Spark Streaming系列-5、应用案例: 百度搜索风云榜
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、 http://spark.apache.org/sql/

目录
- 业务场景
- 初始化环境
-
- 创建 Topic
- 模拟日志数据
- StreamingContextUtils 工具类
- 实时数据ETL存储
- 实时状态更新统计
- 实时窗口统计
百度搜索风云榜( http://top.baidu.com/) 以数亿网民的单日搜索行为作为数据基础,以搜索关键词为统计对象建立权威全面的各类关键词排行榜,以榜单形式向用户呈现基于百度海量搜索数据的排行信息,线上覆盖十余个行业类别,一百多个榜单。

业务场景
仿【百度搜索风云榜】对用户使用百度搜索时日志进行分析:【百度搜索日志实时分析】,主要业务需求如下三个方面:
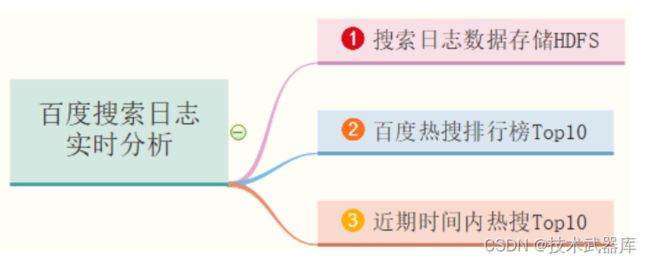
- 业务一:搜索日志数据存储HDFS,实时对日志数据进行ETL提取转换,存储HDFS文件系统;
- 业务二:百度热搜排行榜Top10,累加统计所有用户搜索词次数,获取Top10搜索词及次数;
- 业务三:近期时间内热搜Top10,统计最近一段时间范围(比如,最近半个小时或最近2个小时)内用户搜索词次数,获取Top10搜索词及次数;
开发Maven Project中目录结构如下所示:

初始化环境
编程实现业务之前,首先编写程序模拟产生用户使用百度搜索产生日志数据和创建工具类StreamingContextUtils提供StreamingContext对象与从Kafka接收数据方法。
创建 Topic
启动Kafka Broker服务,创建Topic【search-log-topic】,命令如下所示:
# 1. 启动Zookeeper 服务
zookeeper-daemon.sh start
# 2. 启动Kafka 服务
kafka-daemon.sh start
# 3. Create Topic
kafka-topics.sh --create --topic search-log-topic \
--partitions 3 --replication-factor 1 --zookeeper 192.168.10.10:2181/kafka200
# List Topics
kafka-topics.sh --list --zookeeper 192.168.10.10:2181/kafka200
# Producer
kafka-console-producer.sh --topic search-log-topic --broker-list 192.168.10.10:9092
# Consumer
kafka-console-consumer.sh --topic search-log-topic \
--bootstrap-server 192.168.10.10:9092 --from-beginning
模拟日志数据
模拟用户搜索日志数据,字段信息封装到CaseClass样例类【SearchLog】 类,代码如下:
package app.mock
/**
* 用户百度搜索时日志数据封装样例类CaseClass
*
* @param sessionId 会话ID
* @param ip IP地址
* @param datetime 搜索日期时间
* @param keyword 搜索关键词
*/
case class SearchLog(
sessionId: String, //
ip: String, //
datetime: String, //
keyword: String //
) {
override def toString: String = s"$sessionId,$ip,$datetime,$keyword"
}
模拟产生搜索日志数据类【MockSearchLogs】具体代码如下
package app.mock
import java.util.{Properties, UUID}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/**
* 模拟产生用户使用百度搜索引擎时,搜索查询日志数据,包含字段为:
* uid, ip, search_datetime, search_keyword
*/
object MockSearchLogs {
def main(args: Array[String]): Unit = {
// 搜索关键词,直接到百度热搜榜获取即可
val keywords: Array[String] = Array(
"31省新增确诊17例 本土6例在辽宁",
"孙杨团队:禁赛8年裁决被撤销",
"特朗普政府员工被要求打包行李",
"阿里巴巴涉嫌垄断被立案调查",
"北大学子弑母案今日开庭",
"湖南卫视回应主持人收粉丝礼物",
"英国又发现一种变异新冠病毒",
"高圆圆:我没有任何才艺可以展示",
"港府已采购2250万剂新冠疫苗",
"金融管理部门将约谈蚂蚁集团",
"北京通报顺义1例无症状相关情况",
"青海疑有陨石划过 伴有巨响",
"山东曲阜发生塌陷 学生有序避难",
"2020年日本最美最帅高中生",
"网络招聘不得含有性别歧视性内容",
"永久冻土中发现57000年前小狼崽",
"一名北京赴浙人员新冠阳性",
"元旦起上海超市禁止提供塑料袋",
"男子卖掉女友儿子又卖亲生女儿",
"中国男女性成人平均身高出炉"
)
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "192.168.10.10:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random: Random = new Random()
while (true){
// 随机产生一条搜索查询日志
val searchLog: SearchLog = SearchLog(
getUserId(), //
getRandomIp(), //
getCurrentDateTime(), //
keywords(random.nextInt(keywords.length)) //
)
//打印测试
println(searchLog.toString)
Thread.sleep(10 + random.nextInt(100))
//发送到Kafka的topic中
val record = new ProducerRecord[String, String]("search-log-topic", searchLog.toString)
producer.send(record)
}
// 关闭连接
// producer.close()
}
/**
* 随机生成用户SessionId
*/
def getUserId(): String = {
val uuid: String = UUID.randomUUID().toString
uuid.replaceAll("-", "").substring(16)
}
/**
* 获取当前日期时间,格式为yyyyMMddHHmmssSSS
*/
def getCurrentDateTime(): String = {
val format = FastDateFormat.getInstance("yyyyMMddHHmmssSSS")
val nowDateTime: Long = System.currentTimeMillis()
format.format(nowDateTime)
}
/**
* 获取随机IP地址
*/
def getRandomIp(): String = {
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792,608174079), //36.56.0.0-36.63.255.255
(1038614528,1039007743), //61.232.0.0-61.237.255.255
(1783627776,1784676351), //106.80.0.0-106.95.255.255
(2035023872,2035154943), //121.76.0.0-121.77.255.255
(2078801920,2079064063), //123.232.0.0-123.235.255.255
(-1950089216,-1948778497),//139.196.0.0-139.215.255.255
(-1425539072,-1425014785),//171.8.0.0-171.15.255.255
(-1236271104,-1235419137),//182.80.0.0-182.92.255.255
(-770113536,-768606209),//210.25.0.0-210.47.255.255
(-569376768,-564133889) //222.16.0.0-222.95.255.255
)
// 随机数:IP地址范围下标
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
//println(s"ipNumber = ${ipNumber}")
// 转换Int类型IP地址为IPv4格式
number2IpString(ipNumber)
}
/**
* 将Int类型IPv4地址转换为字符串类型
*/
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// 返回IPv4地址
buffer.mkString(".")
}
}
运行应用程序,源源不断产生日志数据,发送至Kafka(同时在控制台打印),截图如下:

StreamingContextUtils 工具类
所有SparkStreaming应用都需要构建StreamingContext实例对象,并且从采用New KafkaConsumer API消费Kafka数据,编写工具类【StreamingContextUtils】,提供两个方法:
- 方法一: getStreamingContext,获取StreamingContext实例对象

- 方法二: consumerKafka,消费Kafka Topic中数据

具体代码如下:
package app
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 工具类提供:构建流式应用上下文StreamingContext实例对象和从Kafka Topic消费数据
*/
object StreamingContextUtils {
/**
* 获取StreamingContext实例,传递批处理时间间隔
* @param batchInterval 批处理时间间隔,单位为秒
*/
def getStreamingContext(clazz: Class[_], batchInterval: Int): StreamingContext = {
// i. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(clazz.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// 设置Kryo序列化
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[ConsumerRecord[String, String]]))
// ii.创建流式上下文对象, 传递SparkConf对象和时间间隔
val context = new StreamingContext(sparkConf, Seconds(batchInterval))
// iii. 返回
context
}
/**
* 从指定的Kafka Topic中消费数据,默认从最新偏移量(largest)开始消费
* @param ssc StreamingContext实例对象
* @param topicName 消费Kafka中Topic名称
*/
def consumerKafka(ssc: StreamingContext, topicName: String): DStream[ConsumerRecord[String, String]] = {
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// ii.读取哪些Topic数据
val topics = Array(topicName)
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.10.10:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_streaming_0001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用新消费者API获取数据,类似于Direct方式
val kafkaDStream: DStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// vi.返回DStream
kafkaDStream
}
}
实时数据ETL存储
实时从Kafka Topic消费数据,提取ip地址字段,调用【ip2Region】库解析为省份和城市,存储到HDFS文件中,设置批处理时间间隔BatchInterval为10秒,完整代码如下:
package app.etl
import app.StreamingContextUtils
import org.apache.commons.lang.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.lionsoul.ip2region.{DbConfig, DbSearcher}
/**
* @ClassName StreamingETL
* @Description TODO 实时对日志数据进行ETL提取转换,基于IP地址解析得到每个IP对应省份和城市,结果存储到文件系统
* @Create By Frank
*/
object StreamingETL {
def main(args: Array[String]): Unit = {
//todo:1-构建StreamingContext
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 1)
ssc.sparkContext.setLogLevel("WARN")
//todo:2-实现处理
//step1:读取数据
//调用工具类的方法获取Kafka数据
val kafkaData: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc, "search-log-topic")
//step2:处理数据
//etl
val etlData = kafkaData
.map(record => record.value())
.filter(line => line != null && line.trim.split(",").length == 4)
// val searchBroad: Broadcast[DbSearcher] = ssc.sparkContext.broadcast(searcher)
//实现解析:基于IP构建省份和城市
val rsData: DStream[String] = etlData
.mapPartitions(part => {
val searcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
// val value: DbSearcher = searchBroad.value
//基于分区构建解析器:也可以用广播变量来实现
part.map(line => {
//解析IP
val arr = searcher.btreeSearch(line.trim.split(",")(1)).getRegion.split("\\|")
//返回结果:原来的四列+省份+城市
line + "," + arr(2) + "," + arr(3)
})
})
//step3:保存结果
rsData.foreachRDD((rdd, time) => {
//空的数据不输出
if (!rdd.isEmpty()) {
val stime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds)
println("----------------------------------")
println(stime)
println("----------------------------------")
rdd.foreach(println)
//保存到文件
rdd.saveAsTextFile("datas/stream/etl-" + time)
}
})
//todo:3-启动
ssc.start()
ssc.awaitTermination()
ssc.stop(true, true)
}
}
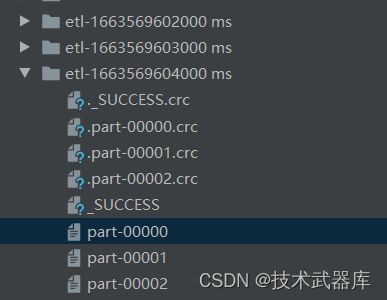
运行模拟日志数据程序和ETL应用程序,查看实时数据ETL后保存文件,截图如下:
实时状态更新统计
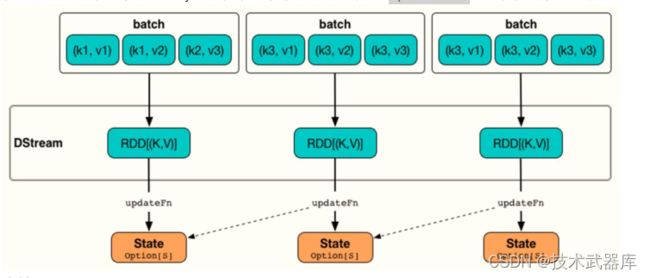
实 时 累 加 统 计 用 户 各 个 搜 索 词 出 现 的 次 数 , 在 SparkStreaming 中 提 供 函 数【 updateStateByKey】实现累加统计。状态更新函数【 updateStateByKey】表示依据Key更新状态,要求DStream中数据类型为【 Key/Value】对二元组,函数声明如下:

将每批次数据状态,按照Key与以前状态,使用定义函数【updateFunc】进行更新,示意图如下:
文档: http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#updatestatebykey-operation
针对搜索词词频统计WordCount,状态更新逻辑示意图如下:
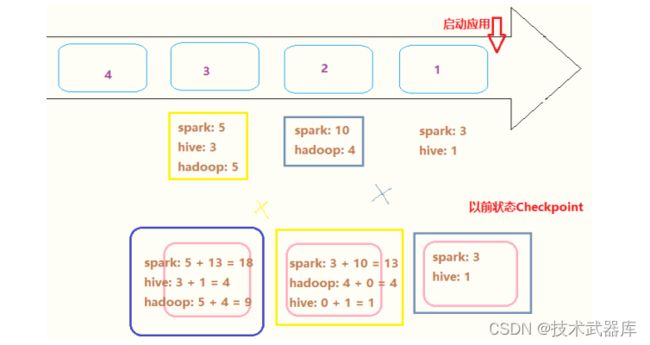
以前的状态数据,保存到Checkpoint检查点目录中,所以在代码中需要设置Checkpoint检查点目录:

完整演示代码如下:
package app.state
import app.StreamingContextUtils
import org.apache.commons.lang.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.dstream.DStream
/**
* @ClassName StreamingWithState
* @Description TODO 累计当前所有搜索词出现的次数,得到热门搜索词的Top10
* @Create By Frank
*/
object StreamingWithState {
def main(args: Array[String]): Unit = {
//todo:1-构建StreamingContext
val ssc = StreamingContextUtils.getStreamingContext(this.getClass,3)
ssc.sparkContext.setLogLevel("WARN")
//配置Checkpoint目录:将上一个批次的最终结果写入CHK
ssc.checkpoint("datas/stream/chk1")
//todo:2-实现处理
//step1:读取数据
val kafkaData: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc,"search-log-topic")
//step2:处理数据
//etl
val etlData = kafkaData
.map(record => record.value())
.filter(line => line != null && line.trim.split(",").length == 4)
//计算当前这个批次每个搜索词出现的次数
val currentBatch: DStream[(String, Int)] = etlData
//取出搜索词,并标记出现1次
.map(line => (line.trim.split(",")(3),1))
.reduceByKey((tmp,item) => tmp+item)
//调用状态函数:将当前批次的结果与前一个批次的结果进行聚合
/**
* 功能:按照Key进行两个批次的聚合
* def updateStateByKey[S: ClassTag](
* updateFunc: (Seq[V], Option[S]) => Option[S] :决定怎么聚合的函数
* Seq[V]:集合类型,表示当前批次这个Key出现的所有Value
* Option[s]:这个Key在上一个批次的结果中出现的次数
* ): DStream[(K, S)]
*/
val rsData = currentBatch.updateStateByKey(
(currentList:Seq[Int],lastBatchValue:Option[Int]) => {
//先获取当前批次这个Key的最终结果
val currentBatchValue = currentList.sum
//然后获取上一个批次中这个Key出现的次数
val lastValue = lastBatchValue.getOrElse(0)
//返回当前批次的结果 + 上一个批次的结果
Some(currentBatchValue + lastValue)
}
)
//step3:输出结果
//输出这个批次最终的结果
rsData.foreachRDD((rdd,time) => {
//空的数据不输出
if(!rdd.isEmpty()){
val stime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds)
println("----------------------------------")
println(stime)
println("----------------------------------")
rdd
.sortBy(tuple => -tuple._2)
.take(10)
.foreach(println)
}
})
//todo:3-启动
ssc.start()
ssc.awaitTermination()
ssc.stop(true,true)
}
}
执行结果如下:

运行应用程序,通过WEB UI界面可以发现,将以前状态保存到Checkpoint检查点目录中,更新时在读取。

此外, updateStateByKey函数有很多重载方法,依据不同业务需求选择合适的方式使用。
实时窗口统计
SparkStreaming中提供一些列窗口函数,方便对窗口数据进行分析,文档:
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#window-operations
在实际项目中,很多时候需求: 每隔一段时间统计最近数据状态,并不是对所有数据进行统计,称为趋势统计或者窗口统计, SparkStreaming中提供相关函数实现功能,业务逻辑如下:

针对用户百度搜索日志数据,实现【近期时间内热搜Top10】,统计最近一段时间范围(比如,最近半个小时或最近2个小时)内用户搜索词次数,获取Top10搜索词及次数。
窗口函数【window】声明如下,包含两个参数: 窗口大小(WindowInterval,每次统计数据范围)和滑动大小(每隔多久统计一次),都必须是批处理时间间隔BatchInterval整数倍。

案例完整实现代码如下,为了演示方便,假设BatchInterval为2秒, WindowInterval为4秒, SlideInterval为2秒。
package app.window
import app.StreamingContextUtils
import org.apache.commons.lang.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.dstream.DStream
/**
* @ClassName StreamingWithWindow
* @Description TODO 每3s处理前6s数据,统计热门搜索词的Top10
* @Create By Frank
*/
object StreamingWithWindow {
def main(args: Array[String]): Unit = {
val batchInterval = 1
//todo:1-构建StreamingContext
val ssc = StreamingContextUtils.getStreamingContext(this.getClass,batchInterval)
ssc.sparkContext.setLogLevel("WARN")
//todo:2-实现处理
//step1:读取数据
val kafkaData: DStream[ConsumerRecord[String, String]] = StreamingContextUtils.consumerKafka(ssc,"search-log-topic")
//step2:处理数据
//etl
val etlData: DStream[String] = kafkaData
.map(record => record.value())
.filter(line => line != null && line.trim.split(",").length == 4)
//第一种窗口计算
// // 先定义窗口
// val windowData: DStream[String] = etlData.window(Seconds(6),Seconds(3))
//
// //再基于窗口聚合
// val rsData = windowData
// //取出搜索词,并标记出现1次
// .map(line => (line.trim.split(",")(3),1))
// .reduceByKey((tmp,item) => tmp+item)
//第二种窗口计算:直接在聚合中设定窗口
val rsData = etlData
.map(line => (line.trim.split(",")(3),1))
.reduceByKeyAndWindow(
(tmp:Int,item:Int) => tmp+item, //还是reduce方法的聚合逻辑
Seconds(6), //窗口大小
Seconds(3) //滑动大小
)
//step3:输出结果
rsData.foreachRDD((rdd,time) => {
//空的数据不输出
if(!rdd.isEmpty()){
val stime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(time.milliseconds)
println("----------------------------------")
println(stime)
println("----------------------------------")
rdd.foreach(println)
//保存到文件
rdd.saveAsTextFile("datas/stream/etl-"+time)
}
})
//todo:3-启动
ssc.start()
ssc.awaitTermination()
ssc.stop(true,true)
}
}
SparkStreaming中同时提供将窗口Window设置与聚合reduceByKey合在一起的函数,为了更加方便编程。

使用【reduceByKeyAndWindow】函数,修改上述代码,实现窗口统计,具体代码如下:
//第二种窗口计算:直接在聚合中设定窗口
val rsData = etlData
.map(line => (line.trim.split(",")(3),1))
.reduceByKeyAndWindow(
(tmp:Int,item:Int) => tmp+item, //还是reduce方法的聚合逻辑
Seconds(6), //窗口大小
Seconds(3) //滑动大小
)