使用香橙派 在Linux环境中安装并学习Python
前言
在实际项目中,经常会遇到需要使用人工智能的场景,如人脸识别,车牌识别等...其一般的流程就是由单片机采集数据发送给提供人工智能算法模型的公司(百度云,阿里云...),然后人工智能将结果回传给单片机,单片机根据结果来对应的操作。
而人工智能的代码普遍要使用python而不是C,所以将数据发给人工智能以及从人工智能拿回数据时,需要涉及到如何在C中使用Python的知识。
综上所述,Python是作为一名合格的嵌入式工程师所必备的技能之一,本节就开始学习Python,主要的学习目标是:用C语言的视角学习python基本概念,学习C语言的Python接口
(PS:其实我的研究生第一学期也学习了Python,不过已经过去了一段时间,所以这节也可以视为复习课吧)
Python的安装和环境搭建
查看当前python版本:
python --version![]()
由于之后图像识别使用低版本python可能会不支持,所以现在需要将python升级到3.9
更新apt:
sudo apt update安装编译Python需要用到的环境:
sudo apt install -y build-essential zlib1g-dev \
libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libsqlite3-dev \
libreadline-dev libffi-dev curl libbz2-dev正式下载Python源码:
wget \
https://www.python.org/ftp/python/3.9.10/Python-3.9.10.tgz
解压源码包:
tar xvf Python-3.9.10.tgz配置安装选项:
1. cd Python-3.9.10/
2. ./configure --enable-optimizations
编译:(35min左右)
make -j4 //j4代表四核全速正式安装:
sudo make install执行完以上的所有步骤,Python3.9就被成功的安装在了/usr/local/bin下!
建立软连接:
其实在local/bin下有很多版本的python,所以为了使得python指令可以准确的知道我要使用的是3.9版本的python,软连接的建立是十分必要的。
执行“ls /usr/bin/python -l”:
可见,现在的软链接指向的是/usr/bin/python2.7
执行“python --version”:
也还是python2.7

所以的确需要修改:
sudo rm -f /usr/bin/python //删除原来的软连接
sudo ln -s /usr/local/bin/python3.9 /usr/bin/python // 在/usr/bin/目录创建软连接python,定向/usr/local/bin/python3.9
python --version //检查python版本是否是3.9

软连接成功!!
更新pip & 更新源
Linux 系统 pip 默认使用的源为 Python 官方的源, 但是国内访问 Python 官方的源速度是很慢的, 并且经常会由于网络原因导致 Python 软件包安装失败。 所以在使用 pip 安装 Python 库时, 需要换 pip 源,但是我目前现在在加拿大,所以我暂时没有更新源。
python环境的pip 类似于 C语言的apt-get,从服务器获得python开发用的第三方包
//更新pip
sudo apt install -y python-pip python3-pip
//更新源
mkdir -p ~/.pip //建立pip工作文件夹
vim ~/.pip/pip.conf //添加pip服务器配置文件
//文件内容如下:
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn]至此,python环境的安装正式完成!
输入" python "就可以进入python3.9的指令行模式了:

Python的学习
参考:(写的很好,不懂就去这里面找)
Python十分钟入门 | 菜鸟教程
Python pass 语句 | 菜鸟教程
Python是一种动态解释型的编程语言,Python可以在Windows、UNIX、MAC等多种操作系统上 使用,也可以在Java、.NET开发平台上使用。
Python的特点
- Python使用C语言开发,但是Python不再有C语言中的指针等复杂的数据类型。
- Python具有很强的面向对象特性,而且简化了面向对象的实现。它消除了保护类型、抽象类、接口等面向对象的元素。
- Python代码块使用空格或制表符缩进的方式分隔代码。
- Python仅有31个保留字,而且没有分号、begin、end等标记。
- Python是强类型语言,变量创建后会对应一种数据类型,出现在统一表达式中的不同类型的变量需要做类型转换。
编写并运行一个python程序
创建一个“mjm_python”文件夹,在文件夹内创建一个“demo1.py”:(其实linux系统不是很关心文件的后缀名,py也行,其他也行,但是为了格式还是写成py最好)

demo1.py:
print("linux C python")保存退出后,输入“python demo1.py” 即可运行程序:
![]()
- 而如果在 demo1.py 的开头就指定解释器:
#! /usr/bin/python print("linux C python")
- 并使用“chmod +x demo1.py”来赋予执行权限;
那么直接执行“./demo1.py”就可以运行程序:
如果开头加上“# -* - coding: UTF-8 -* -” 则可以支持中文显示,所以py文件的开头就默认写这两句话:
#! /usr/bin/python # -* - coding: UTF-8 -* -
输入输出变量
- 输出就是刚刚演示的print函数,注意print函数会自动在打印后加上换行符;
- 获取用户输入则使用input函数
input.py:
#! /usr/bin/python
# -* - coding: UTF-8 -* -
s = input("输入内容,按下ENTER结束\n")
for i in s:
print(i)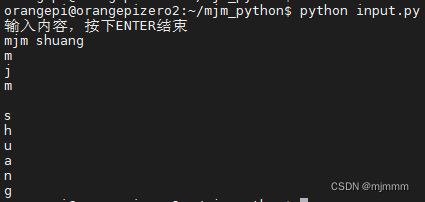
注意,input返回的永远都是字符串,所以如果想要给 整数或者浮点数 等不是字符串的变量 赋值时,需要进行强转:a = int(a)
流程控制
- python不支持自增运算符和自减运算符。例如i++/i-是错误的,但i+=1是可以的。
- 1/2在python2.5之前会等于0.5,在python2.5之后会等于0。
- 不等于为!=或<>
- 等于用==表示
- 逻辑表达式中and表示逻辑与,or表示逻辑或,not表示逻辑非
if/else:
if (表达式) :
语句1
elif (表达式) :
语句2
…
elif (表达式) :
语句n
else :
语句mfor:
for 变量 in 集合 :
…
else : #一般不用
…while:
while(表达式) :
…
else : #一般不用
…列表&元组&字典
列表List:
- 序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
- Python有6个序列的内置类型,但最常见的是列表和元组。
- 序列都可以进行的操作包括索引,切片,加,乘,检查成员。
- 此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
- 列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
- 列表的数据项不需要具有相同的类型
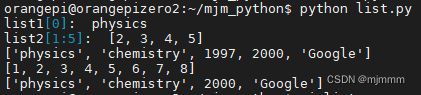
list.py:
#! /usr/bin/python # -* - coding: UTF-8 -* - list1 = ['physics', 'chemistry', 1997, 2000] list2 = [1, 2, 3, 4, 5, 6, 7 ] print("list1[0]: ", list1[0]) print("list2[1:5]: ", list2[1:5]) list1.append('Google') ## 使用 append() 添加元素 list2.append(8) print(list1) print(list2) del list1[2] ##使用del命令删除list print(list1)
元组Tuple:
- Python 的元组与列表类似,不同之处在于元组的元素不能修改
- 元组使用小括号,列表使用方括号
- 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
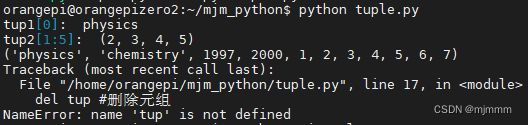
tuple.py:
#! /usr/bin/python # -* - coding: UTF-8 -* - tup1 = ('physics', 'chemistry', 1997, 2000) tup2 = (1, 2, 3, 4, 5, 6, 7 ) print("tup1[0]: ", tup1[0]) print("tup2[1:5]: ", tup2[1:5]) # 以下修改元组元素操作是非法的。 # tup2[0] = 100 # 创建一个新的元组 tup3 = tup1 + tup2 print(tup3) del tup #删除元组 print("after delete:") print(tup3)
字典Dictionary:
- 字典是另一种可变容器模型,且可存储任意类型对象
- 字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式:d = {key1 : value1, key2 : value2 }
- dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict
- 键(key)一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一
- 值(value)可以取任何数据类型,但键(key)必须是不可变的,如字符串,数字或元组
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象
- 字典值(value)可以没有限制地取任何 python 对象,既可以是标准的对象,也可以是用户定义的,但键(key)不行
dict.py:
#! /usr/bin/python # -* - coding: UTF-8 -* tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'} print("tinydict['Name']: ", tinydict['Name']) print("tinydict['Age']: ", tinydict['Age']) ## print("tinydict['Alice']: ", tinydict['Alice']) #由于没有名为Alice的key,所以这句会报错 tinydict['Age'] = 8 # 更新 tinydict['School'] = "RUNOOB" # 添加 print("tinydict['Age']: ", tinydict['Age']) print("tinydict['School']: ", tinydict['School']) del tinydict['Name'] # 删除键是'Name'的条目 tinydict.clear() # 清空字典所有条目 del tinydict # 删除字典

函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明
- 函数内容以冒号起始,并且缩进
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]func.py:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def printme( str ):
#"打印任何传入的字符串"
print(str)
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
![]()
模块
support.py:(作为一个模块)
def print_func( par ):
print("Hello : ", par)
return
demo2.py:(调用support模块)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入模块
import support
#也可以 import print_func from support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
#这里可以直接写成print_func("Runoob") 如果刚刚写成import print_func from support
![]()
文件
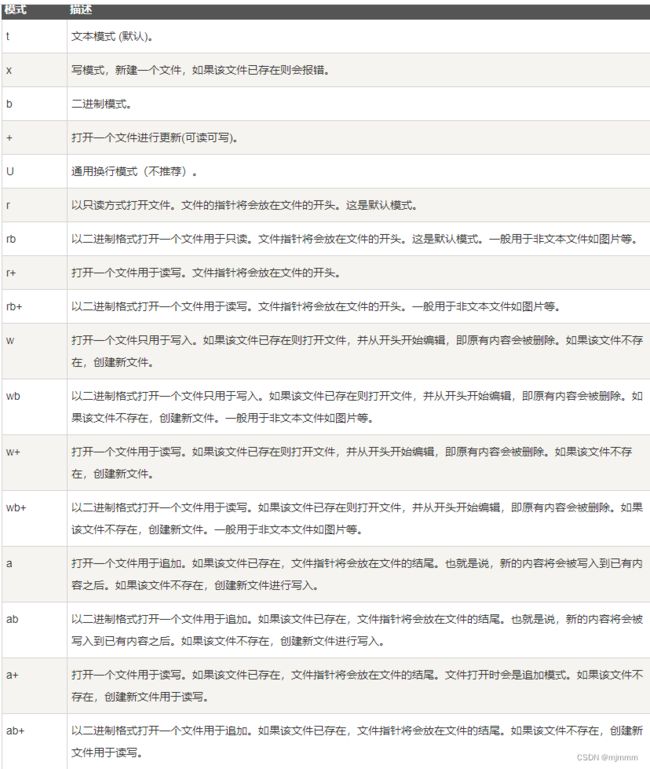
file.py:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件,只写,且文件不存在就创建
fo = open("foo.txt", "w")
#写内容
fo.write( "mjm! Very good!\n")
# 关闭打开的文件
fo.close
# 打开一个文件,读写
fo = open("foo.txt", "r+")
#读内容
str = fo.read(20)
print("读取的字符串是 : ", str)
# 查找当前位置
position = fo.tell()
print("当前文件位置 : ", position)
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(20)
print("重新读取字符串 : ", str)
# 关闭打开的文件
fo.close()
为什么不直接用r+读写打开之后直接写?
因为foo.txt不存在,而r+不支持创建文件,所以可以先使用w只写打开,w支持“如果文件不存在就创建”