嵌入式实时操作系统原理(以μC/OS-III为例)
前言
本文重点讲述以μC/OS-III为例的RTOS内核关键部分的原理,大家耳熟能详的众多功能的实现,不做过多阐述,如信号量、互斥锁、消息队列等具体是如何实现的,大家可拉取源码,自行阅读。
github链接:https://github.com/weston-embedded/uC-OS3
1. 操作系统的概念
1.1 前后台系统与实时操作系统
1.1.1 前后台系统
传统的单片机开发,由于其资源受限或业务逻辑简单,往往不会运行操作系统(Operating System,即OS),而是采用前后台的方式处理业务逻辑。前后台的示意图如下:

如图所示,所有的任务都是平级的,它们在无限循环的后台(while(1)的大循环)中运行或者等待运行条件的到来,一个任务的运行必须等待上一个任务运行结束。
当然,单片机为了能够处理紧急的任务,设置了中断机制来处理紧急任务。我们把中断称为前台。
所以前台程序可以中断后台程序的运行,获得资源先运行起来,等中断任务处理结束后,再回到原来后台任务的断点处,继续运行。
但是由于中断本身要花费时间在断点的处理上面,大量使用中断会占用资源,浪费时间。可是,我们又希望有一个机制能够给予不同的任务等级之分,让紧急的程序能够先获得资源运行起来,而不是非要等到上一个程序运行结束。于是,机智的程序员们就开发出了实时操作系统。
1.1.2 实时操作系统
实时操作系统(Real Time Operating System,即RTOS)的开发是为了能够让某些具有时效性、实时性的任务可以优先获得资源运行起来。其特点就是让一些任务可以在一段指定的时间内完成。
实时操作系统是指所有任务都在规定时间内完成的操作系统,即必须满足时序可预测性(timing pre-dictability)。需要注意的是,实时系统并不是指反应很迅速的系统,而是指反应具有时序可预测性的系统。当然,在实际中,实时系统通常是反应很迅速的系统。但这是实时系统的一个结果,而不是其定义。
RTOS的示意图如下:
根据对时间的硬性要求,又可以将其分为软实时系统和硬实时系统。
1.2 硬实时、软实时及分时操作系统
1.2.1 硬实时操作系统
硬实时操作系统对任务的执行有严格的时间限制,不在某段时间内执行完毕会导致灾难性后果。比如,在导弹防御系统中,对来袭导弹的轨迹计算必须在规定时间内完成,否则就可能被来袭导弹击中而无法做出反应。
1.2.2 软实时操作系统
软实时操作系统在规定时间得不到响应所产生的后果是可以承受的,如流水装配线。即使装配线瘫痪,也只是损失了资金。
1.2.3 分时操作系统
实时操作系统之所以具有实时性,很重要的一个原因是因为其具有抢占式内核,一旦某个事件发生,其能在第一时间内响应该事件,并在规定时间内做出相应的处理。
如果一个操作系统是非抢占式的,一般采用公平调度算法,注重将系统资源平均地分配给各个应用,可以片面地理解为时间片轮转(实际上比较复杂),因此叫做分时操作系统。
实时操作系统对事件响应处理的时间一定具有确定性,而分时操作系统对此具有不确定性(并不是分时系统不够快或效率不够高)。
windows是分时操作系统。
1.3 操作系统的功能
- 处理器管理
- 中断管理
- CPU使用权的调度
- 存储管理
- 设备管理
- 文件管理
- 网络和通信管理
- 提供用户接口
2. RTOS内核原理
2.1 任务调度
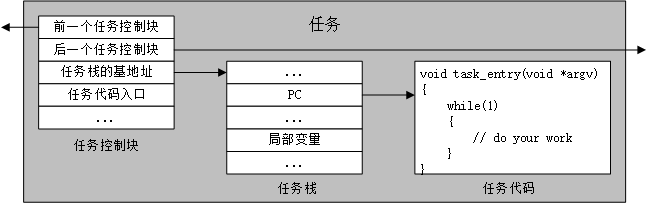
2.1.1 任务的构成
- 任务控制块
- 不同的任务控制块代表着不同的任务,即使任务控制块各成员的值完全相同
- 任务控制块的地址表征任务句柄
- 多个任务控制块构成双向链表
- 任务栈的基地址
- 任务代码入口地址
- 任务优先级
- …
- 任务栈
- 各类压栈的寄存器的值
- 局部变量
- 函数返回值
- 一般自顶向下生长(由处理器决定)
- …
- 任务代码
- 用户业务逻辑在此编写
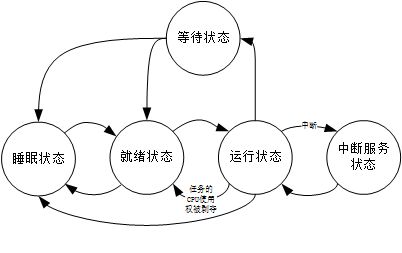
2.1.2 任务的状态
2.1.3 任务就绪列表
2.1.3.1 任务就绪列表的结构
μC/OS-III中维护着一个任务就绪列表,定义如下所示:
OS_EXT OS_RDY_LIST OSRdyList[OS_CFG_PRIO_MAX];
该表的数组以任务优先级作为索引,每一个元素记录着该优先级下的已就绪的任务控制块双向链表,任务控制块双向链表的示意图如下所示:

任务就绪列表的示意图如下所示:
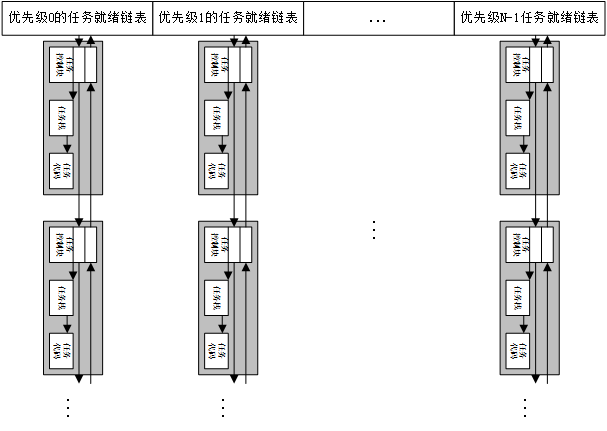
每当有任务就绪时,根据任务的优先级,将就绪任务的任务控制块添加到对应优先级的双向链表中。
2.1.3.2 就绪任务优先级位映射表
2.1.3.2.1 位映射表的定义
OSRdyList中记录着很多不同优先级的已就绪的任务,任务调度时,总是优先调度已就绪任务中优先级最高的任务。
如何查找这个已就绪的最高优先级呢?
一种可能的做法:
遍历OSRdyList的每一个元素(即就绪任务控制块的双向链表)的节点数,节点数不为0,说明该元素的下标即为我们期望的已就绪的最高优先级。
但是,这种做法效率太低,OS内核的一个基本原则是,最大限度减少其对CPU资源的占用,要求以最快的速度处理完内核的工作。
因此,μC/OS-III内核采取了设置和查询就绪任务优先级位映射表的方式。
内核维护了全局的位映射表:
CPU_DATA OSPrioTbl[OS_PRIO_TBL_SIZE];
32位宽的CPU下,CPU_DATA是uint32_t的类型,即OSPrioTbl是每个元素为32位整数的数组。
数组长度OS_PRIO_TBL_SIZE的定义如下:
#define OS_PRIO_TBL_SIZE (((OS_CFG_PRIO_MAX - 1u) / DEF_INT_CPU_NBR_BITS) + 1u)
OS_CFG_PRIO_MAX表示优先级的数目,最低优先级为OS_CFG_PRIO_MAX - 1。DEF_INT_CPU_NBR_BITS表示CPU的位宽,32位机对应值即为32。
假设内核配置的优先级为0-255,即OS_CFG_PRIO_MAX的值为256,则数组长度OS_PRIO_TBL_SIZE的值为8,数组的位大小为8*32=256。
![]()
换言之,数组OSPrioTbl的位宽等于优先级的总数向上按32位对齐的结果。
2.1.3.2.2位映射表的工作原理
1) 位映射表置位
在发送信号量、消息或释放锁(下文统称为内核对象)时,等待内核对象资源可用的任务应该被置为就绪态。
OS内核会从任务等待链表(下文详述)中查找出等待该内核对象的任务,将其从任务等待链表中摘除,添加到任务就绪列表中。
假设该就绪任务的优先级为prio,OS内核会根据优先级prio的数值大小,将数组OSPrioTbl中的某一位置1。
代码如下:
void OS_PrioInsert (OS_PRIO prio)
{
CPU_DATA bit;
CPU_DATA bit_nbr;
OS_PRIO ix;
ix = prio / DEF_INT_CPU_NBR_BITS;
bit_nbr = (CPU_DATA)prio & (DEF_INT_CPU_NBR_BITS - 1u);
bit = 1u;
bit <<= (DEF_INT_CPU_NBR_BITS - 1u) - bit_nbr;
OSPrioTbl[ix] |= bit;
}
ix等于优先级prio对32求模的结果,即要置1的位落在数组的哪个下标索引对应的32位范围内。假设prio值为34,则ix值为1,显然我们要将索引1对应的32-63范围内的某一位置1。bit_nbr等于优先级prio对32求余的结果。此处采用一个比较高效的处理方式,让其和32-1=31按位与,得到的就是预期的结果。此方法适用于某个整数对2的n次幂求余。prio值为34,则bit_nbr值为2。(是否就是要对OSPrioTbl[1]的位2(从0开始)置1呢?)bit等于1左移了(DEF_INT_CPU_NBR_BITS - 1u) - bit_nbr,即29位。OSPrioTbl[ix] |= bit表示将OSPrioTbl[1]的29位置1了,并没有将第2位置1。(正常的逻辑应是将低位的第3位,即位2置1,这里将高位的第3位,即位29置1)
2) 从位映射表查询最高优先级
代码如下:
OS_PRIO OS_PrioGetHighest (void)
{
CPU_DATA *p_tbl;
OS_PRIO prio;
prio = (OS_PRIO)0;
p_tbl = &OSPrioTbl[0]; /*取数组OSPrioTbl的首地址*/
while (*p_tbl == (CPU_DATA)0) { /*如果找到第一个不为0的元素(最高优先级的就绪任务在其中),退出循环*/
prio += DEF_INT_CPU_NBR_BITS; /*否则,每遍历一个元素,prio自加32(因为一个元素有32个优先级)*/
p_tbl++; /*遍历下一个元素*/
}
prio += (OS_PRIO)CPU_CntLeadZeros(*p_tbl);/*汇编或C实现:计算数据值中连续的最高有效前导零位的数量。*/
/*算出真正的优先级,prio += 连续的最高有效前导零位的数*/
return (prio);
}
根据此代码的注释,OSPrioTbl[1]的29位置1,推导出的优先级为32*1+2=34。
![]()
OS_PrioGetHighest函数的while循环中,只要找到第一个不为0的元素即可退出,因为其后被置位的任务,位数大,优先级低。本函数旨在找出就绪任务中的最高优先级。
3) 位映射表复位
当最高优先级的就绪任务获得CPU使用权,变为执行态时,需要将数组OSPrioTbl中相应的置位状态复位(清零)。
代码如下:
void OS_PrioRemove (OS_PRIO prio)
{
CPU_DATA bit;
CPU_DATA bit_nbr;
OS_PRIO ix;
ix = prio / DEF_INT_CPU_NBR_BITS;
bit_nbr = (CPU_DATA)prio & (DEF_INT_CPU_NBR_BITS - 1u);
bit = 1u;
bit <<= (DEF_INT_CPU_NBR_BITS - 1u) - bit_nbr;
OSPrioTbl[ix] &= ~bit;
}
该代码易于理解,不再赘述。
2.1.4 任务挂起列表
任务挂起列表不像任务就绪列表有一个全局数据,它是在用户创建出一个内核对象时,关联在内核对象的控制块中的。
以信号量的控制块为例:
struct os_sem {
OS_OBJ_TYPE Type;
CPU_CHAR *NamePtr;
OS_PEND_LIST PendList;
#if OS_CFG_DBG_EN > 0u
OS_SEM *DbgPrevPtr;
OS_SEM *DbgNextPtr;
CPU_CHAR *DbgNamePtr;
#endif
OS_SEM_CTR Ctr;
CPU_TS TS;
};
每创建出一个信号量,便会初始化一个与之关联的空的任务挂起列表OS_PEND_LIST PendList。
任务挂起列表的结构如下:
struct os_pend_data {
OS_PEND_DATA *PrevPtr;
OS_PEND_DATA *NextPtr;
OS_TCB *TCBPtr;
OS_PEND_OBJ *PendObjPtr;
OS_PEND_OBJ *RdyObjPtr;
void *RdyMsgPtr;
OS_MSG_SIZE RdyMsgSize;
CPU_TS RdyTS;
};
struct os_pend_list {
OS_PEND_DATA *HeadPtr;
OS_PEND_DATA *TailPtr;
OS_OBJ_QTY NbrEntries;
};
该列表是一个双向链表,链表的节点是OS_PEND_DATA类型的结构体,即struct os_pend_data。
因为μC/OS-III允许多个任务等待同一个信号量,所以任何一个等待同一信号量的任务在调用OSSemPend接口等待信号量时,如果信号量不可用,便会向任务挂起列表中插入一个节点,节点中包含了一个重要的参数,即当前任务的句柄OS_TCB *TCBPtr。
当有事件发生,向等待信号量的任务发送信号量时,会根据OSSemPost接口中指定的信号量找到其任务挂起列表,根据OSSemPost接口的opt参数,决定将任务挂起列表中最高优先级的任务设置为就绪态,还是将所有任务设置为就绪态。
这样就回到了任务就绪列表的处理。
2.1.5 任务的调度
2.1.5.1 任务调度的时机
- 任务级调度
用户任务发送信号量、等待信号量时资源不可用或主动释放CPU使用权时引起的任务调度。
μC/OS-III通过OSSched()来触发任务级的任务调度。
- 中断级调度
在中断产生(包括systick(OS的心跳节拍)中断)时,系统进入到中断服务状态。
当从中断服务状态退出时,并不会立即返回到被中断的任务,而是查找已就绪的最高优先级任务,并切换到该任务。
如果已就绪的最高优先级任务就是此前被中断的任务,则直接返回到被中断的任务。
μC/OS-III通过OSIntExit()来触发中断级的任务调度。
2.1.5.2 任务调度的方式
- 抢占式调度
不管是任务级的任务调度,还是中断级的任务调度,当高优先级任务就绪时,OS内核会回收当前任务的CPU使用权,并将其移交给更高优先级的就绪任务,使其得到运行。
看起来是OS作为中间人,从低优先级的一方夺取了资源,交给了高优先级的一方,不符合我们常规理解的高优先级主动抢占。但任务的切换就是由OS来调度的,脱离了OS,任务调度切换就不存在了。
从宏观上看,某个事件产生了,给等待信号量的高优先级任务发了一个信号,让其变成了就绪态,打断了低优先级任务的执行(在OS的帮助下),进入了执行态。这就是所谓的抢占式调度。
- 时间片轮转调度
时间片是指systick时钟的周期长度。
抢占式调度时针对不同优先级的任务的。具有相同优先级的多个任务之间,只能采用公平的时间片轮转算法了。
μC/OS-III允许每个任务运行规定的时间片(有用户设定每个任务的时间片数)。
每发生一次systick中断,当前任务的时间片数会自减1。
当任务没有用完分配给它的时间片时,它可以自愿地放弃CPU(调用OSSchedRoundRobinYield())。
下图是时间片轮转调度的示意图:
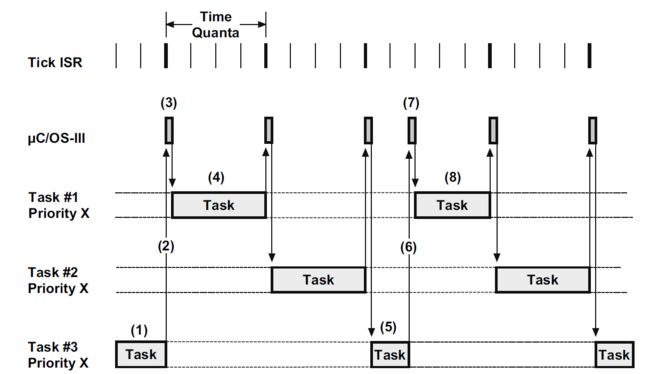
① 任务3正在执行,时间片尚未用尽。
② 任务3主动放弃剩余时间片(OS将该任务的时间片重设为4)。
③ OS暂停任务3,切换到任务1。
④ 任务1持续执行直到时间片用尽。
⑤ 任务3重新得到运行,时间片尚未用尽。
⑥ 任务3主动放弃剩余时间片(OS将该任务的时间片重设为4)。
⑦ OS暂停任务3,切换到任务1。
⑧ 任务1重新得到运行,时间片尚未用尽(将会主动放弃剩余时间片)。
参照任务就绪列表的示意图,优先级作为下标的数组元素,每个元素对应一个当前优先级下的任务控制块链表。
在时间片没有到期时,任何方式引起的任务调度都不会触发时间片轮转算法,即被切走的任务的控制块在链表中的顺序不变。
一旦在systick中断处理中发现当前被中断的任务的时间片为0时,就将它的任务控制块移动到对应链表的尾部。
下次具有该相同优先级的一系列任务获取到CPU的使用权时,该使用权便分配给了链表头部控制块对应的任务。
这样,具有相同优先级的任务,便获得了公平的调度。
在不支持时间片轮转调度的系统中,systick中断(即OS的心跳节拍)不是强需求,即使不打开该中断,也是可以完成任务调度(任务级)的。但是如果低优先级的任务中做了while(1)的操作,但是没有调用引起任务调度的系统接口时,除非来了其它的中断,否则整个系统将会卡死。这会给应用开发者造成不小的困扰,所以现代操作系统中全部支持systick中断。
2.1.5.3 任务调度的实现
- 任务级调度
// os_core.c
void OSSched (void)
{
CPU_SR_ALLOC();
/* ISRs still nested?*/
if (OSIntNestingCtr > (OS_NESTING_CTR)0) {
return; /* Yes ... only schedule when no nested ISRs */
}
/* Scheduler locked?*/
if (OSSchedLockNestingCtr > (OS_NESTING_CTR)0) {
return; /* Yes */
}
CPU_INT_DIS();
/* Find the highest priority ready */
OSPrioHighRdy = OS_PrioGetHighest();
OSTCBHighRdyPtr = OSRdyList[OSPrioHighRdy].HeadPtr;
/* Current task is still highest priority task? */
if (OSTCBHighRdyPtr == OSTCBCurPtr) {
CPU_INT_EN(); /* Yes ... no need to context switch */
return;
}
#if OS_CFG_TASK_PROFILE_EN > 0u
OSTCBHighRdyPtr->CtxSwCtr++; /* Inc. # of context switches to this task */
#endif
OSTaskCtxSwCtr++; /* Increment context switch counter */
#if defined(OS_CFG_TLS_TBL_SIZE) && (OS_CFG_TLS_TBL_SIZE > 0u)
OS_TLS_TaskSw();
#endif
/* Perform a task level context switch */
OS_TASK_SW();
CPU_INT_EN();
}
// os_cpu.h
#define OS_TASK_SW() NVIC_INT_CTRL = NVIC_PENDSVSET
- 中断级调度
// os_core.c
void OSIntEnter (void)
{
if (OSRunning != OS_STATE_OS_RUNNING) { /* Is OS running? */
return; /* No */
}
if (OSIntNestingCtr >= (OS_NESTING_CTR)250u) { /* Have we nested past 250 levels? */
return; /* Yes */
}
OSIntNestingCtr++; /* Increment ISR nesting level */
}
void OSIntExit (void)
{
CPU_SR_ALLOC();
if (OSRunning != OS_STATE_OS_RUNNING) { /* Has the OS started? */
return; /* No */
}
CPU_INT_DIS();
if (OSIntNestingCtr == (OS_NESTING_CTR)0) { /* Prevent OSIntNestingCtr from wrapping */
CPU_INT_EN();
return;
}
OSIntNestingCtr--;
if (OSIntNestingCtr > (OS_NESTING_CTR)0) { /* ISRs still nested? */
CPU_INT_EN(); /* Yes */
return;
}
if (OSSchedLockNestingCtr > (OS_NESTING_CTR)0) { /* Scheduler still locked? */
CPU_INT_EN(); /* Yes */
return;
}
OSPrioHighRdy = OS_PrioGetHighest(); /* Find highest priority */
OSTCBHighRdyPtr = OSRdyList[OSPrioHighRdy].HeadPtr; /* Get highest priority task ready-to-run */
if (OSTCBHighRdyPtr == OSTCBCurPtr) { /* Current task still the highest priority? */
CPU_INT_EN(); /* Yes */
return;
}
#if OS_CFG_TASK_PROFILE_EN > 0u
OSTCBHighRdyPtr->CtxSwCtr++; /* Inc. # of context switches for this new task */
#endif
OSTaskCtxSwCtr++; /* Keep track of the total number of ctx switches */
#if defined(OS_CFG_TLS_TBL_SIZE) && (OS_CFG_TLS_TBL_SIZE > 0u)
OS_TLS_TaskSw();
#endif
OSIntCtxSw(); /* Perform interrupt level ctx switch */
CPU_INT_EN();
}
// os_cpu.h
#define OSIntCtxSw() NVIC_INT_CTRL = NVIC_PENDSVSET
- 时间片轮转调度
void OS_SchedRoundRobin (OS_RDY_LIST *p_rdy_list)
{
OS_TCB *p_tcb;
CPU_SR_ALLOC();
if (OSSchedRoundRobinEn != DEF_TRUE) { /* Make sure round-robin has been enabled */
return;
}
CPU_CRITICAL_ENTER();
p_tcb = p_rdy_list->HeadPtr; /* Decrement time quanta counter */
if (p_tcb == (OS_TCB *)0) {
CPU_CRITICAL_EXIT();
return;
}
if (p_tcb == &OSIdleTaskTCB) {
CPU_CRITICAL_EXIT();
return;
}
if (p_tcb->TimeQuantaCtr > (OS_TICK)0) {
p_tcb->TimeQuantaCtr--;
}
if (p_tcb->TimeQuantaCtr > (OS_TICK)0) { /* Task not done with its time quanta*/
CPU_CRITICAL_EXIT();
return;
}
if (p_rdy_list->NbrEntries < (OS_OBJ_QTY)2) { /* See if it's time to time slice current task */
CPU_CRITICAL_EXIT(); /* ... only if multiple tasks at same priority */
return;
}
if (OSSchedLockNestingCtr > (OS_NESTING_CTR)0) {/* Can't round-robin if the scheduler is locked */
CPU_CRITICAL_EXIT();
return;
}
OS_RdyListMoveHeadToTail(p_rdy_list); /* Move current OS_TCB to the end of the list */
p_tcb = p_rdy_list->HeadPtr; /* Point to new OS_TCB at head of the list */
if (p_tcb->TimeQuanta == (OS_TICK)0) { /* See if we need to use the default time slice */
p_tcb->TimeQuantaCtr = OSSchedRoundRobinDfltTimeQuanta;
} else {
p_tcb->TimeQuantaCtr = p_tcb->TimeQuanta; /* Load time slice counter with new time */
}
CPU_CRITICAL_EXIT();
}
2.1.5.3 上下文切换
上文说到的任务级和中断级的实现代码中均提及到一个类似的宏定义:
#define OS_TASK_SW() NVIC_INT_CTRL = NVIC_PENDSVSET
#define OSIntCtxSw() NVIC_INT_CTRL = NVIC_PENDSVSET
这两个宏定义的实现内容一模一样,均是将嵌套向量中断控制器(NVIC)中的PendSV位置1,触发PendSV中断(可以理解为软中断)。OS内核用汇编代码实现了PendSV的中断处理函数,用于任务的上下文切换,即调度。
本节将从上下文切换原理、汇编代码实现、PendSV各方面进行讲述。
2.1.5.3.1 上下文切换原理
上下文切换的基本原理为:
① 将CPU的PC寄存器的值(当前任务的断点指针)保存到任务栈(一般硬件自动完成)。
② 将CPU通用寄存器的值保存到任务栈。
③ 将CPU的SP寄存器的值(被打断任务的栈指针)保存到该任务的任务控制块中。
④ 获得待运行任务的控制块。
⑤ 将待运行任务控制块中的栈指针恢复到CPU的SP寄存器中。
⑥ 将待运行任务栈中的通用寄存器值,恢复到CPU的通用寄存器中。
⑦ 将待运行任务的断点指针恢复到CPU的PC寄存器中(向PC中写入数据就会引起一次程序的分支,即跳转到了待运行任务上次的断点处继续执行)。
2.1.5.3.2 上下文切换代码实现
1) 双栈机制
Cortex-M系列的处理器,均具有双栈机制:
- 主栈指针(MSP),或写作SP_main。这是缺省的栈指针,它由OS内核、异常服务例程以及所有需要特权访问的应用程序代码来使用。
- 进程栈指针(PSP),或写作 SP_process。用于常规的应用程序代码(不处于异常服用例程中时)。
当引用 R13(或写作SP)时,你引用到的是当前正在使用的那一个,另一个必须用特殊的指令来访问(MRS,MSR指令)。
处理器复位后,默认进入特权级线程模式,使用MSP作为栈指针。
运行μC/OS系统后,应用线程使用PSP,内核代码和中断服务例程使用MSP。
2) 代码实现
① 在main函数中调用OSStart(),触发对汇编函数OSStartHighRdy()的调用,用以在操作系统初始化完成后启动第一次的任务调度(通过在OSStartHighRdy()中触发一次PendSV中断)。
② 第一次任务调度时,由于不需要保存上文,会由PendSV的汇编中断处理函数PendSV_Handler()直接跳转到汇编函数OS_CPU_PendSVHandler_nosave(),用以切换下文,以便切换到一个最高优先级的就绪任务中。
③ 后面每次发生任务调度时,都会触发一次PendSV中断,进行任务调度。由于已经不是第一次任务调度了,被中断了的任务的上文需要保存(保存现场),由PendSV_Handler()函数来完成。上文保存完毕后,退出中断。
需要注意的是:
OS_CPU_PendSVHandler_nosave()只会在OS启动时被调用一次,以后每次发生PendSV中断,仅会执行保存上文的操作,切换下文由PendSV中断退出后,CPU自动弹栈来完成。
OSStartHighRdy:
LDR R0, =NVIC_SYSPRI14 @ 将PendSV中断的优先级设置为最低(255)
LDR R1, =NVIC_PENDSV_PRI
STRB R1, [R0]
MOVS R0, #0 @ 将PSP的值设置为0
MSR PSP, R0
LDR R0, =OS_CPU_ExceptStkBase @ 将MSP的值设置为OS内核提供的内存空间OS_CPU_ExceptStkBase
LDR R1, [R0]
MSR MSP, R1
LDR R0, =NVIC_INT_CTRL @ 触发PendSV中断(引发任务调度)
LDR R1, =NVIC_PENDSVSET
STR R1, [R0]
CPSIE I @ 使能中断
PendSV_Handler:
@ 保存上文
CPSID I @ 关中断
MRS R0, PSP @ PSP寄存器的值放入R0寄存器
CBZ R0, OS_CPU_PendSVHandler_nosave @ R0为0则跳转至OS_CPU_PendSVHandler_nosave
SUBS R0, R0, #0x20 @ R0(栈指针)减小32,保存R4-R11寄存器的值至任务栈
STM R0, {R4-R11} @ 共8个寄存器,占用32字节
LDR R1, =OSTCBCurPtr @ OSTCBCurPtr的地址存入R1寄存器
LDR R1, [R1] @ OSTCBCurPtr所指向内容的前4个字节放入R1(实际就是任务控制块中的StkPtr变量,见下方注释中的图片)
STR R0, [R1] @ 将栈指针放入任务控制块中的StkPtr变量
OS_CPU_PendSVHandler_nosave:
@ 切换下文
PUSH {R14} @ 将LR寄存器压栈
LDR R0, =OSTaskSwHook @ 任务切换的钩子函数的地址送给R0
BLX R0 @ 跳转到任务切换的钩子函数
POP {R14} @ 压栈的LR内容弹栈,即下次返回到钩子函数调用前的位置,用于中断返回
LDR R0, =OSPrioCur @ 将OSPrioCur地址送给R0
LDR R1, =OSPrioHighRdy @ OSPrioHighRdy地址送给R1
LDRB R2, [R1] @ OSPrioHighRdy的低8位值送给R2(高24位清零,因为OSPrioHighRdy就是u8型的变量)
STRB R2, [R0] @ 将R2的低8位值送给OSPrioCur(高24位清零,因为OSPrioCur就是u8型的变量)
@ 该段代码等同于OSPrioCur = OSPrioHighRdy
LDR R0, =OSTCBCurPtr @ OSTCBCurPtr = OSTCBHighRdyPtr;
LDR R1, =OSTCBHighRdyPtr @ 和上面同理
LDR R2, [R1] @ 区别:
STR R2, [R0] @ OSTCBCurPtr和OSTCBHighRdyPtr是32位,不需要高24位清零,即不要用LDRB和STRB指令。
LDR R0, [R2] @ 已就绪任务控制块指针OSTCBHighRdyPtr指向的任务控制块中的前4个字节(StkPtr变量)送给R0,即R0是待运行任务的栈指针
LDM R0, {R4-R11} @ 从栈指针处开始弹栈到将CPU的R4-R11寄存器
ADDS R0, R0, #0x20 @ 栈指针增加32,因为共8个寄存器,占用32字节
MSR PSP, R0 @ 栈指针恢复到PSP寄存器中
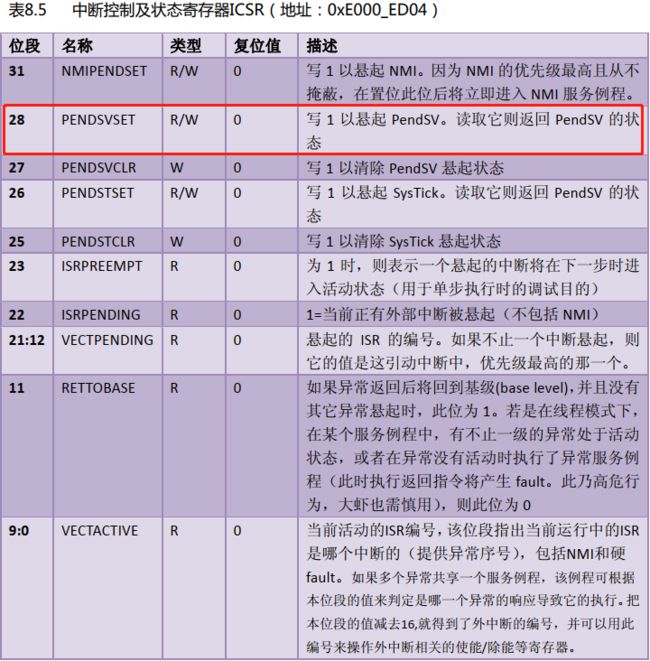
ORR LR, LR, #0x04 @ LR寄存器的值被重新解释,这里和0x04按位或,确保位2置1(参考下面的第3、4两张图)
CPSIE I @ 开中断
BX LR @ 中断返回
.end
任务控制块示意图:
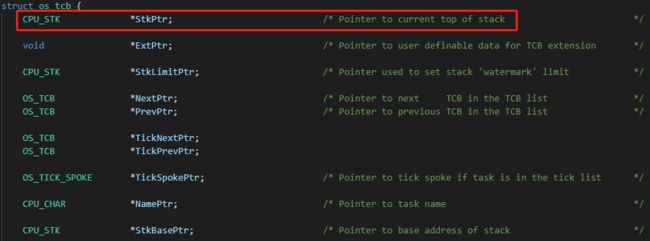



2.1.5.3.3 PendSV
PendSV称为可悬起系统调用。它是可以像普通的中断一样被悬起的(不像SVC那样会上访)。OS可以利用它“缓期执行”一个异常,直到其它重要的任务完成后才执行动作。悬起PendSV的方法是:手工往NVIC的PendSV悬起寄存器中写1。悬起后,如果优先级不够高,则将缓期等待执行。
假设有两个同等优先级的任务A和B,下图是两个任务间通过systick轮转调度的简单模式:
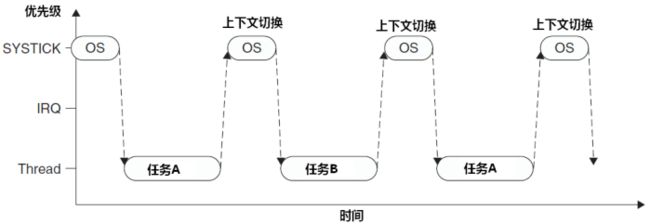
但若在产生systick异常时正在响应一个中断,且systick异常抢占了其ISR。在这种情况下,OS不得执行上下文切换,否则将使中断请求被延迟,而且在真实系统中延迟时间还往往不可预知,任何有一丁点实时要求的系统都决不能容忍这种事。如果OS在某中断活跃时尝试切入线程模式,将触犯用法fault异常(ARM内核也为OS的这个非法行为做了限制)。

为解决此问题,早期的OS大多会检测当前是否有中断在活跃中,只有没有任何中断需要响应时,才执行上下文切换(切换期间无法响应中断)。然而,这种方法的弊端在于,它可以把任务切换动作拖延很久(因为如果抢占了 IRQ,则本次systick在执行后不得作上下文切换,只能等待下一次systick异常),尤其是当某中断源的频率和systick异常的频率比较接近时,会发生“共振”。
现在好了,PendSV来完美解决这个问题了。PendSV异常会自动延迟上下文切换的请求,直到其它的ISR都完成了处理后才放行。为实现这个机制,需要把PendSV编程为最低优先级的异常。如果OS检测到某IRQ正在活动并且被systick抢占,它将悬起一个PendSV异常,以便缓期执行上下文切换。如下图所示:

总结下:PendSV中断就是一个可通过软件触发的中断,OS内核会将该中断优先级设置为最低,当需要任务调度时,会触发该中断。在任务级调度(没有中断产生时),PendSV中断是唯一的中断,可以立即响应,进行任务的上下文切换;在中断级调度时,PendSV中断是优先级最低的那个,会等其它中断执行完毕,而后再响应该中断,进行任务的上下文切换。
2.2 任务的优先级反转
下图展示了优先级反转的一种情况:
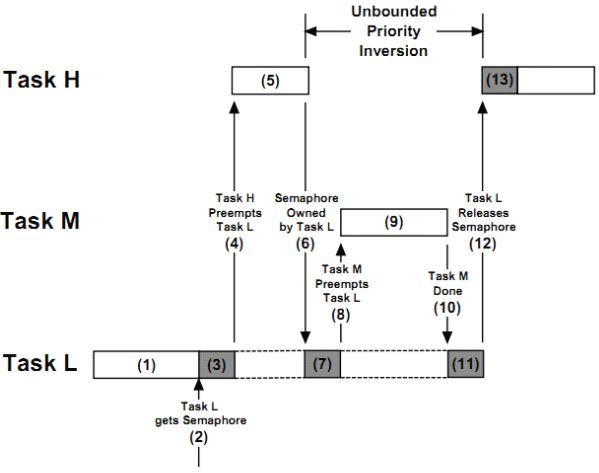
① 任务H和M都在等待事件的发生,任务L正在运行中
② 此时,任务L想获取信号量
③ 任务L访问共享资源,运行中
④ 任务H等待的事件发生了,任务L挂起
⑤ 任务H运行中
⑥ 任务H想要访问任务L所占用的共享资源,因为资源被任务L占用,任务H挂起,等待信号量被释放
⑦ 任务L恢复运行
⑧ 任务M等待的事件发生了,抢占了任务L的运行
⑨ 任务M运行中
⑩ 任务M运行完毕,CPU使用权交给了任务L
⑪ 任务L运行中
⑫ 任务L执行完毕并释放资源,任务H获得资源
⑬ 任务H运行中
以上流程可以看出,任务H在任务L后被执行,因为任务H等待任务L所占用的资源。麻烦在于任务M抢占任务L,若任务M需要执行很长时间,则任务H会被延迟很长时间才执行,这叫做优先级反转。
可以通过提升任务 L 的优先级解决这种问题(只在该任务访问共享资源时),访问结束后就恢复任务的优先级。任务L的优先级需要被上升到任务H的优先级。
μC/OS-III的互斥信号量mutex,就很好的解决了优先级反转的问题,下图展示了何通过mutex解决该问题的:
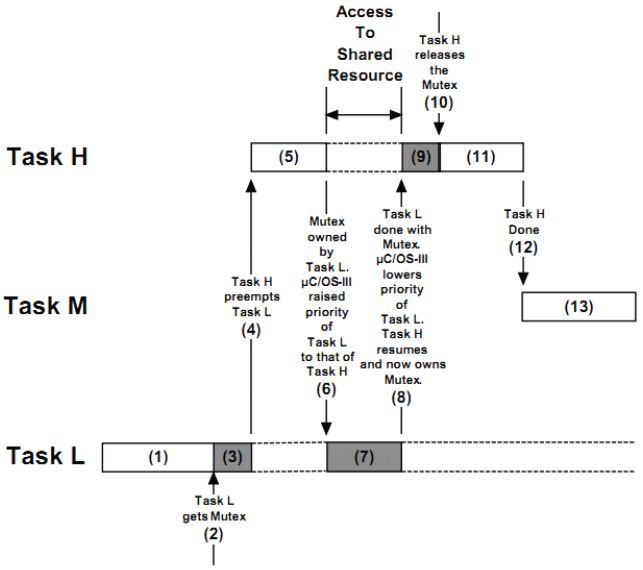
① 任务H和M都在等待事件的发生,任务L正在运行中
② 此时,任务L想获取mutex
③ 任务L访问共享资源,运行中
④ 任务H等待的事件发生了,任务L挂起
⑤ 任务H运行中
⑥ 任务H想要访问任务L所占用的共享资源,因为资源被任务L占用,任务H挂起。同时OS临时提升了任务L的优先级,使其和任务H的优先级相同。这样就防止了后面任务L被任务M抢占。
⑦ 任务L恢复运行
⑧ 任务L执行完毕,释放了共享资源,同时恢复到原有的优先级。此时任务M等待的事件发生了,任务M和H都处于就绪态,但是由于任务H的优先级最高,任务H将会得到运行。
⑨ 任务H运行中
⑩ 任务H对共享资源的访问完毕,释放了mutex。
⑪ 任务H继续运行
⑫ 任务H执行完毕,CPU使用权交给了早已就绪的任务M。
⑬ 任务M被执行
如此一来,流程⑧处,任务M不再优先于任务H执行,优先级反转问题得到解决。
同时也可以get一个技能:
多线程访问共享资源时,不要使用semaphore来互斥,必须使用mutex,以防止优先级反转。