【Spark ML】第 5 章:Recommendations
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
推荐引擎的类型
使用交替最小二乘法的协同滤波
参数
例子
Market Basket分析与FP-Growth
例子
基于内容的过滤
总结
提供个性化推荐是机器学习最受欢迎的应用之一。几乎每个主要零售商,如亚马逊,阿里巴巴,沃尔玛和Target,都会根据客户行为提供某种个性化推荐。Netflix,Hulu和Spotify等流媒体服务根据用户的口味和偏好提供电影或音乐推荐。
建议对于提高客户满意度和参与度至关重要,最终增加销售额和收入。为了强调推荐的重要性,44%的亚马逊买家从他们在亚马逊上看到的产品推荐中购买。第二麦肯锡的一份报告发现,35%的客户销售额直接来自亚马逊的推荐。同一项研究报告称,75%的观众在Netflix上观看的内容来自个性化推荐。第三Netflix的首席产品官在接受采访时宣称,Netflix的个性化电影和电视节目推荐每年对该公司的价值为10亿美元。四阿里巴巴的推荐引擎帮助推动了创纪录的销售,成为全球最大的电子商务公司之一,2013年的销售额达到2480亿美元(超过亚马逊和eBay的总和)。v
推荐不仅限于零售商和流媒体服务。银行使用推荐引擎作为有针对性的营销工具,使用它来为在线银行客户提供金融产品和服务,例如基于其人口统计和心理特征的家庭或学生贷款。广告和营销机构使用推荐引擎来显示高度针对性的在线广告。
推荐引擎的类型
有几种类型的推荐引擎。六我们将讨论最流行的:协作过滤、基于内容的过滤和关联规则。
使用交替最小二乘法的协同滤波
协作筛选通常用于在 Web 上提供个性化建议。利用协同过滤的公司包括Netflix,亚马逊,阿里巴巴,Spotify和苹果,仅举几例。协作筛选根据其他人(协作)的偏好或品味提供建议(筛选)。它基于这样一种想法,即具有相同偏好的人将来更有可能拥有相同的兴趣。例如,劳拉喜欢泰坦尼克号,阿波罗13号和高耸的地狱。汤姆喜欢阿波罗13号和高耸的地狱。如果安妮喜欢阿波罗13号,根据我们的计算,任何喜欢阿波罗13号的人也必须喜欢《高耸的地狱》,那么《高耸的地狱》可能是对安妮的潜在推荐。产品可以是任何项目,例如电影、歌曲、视频或书籍。
图 5-1原子层沉积液评级矩阵
火花 MLlib 包括一种用于协同过滤的流行算法,称为交替最小二乘法 (ALS)。ALS 将评级矩阵(图 5-1)建模为用户和产品因素的乘积(图 5-2)。ALS利用最小二乘计算来最小化估计误差,在固定客户因素和求解产品因素之间交替迭代,反之亦然,直到过程收敛。Spark MLlib 实现了一个阻塞版本的 ALS,该版本利用 Spark 的分布式处理功能,将两组因子(称为“用户”和“产品”)分组为块,并通过在每次迭代时仅向每个产品块发送每个用户向量的一个副本来减少通信,并且仅用于需要该用户特征向量的产品块。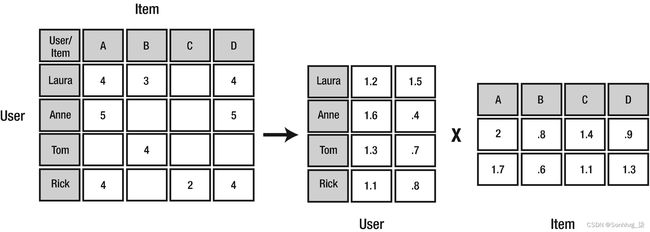
图 5-2ALS 如何计算建议
星火 MLlib 的 ALS 实现同时支持显式和隐式评级。显式分级(默认)要求用户对产品的分级为分数(例如,1-5 竖起大拇指),而隐式分级表示用户对与产品互动的信心(例如,点击次数或页面浏览次数,或视频流式传输的次数)。隐式评级在现实生活中更为常见,因为并非每家公司都为其产品收集明确的评级。但是,可以从公司数据(如 Web 日志、查看习惯或销售交易)中提取隐式评级。Spark MLlib 的 ALS 实现对项目和用户 ID 使用整数,这意味着项目和用户 ID 必须在整数值的范围内,最大值为 2,147,483,647。
注意交替最小二乘法(ALS)在耶胡达·科伦和罗伯特·贝尔的论文“具有联合派生的邻域插值权重的可扩展协同滤波”中进行了描述。
参数
Spark MLlib 的 ALS 实现支持以下参数:
- alpha:适用于 ALS 的隐式反馈版本,该版本指导优先观察的基线置信度
- numBlocks:用于并行处理的 U sed;项目和用户将被划分为的块数
- nonnegative:指示是否对最小二乘法使用非负约束
- implicitPrefs:指示是使用显式反馈还是隐式反馈
- k:指示模型中潜在因子的数量
- regParam:正则化参数
- maxIter:指示要执行的最大迭代次数。
例子
我们将使用电影缩略图数据集来构建玩具电影推荐系统。数据集可以从 https://grouplens.org/datasets/movielens/ 下载。数据集中包含多个文件,但我们主要对评级.csv感兴趣。清单 5-1 所示文件中的每一行都包含用户对电影的显式评级(1-5 评级)。
val dataDF = spark.read.option("header", "true")
.option("inferSchema", "true")
.csv("ratings.csv")
dataDF.printSchema
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- rating: double (nullable = true)
|-- timestamp: integer (nullable = true)
dataDF.show
+------+-------+------+---------+
|userId|movieId|rating|timestamp|
+------+-------+------+---------+
| 1| 1| 4.0|964982703|
| 1| 3| 4.0|964981247|
| 1| 6| 4.0|964982224|
| 1| 47| 5.0|964983815|
| 1| 50| 5.0|964982931|
| 1| 70| 3.0|964982400|
| 1| 101| 5.0|964980868|
| 1| 110| 4.0|964982176|
| 1| 151| 5.0|964984041|
| 1| 157| 5.0|964984100|
| 1| 163| 5.0|964983650|
| 1| 216| 5.0|964981208|
| 1| 223| 3.0|964980985|
| 1| 231| 5.0|964981179|
| 1| 235| 4.0|964980908|
| 1| 260| 5.0|964981680|
| 1| 296| 3.0|964982967|
| 1| 316| 3.0|964982310|
| 1| 333| 5.0|964981179|
| 1| 349| 4.0|964982563|
+------+-------+------+---------+
only showing top 20 rows
val Array(trainingData, testData) = dataDF.randomSplit(Array(0.7, 0.3))
import org.apache.spark.ml.recommendation.ALS
val als = new ALS()
.setMaxIter(15)
.setRank(10)
.setSeed(1234)
.setRatingCol("rating")
.setUserCol("userId")
.setItemCol("movieId")
val model = als.fit(trainingData)
val predictions = model.transform(testData)
predictions.printSchema
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- rating: double (nullable = true)
|-- timestamp: integer (nullable = true)
|-- prediction: float (nullable = false)
predictions.show
+------+-------+------+----------+----------+
|userId|movieId|rating| timestamp|prediction|
+------+-------+------+----------+----------+
| 133| 471| 4.0| 843491793| 2.5253267|
| 602| 471| 4.0| 840876085| 3.2802277|
| 182| 471| 4.5|1054779644| 3.6534667|
| 500| 471| 1.0|1005528017| 3.5033386|
| 387| 471| 3.0|1139047519| 2.6689813|
| 610| 471| 4.0|1479544381| 3.006948|
| 136| 471| 4.0| 832450058| 3.1404104|
| 312| 471| 4.0|1043175564| 3.109232|
| 287| 471| 4.5|1110231536| 2.9776838|
| 32| 471| 3.0| 856737165| 3.5183017|
| 469| 471| 5.0| 965425364| 2.8298397|
| 608| 471| 1.5|1117161794| 3.007364|
| 373| 471| 5.0| 846830388| 3.9275675|
| 191| 496| 5.0| 829760898| NaN|
| 44| 833| 2.0| 869252237| 2.4776468|
| 609| 833| 3.0| 847221080| 1.9167987|
| 608| 833| 0.5|1117506344| 2.220617|
| 463| 1088| 3.5|1145460096| 3.0794377|
| 47| 1088| 4.0|1496205519| 2.4831696|
| 479| 1088| 4.0|1039362157| 3.5400867|
+------+-------+------+----------+----------+
import org.apache.spark.ml.evaluation.RegressionEvaluator
val evaluator = new RegressionEvaluator()
.setPredictionCol("prediction")
.setLabelCol("rating")
.setMetricName("rmse")
val rmse = evaluator.evaluate(predictions)
rmse: Double = NaN列出 5-1使用 ALS 的电影推荐
评估器似乎不喜欢预测数据帧中的 NaN 值。现在,让我们通过删除具有 NaN 值的行来修复它。我们稍后将讨论如何使用冷启动策略参数来处理此问题。
val predictions2 = predictions.na.drop
predictions2.show
+------+-------+------+----------+----------+
|userId|movieId|rating| timestamp|prediction|
+------+-------+------+----------+----------+
| 133| 471| 4.0| 843491793| 2.5253267|
| 602| 471| 4.0| 840876085| 3.2802277|
| 182| 471| 4.5|1054779644| 3.6534667|
| 500| 471| 1.0|1005528017| 3.5033386|
| 387| 471| 3.0|1139047519| 2.6689813|
| 610| 471| 4.0|1479544381| 3.006948|
| 136| 471| 4.0| 832450058| 3.1404104|
| 312| 471| 4.0|1043175564| 3.109232|
| 287| 471| 4.5|1110231536| 2.9776838|
| 32| 471| 3.0| 856737165| 3.5183017|
| 469| 471| 5.0| 965425364| 2.8298397|
| 608| 471| 1.5|1117161794| 3.007364|
| 373| 471| 5.0| 846830388| 3.9275675|
| 44| 833| 2.0| 869252237| 2.4776468|
| 609| 833| 3.0| 847221080| 1.9167987|
| 608| 833| 0.5|1117506344| 2.220617|
| 463| 1088| 3.5|1145460096| 3.0794377|
| 47| 1088| 4.0|1496205519| 2.4831696|
| 479| 1088| 4.0|1039362157| 3.5400867|
| 554| 1088| 5.0| 944900489| 3.3577442|
+------+-------+------+----------+----------+
only showing top 20 rows
val evaluator = new RegressionEvaluator()
.setPredictionCol("prediction")
.setLabelCol("rating")
.setMetricName("rmse")
val rmse = evaluator.evaluate(predictions2)
rmse: Double = 0.9006479893684061注意使用 ALS 时,您有时会遇到测试数据集中在训练模型时不存在的用户和/或项。新用户或项目可能没有任何评级,并且尚未对其进行模型训练。这称为冷启动问题。当数据在评估数据集和训练数据集之间随机拆分时,也可能会遇到这种情况。当用户和/或项目不在模型中时,预测设置为 NaN。这就是我们在评估模型时遇到NaN结果的原因。为了解决这个问题,Spark 提供了一个冷启动策略参数,可以将该参数设置为删除预测数据帧中包含 NaN 值的所有行。
让我们生成一些建议。
为所有用户推荐前三部电影。
model.recommendForAllUsers(3).show(false)
+------+----------------------------------------------------------+
|userId|recommendations |
+------+----------------------------------------------------------+
|471 |[[7008, 4.8596725], [7767, 4.8047066], [26810, 4.7513227]]|
|463 |[[33649, 5.0881286], [3347, 4.7693057], [68945, 4.691733]]|
|496 |[[6380, 4.946864], [26171, 4.8910613], [7767, 4.868356]] |
|148 |[[183897, 4.972257], [6732, 4.561547], [33649, 4.5440807]]|
|540 |[[26133, 5.19643], [68945, 5.1259947], [3379, 5.1259947]] |
|392 |[[3030, 6.040107], [4794, 5.6566052], [55363, 5.4429026]] |
|243 |[[1223, 6.5019746], [68945, 6.353135], [3379, 6.353135]] |
|31 |[[4256, 5.3734074], [49347, 5.365612], [7071, 5.3175936]] |
|516 |[[4429, 4.8486495], [48322, 4.8443394], [28, 4.8082485]] |
|580 |[[86347, 5.20571], [4256, 5.0522637], [72171, 5.037114]] |
|251 |[[33649, 5.6993585], [68945, 5.613014], [3379, 5.613014]] |
|451 |[[68945, 5.392536], [3379, 5.392536], [905, 5.336588]] |
|85 |[[25771, 5.2532864], [8477, 5.186757], [99764, 5.1611686]]|
|137 |[[7008, 4.8952146], [26131, 4.8543305], [3200, 4.6918836]]|
|65 |[[33649, 4.695069], [3347, 4.5379376], [7071, 4.535537]] |
|458 |[[3404, 5.7415047], [7018, 5.390625], [42730, 5.343014]] |
|481 |[[232, 4.393473], [3473, 4.3804317], [26133, 4.357505]] |
|53 |[[3200, 6.5110188], [33649, 6.4942613], [3347, 6.452143]] |
|255 |[[86377, 5.9217377], [5047, 5.184309], [6625, 4.962062]] |
|588 |[[26133, 4.7600465], [6666, 4.65716], [39444, 4.613207]] |
+------+----------------------------------------------------------+
only showing top 20 rows
//为所有电影推荐前三名用户。
model.recommendForAllItems(3).show(false)
+-------+------------------------------------------------------+
|movieId|recommendations |
+-------+------------------------------------------------------+
|1580 |[[53, 4.939177], [543, 4.8362885], [452, 4.5791063]] |
|4900 |[[147, 3.0081954], [375, 2.9420073], [377, 2.6285374]]|
|5300 |[[53, 4.29147], [171, 4.129584], [375, 4.1011653]] |
|6620 |[[392, 5.0614614], [191, 4.820595], [547, 4.7811346]] |
|7340 |[[413, 3.2256641], [578, 3.1126869], [90, 3.0790782]] |
|32460 |[[53, 5.642673], [12, 5.5260286], [371, 5.2030106]] |
|54190 |[[53, 5.544555], [243, 5.486003], [544, 5.243029]] |
|471 |[[51, 5.073474], [53, 4.8641024], [337, 4.656805]] |
|1591 |[[112, 4.250576], [335, 4.147236], [207, 4.05843]] |
|140541 |[[393, 4.4335465], [536, 4.1968756], [388, 4.0388694]]|
|1342 |[[375, 4.3189483], [313, 3.663758], [53, 3.5866988]] |
|2122 |[[375, 4.3286233], [147, 4.3245177], [112, 3.8350344]]|
|2142 |[[51, 3.9718416], [375, 3.8228302], [122, 3.8117828]] |
|7982 |[[191, 5.297085], [547, 5.020829], [187, 4.984965]] |
|44022 |[[12, 4.5919843], [53, 4.501897], [523, 4.301981]] |
|141422 |[[456, 2.7050805], [597, 2.6988854], [498, 2.6347125]]|
|833 |[[53, 3.8047972], [543, 3.740805], [12, 3.6920836]] |
|5803 |[[537, 3.8269677], [544, 3.8034997], [259, 3.76062]] |
|7993 |[[375, 2.93635], [53, 2.9159238], [191, 2.8663528]] |
|160563 |[[53, 4.048704], [243, 3.9232922], [337, 3.7616432]] |
+-------+------------------------------------------------------+
only showing top 20 rows
//为指定的一组电影生成前三个用户推荐。
model.recommendForItemSubset(Seq((111), (202), (225), (347), (488)).toDF("movieId"), 3).show(false)
+-------+----------------------------------------------------+
|movieId|recommendations |
+-------+----------------------------------------------------+
|225 |[[53, 4.4893017], [147, 4.483344], [276, 4.2529426]]|
|111 |[[375, 5.113064], [53, 4.9947076], [236, 4.9493203]]|
|347 |[[191, 4.686208], [236, 4.51165], [40, 4.409832]] |
|202 |[[53, 3.349618], [578, 3.255436], [224, 3.245058]] |
|488 |[[558, 3.3870435], [99, 3.2978806], [12, 3.2749753]]|
+-------+----------------------------------------------------+
//为一组指定的用户生成前三大电影推荐。
model.recommendForUserSubset(Seq((111), (100), (110), (120), (130)).toDF("userId"), 3).show(false)
+------+--------------------------------------------------------------+
|userId|recommendations |
+------+--------------------------------------------------------------+
|111 |[[106100, 4.956068], [128914, 4.9050474], [162344, 4.9050474]]|
|120 |[[26865, 4.979374], [3508, 4.6825113], [3200, 4.6406555]] |
|100 |[[42730, 5.2531567], [5867, 5.1075697], [3404, 5.0877166]] |
|130 |[[86377, 5.224841], [3525, 5.0586476], [92535, 4.9758487]] |
|110 |[[49932, 4.6330786], [7767, 4.600622], [26171, 4.5615706]] |
+------+--------------------------------------------------------------+协同过滤可以非常有效地提供高度相关的建议。它可以很好地扩展,并且可以处理非常大的数据集。为了使协同过滤以最佳方式运行,它需要访问大量数据。数据越多越好。随着时间的流逝和评级开始累积,建议变得越来越准确。在实施的早期阶段,访问大型数据集通常是一个问题。一种解决方案是将基于内容的筛选与协作筛选结合使用。由于基于内容的筛选不依赖于用户活动,因此它可以立即开始提供建议,从而随着时间的推移逐渐增加数据集。
Market Basket分析与FP-Growth
Market Basket分析是零售商常用的一种简单但重要的技术,用于提供产品建议。它使用事务数据集来确定哪些产品经常一起购买。零售商可以使用这些建议来为个性化的交叉销售和追加销售提供信息,从而帮助提高转化率并最大限度地提高每个客户的价值。
在浏览 Amazon.com 时,您很可能已经看到了市场篮分析的实际应用。Amazon.com 产品页面通常会有一个名为“购买此商品的客户也购买了”的部分,向您显示经常与您当前正在浏览的产品一起购买的商品列表。该列表是通过市场篮分析生成的。实体零售商还使用市场篮分析,通过在货架图中通知产品放置和邻接来优化商店。这个想法是通过将互补项目彼此相邻来推动更多销售。
市场篮分析使用关联规则学习来提出建议。关联规则使用大型事务数据集查找项之间的关系。关联规则是根据两个或多个称为项集的项计算得出的。关联规则由前置(如果)和后置(则)组成。例如,如果有人购买饼干(前因),那么这个人也更有可能购买牛奶(随后)。流行的关联规则算法包括先验、SETM、怡亨和FP增长。Spark MLlib 包括一个高度可扩展的 FP 增长实现,用于关联规则挖掘。十五FP-Growth使用频繁模式(“FP”代表频繁模式)树结构识别频繁项目并计算项目频率。
注意FP-Growth在韩佳伟、裴健和尹雯文的论文《挖掘没有候选世代的频繁模式》中有所描述。
例子
我们将使用流行的Instacart在线杂货购物数据集作为我们使用FP-Growth的市场篮分析示例。十八该数据集包含来自 200,000 名 Instacart 客户的 50,000 种产品的 340 万份杂货订单。可以从 www.instacart.com/datasets/grocery-shopping-2017 下载数据集。对于 FP-Growth,我们只需要产品和order_products_train表(参见清单 5-2)。
val productsDF = spark.read.format("csv")
.option("header", "true")
.option("inferSchema","true")
.load("/instacart/products.csv")
ProductsDF.show(false)
+----------+-------------------------------------------------+
|product_id|product_name |
+----------+-------------------------------------------------+
|1 |Chocolate Sandwich Cookies |
|2 |All-Seasons Salt |
|3 |Robust Golden Unsweetened Oolong Tea |
|4 |Smart Ones Classic Favorites Mini Rigatoni With |
|5 |Green Chile Anytime Sauce |
|6 |Dry Nose Oil |
|7 |Pure Coconut Water With Orange |
|8 |Cut Russet Potatoes Steam N' Mash |
|9 |Light Strawberry Blueberry Yogurt |
|10 |Sparkling Orange Juice & Prickly Pear Beverage |
|11 |Peach Mango Juice |
|12 |Chocolate Fudge Layer Cake |
|13 |Saline Nasal Mist |
|14 |Fresh Scent Dishwasher Cleaner |
|15 |Overnight Diapers Size 6 |
|16 |Mint Chocolate Flavored Syrup |
|17 |Rendered Duck Fat |
|18 |Pizza for One Suprema Frozen Pizza |
|19 |Gluten Free Quinoa Three Cheese & Mushroom Blend |
|20 |Pomegranate Cranberry & Aloe Vera Enrich Drink |
+----------+-------------------------------------------------+
+--------+-------------+
|aisle_id|department_id|
+--------+-------------+
|61 |19 |
|104 |13 |
|94 |7 |
|38 |1 |
|5 |13 |
|11 |11 |
|98 |7 |
|116 |1 |
|120 |16 |
|115 |7 |
|31 |7 |
|119 |1 |
|11 |11 |
|74 |17 |
|56 |18 |
|103 |19 |
|35 |12 |
|79 |1 |
|63 |9 |
|98 |7 |
+--------+-------------+
only showing top 20 rows
val orderProductsDF = spark.read.format("csv")
.option("header", "true")
.option("inferSchema","true")
.load("/instacart/order_products__train.csv")
orderProductsDF.show()
+--------+----------+-----------------+---------+
|order_id|product_id|add_to_cart_order|reordered|
+--------+----------+-----------------+---------+
| 1| 49302| 1| 1|
| 1| 11109| 2| 1|
| 1| 10246| 3| 0|
| 1| 49683| 4| 0|
| 1| 43633| 5| 1|
| 1| 13176| 6| 0|
| 1| 47209| 7| 0|
| 1| 22035| 8| 1|
| 36| 39612| 1| 0|
| 36| 19660| 2| 1|
| 36| 49235| 3| 0|
| 36| 43086| 4| 1|
| 36| 46620| 5| 1|
| 36| 34497| 6| 1|
| 36| 48679| 7| 1|
| 36| 46979| 8| 1|
| 38| 11913| 1| 0|
| 38| 18159| 2| 0|
| 38| 4461| 3| 0|
| 38| 21616| 4| 1|
+--------+----------+-----------------+---------+
only showing top 20 rows
// Create temporary tables .
orderProductsDF.createOrReplaceTempView("order_products_train")
productsDF.createOrReplaceTempView("products")
val joinedData = spark.sql("select p.product_name, o.order_id from order_products_train o inner join products p where p.product_id = o.product_id")
import org.apache.spark.sql.functions.max
import org.apache.spark.sql.functions.collect_set
val basketsDF = joinedData
.groupBy("order_id")
.agg(collect_set("product_name")
.alias("items"))
basketsDF.createOrReplaceTempView("baskets"
basketsDF.show(20,55)
+--------+-------------------------------------------------------+
|order_id| items|
+--------+-------------------------------------------------------+
| 1342|[Raw Shrimp, Seedless Cucumbers, Versatile Stain Rem...|
| 1591|[Cracked Wheat, Strawberry Rhubarb Yoghurt, Organic ...|
| 4519|[Beet Apple Carrot Lemon Ginger Organic Cold Pressed...|
| 4935| [Vodka]|
| 6357|[Globe Eggplant, Panko Bread Crumbs, Fresh Mozzarell...|
| 10362|[Organic Baby Spinach, Organic Spring Mix, Organic L...|
| 19204|[Reduced Fat Crackers, Dishwasher Cleaner, Peanut Po...|
| 29601|[Organic Red Onion, Small Batch Authentic Taqueria T...|
| 31035|[Organic Cripps Pink Apples, Organic Golden Deliciou...|
| 40011|[Organic Baby Spinach, Organic Blues Bread with Blue...|
| 46266|[Uncured Beef Hot Dog, Organic Baby Spinach, Smoked ...|
| 51607|[Donut House Chocolate Glazed Donut Coffee K Cup, Ma...|
| 58797|[Concentrated Butcher's Bone Broth, Chicken, Seedles...|
| 61793|[Raspberries, Green Seedless Grapes, Clementines, Na...|
| 67089|[Original Tofurky Deli Slices, Sharp Cheddar Cheese,...|
| 70863|[Extra Hold Non-Aerosol Hair Spray, Bathroom Tissue,...|
| 88674|[Organic Coconut Milk, Everything Bagels, Rosemary, ...|
| 91937|[No. 485 Gin, Monterey Jack Sliced Cheese, Tradition...|
| 92317|[Red Vine Tomato, Harvest Casserole Bowls, Organic B...|
| 99621|[Organic Baby Arugula, Organic Garlic, Fennel, Lemon...|
+--------+-------------------------------------------------------+
only showing top 20 rows
import org.apache.spark.ml.fpm.FPGrowth
// FPGrowth only needs a string containing the list of items.
val basketsDF = spark.sql("select items from baskets")
.as[Array[String]].toDF("items")
basketsDF.show(20,55)
+-------------------------------------------------------+
| items|
+-------------------------------------------------------+
|[Raw Shrimp, Seedless Cucumbers, Versatile Stain Rem...|
|[Cracked Wheat, Strawberry Rhubarb Yoghurt, Organic ...|
|[Beet Apple Carrot Lemon Ginger Organic Cold Pressed...|
| [Vodka]|
|[Globe Eggplant, Panko Bread Crumbs, Fresh Mozzarell...|
|[Organic Baby Spinach, Organic Spring Mix, Organic L...|
|[Reduced Fat Crackers, Dishwasher Cleaner, Peanut Po...|
|[Organic Red Onion, Small Batch Authentic Taqueria T...|
|[Organic Cripps Pink Apples, Organic Golden Deliciou...|
|[Organic Baby Spinach, Organic Blues Bread with Blue...|
|[Uncured Beef Hot Dog, Organic Baby Spinach, Smoked ...|
|[Donut House Chocolate Glazed Donut Coffee K Cup, Ma...|
|[Concentrated Butcher's Bone Broth, Chicken, Seedles...|
|[Raspberries, Green Seedless Grapes, Clementines, Na...|
|[Original Tofurky Deli Slices, Sharp Cheddar Cheese,...|
|[Extra Hold Non-Aerosol Hair Spray, Bathroom Tissue,...|
|[Organic Coconut Milk, Everything Bagels, Rosemary, ...|
|[No. 485 Gin, Monterey Jack Sliced Cheese, Tradition...|
|[Red Vine Tomato, Harvest Casserole Bowls, Organic B...|
|[Organic Baby Arugula, Organic Garlic, Fennel, Lemon...|
+-------------------------------------------------------+
only showing top 20 rows
val fpgrowth = new FPGrowth()
.setItemsCol("items")
.setMinSupport(0.002)
.setMinConfidence(0)
val model = fpgrowth.fit(basketsDF)
// Frequent itemsets.
val mostPopularItems = model.freqItemsets
mostPopularItems.createOrReplaceTempView("mostPopularItems")
// Verify results.
spark.sql("select ∗ from mostPopularItems wheresize(items) >= 2 order by freq desc")
.show(20,55)
+----------------------------------------------+----+
| items|freq|
+----------------------------------------------+----+
|[Organic Strawberries, Bag of Organic Bananas]|3074|
|[Organic Hass Avocado, Bag of Organic Bananas]|2420|
|[Organic Baby Spinach, Bag of Organic Bananas]|2236|
| [Organic Avocado, Banana]|2216|
| [Organic Strawberries, Banana]|2174|
| [Large Lemon, Banana]|2158|
| [Organic Baby Spinach, Banana]|2000|
| [Strawberries, Banana]|1948|
| [Organic Raspberries, Bag of Organic Bananas]|1780|
| [Organic Raspberries, Organic Strawberries]|1670|
| [Organic Baby Spinach, Organic Strawberries]|1639|
| [Limes, Large Lemon]|1595|
| [Organic Hass Avocado, Organic Strawberries]|1539|
| [Organic Avocado, Organic Baby Spinach]|1402|
| [Organic Avocado, Large Lemon]|1349|
| [Limes, Banana]|1331|
| [Organic Blueberries, Organic Strawberries]|1269|
| [Organic Cucumber, Bag of Organic Bananas]|1268|
| [Organic Hass Avocado, Organic Baby Spinach]|1252|
| [Large Lemon, Organic Baby Spinach]|1238|
+----------------------------------------------+----+
only showing top 20 rows
spark.sql("select ∗ from mostPopularItems where
size(items) > 2 order by freq desc")
.show(20,65)
+-----------------------------------------------------------------+----+
| items|freq|
+-----------------------------------------------------------------+----+
|[Organic Hass Avocado, Organic Strawberries, Bag of Organic Ba...| 710|
|[Organic Raspberries, Organic Strawberries, Bag of Organic Ban...| 649|
|[Organic Baby Spinach, Organic Strawberries, Bag of Organic Ba...| 587|
|[Organic Raspberries, Organic Hass Avocado, Bag of Organic Ban...| 531|
|[Organic Hass Avocado, Organic Baby Spinach, Bag of Organic Ba...| 497|
| [Organic Avocado, Organic Baby Spinach, Banana]| 484|
| [Organic Avocado, Large Lemon, Banana]| 477|
| [Limes, Large Lemon, Banana]| 452|
| [Organic Cucumber, Organic Strawberries, Bag of Organic Bananas]| 424|
| [Limes, Organic Avocado, Large Lemon]| 389|
|[Organic Raspberries, Organic Hass Avocado, Organic Strawberries]| 381|
| [Organic Avocado, Organic Strawberries, Banana]| 379|
| [Organic Baby Spinach, Organic Strawberries, Banana]| 376|
|[Organic Blueberries, Organic Strawberries, Bag of Organic Ban...| 374|
| [Large Lemon, Organic Baby Spinach, Banana]| 371|
| [Organic Cucumber, Organic Hass Avocado, Bag of Organic Bananas]| 366|
| [Organic Lemon, Organic Hass Avocado, Bag of Organic Bananas]| 353|
| [Limes, Organic Avocado, Banana]| 352|
|[Organic Whole Milk, Organic Strawberries, Bag of Organic Bana...| 339|
| [Organic Avocado, Large Lemon, Organic Baby Spinach]| 334|
+-----------------------------------------------------------------+----+
only showing top 20 rows列出5-2市场篮分析与FP增长
显示的是最有可能一起购买的物品。列表中最受欢迎的是有机鳄梨,有机草莓和一袋有机香蕉的组合。这种列表可以成为“经常一起购买”类型建议的基础。
// FP-Growth 模型还会生成关联规则。输出包括
// 前因、后因和置信度(概率)。最小值
// 生成关联规则的置信度由
// 最小信任参数。
val AssocRules = model.associationRules
AssocRules.createOrReplaceTempView("AssocRules")
spark.sql("select antecedent, consequent,
confidence from AssocRules order by confidence desc")
.show(20,55)
+-------------------------------------------------------+
| antecedent|
+-------------------------------------------------------+
| [Organic Raspberries, Organic Hass Avocado]|
| [Strawberries, Organic Avocado]|
| [Organic Hass Avocado, Organic Strawberries]|
| [Organic Lemon, Organic Hass Avocado]|
| [Organic Lemon, Organic Strawberries]|
| [Organic Cucumber, Organic Hass Avocado]|
|[Organic Large Extra Fancy Fuji Apple, Organic Straw...|
| [Organic Yellow Onion, Organic Hass Avocado]|
| [Strawberries, Large Lemon]|
| [Organic Blueberries, Organic Raspberries]|
| [Organic Cucumber, Organic Strawberries]|
| [Organic Zucchini, Organic Hass Avocado]|
| [Organic Raspberries, Organic Baby Spinach]|
| [Organic Hass Avocado, Organic Baby Spinach]|
| [Organic Zucchini, Organic Strawberries]|
| [Organic Raspberries, Organic Strawberries]|
| [Bartlett Pears]|
| [Gala Apples]|
| [Limes, Organic Avocado]|
| [Organic Raspberries, Organic Hass Avocado]|
+-------------------------------------------------------+
+------------------------+-------------------+
| consequent| confidence|
+------------------------+-------------------+
|[Bag of Organic Bananas]| 0.521099116781158|
| [Banana]| 0.4643478260869565|
|[Bag of Organic Bananas]| 0.4613385315139701|
|[Bag of Organic Bananas]| 0.4519846350832266|
|[Bag of Organic Bananas]| 0.4505169867060561|
|[Bag of Organic Bananas]| 0.4404332129963899|
|[Bag of Organic Bananas]| 0.4338461538461538|
|[Bag of Organic Bananas]|0.42270861833105333|
| [Banana]| 0.4187779433681073|
| [Organic Strawberries]| 0.414985590778098|
|[Bag of Organic Bananas]| 0.4108527131782946|
|[Bag of Organic Bananas]|0.40930232558139534|
|[Bag of Organic Bananas]|0.40706806282722513|
|[Bag of Organic Bananas]|0.39696485623003197|
|[Bag of Organic Bananas]| 0.3914780292942743|
|[Bag of Organic Bananas]|0.38862275449101796|
| [Banana]| 0.3860811930405965|
| [Banana]|0.38373305526590196|
| [Large Lemon]| 0.3751205400192864|
| [Organic Strawberries]|0.37389597644749756|
+------------------------+-------------------+
only showing top 20 rows根据产量,购买有机覆盆子,有机鳄梨和有机草莓的客户也更有可能购买有机香蕉。如您所见,香蕉是一种非常受欢迎的项目。这种列表可能是“购买此商品的客户也购买了”类型建议的基础。
注意:除了 FP 增长之外,Spark MLlib 还包括频率模式匹配算法的另一种实现,称为前缀跨度。虽然 FP-Growth 对项集的排序方式无动于衷,但 PrefixSpan 使用序列或项集的有序列表来发现数据集中的顺序模式。前缀跨度属于称为顺序模式挖掘的算法子组。前缀跨度在论文“通过模式增长挖掘顺序模式:前缀跨度方法”中进行了描述,作者是 Jian Pei 等人。
基于内容的过滤
基于内容的筛选通过将有关项目的信息(如项目名称、说明或类别)与用户的配置文件进行比较来提供建议。让我们以基于内容的电影推荐系统为例。如果系统根据用户的个人资料确定用户更喜欢加里·格兰特的电影,它可能会开始推荐他的电影,例如西北偏北,抓住小偷和要记住的外遇。推荐人可能会推荐同类型演员的电影,如吉米·斯图尔特,格雷戈里·派克或克拉克·盖博(经典电影)。阿尔弗雷德·希区柯克和乔治·库克执导的电影,经常与卡里·格兰特合作,也可能被推荐。尽管内容推荐引擎很简单,但通常提供相关结果。它也很容易实现。该系统可以立即提供建议,而无需等待用户的显式或隐式反馈,这是困扰其他方法(例如协作过滤)的艰巨要求。
不利的一面是,基于内容的过滤在其建议中缺乏多样性和新颖性。观众有时想要更广泛的电影选择或更前卫的东西,这可能与观众的个人资料不完全匹配。可扩展性是困扰基于内容的推荐系统的另一个挑战。为了生成高度相关的建议,基于内容的引擎需要大量有关其推荐项目的相关域特定信息。十九对于电影推荐人来说,仅仅根据标题,描述或类型来提出建议是不够的。内部数据可能必须使用来自第三方来源(如IMDB或烂番茄)的数据进行增强。无监督学习方法(如潜在狄利克雷分配 (LDA))可用于从这些数据源中提取的元数据创建新主题。我将在第 4 章中详细讨论 LDA。
Netflix通过创建数千种提供高度针对性个性化推荐的微型产品,在这一领域处于领先地位。例如,Netflix不仅知道我的妻子喜欢看韩国电影,还知道她喜欢浪漫音乐韩国电影,谋杀神秘僵尸韩国电影,纪录片黑帮韩国僵尸电影,以及她个人最喜欢的法庭戏剧法律惊悚僵尸韩国电影。通过类似土耳其人的机械系统,Netflix聘请了兼职电影爱好者,手动为其库中的数千部电影和电视节目分配描述和类别。据最新统计,Netflix拥有76,897种独特的微型类型。这是一个新的个性化水平,在Netflix之外的任何地方都看不到。
Spark MLlib 不包含用于基于内容的筛选算法,尽管 Spark 具有必要的组件来帮助您开发自己的实现。为了帮助您入门,我建议您研究一下Spark中可用的高度可扩展的相似性算法,称为“使用MapReduce的维度独立矩阵方块”或简称DIMSUM。查看 https://bit.ly/2YV6qTr 以了解有关 DIMSUM 的更多信息。断续器
总结
每种方法都有自己的优点和缺点。在实际方案中,通常的做法是构建混合推荐引擎,结合多种技术来增强结果。推荐者是研究的沃土。考虑到它为一些世界上最大的公司带来的收入,预计很快就会在这一领域取得更多进展。FP增长的例子改编自巴文·库卡迪亚和丹尼·李在Databricks的工作。