python中关于axis=0和axis=1应该如何理解?
axis=0:数据在纵向发生变化;
axis=1:数据在横向发生变化。
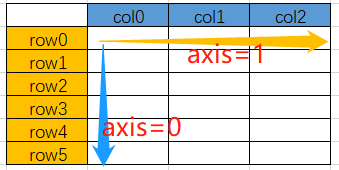
下面我们用python代码的方式更加直观的了解axis=0和axis=1的区别。
import pandas as pd
data = pd.DataFrame(data=[['吴文化', '男', 100, 98, 85],
['史珍香', '女', 66, 75, 72],
['范建', '男', 77, 88, 100],
['胡说', '男', 80, 90, 86],
['夏扯淡', '女', 76, 80, 96]],
columns=['name', 'gender', 'math', 'chinese', 'english'])
print(data)
上面代码的结果如下,这就是我们接下来要操作的数据:
name gender math chinese english
0 吴文化 男 100 98 85
1 史珍香 女 66 75 72
2 范建 男 77 88 100
3 胡说 男 80 90 86
4 夏扯淡 女 76 80 96
1)首先我们求一下每一科目的平均成绩,每一科目的平均成绩就是求科目列的平均值。求科目列的平均值时,我们会把多行压缩成三行(因为有三个科目),这是属于纵向的变化,所以应该指定axis=0。
# 每一科目的平均成绩
avg_subject = data[['math', 'chinese', 'english']].mean(axis=0)
print(avg_subject)
# 下面是运行结果
math 79.8
chinese 86.2
english 87.8
2)然后我们求一下每个同学的平均成绩。每一个同学的平均成绩,会把科目所在的三个列压缩成一个列,属于横向的变化,所以应该指定axis=1。
avg_score = data[['math', 'chinese', 'english']].mean(axis=1)
print(avg_score)
# 下面是运行结果
0 94.333333
1 71.000000
2 88.333333
3 85.333333
4 84.000000
3)接下来我们看一下删除行或者列。
删除math列,因为列减少了,相当于人瘦了,横向上发生了变化。所以我们要指定axis=1。
data.drop(labels='math', inplace=True, axis=1)
print(data)
# 下面是运行结果
name gender chinese english
0 吴文化 男 98 85
1 史珍香 女 75 72
2 范建 男 88 100
3 胡说 男 90 86
4 夏扯淡 女 80 96
4)最后我们看一下删除指定行。因为删除了行,相当于人变矮了,纵向发生了变化。所以指定axis=0。
data.drop(index=0, inplace=True, axis=0)
print(data)
# 下面是运行结果
name gender chinese english
1 史珍香 女 75 72
2 范建 男 88 100
3 胡说 男 90 86
4 夏扯淡 女 80 96