BSVD论文理解:Real-time Streaming Video Denoising with Bidirectional Buffers
BSVD是来自香港科技大学的一篇比较新的视频去噪论文,经实践,去噪效果不错,在这里分享一下对这篇论文的理解。
论文地址:https://arxiv.org/abs/2207.06937
代码地址:GitHub - ChenyangQiQi/BSVD: [ACM MM 2022] Real-time Streaming Video Denoising with Bidirectional Buffers
我们都知道,在超低照度拍摄的图像中,由于单帧数据信噪比过低,难以恢复出高质量的图像,因此,在给定camera sensor的前提下,想要在超低照度成像,主要有两个思路,一是延长曝光时间,二是应用多帧信息。对于视频拍摄来说,延长曝光时间有两个弊端:(1) 难以满足要求的较高帧率;(2) 存在运动物体或者镜头移动的情况下,容易造成帧内模糊。因此,利用多帧信息来达到视频去噪和增强就成为一个重要的研究方向。
1. 算法简介
这篇论文提出了一种双向缓冲块(Bidirectional Buffer Block)作为BSVD的核心模块,可以利用过去帧和未来帧来预测当前帧,使得流程能够以pipe-line的形式达到实时推理。论文中给出了BSVD的推理时间以及图像恢复质量与其他SOTA算法的对比,如下面图示和表格:


2. 网络结构
BSVD的网络结构相对简单,就是两个UNet的级联,称为W-Net,如下图所示:

其中,每个UNet的结构如下:

其中,64是指输入层的输出channels数量,网络根据应用场景的不同,可以有不同的复杂度配置,如BSVD-32、BSVD-24和BSVD-16。
在上面架构表格中,每个Downsample Block和Upsample Block都有2个TSM或者BBB模块,一个UNet一共是8个,整个W-Net一共是16个TSM/BBB模块。TSM全称是Temporal Shift Module,是在训练阶段使用的。BBB就是我们前面提到的Bidirectional Buffer Block,是整个论文的核心,该模块在推理阶段会替换掉TSM模块,进行视频的pipeline推理。由于BBB模块的存在,视频推理过程中会消耗一定的缓存,并且有N帧的延迟(这里,N=16,是BBB模块的数量)。
3. Bidirectional Buffer Block的实现
下面示意图给出了BBB和TSM的实现差异。由于篇幅限制,这里先不对TSM进行过多介绍,想要深入了解TSM的同学可以参考论文《TSM: Temporal Shift Module for Efficient Video Understanding》。

这里,我们重点介绍BBB模块的结构和实现。每个BBB模块的实现如下图所示:
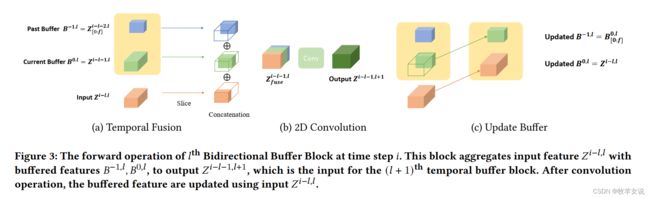
在每一层带BBB的卷积层中,当前输入首先和两个buffer中的数据进行级联,级联后进行卷积操作,卷积的输出作为下一层网络的输入。卷积之后,更新两个buffer的数据,简单来说,就是将当前输入缓存到B0,而原来B0中的数据缓存到B1。上面步骤可以提炼为三步:
(1) 将新输入feature与缓存features进行融合:

(2) 对融合后的数据做卷积,进行特征提取:
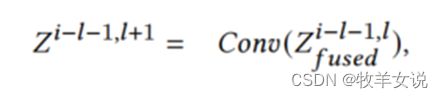
(3) 更新缓存数据:

以上过程实现的伪代码如下:

前面我们也提到,由于BBB的存在,整个pipeline的推理是有延迟的,具体会有N帧的延迟。

4. 推理时间和运行资源分析
(1)关于网络推理时间
FastDVDnet是基于滑窗的实现框架,也是两个UNet的级联,每个UNet输入层对3个带噪视频帧进行融合,因此,整体推理一帧的时间成本是单个UNet的3+1=4倍。与FastDVDnet每次送入网络多帧数据不同,BSVD每次只将一帧数据送入网络,因此计算成本是单UNet网络的1+1=2倍。从下表可以看到,BSVD-32相对于FastDVDnet,节省了50%以上的耗时。

(2) 关于缓存资源
在多帧框架如bidirectional-RNN和MIMO框架中,需要的缓存空间与输入的视频片段长度相关,在资源受限的计算平台进行推理时,需要将完整视频切分成多个短的视频序列,但这样的切分容易造成序列边界帧的推理质量下降。BSVD由于每次只输入一帧数据,且网络结构一旦固定,所需缓存的大小只与BBB模块的数量相关。
(3)时域感受野(Temporal receptive field)
经过前面的分析,我们知道单个BBB模块的时域感受野为2+1=3。论文中,将BBB模块的数量设置为16,因此,整个网络的感受野为16*2+1=33,这样的感受野大小明显大于滑窗方式的框架,也能更好地保证输出视频帧的图像质量。
5. 实践事项
具体在实践过程中,个人认为有几个地方需要特别关注。
(1)对于边界帧的处理
论文中对于边界帧的处理在A.2 Edges of the Stream段落已经提到。所谓边界帧,就是对一段视频序列的最前N-1帧和最后N-1帧的处理。前面的N-1帧(1≤i (2)RGB域去噪与Raw域去噪 BSVD网络支持RGB域的视频去噪和Raw域视频去噪。 对于RGB域去噪,输入channels数为3或4,分别实现盲去噪和非盲去噪。我们实际应用中,大部分会用盲去噪,因此在自己的实践中,基本上只会将R、G、B三个通道的数据输入到网络中。非盲去噪的情况下,除了输入RGB三通道,还需要输入noise map作为第四通道,来作为对去噪程度的控制参数。 如果是在camera前端的应用,那么大多会使用直接从sensor获取的Raw域数据进行去噪。Raw域去噪一般输入网络的channels数量为4或5,4为盲去噪,输入bayer域的RGGB四个通道数据,5为非盲去噪,除了RGGB四通道,也要输入一个通道的noise map。 下面是RGB非盲去噪的一个推理效果视频(取自测试集set8): original denoised