03.MySQL事务及存储引擎笔记
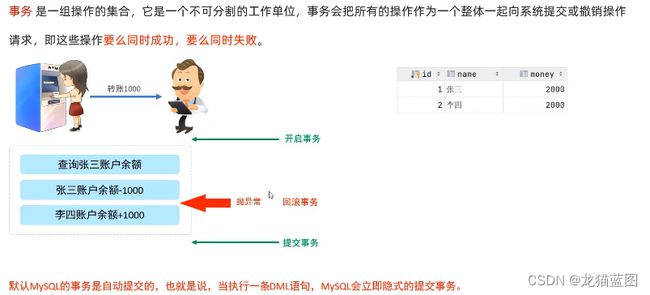
事务
查看/设置事务
select @@autocommit; --查看当前数据库的事务状态,1表示开启,0表示关闭
set @@autocommit = 0; --关闭自动事务提交
采用关闭自动事务提交我们就可以手动进行事务提交,但是这种设置方式是对整个数据库起作用,一些可以立即事务提交的操作,我们也需要commit。所以一般采用下面这种方式开启事务。
开启事务
start transaction 或begin;
提交事务
commit;
回滚事务
rollback;
事务四大特性
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
并发事务问题
脏读: 一个事务读到另一个事务还没有提交的数据。
不可重复读: 一个事务先后读取同一条记录,但两次读取的数据不同。
幻读: 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这条记录,好像出现了“幻影”。

这里事务A先执行id=1的查询语句,发现并没有这条数据,此时事务B过来插入id=1的数据并提交,事务A查询不到数据后进行插入操作,发现数据已经存在,执行一次查询操作又发现数据不存在,就像出现了“幻觉”一样。
隔离级别
MySQL默认的隔离级别是可重复读,Oracle是读已提交。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read(默认) | × | × | √ |
| Serializable | × | × | × |
我们可以设置事务的隔离级别,来演示并发事务安全问题。先设置事务的隔离级别后,开启两个命令行窗口模拟并发事务。
MySQL体系结构

-
连接层
最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
-
服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。
-
引擎层
存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要来选取合适的存储引擎。
-
存储层
主要是将数据存储在文件系统之上,并完成与存储引擎的交互。
存储引擎
存储引擎就是建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎称为表类型。
查看/指定存储引擎
创建表时指定存储引擎:
create table 表名(
字段1 类型 约束,
...
字段n 类型 约束
)engine = innodb;
通过建表语句查看表的存储引擎
show create table 表名;
查看当前数据库支持的存储引擎
show engines;
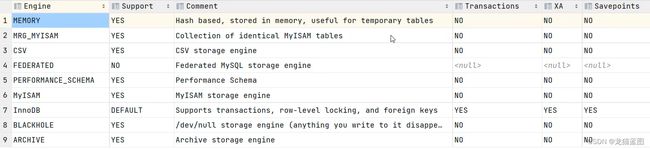
主要关注:MEMORY、InnoDB、MyISAM
Memory
Memory引擎的表数据是存储在内存中的,由于所受到硬件问题或断电问题影响,只能将这些表作为临时表或缓存使用。
特点
- 内存存放。
- hash索引(默认)。
文件
xxx.sdi:存储表结构信息。
MyISAM
MyISAM是MySQL早期的默认存储引擎。【视频读作MySM】
特点
- 不支持事务,不支持外键。
- 支持表锁,不支持行锁。
- 访问速度快。
文件
xxx.sdi:存储表结构信息。
xxx.MYD:存储数据。
xxx.MYI:存储索引。
InnoDB
InnoDB是一种兼顾可靠性和高性能的通用存储引擎,在MySQL5.5之后,InnoDB是默认的MySQL存储引擎。
特点
- DML操作遵循ACID模型,支持事务。
- 行级锁,提高并发访问性能。
- 支持外键约束,保证数据的完整性和正确性。
文件
xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。参数:innodb_file_per_table,默认是开启的:
show variables like 'innodb_file_per_table';
| Variable_name | Value |
|---|---|
| innodb_file_per_table | ON |
我们可以通过命令行模式查看表的表结构中存放的信息:ibd2sdi 表名.ibd
逻辑存储结构
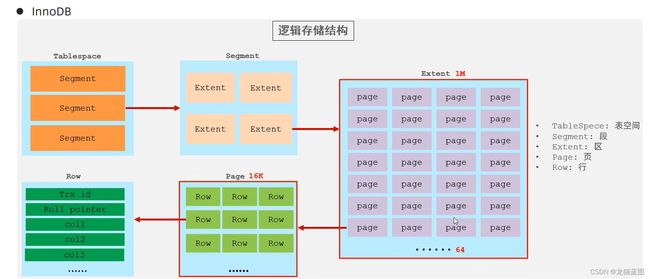
Page是磁盘操作的最小单元,区是固定大小1M,页是固定大小16K,一个区可以包含64个页。
总结
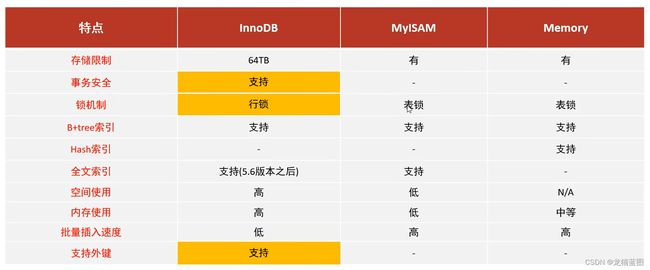
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统还可以根据实际情况选择多种存储引擎进行结合。
- InnoDB:是MySQL的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择它是非常合适的。
- Memory:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。缺点就是对表的大小有限制,太大的表无法缓存在内存中,并且无法保证数据的安全性。
MySQL中表锁和行锁有什么区别:
表锁: 偏向MyISAM存储引擎,开销小,加锁快;无死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行锁: 偏向InnoDB存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。