集合详解(四)----HashSet和HashMap源码剖析(JDK1.7)
- HashSet
- HashMap
HashSet
当初始化一个HashSet的时候,HashSet的底层实现其实是HashMap:
private transient HashMap map;
public HashSet() {
map = new HashMap<>();
} 在每一个方法里面都是会通过map去调用HashMap的方法来实现。那么map是键值对类型的,那在HashSet中是怎么添加数据的呢?下面是HashSet中的添加方法。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}put的时候,e是要保存的key值,那后边的final变量呢是什么?
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();Dummy的意思就是‘虚假的’意思,也就是说当使用add方法将对象添加到Set当中时,实际上是将该对象作为底层所维护的Map对象的key,而value则都是同一个Object对象(该对象我们用不上)。
HashMap
HashMap在初始化的时候,会制定初始容量(16)和加载因子(扩容临界值0.75,意思就是当容量达到10*0.75=12的时候就会扩容):
//默认初始化化容量,即16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//默认装载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap(int initialCapacity, float loadFactor) {//可手动设置初始容量和装载因子的构造器
if (initialCapacity < 0) //参数有效性检查
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY) //参数有效性检查
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor)) //参数有效性检查
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// Find a power of 2 >= initialCapacity
//找出“大于initialCapacity”的最小的2的幂
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//初始化桶数组
table = new Entry[capacity];
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();//一个钩子函数,默认实现是空
}
//通过扩容因子构造HashMap,容量去默认值,即16
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//使用默认的初始容量和默认的加载因子构造HashMap
public HashMap() {
//制定初始容量和加载因子
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
//通过其他Map来初始化HashMap,容量通过其他Map的size来计算,装载因子取0.75
public HashMap(Map m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);//初始化HashMap底层的数组结构
putAllForCreate(m);//添加m中的元素
} 在HashMap的内部通过Entry数组来保存键值对,那个这个Entry是怎么实现的呢?
static class Entry implements Map.Entry {//实现Map.Entry接口
final K key;//键,final类型,不可更改/
V value;//值
Entry next;//HashMap通过链表法解决冲突,这里的next指向链表的下一个元素
int hash;//hash值
/**
* Creates new entry.
*/
//构造器需指定链表的下一个结点,所有冲突结点放到一个链表上
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
//允许设置value
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
//保证键值都相等
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {//键为空则hash值为0,否则通过通过hashcode计算
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap m) {
}
} HashMap内部数组存储的是键值对,也就是Entry对象,Entry对象保存了键、值,并持有一个next指针指向下一个Entry对象(HashMap通过链表法解决冲突):
我们都知道HashMap是通过数组来存储的,那如何通过链表法来解决冲突的呢?举个栗子,定义一个HashMap,当调用put的时候,会根据key的hashCode值计算出一个位置,也就是要存储在数组中的位置,如果这个位置没有对象,就将该对象直接放进数组中:
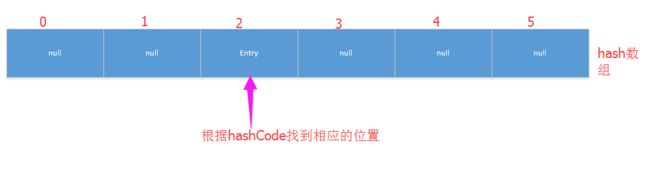
如果该位置已经有对象了,则顺着此存在的对象的链开始寻找(Entry类有一个Entry类型的next成员变量,指向了该对象的下一个对象):
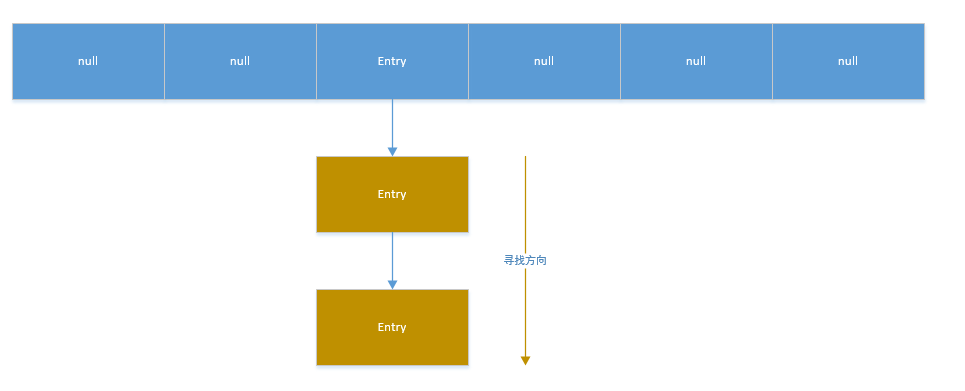
如果此链上有对象的话,就去使用equals方法进行比较,如果对此链上某个对象的equals方法比较为false,就把改对象放到数组中,将数组中该位置以前存在的那个对象链接到次对象的后面。
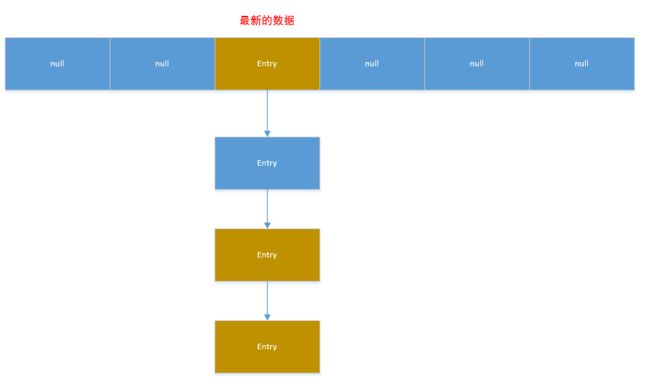
HashMap存值的时候,遵循的是LRU(Least Recently Used)算法,就是最近最少使用,意思就是系统认为最近使用的值可能会被系统经常用到,而添加的早的值用到的几率会小。
着重的说一说HashMap核心的东西,就是HashMap在存数据的时候,也就是当你进行put操作的时候,HashMap是如何来进行存的。
//添加元素
public V put(K key, V value) {
if (table == EMPTY_TABLE) {//如果底层表为空,则初始化
inflateTable(threshold);
}
if (key == null)//如果key为空,则执行空的逻辑
return putForNullKey(value);
int hash = hash(key);//获取key的Hash值
int i = indexFor(hash, table.length);//定位Hash桶
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);//调用value的回调函数,其实这个函数也为空实现
return oldValue;
}
}
modCount++;//更新修改次数
addEntry(hash, key, value, i);//添加到对应Hash桶的链接表中
return null;
}
//添加key为空的元素,key为null的元素添加到第0号Hash桶中
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {//判断元素
V oldValue = e.value;//如果已经存在,修改值
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//更新修改次数
addEntry(0, null, value, 0);//执行链表插入
return null;
} 不允许两个键相同,如果相同,则后插入的键所对应的值会覆盖掉之前的值。
HashMap是通过调用hash()方法获得键的hash值,并通过indexFor方法找到实际插入位置,具体的代码如下:
final int hash(Object k) {//根据键生成hash值
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//根据hash值计算键在桶数组的位置
static int indexFor(int h, int length) {
return h & (length-1);//由put方法可知,这个length就是数组长度,而且由构造器发现数组长度始终为2的整数次方,那么这个&操作实际上就是是h%length的高效表示方式,可以使结果小于数组长度.
} put方法通过addEntry方法将键值插入到合适的位置,当容量查过阈值(threshold)时,会发生扩容,扩容一倍。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {//容量超过阈值
resize(2 * table.length);//数组扩容为原来的两倍
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];//获取原来在该位置上的Entry对象
table[bucketIndex] = new Entry<>(hash, key, value, e);//将当前的键值插到该位置,并作为链表的起始结点。其next指针指向先前的Entry
size++;
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];//创建新数组
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);//将原数组中所有键值对转移至新数组
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {//需遍历每个Entry,耗时
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
} 扩容操作需要开辟新数组,并对原数组中所有键值对重新散列,非常耗时。我们应该尽量避免HashMap扩容。