Java stream api + lamda 基本使用
流基础知识
关于流的一些注意点
①Stream自己不会存储元素。
②Stream不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream操作是延迟执行的。这意味着他们会等到需要结果的时候才执行
流的创建
- Stream.of()
String[] strs = new String[3];
strs[0] = "aaa";
strs[1] = "bbb";
strs[2] = "ccc";
// 基于数组
Stream<String> firstStream = Stream.of(strs);
// 基于可变参数
Stream<String> secondStream = Stream.of("aaa", "bbb", "ccc");
- Arrays.stream()
Stream<String> stream1 = Arrays.stream(strs);
// 取数组的一部分来创建一个流
Stream<String> stream2 = Arrays.stream(strs, 1, 2);
- Stream.empty()
// 空流其实我不太明白这个能在什么场景下用到
Stream<Object> empty = Stream.empty();
- Stream.generate() 创建一个无限流
// 控制台会一直输出
Stream<Object> generate = Stream.generate(() -> "demo");
generate.forEach(System.out::println);
// 一个随机数的无限流
Stream<Object> generate = Stream.generate(Math::random);
generate.forEach(System.out::println);
- Stream.iterate() 创建一个序列
// 一个无限的序列
Stream<BigInteger> iterate = Stream.iterate(BigInteger.ZERO, (n) -> n.add(BigInteger.ONE));
iterate.forEach(System.out::println);
- list.stream() 一个集合可以直接拿到流
List<String> list = Arrays.asList("1", "2", "3");
Stream<String> stream = list.stream();
- nio file
Stream<String> lines = Files.lines("E:\\demo.txt");
还有其它的一些可以得到流的方法,没有那么常用,感兴趣可以去看Java 核心技术卷 II 第一章
Stream 使用
- filter 过滤器
见名知意,就是对数据进行过滤,如下面的例子我要过滤字符串长度小于2的数据写法如下:
List<String> list = Arrays.asList("1", "22", "3");
List<String> collect = list.stream().filter(e -> e.length() < 2).collect(Collectors.toList());
System.out.println(JSONUtil.toJsonStr(collect));
- map 对里面的每一个元素进行操作 需要有返回值 操作之后这个元素可能变了,得到一个新元素的流. 下面的例子,我给每一个字段串增加了一个后缀suffix
List<String> list = Arrays.asList("1", "2", "3");
List<String> collect = list.stream().map(e -> e + "suffix").collect(Collectors.toList());
System.out.println(JSONUtil.toJsonStr(collect));

- flatmap 将多个流组合到一起变成一个,如果map操作返回的又是一个流就可以用flatmap 来替换map将它扁平化
public static void main(String[] args) {
List<String> list = Arrays.asList("today", "is a", "good", "day");
Stream<String> stream = list.stream().flatMap(StreamDemo::getStream);
List<String> collect = stream.collect(Collectors.toList());
System.out.println( JSONUtil.toJsonStr(collect));
}
// 构造一个流
public static Stream<String> getStream(String str) {
List<String> chars = new ArrayList<>();
char[] chs = str.toCharArray();
for (int i = 0; i < chs.length; i ++) {
chars.add(String.valueOf(chs[i]));
}
return chars.stream();
}
![]()
- limt 裁剪尺寸
还记得我前面有个无限流吗?如果我们需要得到一个有限的流就可以用这个方法,下面这这个例子就是只返回10个
List<Double> collect = Stream.generate(Math::random).limit(10).collect(Collectors.toList());
collect.forEach(System.out::println);
- skip 跳过前n个元素之外的元素
下面这个例子我们生成了10个随机数,但是最终我跳过了前5个数字,保留了后五个数字
List<Double> collect = Stream.generate(Math::random).limit(10).skip(5).collect(Collectors.toList());
collect.forEach(System.out::println);
- sorted 对元素进行排序
List<String> list = Arrays.asList( "33", "44", "55","11", "22","88");
// 对于数字和字符串一般自然序就可以,对于对象的话一般会自定义一个比较器
List<String> collect = list.stream().sorted(Comparator.naturalOrder()).collect(Collectors.toList());
collect.forEach(System.out::println);
// 根据字符串长度进行排序
List<String> list = Arrays.asList( "313", "4114", "51115","11", "22","888888");
List<String> collect = list.stream().sorted(Comparator.comparing(String::length)).collect(Collectors.toList());
collect.forEach(System.out::println);
- distinct 去重
List<String> list = Arrays.asList( "313", "4114", "51115","111", "111","888888");
List<String> collect = list.stream().distinct().collect(Collectors.toList());
collect.forEach(System.out::println);
- peek 产生一个流,有点类似于for循环
List<String> list = Arrays.asList("313", "4114", "51115", "111", "111", "888888");
List<String> newRes = new ArrayList<>();
list.stream().peek(e -> {
String str = e + "1" + "2" + "3";
newRes.add(str);
}).collect(Collectors.toList());
- max 与 min
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6);
Optional<Integer> max = integers.stream().max(Comparator.naturalOrder());
System.out.println(max.orElse(Integer.MAX_VALUE));
Optional<Integer> min = integers.stream().min(Comparator.naturalOrder());
System.out.println(min.orElse(Integer.MAX_VALUE));
- findFirst 从符合的条件的结果中取第一个
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6);
Optional<Integer> first = integers.stream().filter(e -> e % 2 == 0).findFirst();
System.out.println(first.orElse(null));
- findAny 从符合条件的结果中取任意一个
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6);
Optional<Integer> any = integers.stream().filter(e -> e % 2 == 0).findAny();
System.out.println(any.orElse(null));
- anyMatch allMatch noneMatch
List<Integer> integers = Arrays.asList(1, 3, 5, 7);
// 集合里面的元素是否全为奇数
boolean match = integers.stream().allMatch(e -> e % 2 != 0);
System.out.println(match);
List<Integer> secondIntegers = Arrays.asList(1, 2, 3, 5, 7);
// 集合里面是否存在偶数
boolean secondMatch = secondIntegers.stream().allMatch(e -> e % 2 == 0);
System.out.println(secondMatch);
// 是否全小于100
boolean b = secondIntegers.stream().noneMatch(e -> e > 100);
System.out.println(b);
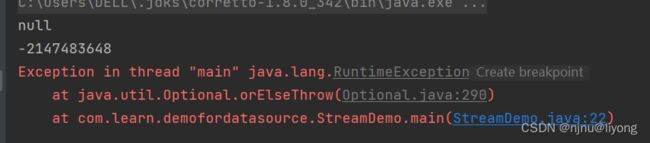
- Optional orElese orElseGet orElseThrow
List<Integer> integers = Arrays.asList(1, 3, 5, 7);
// 找偶数如果不存在返回null
Integer integer = integers.stream().filter(e -> e % 2 == 0).findFirst().orElse(null);
System.out.println(integer);
// 找偶数如果不存在返回Integer.MIN_VALUE
Integer res = integers.stream().filter(e -> e % 2 == 0).findFirst().orElseGet(() -> Integer.MIN_VALUE);
System.out.println(res);
// 找偶数如果不存在抛出异常
integers.stream().filter(e -> e % 2 == 0).findFirst().orElseThrow(RuntimeException::new);
- Optional 存在才消费
List<Integer> integers = Arrays.asList(1, 3, 5, 7);
List<Integer> result = new ArrayList<>();
// 取第一个奇数如果存在就添加到结果集中
integers.stream().filter(e -> e % 2 != 0).findFirst().ifPresent(result::add);
System.out.println(result.size());
- 创建optionnal 值
Optional<Integer> integer = Optional.of(10);
System.out.println(integer.orElse(0));
// 允许值为空
Optional<Object> o = Optional.ofNullable(null);
// 如果值为空 则会抛异常
Optional<Integer> domoNull = Optional.of(null);
收集结果
- itrator 得到流的一个迭代器 但是更常用的还是 forEach 方法
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6);
Iterator<Integer> iterator = integers.stream().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
- forEach
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6);
// 简单输出
integers.forEach(System.out::println);
// 做一些其它处理
integers.forEach(e -> {
System.out.println(e + "d");
});
- toArray
// 演示
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6);
Arrays.stream(integers.stream().filter(e -> e > 3).toArray()).forEach(System.out::println);
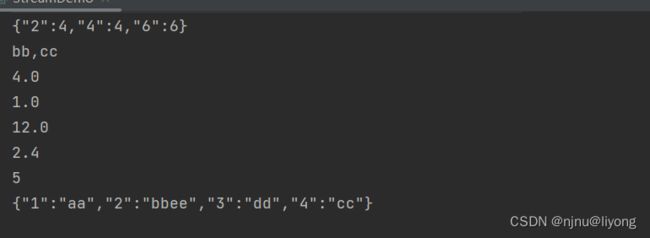
- collect
List<Integer> integers = Arrays.asList(1, 2,2, 3, 4, 5, 6);
// 收集为list
List<Integer> collect = integers.stream().filter(e -> e % 2 == 0).collect(Collectors.toList());
// 收集为set
Set<Integer> collect1 = integers.stream().filter(e -> e % 2 == 0).collect(Collectors.toSet());
// 第一个参数为key 第二个参为值 第三个参数为当key 冲突是怎么取值
// 下面的例子就是 以每个元素转换为字符串为key 以元素原本的值为value 如果key发生冲突则将这两个键值加到一起
Map<String, Integer> collect2 = integers.stream().filter(e -> e % 2 == 0).collect(Collectors.toMap(
String::valueOf, Function.identity(), (a, b) -> a + b
));
System.out.println(JSONUtil.toJsonStr(collect2));
List<String> strings = Arrays.asList("a", "bb", "cc");
// 用,连接元素
String collect3 = strings.stream().filter(e -> e.length() >= 2).collect(Collectors.joining(","));
System.out.println(JSONUtil.toJsonStr(collect3));
// 产生一个double 的统计 可以得到 最大最小 平均 和 数量等一系列属性
// 同时有summarizingInt summarizingLong 用法一模一样
DoubleSummaryStatistics collect4 = integers.stream().filter(e -> e < 5).collect(Collectors.summarizingDouble(Double::new));
System.out.println(collect4.getMax());
System.out.println(collect4.getMin());
System.out.println(collect4.getSum());
System.out.println(collect4.getAverage());
System.out.println(collect4.getCount());
toMap 更适用于对象,这个函数参数比较多,再举一个例子来演示怎么使用:
ArrayList<Foo> foos = new ArrayList<Foo>() {{
add(new Foo(1L, "aa"));
add(new Foo(2L, "bb"));
add(new Foo(2L, "ee"));
add(new Foo(3L, "dd"));
add(new Foo(4L, "cc"));
}};
// 以id作为key, bar作为value 当发生相同key 拼接到一起
Map<Long, String> collect5 = foos.stream().collect(Collectors.toMap(Foo::getId, Foo::getBar, String::concat));
String s = JSONUtil.toJsonStr(collect5);
System.out.println(s);
群组与分区
- groupingBy
ArrayList<Foo> foos = new ArrayList<Foo>() {{
add(new Foo(1L, "aa", "t1"));
add(new Foo(2L, "bb", "t2"));
add(new Foo(3L, "cc", "t2"));
add(new Foo(4L, "dd", "t2"));
add(new Foo(5L, "ee", "t1"));
add(new Foo(6L, "ff", "t2"));
}};
Map<String, List<Foo>> collect = foos.stream().collect(Collectors.groupingBy(Foo::getType));
System.out.println(JSONUtil.toJsonStr(collect));
}
![]()
- partitioningBy 也是分组一般是分两类 一类true 一类false 两个类型分类的时候更推荐用这个方法
ArrayList<Foo> foos = new ArrayList<Foo>() {{
add(new Foo(1L, "aa", "t1"));
add(new Foo(2L, "bb", "t2"));
add(new Foo(3L, "cc", "t2"));
add(new Foo(4L, "dd", "t2"));
add(new Foo(5L, "ee", "t1"));
add(new Foo(6L, "ff", "t2"));
}};
Map<Boolean, List<Foo>> collect = foos.stream().collect(Collectors.partitioningBy(e -> e.getType().equals("t1")));
System.out.println(JSONUtil.toJsonStr(collect));
}
![]()
下游收集器:
ArrayList<Foo> foos = new ArrayList<Foo>() {{
add(new Foo(1L, "aa", "t1"));
add(new Foo(2L, "bb", "t2"));
add(new Foo(3L, "cc", "t2"));
add(new Foo(4L, "dd", "t2"));
add(new Foo(5L, "ee", "t1"));
add(new Foo(6L, "ff", "t2"));
}};
// 下游收集器,对上游分组结果进行再处理
// 分组的key 不变只是对分组后的每个key 的数据列表做处理
Map<Boolean, Map<Long, Foo>> collect = foos.stream().collect(Collectors.partitioningBy(e -> e.getType().equals("t1")
, Collectors.toMap(Foo::getId, Function.identity(), (a, b) -> a)));
System.out.println(JSONUtil.toJsonStr(collect));
// 统计每个分组的数量
Map<Boolean, Long> counting = foos.stream().collect(Collectors.partitioningBy(e -> e.getType().equals("t1")
, Collectors.counting()));
System.out.println(JSONUtil.toJsonStr(counting));
// 统计每个分组的和
Map<String, Long> sum = foos.stream().collect(Collectors.groupingBy(Foo::getType
, Collectors.summingLong(Foo::getId)));
System.out.println(JSONUtil.toJsonStr(sum));
// 统计最大值, 返回的是id 最大的对应的对象
Map<String, Optional<Foo>> max = foos.stream().collect(Collectors.groupingBy(Foo::getType
, Collectors.maxBy(Comparator.comparing(Foo::getId))));
System.out.println(JSONUtil.toJsonStr(max));
运行结果:
{"false":{"2":{"id":2,"bar":"bb","type":"t2"},"3":{"id":3,"bar":"cc","type":"t2"},"4":{"id":4,"bar":"dd","type":"t2"},"6":{"id":6,"bar":"ff","type":"t2"}},"true":{"1":{"id":1,"bar":"aa","type":"t1"},"5":{"id":5,"bar":"ee","type":"t1"}}}
{"false":4,"true":2}
{"t1":6,"t2":15}
{"t1":"Optional[Foo(id=5, bar=ee, type=t1)]","t2":"Optional[Foo(id=6, bar=ff, type=t2)]"}
下面再看两个方法mapping 和 collectAndThen 两个方法 第一个首先是将数据直接传递给下游收集器,对数据做处理然后指定要收集为什么样的集合。 但是collectAndThen 不一样,它是先收集为集合,再计算与集合相关的属性,下面来看例子:
ArrayList<Foo> foos = new ArrayList<Foo>() {{
add(new Foo(1L, "aa", "t1"));
add(new Foo(2L, "bb", "t2"));
add(new Foo(3L, "cc", "t2"));
add(new Foo(4L, "dd", "t2"));
add(new Foo(5L, "ee", "t1"));
add(new Foo(6L, "ff", "t2"));
}};
// 它的含义是 先将集合根据type分组 然后收集为set 然后取收集后set的size 就是统计每个分组的数量说白了
Map<String, Object> collect = foos.stream().collect(Collectors.groupingBy(Foo::getType, Collectors.collectingAndThen(Collectors.toSet(), Set::size)));
System.out.println(JSONUtil.toJsonStr(collect));
// 分组后取第一个
Map<String, Object> collect1 = foos.stream().collect(Collectors.groupingBy(Foo::getType, Collectors.collectingAndThen(Collectors.toList(), e -> e.get(0))));
System.out.println(JSONUtil.toJsonStr(collect1));
结果:
{"t1":2,"t2":4}
{"t1":{"id":1,"bar":"aa","type":"t1"},"t2":{"id":2,"bar":"bb","type":"t2"}}
再来看mapping
ArrayList<Foo> foos = new ArrayList<Foo>() {{
add(new Foo(1L, "aa", "t1"));
add(new Foo(2L, "bb", "t2"));
add(new Foo(3L, "cc", "t2"));
add(new Foo(4L, "dd", "t2"));
add(new Foo(5L, "ee", "t1"));
add(new Foo(6L, "ff", "t2"));
}};
// 先分组 随后对分组后的每个元素 取bar 属性, 最后放到list里面
Map<String, List<String>> collect = foos.stream().collect(Collectors.groupingBy(Foo::getType, Collectors.mapping(Foo::getBar, Collectors.toList())));
System.out.println(JSONUtil.toJsonStr(collect));
{"t1":["aa","ee"],"t2":["bb","cc","dd","ff"]}
reduce
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
int sum = integers.stream().mapToInt(Integer::valueOf).sum();
System.out.println("sum1 : " + sum);
// 指定初始值
Integer reduce = integers.stream().reduce(0, (a, b) -> a + b);
System.out.println("sum2 : " + reduce);
// 不指定初始值
Optional<Integer> reduce1 = integers.stream().reduce((a, b) -> a + b);
System.out.println("sum3 : " + reduce1.get());
基本类型
IntStream,LongStream,DoubleStream
提供了一列的方法,例如sum 和 统计
int sum = IntStream.range(1, 10).sum();
int max = IntStream.range(1, 10).summaryStatistics().getMax();
并行流
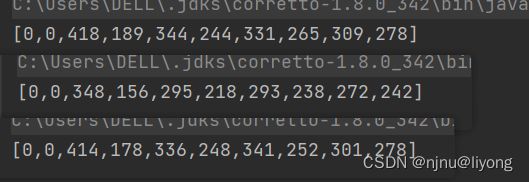
使用并行流需要注意,并行的执需要注意线程安全问题,要么在不涉及操作同一个变量,要么加锁。
错误示范:
demo.txt 里面是长度为0-20字符串,总计1万个。我们统计了小于10的字符串数量,可以看到三次运行结果都不一样,因为并行的时候计数的数组不是线程安全的,所以并行的时候要注意线程安全问题。
int shortWords[] = new int[10];
String s = FileUtil.readString(new File("E:\\demo.txt"), "utf-8");
String substring = s.substring(1, s.length() - 2);
s = substring;
String[] split = s.split(",");
List<String> strings = Arrays.asList(split);
strings.parallelStream().forEach(it -> {
if (it.length() < 10) {
shortWords[it.length()] ++;
}
});
System.out.println(JSONUtil.toJsonStr(shortWords));