python实现excel的数据提取
一文带你实现excel表格的数据提取
今天记录一下如何使用python提取Excel中符合特定条件的数据
在数据处理和分析的过程中,我们经常需要从Excel表格中提取特定条件下的数据。Python的pandas库为我们提供了方便的方法来进行数据查询和过滤。
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
- Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
- Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
- Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
- Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
- Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
- Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas应用
Pandas 的主要数据结构是 **Series (一维数据)**与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
01.简单数据类型的提取
| 序号 | a | b |
|---|---|---|
| 1 | 1.5 | 2.8 |
| 2 | 3.2 | 4.7 |
| 3 | 2.1 | 3.6 |
| 4 | 4.3 | 1.9 |
| 5 | 4.1 | 3.2 |
要求:提取a,b两列中介于2.5到5之间的数据
使用query方法提取数据
首先,我们将使用query方法来提取符合条件的数据。query方法允许我们使用类似SQL的语法进行数据查询。
代码如下:
import pandas as pd
# 读取Excel表格
df = pd.read_excel('data.xlsx') # 将'data.xlsx'替换为你的文件路径
# 使用query方法进行查询
query_string = '2.5 < x < 5 and 2.5 < y < 5'
filtered_data = df.query(query_string)
# 打印提取的数据
print(filtered_data)
02.复杂数据类型的数据提取
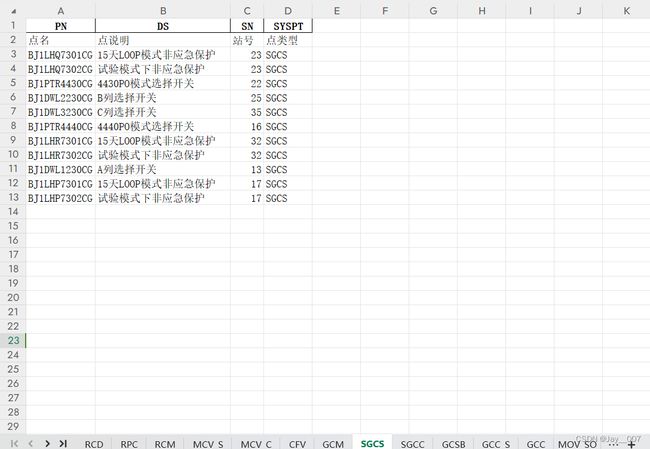
如下是一个包含70+sheet表单的excel工作簿,现在要求从该excel中抽取特定的数据列到新表中
话不多说,直接上代码
import pandas as pd
import openpyxl
wb = openpyxl.Workbook()
# 获取默认工作表
ws = wb.active
# 读取原始Excel文件
# df = pd.read_excel('SA.xlsx')
df = pd.read_excel('SA.xlsx', sheet_name=['RCD', 'RPC','RCM','MCV_S','MCV_C','CFV',
'GCM','SGCS','SGCC','GCSB','GCC_S','GCC','MOV_SO'
,'MOV_SC','MOV_N','MNV_C','BSV_C','MSV_CSC','MSV_CLC'
,'MSV_CLO','CAH_N','BAH_N','BAH_L','BAH_OT','MOS_T','MOS_C'
,'MOS_N','MOS_L','NOPDS','ALA_P','AVIE','SLT8','SLT4','BOOLS'
,'REALS','EPS','SA','KG','TRAN','SETP','PID','NSD','DV','AMI',
'DCO','ACO','DCI','ACI6','ACI4','ACI','DM','AM4','AM','SOE','PVI'
,'DVO','AVO','DVI','AVI8','AVI6','AVI4','AVI'])
# 创建一个新的Excel文件
wb = pd.ExcelWriter('new.xlsx')
# 遍历每个sheet
for sheet_name, sheet_data in df.items():
# 提取需要的列数据
columns_to_extract = [ 'PN','SN']
if all(column in sheet_data.columns for column in columns_to_extract):
extracted_data = sheet_data[columns_to_extract]
# 将提取的数据写入新的Excel文件中的对应sheet
extracted_data.to_excel(wb, sheet_name=sheet_name, index=False)
extracted_data.to_excel('new.xlsx', index=False)
df_extracted = pd.read_excel('new.xlsx', sheet_name=None,engine='openpyxl')
# 创建一个新的Excel写入器
writer = pd.ExcelWriter('merged_1023.xlsx')
# 遍历抽取的Excel的每个sheet
for sheet_name, df_sheet in df_extracted.items():
# 将每个sheet写入新的Excel中
df_sheet.to_excel(writer, sheet_name, index=False)
# 保存并关闭新的Excel
writer.close()
wb.close()
详细的注释已经写在上面,可以根据自己的需求和条件选择相应的文件进行数据提取
合并结果如下: