SpringBoot整合mybatis(使用注解)
文章目录
- 前言
- 使用SpringBoot整合mybatis
-
- 依赖配置
-
- pom.xml
- application.yml
- 建表语句和数据
- 实体类
- 创建Mapper
- 创建server层
- 测试代码
- MyBatis 中 #{} 和 ${} 的区别
-
- 1、在MyBatis 的映射配置文件中,动态传递参数有两种方式:
- 2、#{} 和 ${} 的区别
- 3、演示
-
- Mapper 层
- server层
- 测试类
- 查询结果对比
- MyBits批量插入大量数据
-
- 使用 @InsertProvider
-
- 1. 建表语句
- 2. 项目中的实体类
- 3. 每个实体类对应的Mapper方法
- 4. SQL工厂
- 测试代码
- 运行结果
- Mybatis 流式查询
-
- 基本概念
- MyBatis 流式查询接口--Cursor
-
- 简介
- 我们举个实际例子
-
- 1、下面是一个 Mapper 类:
- 2、然后我们再写一个测试方法来调用 Mapper:
- 3 、 运行结果
- 方案一:SqlSessionFactory
- 方案二:TransactionTemplate
- 方案三:@Transactional 注解
- MyBatis 流式查询对比
-
- 1、数据表
- 2、Mapper
- 3、Controller
- 结果
- 项目源码
这篇文章是初探mybatis的总结
借助 MyBatis-Spring-Boot-Starter 来实现零xml使用mybatis
参考文章
http://mybatis.org/spring/zh/index.html
http://mybatis.org/spring-boot-starter/mybatis-spring-boot-autoconfigure/
前言
众所周知,MyBatis的核心有两大组件:SqlSessionFactory 和 Mapper 接口。前者表示数据库链接,后者表示SQL映射。当我们基于Spring使用MyBatis的时候,也要保证在Spring环境中能存在着两大组件。
MyBatis-Spring-Boot-Starter 将会完成以下功能:
1、Autodetect an existing DataSource
自动发现存在的DataSource
2、Will create and register an instance of a SqlSessionFactory passing that DataSource as an input using the SqlSessionFactoryBean
利用SqlSessionFactoryBean创建并注册SqlSessionFactory
3、Will create and register an instance of a SqlSessionTemplate got out of the SqlSessionFactory
创建并注册SqlSessionTemplate
4、Auto-scan your mappers, link them to the SqlSessionTemplate and register them to Spring context so they can be injected into your beans
自动扫描Mappers,并注册到Spring上下文环境方便程序的注入使用
mybatis-spring-boot-starter就是参照Spring Boot的设计思想,化繁为简,以简单注解的方式让用户快速上手。
下面我们简单的创建一个springboot项目,让他跑起来:
使用SpringBoot整合mybatis
依赖配置
pom.xml
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.1version>
<scope>testscope>
dependency>
application.yml
mybatis:
configuration:
map-underscore-to-camel-case: true
# 该配置就是将带有下划线的表字段映射为驼峰格式的实体类属性
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybits?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=UTF-8
username: root
password: aaaa
建表语句和数据
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(0) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`sex` char(6) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`pwd` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`email` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
INSERT INTO `user` VALUES (2, 'java', '✔', 'aaaa', '[email protected]');
INSERT INTO `user` VALUES (3, '张三', '男', 'a', '[email protected]');
INSERT INTO `user` VALUES (4, '李四', '男', 'a', '[email protected]');
INSERT INTO `user` VALUES (5, '王五', '女', 'a', '[email protected]');
INSERT INTO `user` VALUES (6, '赵六', '女', 'a', '[email protected]');
INSERT INTO `user` VALUES (7, '测试', '男', 'aaaaa', '[email protected]');
实体类
@Data
@Builder
public class User {
private Integer id;
private String name;
private String sex;
private String pwd;
private String email;
public User() { }
public User(Integer id, String name, String sex, String pwd, String email) {
this.id = id;
this.name = name;
this.sex = sex;
this.pwd = pwd;
this.email = email;
}
}
创建Mapper
@Mapper
public interface UserMapper {
@Select("select * from user")
List<User> selectAll();
@Select("select * from user where id = #{id}")
User selectById(@Param("id") int id);
@Select("select * from user where name = #{name}")
Map<String, Object> selectByName1(@Param("name") String name);
@Select("select * from user where name = #{name}")
User selectByName2(@Param("name") String name);
// @Select("select * from user where name = #{name} and pwd = #{name}")
// User selectByNameAndPwd(@Param("name") String name, @Param("pwd") String pwd);
@Select("select * from user where name = #{name} and pwd = #{pwd}")
User selectByNameAndPwd(String name, String pwd);
@Delete("delete from user where id = #{id}")
boolean deleteById(int id);
@Insert("insert into user values (null,#{name},#{sex},#{pwd},#{email})")
boolean insertUser(String name, String sex, String pwd, String email);
@Update("update user set name = #{name} where id = #{id}")
boolean updateById(String name, int id);
}
创建server层
@Service
public class UserBiz {
@Resource
private UserMapper um;
public User selectById(int id) {
return um.selectById(id);
}
public List<User> queryAll() {
return um.selectAll();
}
public Map<String, Object> queryByName1(String name) {
return um.selectByName1(name);
}
public User queryByName2(String name) {
return um.selectByName2(name);
}
public User queryByNameAndPwd(String name, String pwd) {
return um.selectByNameAndPwd(name, pwd);
}
public boolean delete(int id) {
return um.deleteById(id);
}
public boolean add(User user) {
return um.insertUser(user.getName(), user.getSex(), user.getPwd(), user.getEmail());
}
public boolean change(String name, int id) {
return um.updateById(name, id);
}
}
测试代码
@SpringBootTest
public class UserBizTest {
@Autowired
UserBiz userBiz;
@Test
public void selectByAccountAndPwd() {
System.out.println(userBiz.selectById(2));
}
@Test
public void queryAll() {
System.out.println(userBiz.queryAll());
}
@Test
public void queryByName() {
long t1 = new Date().getTime();
Map<String, Object> maps = userBiz.queryByName1("张三");
long t2 = new Date().getTime();
System.out.println(t2 - t1);
System.out.println(maps);
t1 = new Date().getTime();
User user = userBiz.queryByName2("张三");
t2 = new Date().getTime();
System.out.println(t2 - t1);
System.out.println(user);
}
@Test
public void login() {
User user = userBiz.queryByNameAndPwd("张三", "a");
System.out.println(user);
user = userBiz.queryByNameAndPwd("张三", "aa");
System.out.println(user);
}
@Test
public void delete() {
Assert.isTrue(userBiz.delete(1));
}
@Test
public void add() {
User user = new User(null, "Test", "男", "aaaaa", "[email protected]");
Assert.isTrue(userBiz.add(user));
}
@Test
public void change() {
Assert.isTrue(userBiz.change("测试",7),"修改失败");
}
}
上面的代码就演示了使用mybatis对数据库的增删改查操作
MyBatis 中 #{} 和 ${} 的区别
https://www.cnblogs.com/dato/p/7027949.html
1、在MyBatis 的映射配置文件中,动态传递参数有两种方式:
(1)#{} 占位符
(2)${} 拼接符
2、#{} 和 ${} 的区别
-
#{} 为参数占位符 ?,即sql 预编译
${} 为字符串替换,即 sql 拼接 -
#{}:动态解析 -> 预编译 -> 执行
${}:动态解析 -> 编译 -> 执行 -
#{} 的变量替换是在DBMS 中
${} 的变量替换是在 DBMS 外 -
变量替换后,#{} 对应的变量自动加上单引号 ‘’
变量替换后,${} 对应的变量不会加上单引号 ‘’ -
#{} 能防止sql 注入
${} 不能防止sql 注入
3、演示
Mapper 层
/**
* 使用 #{} 占位符
*
* @param id
* @return
*/
@Select("select * from user where id > #{id}")
List<User> select1(String id);
/**
* 使用 ${} 拼接符
*
* @param id
* @return
*/
@Select("select * from user where id > ${id}")
List<User> select2(String id);
server层
public List<User> test1(String id){
return um.select1(id);
}
public List<User> test2(String id){
return um.select2(id);
}
测试类
@Test
public void test1(){
printList(userBiz.test1("1"));
System.out.println();
printList(userBiz.test1("1 and sex = '男'"));
}
@Test
public void test2(){
printList(userBiz.test2("1"));
System.out.println();
printList(userBiz.test2("1 and sex = '男'"));
}
public void printList(List list){
for(Object o: list){
System.out.println(o);
}
}
查询结果对比
- 使用#{}
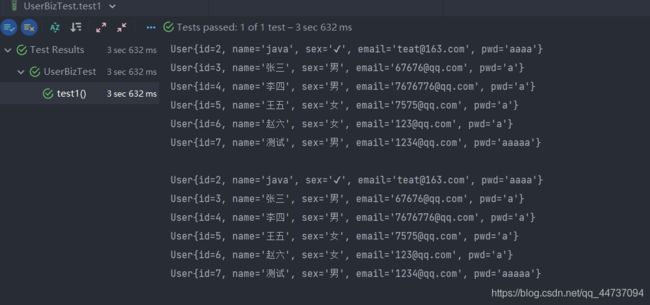
- 使用${}

MyBits批量插入大量数据
使用 @InsertProvider
@Insert和@InsertProvider都是用来在实体类的Mapper类里注解保存方法的SQL语句。不同的是,@Insert是直接配置SQL语句,而@InsertProvider则是通过SQL工厂类及对应的方法生产SQL语句,这种方法的好处在于,我们可以根据不同的需求生产出不同的SQL,适用性更好。
1. 建表语句
DROP TABLE IF EXISTS `users`;
CREATE TABLE `users` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`time_datetime` datetime(0) NOT NULL,
`time_timestamp` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0),
`time_long` bigint(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `time_long`(`time_long`) USING BTREE,
INDEX `time_timestamp`(`time_timestamp`) USING BTREE,
INDEX `time_datetime`(`time_datetime`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1000003 CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
2. 项目中的实体类
@Builder
@Data
public class Users {
//自增唯一id
private Long id;
//datetime类型的时间
private Timestamp timeDatetime;
//timestamp类型的时间
private Timestamp timeTimestamp;
//long类型的时间
private long timeLong;
}
3. 每个实体类对应的Mapper方法
@Mapper
public interface UsersMapper {
//批量插入数据方法
@InsertProvider(type = UsersDaoProvider.class, method = "insertAll")
void batchSaveUsersList(@Param("list") List<Users> users);
//单条插入数据
@Insert("insert into users(time_datetime, time_timestamp, time_long) value(#{timeDate}, #{timeTimestamp}, #{timeLong})")
@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")
void saveUsers(Users users);
}
4. SQL工厂
public class UsersDaoProvider {
public String insertAll(Map map) {
List<Users> list = (List<Users>) map.get("list");
StringBuilder sb = new StringBuilder();
sb.append("insert into users");
sb.append("(time_datetime, time_timestamp, time_long) ");
sb.append("value ");
MessageFormat mf = new MessageFormat("(#'{'list[{0}].timeDatetime},#'{'list[{0}].timeTimestamp},#'{'list[{0}].timeLong})");
for (int i = 0; i < list.size(); i++) {
sb.append(mf.format(new Object[]{i}));
if (i < list.size() - 1) {
sb.append(",");
}
}
//打印出拼接完成的sql语句
System.out.println(sb);
return sb.toString();
}
}
测试代码
@SpringBootTest
public class UsersMapperTest {
@Autowired
private UsersMapper usersMapper;
//插入500000条,一次插入1000条
@Test
public void saveAllUsers() {
for (int a = 0;a <500;a++) {
List<Users> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
long time = System.currentTimeMillis();
Users users = Users.builder().timeDatetime(new Timestamp(time)).timeLong(time).timeTimestamp(new Timestamp(time)).build();
list.add(users);
}
usersMapper.batchSaveUsersList(list);
}
}
//插入500000条数据,一次插入一条
@Test
public void saveUsers() {
for (int i = 0; i < 500000; i++) {
long time = System.currentTimeMillis();
usersMapper.saveUsers(Users.builder().timeDatetime(new Timestamp(time)).timeLong(time).timeTimestamp(new Timestamp(time)).build());
}
}
}
运行结果
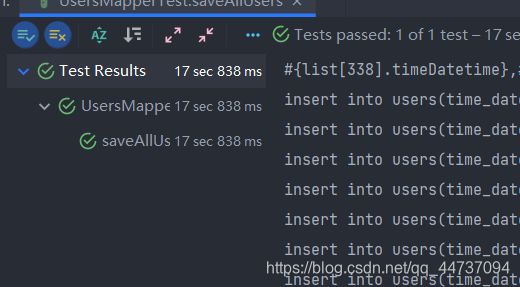
可以看到使用@InsertProvider来批量插入数据大大提高了效率
Mybatis 流式查询
基本概念
流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。
如果没有流式查询,我们想要从数据库取 1000 万条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。
流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。
MyBatis 流式查询接口–Cursor
简介
MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:
- Cursor 是可关闭的;
- Cursor 是可遍历的。
除此之外,Cursor 还提供了三个方法:
- isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;
- isConsumed():用于判断查询结果是否全部取完。
- getCurrentIndex():返回已经获取了多少条数据。
因为 Cursor 实现了迭代器接口,因此在实际使用当中,从 Cursor 取数据非常简单:
cursor.forEach(rowObject -> {...});
但构建 Cursor 的过程不简单
我们举个实际例子
1、下面是一个 Mapper 类:
@Mapper
public interface FooMapper {
@Select(“select * from foo limit #{limit}”)
Cursor scan(@Param(“limit”) int limit);
}
方法 scan() 是一个非常简单的查询。通过指定 Mapper 方法的返回值为 Cursor 类型,MyBatis 就知道这个查询方法一个流式查询。
2、然后我们再写一个测试方法来调用 Mapper:
@SpringBootTest
@RunWith(SpringJUnit4ClassRunner.class)
public class UserCursorTest {
@Autowired
UserMapper userMapper;
@Test
public void test1() {
try (Cursor<User> cursor = userMapper.scan(10)) {
cursor.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
}
3 、 运行结果

这是因为我们前面说了在取数据的过程中需要保持数据库连接,而 Mapper 方法通常在执行完后连接就关闭了,因此 Cusor 也一并关闭了。
所以,解决这个问题的思路不复杂,保持数据库连接打开即可。我们至少有三种方案可选。
方案一:SqlSessionFactory
我们可以用 SqlSessionFactory 来手工打开数据库连接,将测试方法修改如下:
@Autowired
SqlSessionFactory sqlSessionFactory;
@Test
public void test2() {
try (SqlSession sqlSession = sqlSessionFactory.openSession();// 1
Cursor<User> cursor = sqlSession.getMapper(UserMapper.class).scan(10)//2
) {
cursor.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
上面的代码中,1 处我们开启了一个 SqlSession (实际上也代表了一个数据库连接),并保证它最后能关闭;2 处我们使用 SqlSession 来获得 Mapper 对象。这样才能保证得到的 Cursor 对象是打开状态的。
运行结果
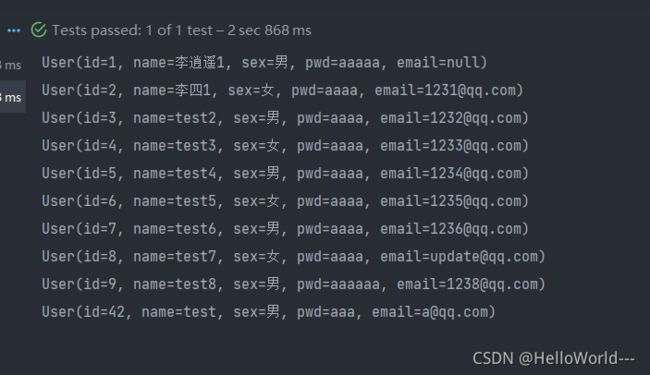
方案二:TransactionTemplate
在 Spring 中,我们可以用 TransactionTemplate 来执行一个数据库事务,这个过程中数据库连接同样是打开的。代码如下:
@Autowired
TransactionTemplate transactionTemplate;
@Test
public void test3() {
//TransactionTemplate transactionTemplate = new TransactionTemplate(transactionManager); // 1
transactionTemplate.execute(status -> { // 2
try (Cursor<User> cursor = userMapper.scan(20)) {
cursor.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
return null;
});
}
上面的代码中,1 处我们创建了一个 TransactionTemplate 对象(此处 transactionManager 是怎么来的不用多解释,本文假设读者对 Spring 数据库事务的使用比较熟悉了),2 处执行数据库事务,而数据库事务的内容则是调用 Mapper 对象的流式查询。注意这里的 Mapper 对象无需通过 SqlSession 创建。
方案三:@Transactional 注解
这个本质上和方案二一样,代码如下:
@Transactional
@Test
public void test4() {
try (Cursor<User> cursor = userMapper.scan(10)) {
cursor.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
它仅仅是在原来方法上面加了个 @Transactional 注解。这个方案看上去最简洁,但请注意 Spring 框架当中注解使用的坑:只在外部调用时生效。在当前类中调用这个方法,依旧会报错。
以上是三种实现 MyBatis 流式查询的方法。
MyBatis 流式查询对比
1、数据表
数据表就用上面批量插入创建的users表
2、Mapper
@Mapper
public interface UsersMapper {
//TODO MyBatis 流式查询对比
@Select("select * from users limit #{limit}")
Cursor<Users> scan(@Param("limit") int limit);
@Select("select * from users limit #{limit}")
List<Users> selectList(@Param("limit") int limit);
}
3、Controller
@RestController
public class UsersController {
@Autowired
UsersMapper usersMapper;
@Autowired
SqlSessionFactory sqlSessionFactory;
//流式查询
@RequestMapping(value = "/query1", method = {RequestMethod.GET, RequestMethod.POST})
public JsonModel query1(int limit) {
JsonModel jsonModel = new JsonModel();
try (SqlSession sqlSession = sqlSessionFactory.openSession();
) {
long start = new Date().getTime();
Cursor<Users> cursor = sqlSession.getMapper(UsersMapper.class).scan(limit);
long end = new Date().getTime();
cursor.forEach(System.out::println);
jsonModel.setMsg("查询成功! " + "耗时: " + (end - start) );
cursor.close();
return jsonModel;
} catch (Exception e) {
jsonModel.setMsg(e.getMessage());
e.printStackTrace();
}
return jsonModel;
}
//普通查询
@RequestMapping(value = "/query2", method = {RequestMethod.GET, RequestMethod.POST})
public JsonModel query2(int limit) {
JsonModel jsonModel = new JsonModel();
try {
long start = new Date().getTime();
List<Users> list = usersMapper.selectList(limit);
long end = new Date().getTime();
list.forEach(System.out::println);
jsonModel.setMsg("查询成功! " + "耗时: " + (end - start) );
} catch (Exception e) {
jsonModel.setMsg(e.getMessage());
e.printStackTrace();
}
return jsonModel;
}
}
结果
流式查询耗时

普通查询耗时
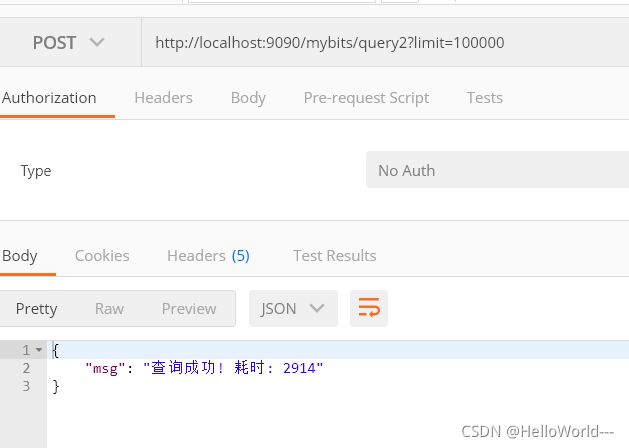
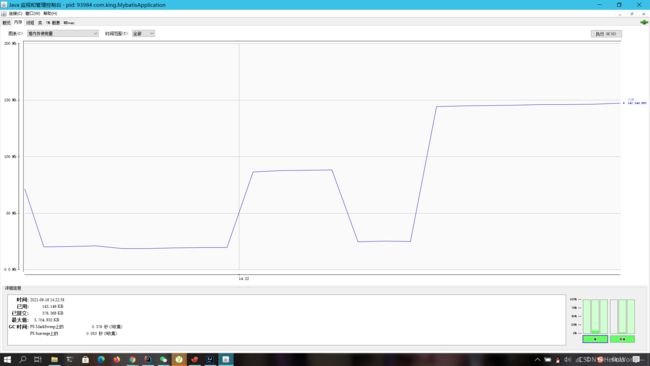
结论:流式查询能够降低内存使用,貌似也更快。
项目源码
最后附上我的演示例源码
Github
https://github.com/KingJin-web/springboot/tree/master/mybatis
Gitee
https://gitee.com/king__gitee/springboot/tree/master/mybatis
以上内容属于个人笔记整理,如有错误,欢迎批评指正!