性能测试工具-Locust的使用方法
Locust介绍
Locust是一款使用Python开发的开源性能测试工具,支持分布式,可在多台主机上对系统持续发送请求,与Jmeter、LoadRunner的等压测工具使用线程的方式模拟用户请求不同,Locust是使用协程的方式模拟用户请求,协程的上下文切换是由自己控制,当一个协程执行完成后会主动让出,让另一个协程开始执行,切换是在用户态完成的,而线程切换是受系统控制,是在用户态与内核态之间切换,所以协程上下文切换的代价远比线程切换的代价小的多,因此Locust可以达到更高数量级的并发,更多介绍请查看官方文档
Locust安装
需要先安装python3.6以上版本,然后再安装Locust
pip install locust # 安装locust
locust -V # 查看版本
Locust文件编写
locust是通过编写python脚本进行测试的,直接看代码吧!对于单接口场景,如下所示:
TaskSet类和SequentialTaskSet类实现了虚拟用户所执行任务的调度算法,包括挑选任务、执行任务、规划执行顺序等等;HttpUser中有一个用于发送http请求的client属性,在发送请求前需先调用HttpUser类;task装饰器是为了给用户添加任务,只有带有task装饰器的方法才会发起请求;constant是设置固定等待时间
# OPLogin.py文件
import re
from locust import HttpUser,task,TaskSet,constant
# openstack登录
class MyTask(TaskSet):
# on_start/on_stop是前置和后置操作方法,与jmeter中的setup/teardown类似,开始前后执行一次
def on_start(self):
self.op_url = "/dashboard/auth/login/"
# 访问登录页面
res = self.client.get(url=self.op_url, name="获取token")
# 使用正则表达式在响应文档中提取动态token
csrf = re.findall('name="csrfmiddlewaretoken" value="(.+(?=">))', res.text)
# 将列表转为字符串,使用join方法将非字符串的格式内容都去掉,把列表中的内容都取出来,用空字符进行连接
self.token = "".join(csrf)
self.cookie = res.cookies
print("********** 开始执行性能测试 **********")
def on_stop(self):
print("********** 测试结束 **********")
@task # @task装饰器的作用是将opLogin标记为可被调用的方法
def opLogin(self):
# 登录参数
data = {
"csrfmiddlewaretoken": self.token, # 调用on_start中获取的token
"region": "default",
"username": "admin",
"password": "0565317d22c54a97"
}
# 发送登录请求,url与on_start中的一样,直接调用
resp = self.client.request(method="post",url=self.op_url,data=data,name="登录openstack")
try: # 断言,判断响应文本中是否包含指定内容,包含则返回“成功”,否则返回“失败”并打印异常
assert "Instance Overview - OpenStack Dashboard" in resp.text
print("登录成功")
except Exception as e:
print("登录失败,未找到【Instance Overview - OpenStack Dashboard】",e)
class OPlogin(HttpUser):
tasks = [MyTask] # 要执行的任务
host = "http://192.166.66.33" # 被测网站域名
wait_time = constant(3) # 请求间隔时间,每次请求间隔固定3s
对于多接口测试,也是同样的操作,在每个方法上加上task装饰器即可,task装饰器上可添加权重参数,如下所示
# CreateRES.py文件
import re
from locust import HttpUser,task,TaskSet
class MyTask(TaskSet):
# 由于未登录无法访问创建资源,所以先直接将获取token和登录都放到on_start中
def on_start(self):
self.op_url = "/dashboard/auth/login/"
# 发送获取token请求
res = self.client.get(url=self.op_url, name="获取token")
csrf = re.findall('name="csrfmiddlewaretoken" value="(.+(?=">))', res.text)
self.token = "".join(csrf)
self.cookie = res.cookies
data = {
"csrfmiddlewaretoken": self.token,
"region": "default",
"username": "admin",
"password": "0565317d22c54a97"
}
# 发送登录请求
self.client.request(method="post",url=self.op_url,data=data,name="登录openstack")
print("********** 开始执行性能测试 **********")
@task(6) # (6)是可选权重参数,自定义权重占比为6
def CreateVolume(self):
vol_url = "/dashboard/project/volumes/create/"
vol_data = {
"csrfmiddlewaretoken":self.token, # 调用on_start中获取的token
"name":"dyd-volume",
"volume_source_type":"no_source_type",
"type":"iscsi",
"size":"1",
"availability_zone":"nova"
}
# 发送创建云硬盘的请求,需有cookie才能创建成功,在on_start中获取cookie后调用
self.client.request(method="post",url=vol_url,data=vol_data,cookies=self.cookie,name="创建云硬盘")
@task(3) # 权重占比为3
def CreateSecGroup(self):
csecg_url = "/dashboard/project/security_groups/create/"
csecg_data = {"csrfmiddlewaretoken":self.token,"name":"dyd-SecG"}
self.client.request(method="post",url=csecg_url,data=csecg_data,name="创建安全组")
@task
def SecGList(self):
secg_url = "/dashboard/project/security_groups/"
self.client.request(method="get",url=secg_url,name="查看安全组列表")
class OPlogin(HttpUser):
tasks = [MyTask]
host = "http://192.166.66.33"
对于业务流的测试,需要使用SequentialTaskSet类,可以按代码顺序由上到下执行带有task装饰器的任务
# Operflow.py文件
import re
from locust import HttpUser,task,between,SequentialTaskSet
# openstack中创建云硬盘业务流性能测试
class MyTask(SequentialTaskSet):
@task # 步骤一,先获取token
def get_token(self):
self.op_url = "/dashboard/auth/login/"
res = self.client.get(url=self.op_url, name="获取token")
# 使用正则表达式在响应文档中提取动态token
csrf = re.findall('name="csrfmiddlewaretoken" value="(.+(?=">))', res.text)
# 将列表转为字符串,使用join方法将非字符串的格式内容都去掉,把列表中的内容都取出来,用空字符进行连接
self.token = "".join(csrf)
self.cookie = res.cookies
print("********** 开始执行性能测试 **********")
@task # 步骤二,拿到token后登录到平台
def opLogin(self):
data = {
"csrfmiddlewaretoken": self.token, # 调用on_start中获取的token
"region": "default",
"username": "admin",
"password": "0565317d22c54a97"
}
# 发送登录请求,url与on_start中的一样,直接调用
resp = self.client.request(method="post",url=self.op_url,data=data,name="登录openstack")
try: # 断言,判断响应文本中是否包含指定内容,包含则返回“成功”,否则返回“失败”并打印异常
assert "Instance Overview - OpenStack Dashboard" in resp.text
print("登录成功")
except Exception as e:
print("登录失败,未找到【Instance Overview - OpenStack Dashboard】",e)
@task # 步骤三,登录平台后创建资源
def CreateVolume(self):
vol_url = "/dashboard/project/volumes/create/"
vol_data = {
"csrfmiddlewaretoken":self.token,
"name":"dyd-volume",
"volume_source_type":"no_source_type",
"type":"iscsi",
"size":"1",
"availability_zone":"nova"
}
# 发送创建云硬盘的请求
self.client.request(method="post",url=vol_url,data=vol_data,cookies=self.cookie,name="创建云硬盘")
class OPlogin(HttpUser):
tasks = [MyTask]
host = "http://192.166.66.33"
wait_time = between(0.5,2) # 请求间隔时间,会在0.5~2s之间产生一个随机数作为思考时间
也可以只调用HttpUser类,通常代码量少时使用,tag装饰器是为了标记任务,可以执行指定带有某个标记的任务
# jpress.py文件
from locust import HttpUser, task, tag
class MyJPress(HttpUser):
host = "http://192.166.66.22:8080"
@tag("login")
@task
def dologin(self):
login_url = "/user/doLogin"
data = {"user":"admin","pwd":"123456"}
self.client.request(method="post",data=data,url=login_url,name="登录JPress")
@tag("details","info")
@task
def lkarticle(self):
url = "/article/2"
self.client.request(method="get",url=url,name="查看文章详情")
断言
上文中登录通过查找响应结果中是否包含关键字判断是否正确,还可以通过响应码、响应状态、响应时间等方法进行断言
from locust import HttpUser, task, tag
class MyJPress(HttpUser):
host = "http://192.166.66.22:8080"
@task
def dologin(self):
login_url = "/user/doLogin"
data = {"user":"admin","pwd":"123456"}
resp = self.client.request(method="post",data=data,url=login_url,name="登录JPress")
if resp.status_code != 200: # 通过状态码判断
print("访问出错啦!暂时无法登录")
elif resp.json()["state"] == "ok": # 通过响应状态判断
print("登录成功")
elif resp.elapsed.total_seconds() > 1: # 通过响应时长判断
print("请求响应时间过长")
@task
def lkarticle(self):
url = "/article/2"
# 使用catch_response参数和with语句判断请求结果
with self.client.request(method="get",url=url,name="查看文章详情",catch_response=True) as res:
if "小测试" in res.text:
res.success()
else:
res.failure("无法查看文章详情!")
参数化
可借助第三方库mimesis或faker进行参数化,可自动生成账号、密码、邮箱、文本、地址、日期等
pip install mimesis # 安装mimesis库
from locust import HttpUser, task, tag
from mimesis import Text # 导入mimesis库中的Text模块
class MyJPress(HttpUser):
host = "http://192.166.66.22:8080"
@task
def dologin(self):
login_url = "/user/doLogin"
data = {"user":"admin","pwd":"123456"}
resp = self.client.request(method="post",data=data,url=login_url,name="登录JPress")
@task
def writeArt(self):
csrf_url = "/ucenter"
csrf = self.client.request(method="get", url=csrf_url, name="获取csrf_token")
self.token = csrf.cookies["csrf_token"] # 提取csrf_token值
war_url = "/ucenter/article/doWriteSave"
art = Text("zh")
data = {"article.edit_mode":"markdown",
"article.title": art.color() + art.level() +"……", # 使用mimesis生成标题
"article.content":art.text(), # 使用mimesis生成文章内容
"csrf_token": self.token
}
resp = self.client.request(method="post",url=war_url,data=data,name="投稿文章")
Locust文件执行
GUI模式
单击压测,-f表示要执行的文件,--tags表示执行带有指定标签的任务
locust -f 路径/文件名.py # 执行文件中所有待@task装饰器的任务
locust -f 路径/文件名.py --tags login info # 执行文件中标签为login、info的任务
之后在浏览器中输入IP:8089访问Web页面,输入总用户数和每秒增加用户数,因为代码中已经定义Host,Web页面会自动带入,若未定义可在命令中带上--host参数,或者直接在Web页面输入
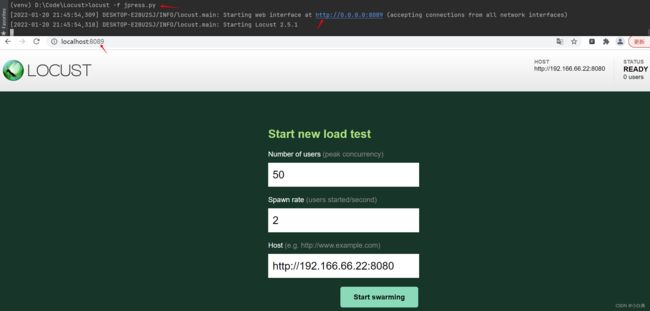
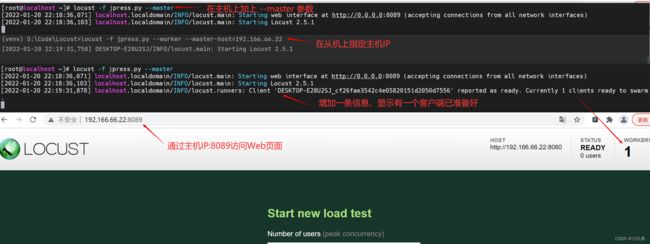
分布式压测,使用多台主机时需指明主从机器,--master表示作为主机使用,--worker表示作为从机使用,--master-host与--worker一起使用,设置主机的主机名或IP,分布式压测每台机器上都要需要安装locust,而且需要将文件拷贝至所用到的每台机器上
locust -f 路径/文件名.py --master # 在主机上执行此命令,Web界面会在此主机上运行
locust -f 路径/文件名.py --worker --master-host=192.166.66.22 # 在每台从机上执行此命令,指定主机IP
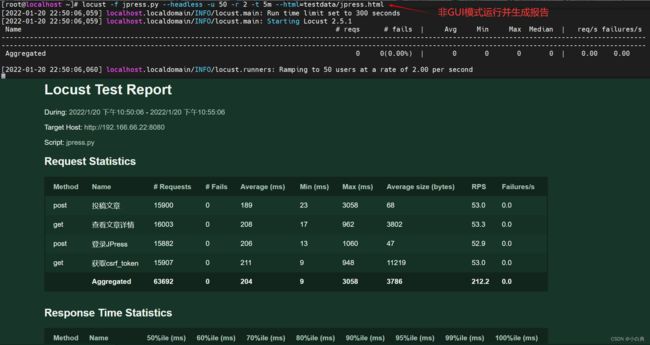
非GUI模式
单机压测,--headless表示使用没有UI界面的方式运行,-u表示总用户数,-r表示每秒增加的用户数,-t表示测试运行时间,--html是输出测试报告,也可以使用--csv导出csv格式的测试结果,会导出4个结果文件,-t、--html、--csv都是可选参数
locust -f 路径/文件名.py --headless -u 30 -r 2 -t 1h30m --html=路径/报告名.html
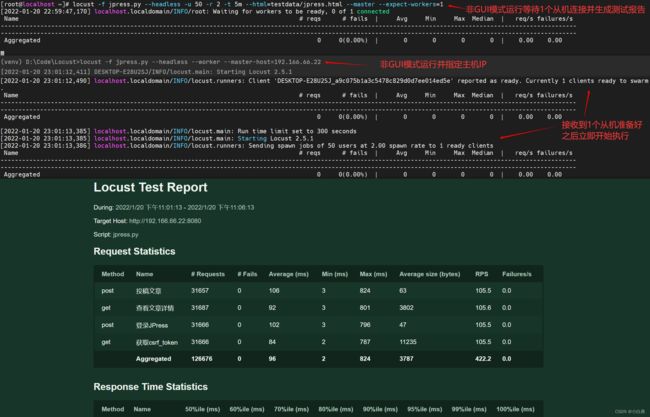
分布式压测,非GUI模式使用以下命令,--expect-workers表示等待几个从机连接后再开始测试,从机个数达到要求后会立即开始执行
locust -f 路径/文件名.py --headless -u 10 -r 2 -t 5s --master --expect-workers=2 # 在主机上执行,可带上报告参数
locust -f 路径/文件名.py --headless --worker --master-host=192.166.66.22 # 在每台从机上执行此命令
监控工具
基本性能指标:响应时间、吞吐量、资源利用率,使用Locust自带的监控功能即可
也可以使用系统自带的监控工具:vmstat、top,或nmon、dstat,后两项需要使用yum命令安装
还可以使用Prometheus+Grafana实现更炫酷的监控图表,如下所示,整个压测过程系统性能变化会以图表形式展示
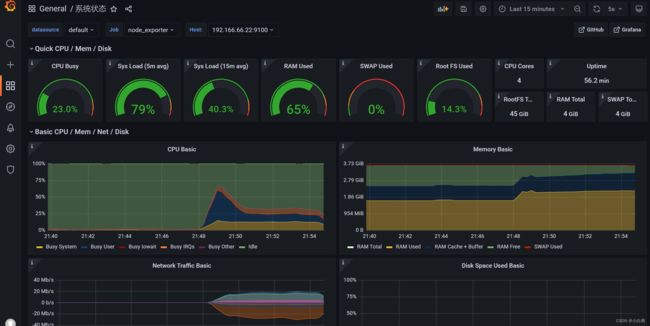
通常一个正常系统应随着压力增大CPU的利用率也应不断升高,所以性能测试首先关注的是CPU,CPU上不去就意味着压力上不去,压力上不去又意味着无法测试系统的处理能力,继续压测并没有什么意义。单台机器的CPU处理能力是有限的,所以通常采用分布式的方式进行性能测试,从上文的报告就可以看出单台机器与分布式测试的RPS是有很大差距的,只有压力上去之后测试的结果才更准确,更容易确定系统瓶颈,常见的系统瓶颈有线程阻塞、数据库加锁、磁盘IO阻塞等