任何的数据协议,只要是称得上是协议,就会有固定的格式。
比如,如下的一个数据协议,应该是一个相当复杂的数据协议:

数据协议demo
这个协议,可以用“包头+包体+包尾”这样个格式。其中,包头和包尾的数据长度是固定的,变化的只是包体长度。
来解析或者编码这样一个数据协议,我们首先想到的是应用模板方法模式,因为不管包体的解析怎么变,包头和包尾的解析是不变的,因此,我们可以把对包头和包尾的解析放到父类里,而把对包体的解析延迟到子类完成。基于这样一个编程思路,就是模板方法模式的应用了。
下面来看它的具体实现:
首先是解析包头-
@Slf4j
public abstract class CashboxBaseDecoder {
//只给读写钱箱参数命令返回解析使用
@Setter
private CashboxParamHandleType handleType;
@Setter
private CashboxCommandType commandType;
//已经获取了7个字节
private CashboxBaseData decodeHeader(ByteBuf buffer) {
log.info("开始解析数据包头...");
logByteBuf(buffer, log);
CashboxBaseData result;
CashboxBaseData baseData = new CashboxBaseData();
baseData.setBeginDLE(buffer.getByte(0));
baseData.setStx(buffer.getByte(1));
baseData.setLength(buffer.getShortLE(2));
baseData.setType(this.commandType);
//解析返回结果和错误码
CashboxBaseResultData cashboxBaseResultData = new CashboxBaseResultData(baseData);
cashboxBaseResultData.setResult(getById(buffer.getByte(4)).get());
cashboxBaseResultData.setErrorCode(buffer.getShortLE(5));
result = cashboxBaseResultData;
return result;
}
值得注意的是,在解析包头的方法decodeHeader中,除了解析了包头的4个字节以外,还解析了包体的3个字节,因为包体开头的3个字节-结果和错误码,也在每一个数据包中是一样的,所以,虽然这3个字节在包体中,我们仍然把它放到了包头中解析。
接着解析包尾-
private void decodeTail(CashboxBaseData baseData, ByteBuf buffer) throws DataAlteredException{
log.info("开始解析数据包尾...");
int beginPort = 4 + baseData.getLength();
baseData.setId(buffer.getMediumLE(beginPort));
baseData.setEndDLE(buffer.getByte(beginPort + 3));
baseData.setEtx(buffer.getByte(beginPort + 4));
baseData.setCrc(buffer.getUnsignedShortLE(beginPort + 5));
System.out.println(getCheckCode(buffer, baseData.getLength()));
if (baseData.getCrc() != getCheckCode(buffer, baseData.getLength())) {
throw new DataAlteredException(ErrorCode.ERROR_PROTO_CHECKSUM, "CRC校验不正确!");
}
}
包尾解析7个字节,任何数据包都一样。最后,做一下CRC校验。
对包体的解析在父类里无法实现,抽象到子类中实现-
protected abstract CashboxBaseData decodeBody(CashboxBaseData baseData, ByteBuf buffer, CashboxParamHandleType handleType);
最后是对整个数据包的解析,先调用对包头的解析,然后把结果赋给对包体解析的方法-
public final CashboxBaseData decode(ByteBuf buffer) throws DataAlteredException{
CashboxBaseData baseData = decodeBody(decodeHeader(buffer), buffer, handleType);
后调用对包尾的解析-
decodeTail(baseData, buffer);
log.debug("解析结果, 公共数据:"+baseData.toString());
return baseData;
}
}
这就完成了对父类的编码。
下面,我们来看看子类的实现。
第一个子类是“初始化结果返回”:
@Slf4j
public class CashboxInitialiseResultDecoder extends CashboxBaseDecoder{
@Override
protected CashboxBaseData decodeBody(CashboxBaseData baseData, ByteBuf buffer, CashboxParamHandleType handleType) {
log.info("进入初始化结果返回数据解析...");
return baseData;
}
}
初始化结果返回的包体没有任何内容。
下面一个子类是“获取固件版本结果返回”:
@Slf4j
public class CashboxInitialiseResultDecoder extends CashboxBaseDecoder{
@Override
protected CashboxBaseData decodeBody(CashboxBaseData baseData, ByteBuf buffer, CashboxParamHandleType handleType) {
log.info("解析固件版本号结果...");
CashboxVersionReadResultData data = new CashboxVersionReadResultData((CashboxBaseResultData) baseData);
data.setVersion(buffer.getCharSequence(RESULT_PORT_BEGIN, data.getLength() - SIZE_OF_DATA_4_CODE, Charset.forName("utf-8")).toString());
return data;
}
}
获取固件版本号的包体里只有一个数据,就是版本号,是字符串形式的。
以上就是整个数据包解析应用模板方法模式的解决过程,其类图如下所示:
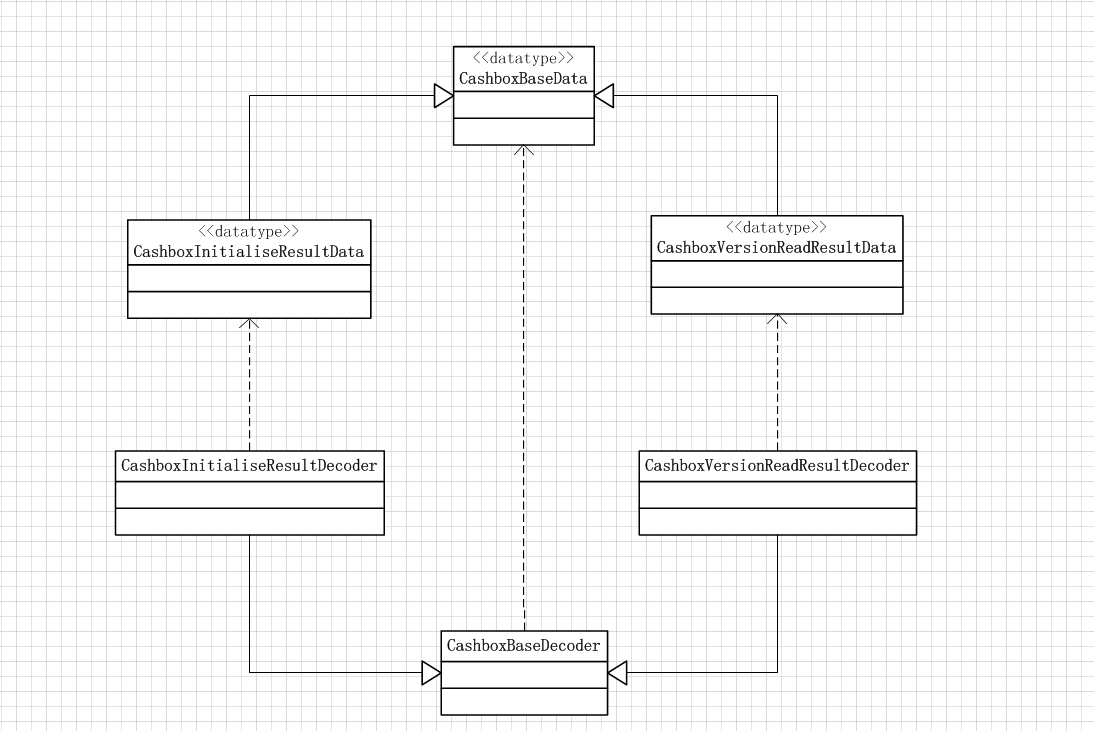
类图