eBPF理解 (一)
目录
一、eBPF简介
二、快速实现BPF程序
三、使用bpf映射
一、eBPF简介
eBPF 是从 BPF (Berkeley Packet Filter) 技术扩展而来的
eBPF 系统启动后就一直运行在那里,它需要事件触发后才会执行。借助kprobe和uprobe,eBPF 程序几乎可以在内核和应用的任意位置进行插桩。
eBPF 的诞生成为内核的一个顶级子系统最典型的就是 iovisor 带来的 BCC、bpftrace 等工具。

图片来源Linux Extended BPF (eBPF) Tracing Tools
BPF开发过程过程
- 使用C语言开发eBPF程序
- 借助LLVM把eBPF程序编译成BPF字节码
- 通过bpf系统调用,把BPF字节码提交给内核
- 内核验证并运行BPF字节码,并把相应的状态保存到BPF映射中
- 用户通过BPF映射查询BPF字节码的运行状态
验证过程
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- BPF 程序不能导致内核崩溃;
- BPF 程序必须在有限时间内完成。
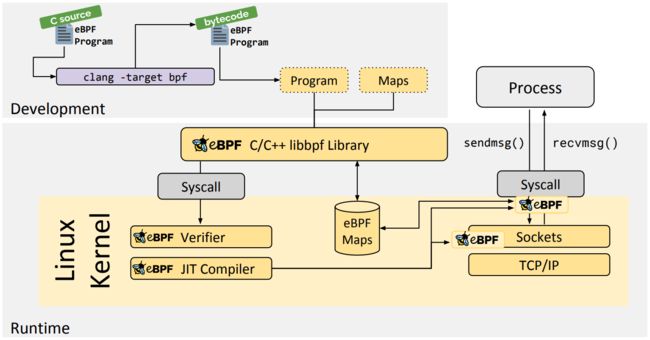
映射过程,来源,eBPF 程序的运行需要历经编译、加载、验证和内核态执行等过程,而用户态程序则需要借助 BPF 映射来获取内核态 eBPF 程序的运行状态。
安装方式 ubuntu22.04上
sudo apt-get install -y make clang llvm libelf-dev libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)二、快速实现BPF程序
使用BCC开发eBPF程序,跟踪openat系统调用
1、编辑C程序
int hello_world(void *ctx)
{
bpf_trace_printk("Hello, World!");
return 0;
}新建hello_world.c 文件,
输出Hello, World!打印
bpf_trace_printk时BPF提供的输出,可以用cat /sys/kernel/debug/tracing/trace_pipe查看
2、编辑python程序
from bcc import BPF
b = BPF(src_file="hello_world.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
b.trace_print()
python语言,导入BCC模块的BPF
调用BPF加载.c文件
将BPF程序挂在到内核探针kprobe上,event是系统调用openat在内核的实现
打印输出,读取内核中/sys/kernel/debug/tracing/trace_pipe的内容
3、运行eBPF程序
root@root:/# python3 hello.py
b'CPU:1 [LOST 127 EVENTS]'
b' systemd-1 [001] d...1 3141.925409: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925410: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925415: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925416: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925417: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925419: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925421: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925423: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925430: bpf_trace_printk: Hello, World!'
b' systemd-1 [001] d...1 3141.925442: bpf_trace_printk: Hello, World!'
systemd-1 表示进程的名字
[001]表示CPU编号
d...1是选项
3141.9254xx是时间戳
bpf_trace_printk是函数名
Hello,World是打印输出
三、使用bpf映射
BCC定义的库函数和辅助定义
BPF_PERF_OUTPUT函数功能
创建一个 BPF 表,用于通过性能环缓冲区将自定义事件数据推送到用户空间。这是将每个事件的数据推送到用户空间的首选方法。
1、改进的.c文件
//头文件
#include
#include
//结构体
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
//定义性能事件映射
BPF_PERF_OUTPUT(events);
//处理函数
int hello(struct pt_regs *ctx, int dfd, const char __user * filename, struct open_how *how) {
struct data_t data = {};
//获取PID和时间
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
//获取进程名,把进程名复制到预定义的缓冲区
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0)
{ //读取进程打开的文件名
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
//提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
} 有映射后,bpf_trace_printk就不需要了,用户可以直接从内核态读取数据。
2、改进的python
将C语言写在一起,参考hello_perf_outputpy
from bcc import BPF
# define BPF program
prog = """
#include
// define output data structure in C
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
BPF_PERF_OUTPUT(events);
int hello(struct pt_regs *ctx,int dfd,const char __user *filename,struct open_how *how) {
struct data_t data = {};
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
if(bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0)
{
bpf_probe_read(&data.fname,sizeof(data.fname),(void *)filename);
}
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("openat"), fn_name="hello")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
# process event
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %s" % (time_s, event.comm, event.pid,
"Hello, perf_output!"))
# loop with callback to print_event
b["events"].open_perf_buffer(print_event)
while 1:
b.perf_buffer_poll() open_perf_buffer定义了名为event的perf映射事件,通过循环调用perf_buffer_poll读取映射的内容。
3、运行eBPF程序
root@root/# python3 hello_perf.py
TIME(s) COMM PID MESSAGE
0.000000000 b'systemd-oomd' 788 b'/proc/meminfo'
0.250287922 b'systemd-oomd' 788 b'/proc/meminfo'
0.500141038 b'systemd-oomd' 788 b'/proc/meminfo'
0.500233681 b'systemd-oomd' 788 b'/sys/fs/cgroup/user.slice/user-1000.slice/[email protected]/memory.pressure'
0.500300281 b'systemd-oomd' 788 b'/sys/fs/cgroup/user.slice/user-1000.slice/[email protected]/memory.current'
0.500315337 b'systemd-oomd' 788 b'/sys/fs/cgroup/user.slice/user-1000.slice/[email protected]/memory.min'
参考:
bcc/reference_guide.md at master · iovisor/bcc · GitHub
What is eBPF? An Introduction and Deep Dive into the eBPF Technology
Linux eBPF Tracing Tools (brendangregg.com)