tensorRTlib下带有protobuf的so文件
# 这可能带来错误
link_directories(
${PROTOBUF_DIR}/lib
${TENSORRT_DIR}/lib
${CUDA_TOOLKIT_ROOT_DIR}/lib64
${CUDNN_DIR}/lib
)
if("${HAS_PYTHON}" STREQUAL "ON")
message("Usage Python ${PythonRoot}")
include_directories(${PythonRoot}/include/${PythonName})
link_directories(${PythonRoot}/lib)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -DHAS_PYTHON")
endif()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -O0 -Wfatal-errors -pthread -w -g")
set(CUDA_NVCC_FLAGS "${CUDA_NVCC_FLAGS} -std=c++11 -O0 -Xcompiler -fPIC -g -w ${CUDA_GEN_CODE}")
file(GLOB_RECURSE cpp_srcs ${PROJECT_SOURCE_DIR}/src/*.cpp)
file(GLOB_RECURSE cuda_srcs ${PROJECT_SOURCE_DIR}/src/*.cu)
cuda_add_library(plugin_list SHARED ${cuda_srcs})
target_link_libraries(plugin_list nvinfer nvinfer_plugin)
target_link_libraries(plugin_list cuda cublas cudart cudnn)
target_link_libraries(plugin_list protobuf pthread)
target_link_libraries(plugin_list ${OpenCV_LIBS})
add_executable(pro ${cpp_srcs})
# 如果提示插件找不到,请使用dlopen(xxx.so, NOW)的方式手动加载可以解决插件找不到问题
target_link_libraries(pro nvinfer nvinfer_plugin)
target_link_libraries(pro cuda cublas cudart cudnn)
target_link_libraries(pro protobuf pthread plugin_list)
target_link_libraries(pro ${OpenCV_LIBS})
if("${HAS_PYTHON}" STREQUAL "ON")
set(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/example-python/pytrt)
add_library(pytrtc SHARED ${cpp_srcs})
target_link_libraries(pytrtc nvinfer nvinfer_plugin)
target_link_libraries(pytrtc cuda cublas cudart cudnn)
target_link_libraries(pytrtc protobuf pthread plugin_list)
target_link_libraries(pytrtc ${OpenCV_LIBS})
target_link_libraries(pytrtc "${PythonName}")
target_link_libraries(pro "${PythonName}")
endif()
add_custom_target(
yolo
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro yolo
)
add_custom_target(
yolo_gpuptr
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro yolo_gpuptr
)
add_custom_target(
yolo_fast
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro yolo_fast
)
add_custom_target(
centernet
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro centernet
)
add_custom_target(
alphapose
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro alphapose
)
add_custom_target(
retinaface
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro retinaface
)
add_custom_target(
dbface
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro dbface
)
add_custom_target(
arcface
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro arcface
)
add_custom_target(
bert
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro bert
)
add_custom_target(
fall
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro fall_recognize
)
add_custom_target(
scrfd
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro scrfd
)
add_custom_target(
lesson
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro lesson
)
add_custom_target(
pyscrfd
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_scrfd.py
)
add_custom_target(
pyinstall
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python setup.py install
)
add_custom_target(
pytorch
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_torch.py
)
add_custom_target(
pyyolov5
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_yolov5.py
)
add_custom_target(
pycenternet
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_centernet.py
)
2.2 配置Makefile
主要修改六处
1. 修改第 4 行,修改 protobuf 路径
lean_protobuf := /home/jarvis/protobuf
2. 修改第 5 行,修改 tensorRT 路径
lean_tensor_rt := /opt/TensorRT-8.4.1.5
3. 修改第 6 行,修改 cuDNN 路径
lean_cudnn := /usr/local/cudnn8.4.0.27-cuda11.6
4. 修改第 7 行,修改 OpenCV 路径
lean_opencv := /usr/local
5. 修改第 8 行,修改 CUDA 路径
lean_cuda := /usr/local/cuda-11.6
6. 修改第 9 行,选择不支持 python (也可选择支持)
use_python := false
完整的 Makefile 的内容如下:
cc := g++
nvcc = ${lean_cuda}/bin/nvcc
lean_protobuf := /home/jarvis/protobuf # ===== 修改 1 =====
lean_tensor_rt := /opt/TensorRT-8.4.1.5 # ===== 修改 2 =====
lean_cudnn := /usr/local/cudnn8.4.0.27-cuda11.6 # ===== 修改 3 =====
lean_opencv := /usr/local # ===== 修改 4 =====
lean_cuda := /usr/local/cuda-11.6 # ===== 修改 5 =====
use_python := false # ===== 修改 6 =====
python_root := /datav/software/anaconda3
# python_root指向的lib目录下有个libpython3.9.so,因此这里写python3.9
# 对于有些版本,so名字是libpython3.7m.so,你需要填写python3.7m
# /datav/software/anaconda3/lib/libpython3.9.so
python_name := python3.9
# 如果是其他显卡,请修改-gencode=arch=compute_75,code=sm_75为对应显卡的能力
# 显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute
cuda_arch := # -gencode=arch=compute_75,code=sm_75
cpp_srcs := $(shell find src -name "*.cpp")
cpp_objs := $(cpp_srcs:.cpp=.cpp.o)
cpp_objs := $(cpp_objs:src/%=objs/%)
cpp_mk := $(cpp_objs:.cpp.o=.cpp.mk)
cu_srcs := $(shell find src -name "*.cu")
cu_objs := $(cu_srcs:.cu=.cu.o)
cu_objs := $(cu_objs:src/%=objs/%)
cu_mk := $(cu_objs:.cu.o=.cu.mk)
include_paths := src \
src/application \
src/tensorRT \
src/tensorRT/common \
$(lean_protobuf)/include \
$(lean_opencv)/include/opencv4 \
$(lean_tensor_rt)/include \
$(lean_cuda)/include \
$(lean_cudnn)/include
library_paths := $(lean_protobuf)/lib \
$(lean_opencv)/lib \
$(lean_tensor_rt)/lib \
$(lean_cuda)/lib64 \
$(lean_cudnn)/lib
link_librarys := opencv_core opencv_imgproc opencv_videoio opencv_imgcodecs \
nvinfer nvinfer_plugin \
cuda cublas cudart cudnn \
stdc++ protobuf dl
# HAS_PYTHON表示是否编译python支持
support_define :=
ifeq ($(use_python), true)
include_paths += $(python_root)/include/$(python_name)
library_paths += $(python_root)/lib
link_librarys += $(python_name)
support_define += -DHAS_PYTHON
endif
empty :=
export_path := $(subst $(empty) $(empty),:,$(library_paths))
run_paths := $(foreach item,$(library_paths),-Wl,-rpath=$(item))
include_paths := $(foreach item,$(include_paths),-I$(item))
library_paths := $(foreach item,$(library_paths),-L$(item))
link_librarys := $(foreach item,$(link_librarys),-l$(item))
cpp_compile_flags := -std=c++11 -g -w -O0 -fPIC -pthread -fopenmp $(support_define)
cu_compile_flags := -std=c++11 -g -w -O0 -Xcompiler "$(cpp_compile_flags)" $(cuda_arch) $(support_define)
link_flags := -pthread -fopenmp -Wl,-rpath='$$ORIGIN'
cpp_compile_flags += $(include_paths)
cu_compile_flags += $(include_paths)
link_flags += $(library_paths) $(link_librarys) $(run_paths)
ifneq ($(MAKECMDGOALS), clean)
-include $(cpp_mk) $(cu_mk)
endif
pro : workspace/pro
pytrtc : example-python/pytrt/libpytrtc.so
expath : library_path.txt
library_path.txt :
@echo LD_LIBRARY_PATH=$(export_path):"$$"LD_LIBRARY_PATH > $@
workspace/pro : $(cpp_objs) $(cu_objs)
@echo Link $@
@mkdir -p $(dir $@)
@$(cc) $^ -o $@ $(link_flags)
example-python/pytrt/libpytrtc.so : $(cpp_objs) $(cu_objs)
@echo Link $@
@mkdir -p $(dir $@)
@$(cc) -shared $^ -o $@ $(link_flags)
objs/%.cpp.o : src/%.cpp
@echo Compile CXX $<
@mkdir -p $(dir $@)
@$(cc) -c $< -o $@ $(cpp_compile_flags)
objs/%.cu.o : src/%.cu
@echo Compile CUDA $<
@mkdir -p $(dir $@)
@$(nvcc) -c $< -o $@ $(cu_compile_flags)
objs/%.cpp.mk : src/%.cpp
@echo Compile depends CXX $<
@mkdir -p $(dir $@)
@$(cc) -M $< -MF $@ -MT $(@:.cpp.mk=.cpp.o) $(cpp_compile_flags)
objs/%.cu.mk : src/%.cu
@echo Compile depends CUDA $<
@mkdir -p $(dir $@)
@$(nvcc) -M $< -MF $@ -MT $(@:.cu.mk=.cu.o) $(cu_compile_flags)
yolo : workspace/pro
@cd workspace && ./pro yolo
yolo_gpuptr : workspace/pro
@cd workspace && ./pro yolo_gpuptr
dyolo : workspace/pro
@cd workspace && ./pro dyolo
dunet : workspace/pro
@cd workspace && ./pro dunet
dmae : workspace/pro
@cd workspace && ./pro dmae
dclassifier : workspace/pro
@cd workspace && ./pro dclassifier
yolo_fast : workspace/pro
@cd workspace && ./pro yolo_fast
bert : workspace/pro
@cd workspace && ./pro bert
alphapose : workspace/pro
@cd workspace && ./pro alphapose
fall : workspace/pro
@cd workspace && ./pro fall_recognize
retinaface : workspace/pro
@cd workspace && ./pro retinaface
arcface : workspace/pro
@cd workspace && ./pro arcface
test_warpaffine : workspace/pro
@cd workspace && ./pro test_warpaffine
test_yolo_map : workspace/pro
@cd workspace && ./pro test_yolo_map
arcface_video : workspace/pro
@cd workspace && ./pro arcface_video
arcface_tracker : workspace/pro
@cd workspace && ./pro arcface_tracker
test_all : workspace/pro
@cd workspace && ./pro test_all
scrfd : workspace/pro
@cd workspace && ./pro scrfd
centernet : workspace/pro
@cd workspace && ./pro centernet
dbface : workspace/pro
@cd workspace && ./pro dbface
high_perf : workspace/pro
@cd workspace && ./pro high_perf
lesson : workspace/pro
@cd workspace && ./pro lesson
plugin : workspace/pro
@cd workspace && ./pro plugin
pytorch : pytrtc
@cd example-python && python test_torch.py
pyscrfd : pytrtc
@cd example-python && python test_scrfd.py
pyretinaface : pytrtc
@cd example-python && python test_retinaface.py
pycenternet : pytrtc
@cd example-python && python test_centernet.py
pyyolov5 : pytrtc
@cd example-python && python test_yolov5.py
pyyolov7 : pytrtc
@cd example-python && python test_yolov7.py
pyyolox : pytrtc
@cd example-python && python test_yolox.py
pyarcface : pytrtc
@cd example-python && python test_arcface.py
pyinstall : pytrtc
@cd example-python && python setup.py install
clean :
@rm -rf objs workspace/pro example-python/pytrt/libpytrtc.so example-python/build example-python/dist example-python/pytrt.egg-info example-python/pytrt/__pycache__
@rm -rf workspace/single_inference
@rm -rf workspace/scrfd_result workspace/retinaface_result
@rm -rf workspace/YoloV5_result workspace/YoloX_result
@rm -rf workspace/face/library_draw workspace/face/result
@rm -rf build
@rm -rf example-python/pytrt/libplugin_list.so
@rm -rf library_path.txt
.PHONY : clean yolo alphapose fall debug
# 导出符号,使得运行时能够链接上
export LD_LIBRARY_PATH:=$(export_path):$(LD_LIBRARY_PATH)
3. ONNX导出
- 训练的模型使用 yolov5s.pt,torch 版本 1.12.1,onnx 版本 1.13.1
- ONNX 导出参考自 YoloV5案例第一部分,导出ONNX
关于静态 batch 和动态 batch 有以下几点说明,更多细节请查看 YoloV8的动态静态batch如何理解和使用
静态batch
- 导出的 onnx 指定所有维度均为明确的数字,是静态 shape 模型
- 在推理的时候,它永远都是同样的 batch 推理,即使你目前只有一个图推理,它也需要 n 个 batch 的耗时
- 适用于大部分场景,整个代码逻辑非常简单
动态batch
- 导出的时候指定特定维度为 dynamic,也就是不确定状态
- 模型推理时才决定所需推理的 batch 大小,耗时最优,但 onnx 复杂度提高了
- 适用于如 server 有大量不均匀的请求时的场景
3.1 静态batch导出
静态 batch 的导出需要修改 yolov5-7.0/export.py 这个文件的内容,具体修改如下:
# yolov5-7.0/export.py第141行
# output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
# 修改为:
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output']
将训练好的 VOC 权重 best.pt 放在 yolov5-7.0 主目录下,在终端执行如下指令:
cd yolov5-7.0
python export.py --weights=./best.pt --include=onnx --simplify --opset=11
执行完成后会在当前目录生成导出的 best.onnx 模型,用于后续量化部署。
3.2 动态batch导出
动态 batch 的导出需要修改 yolov5-7.0/models/yolo.py 和 yolov5-7.0/export.py 两个文件的内容,具体修改如下:
# yolov5-7.0/models/yolo.py第60行,forward函数
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 修改为:
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs = -1
ny = int(ny)
nx = int(nx)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# yolov5-7.0/export.py第141行
# output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
# if dynamic:
# dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
# if isinstance(model, SegmentationModel):
# dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
# dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
# elif isinstance(model, DetectionModel):
# dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
# 修改为:
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output']
if dynamic:
dynamic = {'images': {0: 'batch'}} # shape(1,3,640,640)
if isinstance(model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(model, DetectionModel):
dynamic['output'] = {0: 'batch'} # shape(1,25200,85)
然后将训练好的 VOC 权重 best.pt 放在 yolov5-7.0 主目录下,在终端执行如下指令:
cd yolov5-7.0
python export.py --weights=./best.pt --dynamic --simplify --include=onnx --opset=11
执行完成后会在当前目录生成导出的 best.onnx 模型,用于后续量化部署。
4. PTQ量化
4.1 前置工作
在开始 PTQ 量化之前我们需要准备两个东西:模型和校准图片
模型我们采用动态 batch 导出的 best.onnx 模型,将它放在 tensorRT_Pro/workspace 文件夹下
校准图片我们从训练集随机选取 1000 张图片进行校准,将它也放在 tensorRT_Pro/workspace 文件夹下
1000 张校准数据集随机选取的代码如下:
import os
import random
import shutil
def random_copy_images(source_folder, destination_folder, num_images=1000):
# 确保目标文件夹存在
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
# 获取源文件夹中的所有图片文件
image_files = [file for file in os.listdir(source_folder) if file.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif'))]
# 随机选择1000张图片
selected_images = random.sample(image_files, min(num_images, len(image_files)))
# 复制选中的图片到目标文件夹
for image_file in selected_images:
source_path = os.path.join(source_folder, image_file)
destination_path = os.path.join(destination_folder, image_file)
shutil.copy(source_path, destination_path)
source_folder = '/home/jarvis/Learn/Datasets/VOC_PTQ/images/train' # 带有图片的文件夹路径
destination_folder = 'calib_data' # 目标文件夹路径
num_images = 1000 # 需要随机获取的图片数量
random_copy_images(source_folder, destination_folder, num_images)
你需要修改以下几项:
- source_folder:源训练集文件夹路径
- destination_folder:校准数据集文件夹路径
- num_images:随机选择的图片数量
4.2 源码修改
将上述模型和校准图片准备好后还要修改下源码,yolo 模型的推理代码主要在 src/application/app_yolo.cpp 文件中,我们就只需要修改这一个文件中的内容即可,源码修改较简单主要有以下几点:
- 1. app_yolo.cpp 177 行,Yolo::Type 修改为 V5,TRT::Mode 修改为 INT8,“yolov7” 改成 “best”
- 2. app_yolo.cpp 25 行,新增 voclabels 数组,添加 voc 数据集的类别名称
- 3. app_yolo.cpp 100 行,cocolabels 修改为 voclabels
- 4. app_yolo.cpp 149 行,“inference” 修改为 “calib_data” 指定校准图片的路径
具体修改如下:
test(Yolo::Type::V5, TRT::Mode::INT8, "best") // 修改1 177行"yolov7"改成"best"
static const char *voclabels[] = {"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"}; // 修改2 25行新增代码,为自训练模型的类别名称
for(auto& obj : boxes){
...
auto name = mylabels[obj.class_label]; // 修改3 100行cocolabels修改为mylabels
...
}
TRT::compile(
mode, // FP32、FP16、INT8
test_batch_size, // max batch size
onnx_file, // source
model_file, // save to
{},
int8process,
"calib_data" // 修改4 149行 "inference" 修改为 "calib_data"
);
4.3 编译运行
OK!源码修改好了,Makefile 编译文件也搞定了,可以编译运行了,直接在终端执行如下指令即可:
make yolo
图解如下所示:
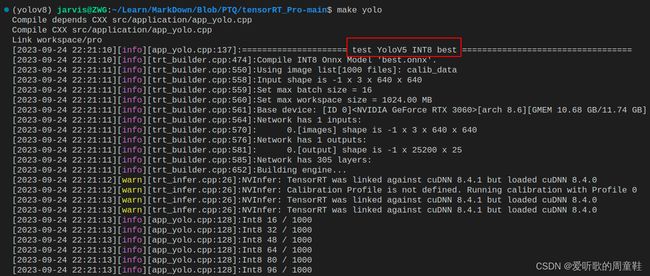

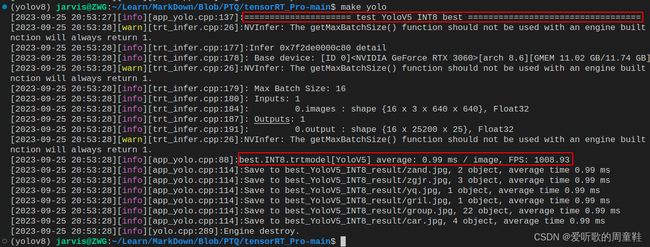
编译运行后在 workspace 文件夹下会生成 INT8 的 engine 模型 best.INT8.trtmodel 用于模型推理,同时它还会生成 best_Yolov5_INT8_result 文件夹,该文件夹下保存了推理的图片
模型推理效果如下图所示:

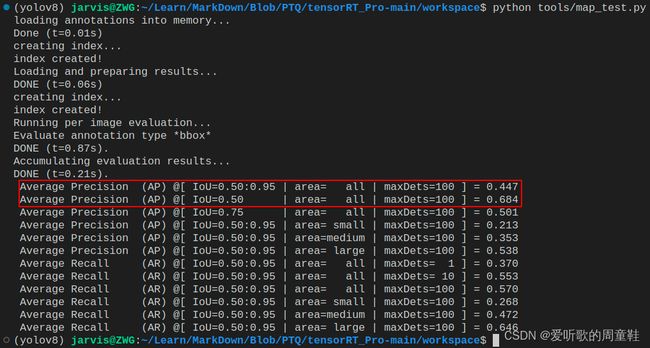
4.4 PTQ模型mAP测试
我们再来测试下经过 PTQ 量化后模型的 mAP,tensorRT_Pro 中已经提供了对应 mAP 测试的代码,在 src/application/test_yolo_map.cpp 文件中,我们就只需要修改这一个文件中的内容即可,源码修改较简单主要有以下几点:
- 1. test_yolo_map.cpp 172 行,修改要测试的验证集文件夹路径
- 2. test_yolo_map.cpp 175 行,修改要测试的 INT8 模型,yolov5s 修改为 best
- 3. test_yolo_map.cpp 176 行,TRT::Mode 修改为 INT8
- 4. test_yolo_map.cpp 125 行,将 save_to_json 函数简单修改下
修改后完整的 test_yolo_map.cpp 如下所示:
#include 上述代码会将 INT8 模型在验证集中所有图像的检测结果存储到一个 JSON 文件中,每个检测到的物体都被序列化为 JSON 格式信息,包括图像 ID、类别 ID、置信度和边界框坐标。后续我们就可以拿着这个预测结果的 JSON 文件和我们真实标签的 JSON 文件通过 COCO Python API 去计算 mAP 指标。
有以下几点需要注意:
- 博主将 JSON 文件中的 image_id 保存为一个字符串,考虑到图片命名的差异性
- 博主将 JSON 文件中的 category_id 直接保存为类别标签,没有做转换
- mAP 测试使用的 NMS_threshold = 0.65f,Conf_threshold = 0.001f 与 pytorch 保持一致
- 关于 mAP 的相关原理介绍可参考 目标检测mAP计算以及coco评价标准
将源码修改好后,直接在终端执行如下指令即可:
make test_yolo_map
图解如下所示:
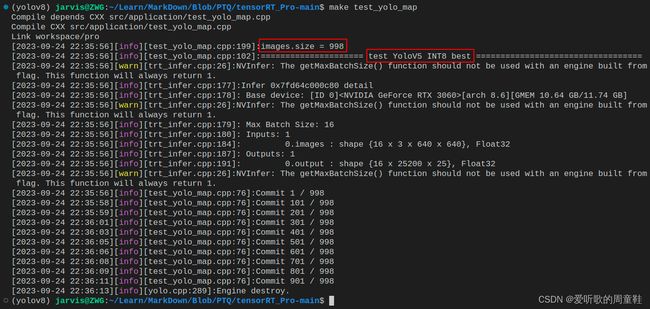
运行成功后在 workspace 文件夹下会生成 best.prediction.json 文件,该 JSON 文件中保存着 INT8 模型在验证集上的推理结果。
我们拿到了模型预测结果的 JSON 文件后,还需要拿到真实标签的 JSON 文件,但是现在我们只有验证集真实的 YOLO 标签文件,因此需要将 YOLO 标签转换为 JSON 文件,转换代码如下:(from chatGPT)
import os
import cv2
import json
import logging
import os.path as osp
from tqdm import tqdm
from functools import partial
from multiprocessing import Pool, cpu_count
def set_logging(name=None):
rank = int(os.getenv('RANK', -1))
logging.basicConfig(format="%(message)s", level=logging.INFO if (rank in (-1, 0)) else logging.WARNING)
return logging.getLogger(name)
LOGGER = set_logging(__name__)
def process_img(image_filename, data_path, label_path):
# Open the image file to get its size
image_path = os.path.join(data_path, image_filename)
img = cv2.imread(image_path)
height, width = img.shape[:2]
# Open the corresponding label file
label_file = os.path.join(label_path, os.path.splitext(image_filename)[0] + ".txt")
with open(label_file, "r") as file:
lines = file.readlines()
# Process the labels
labels = []
for line in lines:
category, x, y, w, h = map(float, line.strip().split())
labels.append((category, x, y, w, h))
return image_filename, {"shape": (height, width), "labels": labels}
def get_img_info(data_path, label_path):
LOGGER.info(f"Get img info")
image_filenames = os.listdir(data_path)
with Pool(cpu_count()) as p:
results = list(tqdm(p.imap(partial(process_img, data_path=data_path, label_path=label_path), image_filenames), total=len(image_filenames)))
img_info = {image_filename: info for image_filename, info in results}
return img_info
def generate_coco_format_labels(img_info, class_names, save_path):
# for evaluation with pycocotools
dataset = {"categories": [], "annotations": [], "images": []}
for i, class_name in enumerate(class_names):
dataset["categories"].append(
{"id": i, "name": class_name, "supercategory": ""}
)
ann_id = 0
LOGGER.info(f"Convert to COCO format")
for i, (img_path, info) in enumerate(tqdm(img_info.items())):
labels = info["labels"] if info["labels"] else []
img_id = osp.splitext(osp.basename(img_path))[0]
img_h, img_w = info["shape"]
dataset["images"].append(
{
"file_name": os.path.basename(img_path),
"id": img_id,
"width": img_w,
"height": img_h,
}
)
if labels:
for label in labels:
c, x, y, w, h = label[:5]
# convert x,y,w,h to x1,y1,x2,y2
x1 = (x - w / 2) * img_w
y1 = (y - h / 2) * img_h
x2 = (x + w / 2) * img_w
y2 = (y + h / 2) * img_h
# cls_id starts from 0
cls_id = int(c)
w = max(0, x2 - x1)
h = max(0, y2 - y1)
dataset["annotations"].append(
{
"area": h * w,
"bbox": [x1, y1, w, h],
"category_id": cls_id,
"id": ann_id,
"image_id": img_id,
"iscrowd": 0,
# mask
"segmentation": [],
}
)
ann_id += 1
with open(save_path, "w") as f:
json.dump(dataset, f)
LOGGER.info(
f"Convert to COCO format finished. Resutls saved in {save_path}"
)
if __name__ == "__main__":
# Define the paths
data_path = "/home/jarvis/Learn/Datasets/VOC_PTQ/images/val"
label_path = "/home/jarvis/Learn/Datasets/VOC_PTQ/labels/val"
class_names = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] # 类别名称请务必与 YOLO 格式的标签对应
save_path = "./val.json"
img_info = get_img_info(data_path, label_path)
generate_coco_format_labels(img_info, class_names, save_path)
上述代码的功能是将 YOLO 格式的数据集(包括图像文件和对应的 .txt 标签文件)转换成 COCO JSON 格式的标注。转换后的数据包括一个 JSON 标签文件,JSON 标签文件中包含了每个图像的所有物体的类别和边界框信息。
你需要修改以下几项:
- data_path:需要转换的图像文件路径
- label_path:需要转换的 txt 标签文件路径
- class_names:数据集的类别列表,请务必与 YOLO 标签的相对应
- save_path:转换后 JSON 文件保存的路径
- 注意:以上路径都不要包含中文,Windows 下路径记得使用
\\或者/防止转义
YOLO 标签中目标框保存的格式是每一行代表一个目标框信息,每一行共包含 [label_id, x_center, y_center, w, h] 五个变量,分别代表着标签 ID,经过归一化后的中心点坐标和目标框宽高。
JSON 文件中目标框保存的格式是 [x,y,w,h] 四个变量,分别代表着经过归一化的左上角坐标和目标框宽高。
关于代码的分析可以参考:tensorRT模型性能测试
至此,两个 JSON 文件都准备好了,一个是模型推理的预测结果,一个是真实结果。拿到两个 JSON 文件后我们就可以进行 mAP 测试了,具体代码如下:
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# Run COCO mAP evaluation
# Reference: https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
annotations_path = "val.json"
results_file = "best.prediction.json"
cocoGt = COCO(annotation_file=annotations_path)
cocoDt = cocoGt.loadRes(results_file)
imgIds = sorted(cocoGt.getImgIds())
cocoEval = COCOeval(cocoGt, cocoDt, 'bbox')
cocoEval.params.imgIds = imgIds
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
你需要修改以下几项:
- annotations_path:真实标签的 JSON 文件路径
- results_file:模型预测结果的 JSON 文件路径
执行后测试结果如下图所示:
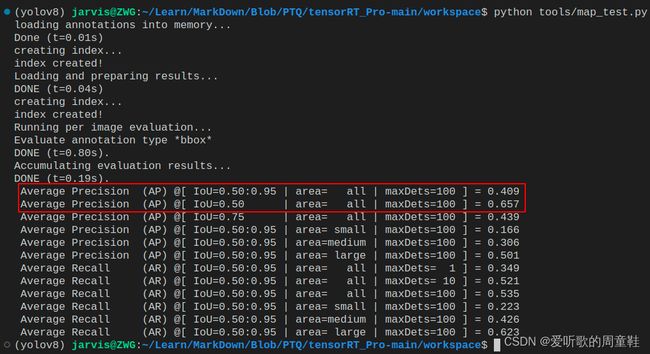
我们将它与原始 pytorch 的模型放在一起进行对比下:
| Model | Size | mAPval 0.5:0.95 |
mAPval 0.5 |
Params (M) |
FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv5s | 640 | 0.471 | 0.711 | 7.2 | 16.5 |
| YOLOv5s-INT8 | 640 | 0.409 | 0.657 | 7.2 | 16.5 |
可以看到相比于原始 pytorch 模型,PTQ 量化后的模型 mAP 下降了近 6 个点
OK!至此 YOLOv5 模型的 PTQ 量化到这里结束了,各位看官可以在自己的数据集测试下 PTQ 量化后模型的性能。
四、讨论
1. 校准图片数量
那可能有不少看官好奇为什么校准图片选择 1000 张呢?是由什么来决定的呢?
这小节我们就来看看校准图片数量对 PTQ 量化模型的影响,博主测试了在不同校准图片下量化的 PTQ 模型在同一个验证集上的 mAP,分别在训练集随机挑选了 100、500、1000、2000、4013 张图片,其中 4013 张图片是整个训练集的数量。
测试结果如下表所示:
| Model | Calib Data | mAPval 0.5:0.95 |
mAPval 0.5 |
|---|---|---|---|
| YOLOv5s-INT8 | 100 | 0.273 | 0.481 |
| YOLOv5s-INT8 | 500 | 0.407 | 0.655 |
| YOLOv5s-INT8 | 1000 | 0.409 | 0.657 |
| YOLOv5s-INT8 | 2000 | 0.307 | 0.522 |
| YOLOv5s-INT8 | 4013(all) | 0.320 | 0.535 |
可视化图如下所示:
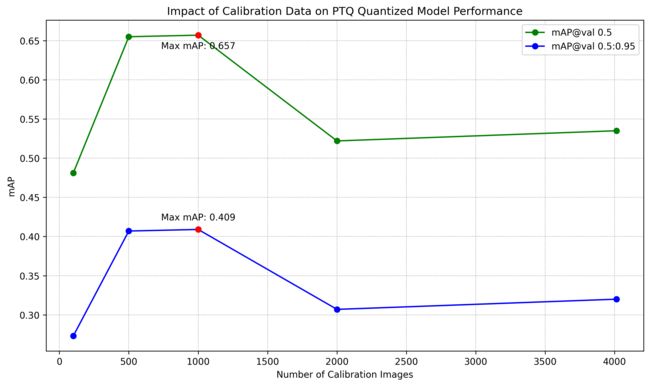
从表中的数据我们可以分析得到下面的一些结论:
1. 校准数据量与模型性能的关系:校准数据的数量对模型 PTQ 量化后的性能有明显的影响。特别是当校准数据从 100 增加到 1000 时,模型的 mAP 明显增加,说明在这个区间内,增加校准数据可以有效提高模型的性能。
2. 最佳校准数据量:在这个测试中,当使用 1000 张校准图片时,模型达到了最高点的 mAP(分别为 0.409 和 0.657)。这意味着并不是校准数据越多越好,需要找到一个适当的平衡点。
3. 校准数据过多可能导致性能下降:当校准数据从 1000 增加到 2000 或 4013 时,模型的性能反而有所下降。这可能是因为过多的校准数据可能引入了噪声,使得量化的过程过于复杂,从而降低了模型的性能。
4. 整个训练集并非最佳选择:尽管使用整个训练集(4013 张图片)进行校准可能看起来是一个直观的选择,但在这个测试中,它并没有提供最佳的性能。这可能意味着在实际应用中,只需要选择一个子集进行校准即可,无需使用整个训练集。
5. 初步校准数据的不足:当仅使用 100 张校准图片时,模型的性能是最低的。这说明在实际应用中,如果只有有限的校准数据,可能需要考虑采集更多的数据以提高量化后的模型性能。
综上所述,选择合适的校准数据量是 PTQ 量化的一个重要步骤。不同的模型和应用场景可能需要不同的校准数据量。因此,为了得到最佳的量化性能,可能需要进行多次实验来确定最佳的校准数据量。
2. 不同精度模型对比
PTQ 量化的模型性能到底怎么样呢?与其它精度的模型相比有哪些优势又有哪些劣势呢?
这个小节我们就来看看不同精度的模型的性能对比,主要从 mAP 和速度两个方面衡量。博主测试了在同一个验证集上原始 pytorch 模型,FP32 模型,FP16 模型,INT8 模型的性能。
原始 pytorch 模型和 INT8 模型性能我们之前已经了解过了,下面我们来看看 FP32 模型和 FP16 模型的性能。
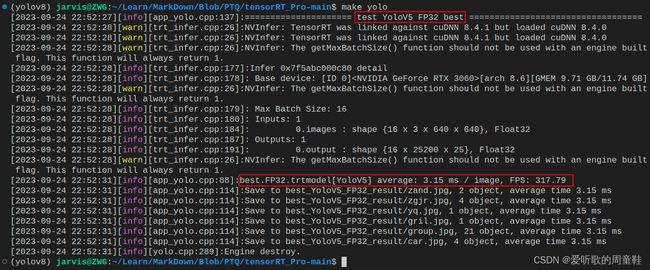
FP32模型:
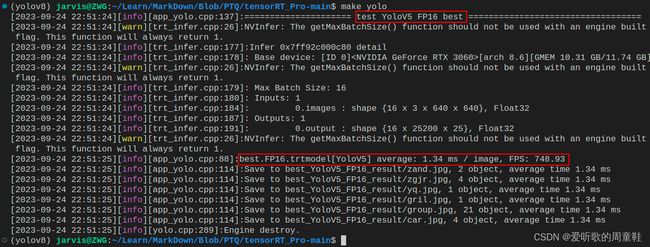
FP16模型:
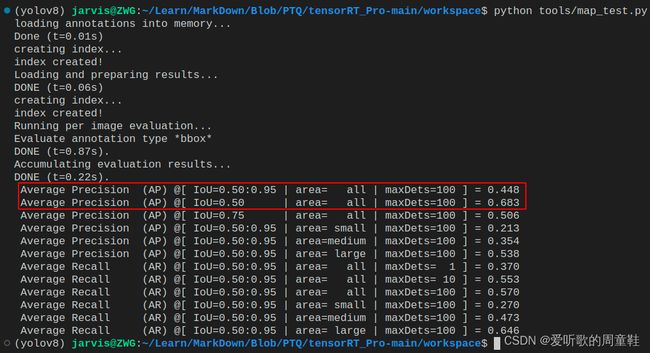
INT8模型:

值得注意的是,关于速度的测试我们之前似乎并没有提到,它具体是如何测试的呢?
其实在 inference_and_performance 函数中就有关于速度相关的测试,主要说明如下:
- 1. 输入分辨率 640x640
- 2. batch_size = 1
- 3. 图像预处理 + 推理 + 后处理
- 4. CUDA-11.6,cuDNN-8.4.0,TensorRT-8.4.1.5
- 5. NVIDIA RTX3060
- 6. 测试次数,100 次取平均,去掉 warmup
- 7. 测试代码:src/application/app_yolo.cpp
- 8. 测试图像 6 张,位于 workspace/inference
- 分辨率分别为:810x1080,500x806,1024x684,550x676,1280x720,800x533
- 9. 测试方式,加载 6 张图后,以原图重复 100 次不停的塞进去。让模型经历完整的图像的预处理,后处理
测试结果如下表所示:
| Model | Precision | mAPval 0.5:0.95 |
mAPval 0.5 |
Elapsed Time/ms | FPS |
|---|---|---|---|---|---|
| YOLOv5s.pt | - | 0.471 | 0.711 | - | - |
| YOLOv5s-FP32 | FP32 | 0.447 | 0.684 | 3.15 | 317.79 |
| YOLOv5s-FP16 | FP16 | 0.448 | 0.683 | 1.34 | 748.93 |
| YOLOv5s-INT8 | INT8 | 0.409 | 0.657 | 0.99 | 1008.93 |
可视化图如下所示:
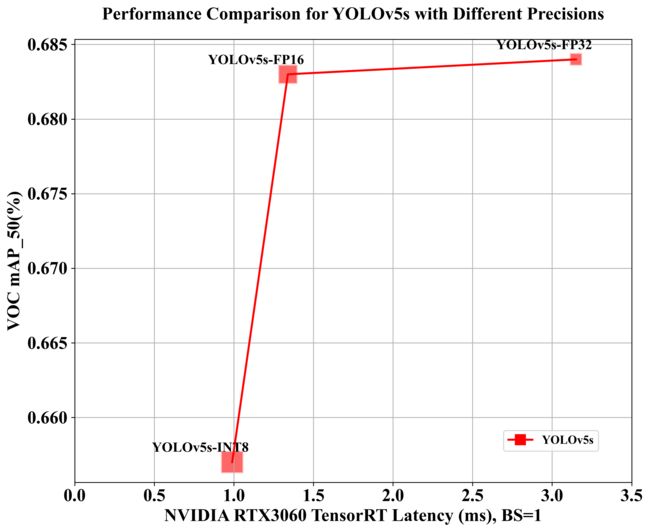
从表中的数据我们可以分析得到下面的一些结论:
1. 精度与模型性能的关系
- 当我们从原始 pytorch 模型转到 FP32 模型时,正常来说应该基本是无损的,但是 mAP 掉了将近 3 个点左右,这并不符合我们的直觉。
- mAP 差 3 个点的原因可能是在固定分辨率这件事上,tensorRT 将图片分辨率固定在 640x640 大小。还有就是 pytorch 实现的所有细节并未完全加入进来,这些细节可能有没有找到的部分。
- FP32 模型和 FP16 模型的 mAP 几乎一样,没有任何精度的损失,这倒是符合我们的直觉
2. 速度与模型性能的关系
- FP16 和 INT8 的 FPS 分别为 748.93 和 1008.93,远高于 FP32 的 317.79
- INT8 模型是所有模型中最快的,达到了 1000 FPS 的速度,尽管其精度稍低。
3. 权衡速度与精度
- FP32 提供了较好的精度,但速度较慢
- FP16 提供了与 FP32 类似的精度,但速度提高了约 2.4 倍,是一个非常不错的选择。
- INT8 提供了略低的精度,但速度却是最快的,比 FP32 快约 3 倍。
综上所述,在实际应用中,需要根据具体的需求权衡速度和精度。例如,对于实时应用,可能会选择 FP16 或 INT8 以获得更高的速度,尽管可能牺牲一些精度。而对于需要高精度的应用,可能会选择 FP32。
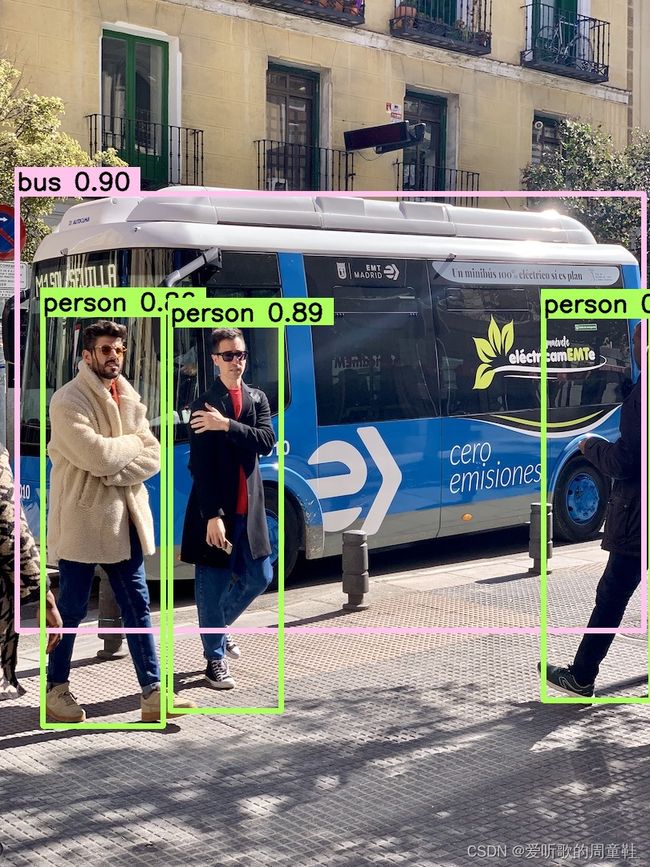
最后博主对比了同一张图片在不同精度模型下的推理效果,如下所示,让大家有个更直观的感受。


OK!YOLOv5-PTQ 量化的内容到这里就结束了,各位看官可以自行测试。
结语
本篇博客介绍了关于 yolov5 的 PTQ 量化以及部署流程,博主在这里只做了最基础的演示,如果有更多的需求需要各位看官自己去挖掘啦。下篇文章我们将会分享关于 yolov5 的 QAT 量化以及部署流程,感谢各位看到最后,创作不易,读后有收获的看官帮忙点个⭐️
下载链接
-
软件安装包下载链接【提取码:yolo】
-
源代码、权重、数据集下载链接【提取码:yolo】
参考
- COCO Python API
- tensorRT模型性能测试
- Ubuntu20.04部署YOLOv5
- YoloV5案例第一部分,导出ONNX
- TensorRT量化第四课:PTQ与QAT
- 目标检测mAP计算以及coco评价标准
- 目标检测:PASCAL VOC 数据集简介
- YoloV8的动态静态batch如何理解和使用
- https://github.com/ultralytics/yolov5
- https://github.com/shouxieai/tensorRT_Pro
- 利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学)