caffe版crpn训练过程及遇到问题
环境:centos、cuda9、protobuf3、python2.7、anaconda2、OpenCV3
其中x86_64-redhat-linux-c++、x86_64-redhat-linux-gcc、x86_64-redhat-linux-g++的版本都是5.3.1
在PATH中加上gcc、g++的环境变量
环境变量设置如下: PATH=/usr/local/protobuf-3.0.0-compiled/bin:/usr/local/cuda-9.0/bin:/usr/bin:/usr/local/bin LD_LIBRARY_PATH=/usr/local/protobuf-3.0.0-compiled/lib:/usr/local/cuda-9.0/lib64:/usr/local/lib:/usr/lib:/usr/lib64:$CONDA_HOME/lib
crpn代码:
git clone https://github.com/xhzdeng/crpn.git进入crpn的根目录编译caffe和pycaffe
cd $CRPN_ROOT/caffe-fast-rcnn构建Cython
cd $CRPN_ROOT/lib
make准备VOC数据集,VOC数据的格式如下
$VOCdevkit/
$VOCdevkit/VOC2007 进入cd data文件夹,通过链接命令ln创建软链接,将VOC数据集链接到VOC2007
cd $CRPN_ROOT/data
ln -s [path] VOCdevkit下载vgg16预训练模型参数,链接地址
http://www.robots.ox.ac.uk/~vgg/software/very_deep/caffe/VGG_ILSVRC_16_layers.caffemodel
将VGG_ILSVRC_16_layers.caffemodel放到
$CRPN_ROOT目录下面
crpn配置文件Makefile.config修改:
1. 打开CUDNN
![]()
2. 打开opencv(如果使用就打开)

3. 打开Openblas

4. 打开anaconda,如果使用anaconda环境需要打开,由于安装库方便及兼容性问题,本人使用了anaconda
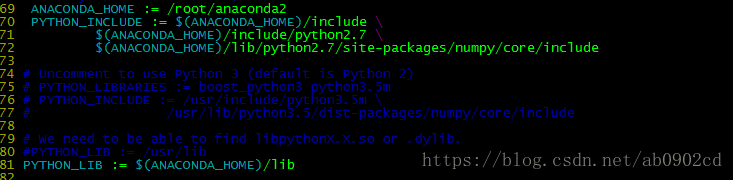
5. 打开python layer支持
![]()
如果不打开,可能会遇到以下问题
I0822 09:32:26.120649 3367 layer_factory.hpp:77] Creating layer data-input
F0822 09:32:26.120674 3367 layer_factory.hpp:81] Check failed: registry.count(type) == 1 (0 vs. 1) Unknown layer type: Python (known types: AbsVal, Accuracy, ArgMax, BNLL, BatchNorm, BatchReindex, Bias, Concat, ContrastiveLoss, Convolution, Crop, Data, Deconvolution, Dropout, DummyData, ELU, Eltwise, Embed, EuclideanLoss, Exp, Filter, Flatten, HDF5Data, HDF5Output, HingeLoss, Im2col, ImageData, InfogainLoss, InnerProduct, Input, LRN, LSTM, LSTMUnit, Log, MVN, MemoryData, MultinomialLogisticLoss, PReLU, Parameter, Pooling, Power, RNN, ReLU, Reduction, Reshape, SPP, Scale, Sigmoid, SigmoidCrossEntropyLoss, Silence, Slice, SmoothL1Loss, Softmax, SoftmaxWithLoss, Split, TanH, Threshold, Tile, WindowData)
*** Check failure stack trace: ***
6. 加入protobuf的库
![]()
到此,配置步骤完成。
以上所有步骤完成后就开始训练模型:
Train with YOUR dataset
cd $CRPN_ROOT
./experiments/scripts/train.sh [NET] [MODEL] [DATASET] [ITER_NUM]或者执行
/root/anaconda2/bin/python tools/train_net.py --gpu=0 --weights=VGG_ILSVRC_16_layers.caffemodel --imdb=voc_2007_train --iters=100000 --solver=models/vgg16/solver.pt --cfg=models/vgg16/config.yml
注意:在训练之前,查看data目录下面是否存在cache文件夹,如果存在最后先删除该文件下面所有内容(避免出现莫名的问题),再开始训练,默认会去读取改文件夹下的pkl文件。在训练之前执行export LD_LIBRARY_PATH=/usr/local/protobuf-3.0.2-compiled/lib:/usr/local/cuda-9.0/lib64:/usr/local/lib:/usr/lib:/usr/lib64:/$CONDA_HOME/lib
可能遇到的问题:
1. 运行faster rcnn时,发生“protobuf'module' object has no attribute 'text_format'”,是因为protobuf的版本发生了变化,解决方法:
在文件./lib/fast_rcnn/train.py增加一行import google.protobuf.text_format 即可解决问题
2. python未注册问题 Check failed: registry.count(type) == 1 (0 vs. 1) Unknown layer type: Python (known types: AbsVal, Accuracy, ArgMax, BNLL, BatchNorm, BatchReindex, Bias, Concat, ContrastiveLoss, Convolution, Crop, Data, Deconvolution, Dropout, DummyData, ELU, Eltwise, Embed, EuclideanLoss, Exp, Filter, Flatten, HDF5Data, HDF5Output, HingeLoss, Im2col, ImageData, InfogainLoss, InnerProduct, Input, LRN, LSTM, LSTMUnit, Log, MVN, MemoryData, MultinomialLogisticLoss, PReLU, Parameter, Pooling, Power, RNN, ReLU, Reduction, Reshape, SPP, Scale, Sigmoid, SigmoidCrossEntropyLoss, Silence, Slice, SmoothL1Loss, Softmax, SoftmaxWithLoss, Split, TanH, Threshold, Tile, WindowData)
在Makefile.config 文件中打开WITH_PYTHON_LAYER :=1,并重新编译caffe和pycaffe生成相关库
3. libcudart.so.* 库importError问题,如
ImportError: libcudart.so.8.0: cannot open shared object file: No such file or directory
在terminal中export LD_LIBRARY_PATH=/usr/local/protobuf-3.0.2-compiled/lib:/usr/local/cuda-9.0/lib64:/usr/local/lib:/usr/lib:/usr/lib64:$CONDA_HOME/lib
4. 数据格式问题
PascalVOC 数据使用[xmin, ymin, xmax, ymax] 生成annotations, 而crpn使用 [x1, y1, x2, y2, x3, y3, x4, y4] 来表示一个box,可表示旋转的矩形框. [bndbox] 内容格式如下:
158
128
158
181
411
181
411
128
如果数据格式是txt格式,需要转换为xml格式,转换脚本如下
import os
from xml.dom.minidom import Document
from xml.dom.minidom import parse
import xml.dom.minidom
import numpy as np
import csv
import cv2
def WriterXMLFiles(filename, path, box_list, label_list, w, h, d):
# dict_box[filename]=json_dict[filename]
doc = xml.dom.minidom.Document()
root = doc.createElement('annotation')
doc.appendChild(root)
foldername = doc.createElement("folder")
foldername.appendChild(doc.createTextNode("JPEGImages"))
root.appendChild(foldername)
nodeFilename = doc.createElement('filename')
nodeFilename.appendChild(doc.createTextNode(filename))
root.appendChild(nodeFilename)
pathname = doc.createElement("path")
pathname.appendChild(doc.createTextNode("xxxx"))
root.appendChild(pathname)
sourcename=doc.createElement("source")
databasename = doc.createElement("database")
databasename.appendChild(doc.createTextNode("Unknown"))
sourcename.appendChild(databasename)
annotationname = doc.createElement("annotation")
annotationname.appendChild(doc.createTextNode("xxx"))
sourcename.appendChild(annotationname)
imagename = doc.createElement("image")
imagename.appendChild(doc.createTextNode("xxx"))
sourcename.appendChild(imagename)
flickridname = doc.createElement("flickrid")
flickridname.appendChild(doc.createTextNode("0"))
sourcename.appendChild(flickridname)
root.appendChild(sourcename)
nodesize = doc.createElement('size')
nodewidth = doc.createElement('width')
nodewidth.appendChild(doc.createTextNode(str(w)))
nodesize.appendChild(nodewidth)
nodeheight = doc.createElement('height')
nodeheight.appendChild(doc.createTextNode(str(h)))
nodesize.appendChild(nodeheight)
nodedepth = doc.createElement('depth')
nodedepth.appendChild(doc.createTextNode(str(d)))
nodesize.appendChild(nodedepth)
root.appendChild(nodesize)
segname = doc.createElement("segmented")
segname.appendChild(doc.createTextNode("0"))
root.appendChild(segname)
for (box, label) in zip(box_list, label_list):
nodeobject = doc.createElement('object')
nodename = doc.createElement('name')
nodename.appendChild(doc.createTextNode(str(label)))
nodeobject.appendChild(nodename)
nodebndbox = doc.createElement('bndbox')
nodex1 = doc.createElement('x1')
nodex1.appendChild(doc.createTextNode(str(box[0])))
nodebndbox.appendChild(nodex1)
nodey1 = doc.createElement('y1')
nodey1.appendChild(doc.createTextNode(str(box[1])))
nodebndbox.appendChild(nodey1)
nodex2 = doc.createElement('x2')
nodex2.appendChild(doc.createTextNode(str(box[2])))
nodebndbox.appendChild(nodex2)
nodey2 = doc.createElement('y2')
nodey2.appendChild(doc.createTextNode(str(box[3])))
nodebndbox.appendChild(nodey2)
nodex3 = doc.createElement('x3')
nodex3.appendChild(doc.createTextNode(str(box[4])))
nodebndbox.appendChild(nodex3)
nodey3 = doc.createElement('y3')
nodey3.appendChild(doc.createTextNode(str(box[5])))
nodebndbox.appendChild(nodey3)
nodex4 = doc.createElement('x4')
nodex4.appendChild(doc.createTextNode(str(box[6])))
nodebndbox.appendChild(nodex4)
nodey4 = doc.createElement('y4')
nodey4.appendChild(doc.createTextNode(str(box[7])))
nodebndbox.appendChild(nodey4)
# ang = doc.createElement('angle')
# ang.appendChild(doc.createTextNode(str(angle)))
# nodebndbox.appendChild(ang)
nodeobject.appendChild(nodebndbox)
root.appendChild(nodeobject)
fp = open(path + filename, 'w')
doc.writexml(fp, indent='\n')
fp.close()
def load_annoataion(p):
'''
load annotation from the text file
:param p:
:return:
'''
text_polys = []
text_tags = []
if not os.path.exists(p):
return np.array(text_polys, dtype=np.float32)
with open(p, 'r') as f:
reader = csv.reader(f)
for line in reader:
label = 'text'
# strip BOM. \ufeff for python3, \xef\xbb\bf for python2
line = [i.strip('\ufeff').strip('\xef\xbb\xbf') for i in line]
x1, y1, x2, y2, x3, y3, x4, y4 = list(map(float, line[:8]))
text_polys.append([x1, y1, x2, y2, x3, y3, x4, y4])
text_tags.append(label)
return np.array(text_polys, dtype=np.int32), np.array(text_tags, dtype=np.str)
if __name__ == "__main__":
txt_path = '/data/data/icpr/tianchiData_train'
xml_path = '/data/icpr_xml/Annotations/'
img_path = '/data/icpr_xml/JPEGImages/'
print(os.path.exists(txt_path))
txts = [f for f in os.listdir(txt_path) if f.endswith('.txt')]
for count, t in enumerate(txts):
boxes, labels = load_annoataion(os.path.join(txt_path, t))
xml_name = t.replace('.txt', '.xml')
img_name = t.replace('.txt', '.jpg')
img = cv2.imread(os.path.join(img_path, img_name.split('gt_')[-1]))
if img is not None:
h, w, d = img.shape
WriterXMLFiles(xml_name.split('gt_')[-1], xml_path, boxes, labels, w, h, d)
if count % 1000 == 0:
print(count)