Q-Learning 、Sarsa与 DQN算法
Q-Learning 、Sarsa与 DQN算法
-
- Q-Learning算法
- Sarsa 算法
- DQN算法
Q-Learning算法
一、算法思想:
QLearning是强化学习算法中value-based的算法,Q即为 Q ( s , a ) Q(s,a) Q(s,a) 就是在某一时刻的 s 状态下 ( s ∈ S ) (s∈S) (s∈S) ,采取动作 a ( a ∈ A ) a (a∈A) a(a∈A) 动作能够获得收益的期望,环境会根据 agent 的动作反馈相应的回报reward r r r,所以算法的主要思想就是将 State 与 Action 构建成一张 Q-table 来存储Q值,然后根据Q值来选取能够获得最大的收益的动作。
| Q-Table | a1 | a2 |
|---|---|---|
| s1 | q(s1,a1) | q(s1,a2) |
| s2 | q(s2,a1) | q(s2,a2) |
| s3 | q(s3,a1) | q(s3,a2) |
Qlearning的主要优势就是使用了时间差分法TD(融合了蒙特卡洛和动态规划)能够进行离线学习, 使用 bellman方程可以对马尔科夫过程求解最优策略
二、参数更新方式
利用时间差分法对Q-table的Q值进行计算更新:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ m a x a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a)←Q(s,a)+α[r+γmax_{a^′}Q(s^′,a^′)−Q(s,a)] Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
根据下一个状态 s ’ s^’ s’ 中选取最大的 Q ( s ′ , a ′ ) Q(s^{'} , a^{'}) Q(s′,a′) 值乘以奖励衰减因子 γ γ γ 加上真实回报值作为 Q现实,而根据过往Q表里面的 Q ( s , a ) Q(s,a) Q(s,a) 作为 Q估计。

Sarsa 算法
Sarsa 的决策部分和 Q-learning 一模一样, 都是使用 Q 表的形式决策, 不同的地方在于 Sarsa 的更新方式。
注意Q-Learning与Sarsa算法的参数更新公式的细微不同,虽然两个算法都是通过时间差分法进行参数更新,但Sarsa算法不需要取下一状态的 Q m a x Q_{max} Qmax,而是通过策略 π \pi π 与环境做交互实时得到下一状态的 Q 值,因此Sarsa算法是一种on-policy的算法(用于采集数据的策略与用于训练的策略是同一个策略)。

DQN算法
深度 Q 网络(Deep Q-network,DQN)是指基于深度学习的 Q 学习算法,主要结合了值函数近似与神经网络技术,并采用了经验回放和固定目标网络的两大改进方法进行网络训练。
一、DQN解决的问题
Q-learning的核心在于Q表格,通过建立Q表格来为行动提供指引,但这仅适用于状态和动作空间是离散且维数不高的情况,当状态和动作空间很大时Q表格将变得十分巨大,对于维护Q表格和查找都是不现实的。当然DQN算法一般也不用于动作空间连续的情况。
Q ϕ ( s , a ) ≈ Q π ( s , a ) Q_{\phi}(s, a) \approx Q^{\pi}(s,a) Qϕ(s,a)≈Qπ(s,a)
可以通过如上式所示的值函数近似的方法,拟合一个参数为 ϕ \phi ϕ 的函数 Q ϕ ( s , a ) Q_ϕ(s, a) Qϕ(s,a) (如神经网络)来输出Q值,一般为输入一个状态,给出不同动作的Q值。深度学习在复杂特征提取效果良好,将RL与DL结合变得到了DQN。
这将带来两个好处:
1.只需要存储DL的网络结构与参数
2.相近的的输入会得到相近的输出,泛化能力更强
【补充】动作空间的维数:(举例来说)
一维动作空间:智能体只能前进和后退
二维动作空间:智能体可以向左、向右、向前、向后运动,动作有两个维度,动作组合为 2 2 2^2 22 种。
三维动作空间:智能体可以前后、左右、上下移动,动作有三个维度,动作组合为 2 3 2^3 23 种。
也就是说,当智能体的动作空间维度增加时,动作空间也会呈现指数级增长,容易出现维度爆炸的问题。高维动作空间往往还是连续的,很少会遇到高维离散动作空间(推荐系统可能会遇到)。比如机械臂的关节有很多,每个关节的维度也会涉及到一个角度,角度是连续值,就会涉及到高维连续动作空间的问题。
通常而言,DQN算法只是适用于动作空间离散且比较大(也就是可选择的动作种类比较多)的情况,并不适用于高维连续动作空间的情况。
二、DQN面临的问题
DQN ≈ ≈ ≈ Q-Learning + + +神经网络,如果只是简单的结合将会带来两个问题:
1.神经网络要求输入的样本之间相互独立,互不关联,满足独立同分布。而强化学习输入的状态是相互关联的,不满足独立同分布。
2.引入非线性函数,使用神经网络来近似Q表格,训练结果可能不收敛。
三、DQN的两大改进
首先明确一个问题,为什么当输入数据之间不满足独立同分布时神经网络训练会难以收敛?
举例来说,数据倾斜问题(正负样本不均衡),在分类问题中,当训练数据是99张猫和1张狗时(数据不满足独立同分布),会使得网络倾向于将输入数据分类成猫。当测试集中的猫和狗比例相同时,就会出现很多预测错误的情况,网络的loss会比较大,难以收敛。
再比如说,回归问题中,输入数据之间如果存在关联性,可能会导致网络拟合的函数发生变化,使得预测结果不准确,loss比较大。
DQN的两大改进都缓解了输入数据之间不满足独立同分布时网络难以收敛的问题。
1.experience replay 经验池
DQN利用到了Q-learning是off-policy的特性,behavior-policy在探索或行动获取经验后会将经验存储到经验池中,一条经验可以由 ( s , a , r , s ’ ) (s,a,r,s’) (s,a,r,s’) 来表示。target-policy随机从经验池中抽取一条经验来更新网络,流程如下:

引入经验池的目的:用来实现off-policy性质的训练性能提升,经验回放会构建一个回放缓冲区(replay buffer),回放缓冲区又被称为回放内存(replay memory)。回放缓冲区说明与环境做互动的策略 π 与 用来训练的策略 π’ 不是同一个策略,与环境做互动的策略用于收集数据并存入经验缓冲区,当前用来训练的策略可以直接从经验缓冲区中采样经验来训练更新网络,这也体现了off-policy的思想(收集数据的策略与用于训练的策略的不是同一个策略)。
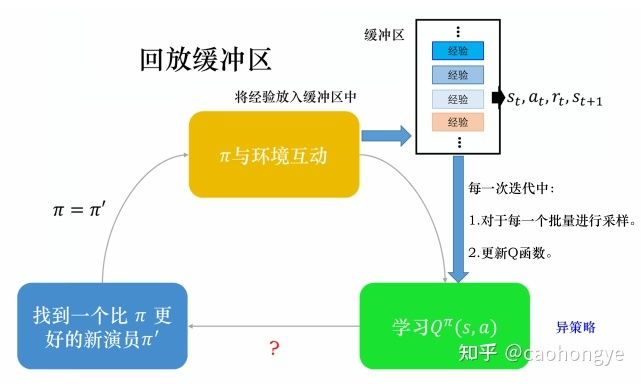
这将带来两个好处:
1)随机抽取,数据多样性,可以切断经验的相关性。
在训练网络的时候,我们希望一个batch 里面的数据越多样(diverse) 越好。如果batch里面都是一样的数据,训练的时候性能会比较差。因此,我们希望batch的数据越多样越好。如果数据缓冲区里面的经验通通来自于不同的策略,那么采样到的一个batch 里面的数据会是比较多样的,可以切断经验的相关性。
2)减少与环境交互次数,提升训练时间;每一条经验可以重复学习多次,提高了经验的利用率。
在做强化学习的时候,往往最花时间的步骤是在跟环境做互动,训练网络反而是比较快的。因为我们用 GPU 训练其实很快,真正花时间的往往是在跟环境做互动。用回放缓冲区可以减少跟环境做互动的次数,因为在做训练的时候,经验不需要通通来自于某一个策略。一些过去的策略所得到的经验可以放在数据缓冲区里面被使用很多次,被反复的再利用,这样让采样到经验的利用是比较高效的。
2.固定Q-target 网络
DQN中会有两个结构完全相同但是参数却不同的网络,当前Q网络用于预测Q估计值,target Q网络用于预测Q现实值,当前Q网络使用最新的参数,并不断训练更新,target Q网络会使用很久之前的参数,隔步更新。
当前 Q网络计算的Q估计值为: Q ( s , a ; θ ) Q(s,a;θ) Q(s,a;θ)
用 target Q网络计算的Q现实值为: t a r g e t = r + γ ∗ Q m a x ( s ′ , a ′ ; θ ′ ) target = r + γ* Q_{max}(s',a';θ') target=r+γ∗Qmax(s′,a′;θ′)
Q现实值随着target Q网络更新才会更新,因此一般也是隔几步才更新,这样有利于网络训练的稳定性。
与Q-learning 算法的更新方式类似,根据Q现实与Q估计得到损失,损失函数一般采用均方误差损失:
L o s s ( θ ) = E [ ( t a r g e t − Q ( s , a ; θ ) ) 2 ] Loss(θ)=E[(target−Q(s,a;θ))^2] Loss(θ)=E[(target−Q(s,a;θ))2]
根据 bellman 方程(一个状态的价值由该状态所得的奖励以及后续下一个状态的价值按一定的衰减比例联合组成),算法更新的目标是训练 Q ( s , a ; θ ) Q(s,a;θ) Q(s,a;θ),使之逼近Q现实 r + γ ∗ Q m a x ( s ′ , a ′ ; θ ′ ) r + γ* Q_{max}(s',a';θ') r+γ∗Qmax(s′,a′;θ′),使得 loss 越小越好,因此当前 Q网络的参数并不像target Q网络那样阶段性固定,而是持续更新。
注意这里的 Q ( s , a ; θ ) Q(s,a;θ) Q(s,a;θ) 与Q现实 r + γ ∗ Q m a x ( s ′ , a ′ ; θ ′ ) r + γ* Q_{max}(s',a';θ') r+γ∗Qmax(s′,a′;θ′) 之间的输入 ( s , a ) (s,a) (s,a)对 是不同的,根据贝尔曼方程,网络训练的目的是使这两个值越接近越好,而不是要使得当前Q网络与target Q网络变得接近(这两个网络初始就是一样的,如果训练的目的是使得这两个网络接近,那一开始就没有训练意义了)。
过程描述:初始化当前Q网络t和target Q网络,根据损失函数从而更新当前Q网络的参数,而target Q网络的参数则固定不变,在经过多次迭代之后,将当前Q网络的参数全部复制给target Q网络(硬更新),并一直如此循环迭代。这样一段时间内的 t a r g e t target target 是固定不变的,从而使得算法更新更加稳定。
【补充】
硬更新:将当前Q网络的参数完全复制给target Q网络
软更新:按照不同的比例分别 × × × 当前 Q网络的参数和target Q网络的参数,将两个乘积之和作为更新参数,赋值给target Q网络。 比如 ϕ t a r g e t = 0.95 × ϕ t a r g e t + 0.05 × ϕ 当前 Q 网络 \phi_{target} = 0.95 × \phi_{target} + 0.05 × \phi_{当前Q网络} ϕtarget=0.95×ϕtarget+0.05×ϕ当前Q网络

【补充】
① on-policy的算法:用于采集数据的策略与用于训练的策略是同一个策略,如Sarsa算法。
因为根据贝尔曼方程, Q π ( s , a ) = E π ( R t + 1 + γ Q π ( s t + 1 , a t + 1 ) ∣ s t = s , a t = a ) Q_{\pi}(s, a) = E_{\pi}(R_{t + 1} + \gamma Q_{\pi}(s_{t + 1}, a_{t + 1}) |s_t = s, a_t = a) Qπ(s,a)=Eπ(Rt+1+γQπ(st+1,at+1)∣st=s,at=a),当前动作价值函数值的推导需要用到后续动作价值函数的期望,而后续动作价值函数的期望是由 “即时奖励 + 奖励衰减因子 × × × 所有可能出现的下一状态的概率 × × × 该下一状态的状态价值” 计算得到的,其中,下一状态出现的概率与策略 π \pi π 相关,当策略发生变化时,当前Q值的估计就会出现较大的误差。因此,这就要求采集数据的策略与用于训练的策略是同一个策略。
那为何DQN可以off-policy而不考虑误差问题?
因为DQN参数更新用的是 Q m a x Q_{max} Qmax ,对于不同策略来说, Q m a x Q_{max} Qmax 值一般是相同的,因此可以无视采集数据的策略与用于训练的策略之间不同而导致的误差。
像Sarsa之类的on-policy算法 ,一般是先收集一个batch大小的 target值与当前Q值 ,然后将该batch大小的数据传入神经网络进行训练与参数更新。也就是说在一个batch内传入网络的采集数据来自当前要训练的网络,网络用该batch内收集的数据进行参数更新,参数更新完后,之前收集的batch大小数据就不要了,重新采集数据,这就保证了采集数据的策略与用于训练的策略在每个batch内都是相同的。
② off-policy的算法:用于采集数据的策略与用于训练的策略的不是同一个策略,如 Q-Learning。这种算法通常用到经验回放池来保存很久之前收集到的数据。
③ 介于两者之间的算法:如PPO算法等采用了重要性采样的算法。该类算法一般是先收集batch大小的数据,然后利用该batch数据进行多次参数更新,那么第一次参数更新时,算法是on-policy的,因为采集数据的策略和用于训练的策略是同一个策略。当利用之间收集的batch数据进行第二次参数更新时,由于网络参数在第一次更新时已经发生了改变,这就导致此时采集数据的策略和用于训练的策略不是同一个策略了,此时属于off-policy,但由于batch大小的数据远比经验回放池的容量小,而且用于参数更新的数据也不会出现像经验池那样很久之前的数据,这就使得算法也不完全像off-policy,因此介于两者之间。
DQN为什么要用两个网络?
① 从训练稳定性的角度:
因为算法更新的目标是让Q估计 Q ( s , a ; θ ) Q(s,a;θ) Q(s,a;θ) 逼近Q现实 r + γ ∗ Q m a x ( s ′ , a ′ ; θ ′ ) r + γ* Q_{max}(s',a';θ') r+γ∗Qmax(s′,a′;θ′),由于TD误差目标本身就包含神经网络的输出,因此在更新网络参数的同时目标也在不断地改变,这非常容易造成神经网络训练的不稳定性。因此,需要先将TD误差目标中的 Q 网络固定住,防止目标不断变化。
② 从训练收敛性的角度:
通常来说,用一个Q网络就可以求出所有的值并进行更新(比如Q-Learning),用一个网络时,网络训练的误差会比较小,但Q估计与Q现实之间会有相关性。
由于DQN引入了神经网络,神经网络一般要求输入数据之间独立同分布,如果只用一个网络,Q估计与Q现实是用同一个网络算出来的,相关性很大,这就使得网络会难以收敛。因此用一个target固定网络来帮助训练,加快收敛,但这种方式也会导致网络训练中Q现实的计算误差比较大(因为用的是之前几步没更新的网络得到的结果)。
但是Q-learning也用到了TD误差,为啥它只用一个网络就行?
因为Q-learning没用到神经网络,是表格型value based方法,每次更新时只改变表格中的当前状态的Q值 Q ( s , a ; θ ) Q(s,a;θ) Q(s,a;θ),对其他值没有影响。而DQN用到的是神经网络,每次更新参数时,神经网络整体都会受到影响,因此所有的Q估计值和Q现实都会受到影响而改变,这就使得网络训练会很不稳定。
四、DQN算法总结
基于ε-贪心来执行动作(探索),用于存储动作-状态-价值信息(经验回放),存储完成之后,以batch的形式获取数据,根据贝尔曼方程,利用target网络得到的目标值,进行当前网络Q函数的训练,来使Q估计 Q ( s , a ; θ ) Q(s,a;θ) Q(s,a;θ) 逼近Q现实 r + γ ∗ Q m a x ( s ′ , a ′ ; θ ′ ) r + γ* Q_{max}(s',a';θ') r+γ∗Qmax(s′,a′;θ′),然后设定一个C步更新,每C步就更新target网络参数。

DQN与Q-Learning 的区别:
整体来说,DQN 与 Q-Learning 的目标价值以及价值的更新方式都非常相似,主要的不同点在于:
DQN将 Q-Learning与深度学习结合,用深度网络来近似动作价值函数,而 Q-Learning则是采用表格存储;DQN 采用了经验回放的训练方法,从replay buffer中的历史数据中随机采样,而 Q-Learning直接采用表格中下一个状态的数据进行学习。