01.MySQL(SQL分类及使用)
注意:DML只是进行增删改,DQL才有查询
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
DDL
数据库操作:
1. 查询所有数据库
SHOW DATABASES;
2. 查询所处数据库
SELECT DATABASE();
3. 创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名 [DEFAULT CHARSET 字符集] [COLLATE 排序规则];
--例:CREATE DATABASE test01 DEFAULT CHARSET utf8mb4;
4. 删除数据库
DROP DATABASE [IF EXISTS] 数据库名;
5. 使用
USE 数据库名;
表操作:
1. 查询当前数据库中所有表
SHOW TABLES;
2. 查询表结构
DESC 表名;
3. 查询指定表的建表语句
SHOW CREATE TABLE 表名;
4. 添加字段
ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束];
5. 修改字段类型
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
6. 修改字段名和字段类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
7. 删除字段
ALTER TABLE 表名 DROP 字段名;
8. 修改表名
ALTER TABLE 表名 RENAME TO 新表名;
9. 创建表
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释],
...
字段1 字段1类型 [COMMENT 字段1注释]
)[COMMENT 表注释];
10. 删除表
DROP TABLE [IF EXISTS] 表名;
11. 删除表中所有数据,删表后建表
TRUNCATE TABLE 表;
数据类型
| 分类 | 类型 | 大小 | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|---|
| 数值类型 | TINYINT | 1 byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 bytes | (-32768,32767) | (0,65535) | 大整数值 | |
| MEDIUMINT | 3 bytes | (-8388608,8388607) | (0,16777215) | 大整数值 | |
| INT或INTEGER | 4 bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 | |
| BIGINT | 8 bytes | (-263 ,263-1) | (0,264-1) | 极大整数值 | |
| FLOAT | 4bytes | 单精度浮点数值 | |||
| DOUBLE | 8 bytes | 双精度浮点数值 | |||
| DECIMAL | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确点数) |
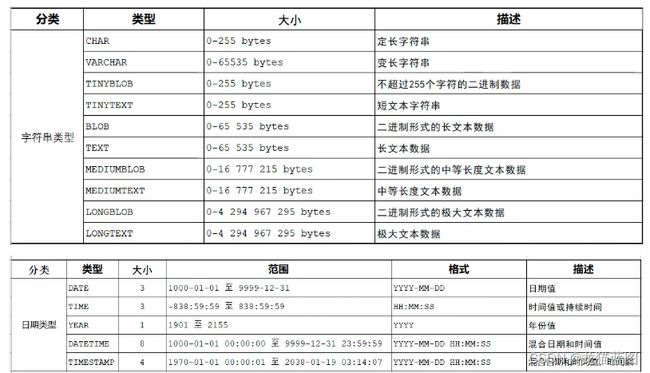
日期类型注意timestamp 跟 datetime,它们表示的年份范围不同,其中timestamp会根据时区不同自动转换日期时间,而datetime则会保持不变。
| date_time | time_stamp |
|---|---|
| 2020-01-11 09:53:32 | 2020-01-11 09:53:32 |
现在我们运行
修改当前会话的时区:
set time_zone='+8:00';
再次查看数据:
| date_time | time_stamp |
|---|---|
| 2020-01-11 09:53:32 | 2020-01-11 17:53:32 |
性能
由于 TIMESTAMP 需要根据时区进行转换,所以从毫秒数转换到 TIMESTAMP 时,不仅要调用一个简单的函数,还要调用操作系统底层的系统函数。这个系统函数为了保证操作系统时区的一致性,需要进行加锁操作,这就降低了效率。
DATETIME 不涉及时区转换,所以不会有这个问题。
为了避免 TIMESTAMP 的时区转换问题,建议使用指定的时区,而不是依赖于操作系统时区。
# 查看当前会话时区
SELECT @@session.time_zone;
# 设置当前会话时区
SET time_zone = 'Europe/Helsinki';
SET time_zone = "+00:00";
# 数据库全局时区设置
SELECT @@global.time_zone;
# 设置全局时区
SET GLOBAL time_zone = '+8:00';
SET GLOBAL time_zone = 'Europe/Helsinki';
DML
DML:Data Manipulation Language(数据操作语言),用于对数据库表中表的数据记录进行增删改操作。
添加数据
- 指定字段添加数据
INSERT INTO 表名 (字段名1,字段名2,...) values (值1,值2,...);
- 给全部字段添加数据
INSERT INTO 表名 VALUES (值1,值2,...);
- 批量添加数据
INSERT INTO 表名 (字段名1,字段名2,...) values (值1,值2,...),(值1,值2,...);
注意:字符串和日期类型数据应该包含在括号中。
更新数据
UPDATE 表名 SET 字段名1 = 值1,字段名2 = 值2,...[WHERE 条件];
注意:条件可以有也可以没有,没有就是修改整张表的所有数据。
删除数据
DELETE FROM 表名 [WHERE 条件];
注意:DELETE不设置条件删除整张表,DELETE不能删除某个字段,但可以使用UPDATE
DQL

基本查询
- 多字段查询
SELECT 字段1,字段2... FROM 表名;
- 全部字段查询
SELECT * FROM 表名;
- 设置别名
SELECT 字段1 [AS 别名1],字段2 [AS 别名1]... FROM 表名;
- 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
查询的字段列表数据完全一致为重复。
条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表;
条件:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <>或!= | 不等于 |
| BETWEEN… AND… | 在某个范围之内(含最大、最小值) |
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| IS NULL | 是NULL |
| ADN 或 && | 并且(多个条件同时成立) |
| 或OR 或双竖线 | 或者(多个条件任意一个成立) |
| NOT 或! | 非,不是 |
查询姓名为两个字的员工信息
SELECT * FROM emp WHERE emp_name LIKE '__';
查询身份证最后一位为X的员工信息
SELECT * FROM emp WHERE idcare LIKE '%X';
聚合函数
SELECT 聚合函数(字段列表) FROM 表名;
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件];
where与having条件:
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
注意:
-
执行顺序:where > 聚合函数 > having。
-
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
-
查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
SELECT workaddress FROM emp WHERE age < 45 GROUP BY workaddress HAVING COUNT(*) >= 3;
排序查询
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式,字段2 排序方式
排序方式
- ASC:升序(默认值)
- DESC:降序
注意:如果是多字段排序,当第一个字段值相同时才会根据第二个字段排序。
分页查询
SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询记录数;
执行顺序

DCL
管理用户
- 查询用户【用于查询有哪些用户对当前数据库管理系统有哪些权限】
USE mysql;
SELECT * FROM user;
- 创建用户【表示创建的用户能访问数据库管理系统,并没有权限访问数据库,需要授权】
create user '用户名'@'主机名' identified by '密码';
主机名:使用localhost时表示只能在本机访问,可以使用%表示任意主机都可访问,例如可以进行远程连接。
- 修改用户密码
alter user '用户名'@'主机名' identified with mysql_native_password by '新密码';
- 删除用户
drop user '用户名'@'主机名';
权限管理
- 查询权限
SHOW GRANTS FOR '用户名'@'主机名'
- 授予权限
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
- 撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
权限列表
MySQL中定义了很多种权限,但是常用的就以下几种:
| 权限 | 说明 |
|---|---|
| ALL,ALL PRIVILEGES所有权限 | |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
注意:
- 多个权限之间使用逗号分隔
- 授权时,数据库名和表名可以使用*进行通配,表示所有。