golang内建函数defer、panic、recover的运营关系
前言:
GO语言追求简洁优雅,GO语言不类似try catch操作
GO语言中引入的处理方式为:defer、panic、recover
GO可以抛出一个panic异常。然后在defer中通过recover捕获异常再处理
GO没有提供“try-catch-finally”这样的异常处理机制,然而是提供出panic和recover,当然panic写recover还要结合defer使用。
虽然对于其他语言转型的大家一开始会有点不适用,甚至会有征讨之声。但个人感觉,这才是go,这很go。
我们先简单介绍一下panic,defer,recover他们三个各自的功能和实现。
Panic
Panic是内建的停止控制流的函数。相当于抛异常操作。当函数F调用了panic,F的执行会被停止,在F中panic前面定义的defer操作都会被执行,然后F函数返回。对于调用者来说,调用F的行为就像调用panic(如果F函数内部没有把panic recover掉)。如果都没有捕获该panic,相当于一层层panic,程序将会crash。
Defer
Defer语句将一个函数放入一个列表(用栈表示其实更准确)中,该列表的函数在环绕defer的函数返回时会被执行。
Recover
Recover是一个从panic恢复的内建函数。Recover只有在defer的函数里面才能发挥真正的作用。如果是正常的情况(没有发生panic),调用recover将会返回nil并且没有任何影响。如果当前的goroutine panic了,recover的调用将会捕获到panic的值,并且恢复正常执行。
搭配使用
明白了三者的功能属性那么来看看他们是如何搭配使用的。
一开始和大家将底层逻辑处理想必大家会觉得比较枯燥,那么我们先来举个栗子,简单看下go中的发生了panic的表现。希望大家边看边思考,最后我们一起小结。
下面我举个栗子模拟这一过程:
没有recover的时候,一旦panic发生,panic会按照既定顺序结束当前进程,这一过程成为panicking。
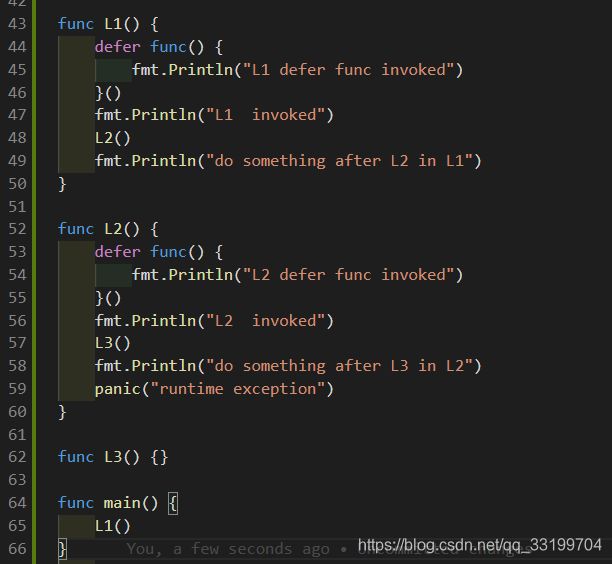
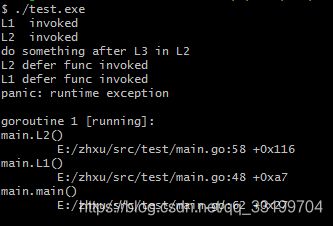
这里栗子中,我们首先可以看到defer的调用栈的实现(这里不再详述),进一步可以观察到panic在L2 中发生,在L2真正退出之前,L2中注册的defer函数会被逐一执行(FILO),由于L2 中的defer 没有捕捉panic,因此panic被抛向其caller:L1.
这是对于L1而言,其函数体中的L2调用就好像变成了panic调用。panic在L1中扩展开来,同样L1中的defer 也没有捕捉recover,待L1中的derfer func执行完毕后,panic继续抛向caller:main。main函数与上述函数一直,没有recover,直接异常返回,导致进程异常退出。
下面我们再看一看 带有 recover 的表现。
值得一提的是,recover只要在defer函数汇中调用才能起到作用,他们之间有着亲密的关系。
将程序改写成:
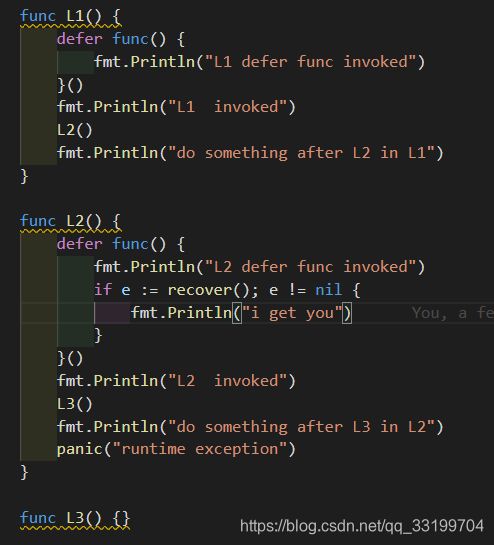
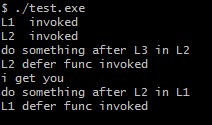
由于L2在defer里恢复了panic,这样在L2这种返回后,L1不会感知到任何异常,按照正常逻辑输出函数执行内容。比如示例中提到的:
do something after L2 in L1。
小结
普通情况是当调用到panic函数或者是发生意外导致的panic,函数自身会被停止。
紧接着,流程控制权会交回给调用方函数。然后其调用方函数也会被停止。panic就是这样沿着调用栈反向进行传播,直到到达当前rountine的最高层。一旦达到顶层,就意味着该routine调用栈中所有的函数执行都已经被停止,程序已经崩溃。要么使用了defer+recover机制,go自然而然就提供出“拦截”。
它可以使程序从panic状态中恢复并重新获得流程控制权。recover函数被调用后,会返回一个interface类型的结果,如果当时当时的程序正处于运行panic的状态,那么该结果就是非nil的。

就像这个样子,将defer匿名函数放在函数体的开始处,可以有效防止该函数及其下层调用的代码引发运行时的panic。同时也可以检查运行时panic的带值类型,并根据类型的不同来做不同的后续动作,可以精确地控制程序的错误处理行为。
那么有关panic defer reovcer我们可以先总结一波:
- panic()执行后,后续语句不再执行,会先调用当前协程的defer链表。
- 如果某个goroutine的defer没有recover,会终止整个程序(exit(2)),不仅仅是终止当前goroutine。
- 如发现defer函数包含recover,则会运行recovery函数,recovery会跳转到defer return。
- panic被recover后,会影响到当前函数中的后续语句的执行,但不影响当前goroutine的继续执行。
- recover()的作用是捕获异常之后让程序正常往下执行而不会退出。
- recover()必须写在defer语块中才能生效。
- recover()的作用范围仅限于当前的所属go routine。发生panic时只会执行当前协程中的defer函数,其它协程里面的defer不会执行。
那么介绍到这里,小伙伴就要问了,你说了这么多go的特性,为啥error要主动panic而不是一层一层的返回呢?每个函数返回error不是应该是常规操作吗?
我在这里说下我自己的看法:
第一、 既然go已经提出了defer+panic的机制处理panic信息。为何我们不可以利用起来?
第二、 有时候,从异常中恢复我们可以在程序崩溃前,做一些操作。比如说当web服务器遇到不可预料的问题,在崩溃前应该将所有的链接关闭;或当程序发生崩溃后,将DB链接释放等等。
第三、 对panic的处理都集中在一个包下,有助于简化对复杂和不可以预料问题的处理。
第四、 从资源性能的角度上,一层层函数返回error和遇到error交给recover处理其实并没有什么区别。
第五、 也是最重要的一点,编码的时候你一定要想清楚为何要使用panic?你的期望是什么?如果不希望go die为什么要用panic?
下面我来结合业务结合现实,从代码上正反面来对比说明,此编码风格的优势。
我们先从编码的风格上来品~ 大家细品~
函数在返回的时候增加error类型的返回值,如果有错误则赋值给err,在调用函数处对err进行判断,如果不为nil则处理错误。这种方式在嵌套的层少的时候还好办,要是嵌套的层多了那就要一级一级的返回err,显然会很麻烦。如下面的代码:
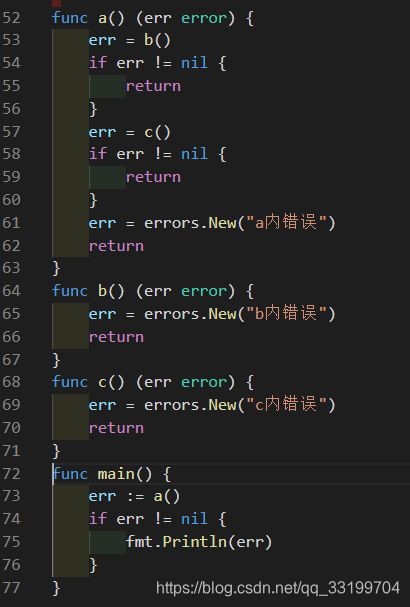
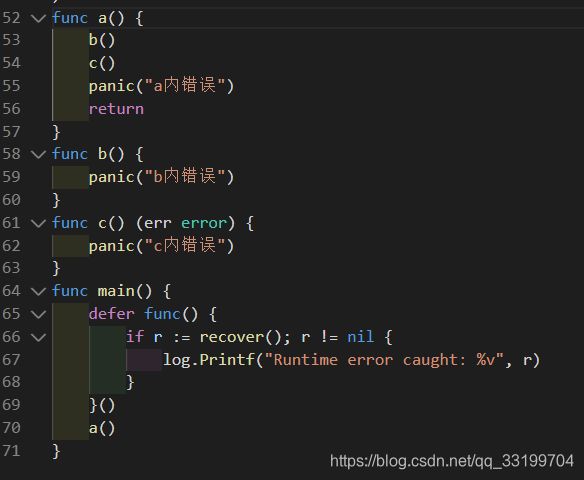
可以看到整个代码都简洁了很多,当然这里的代码比较简单可能看不出什么太大效果,在业务较为繁杂、经常要做各种校验的时候就可以显现出简洁了。
在开发api接口项目的时候,我会封装好recover的方法用来处理内部返回的错误信息,然后统一输出到客户端,感觉便捷很多。
我们再来从业务的角度品一品~



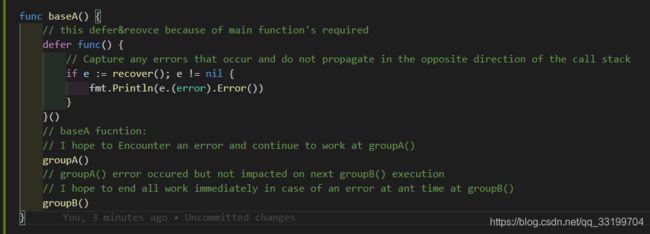
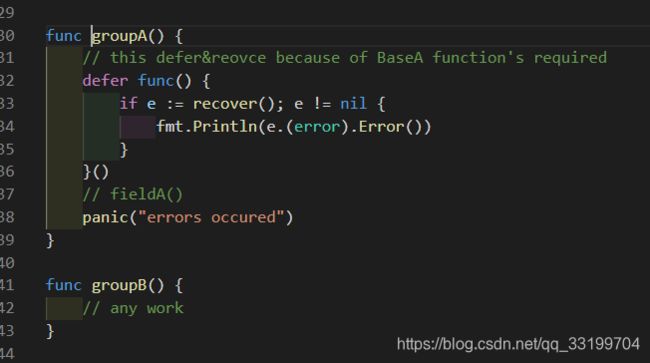
详细解释说明我已经在函数中提示了,为了培养大家写注释读注释的习惯以及独立思考学习的习性,这里我就不再详述了。
最后留下一个扩展问题,想和大家一起思考讨论一下:
如果想统一处理捕获panic,可以考虑把panic这样的事件通知给其他goroutine处理,那这样该怎么做?何种业务场景下适合?