【分布式技术专题】「分布式技术架构」MySQL数据同步到Elasticsearch之N种方案解析,实现高效数据同步
MySQL数据同步到Elasticsearch之N种方案解析,实现高效数据同步
- 前提介绍
- MySQL和ElasticSearch的同步双写
-
- 优点
- 缺点
-
- 针对于缺点补充优化方案
- MySQL和ElasticSearch的异步双写
-
- 优点
- 缺点
- 定时延时写入ElasticSearch数据库机制
-
- 优点
- 缺点
- 开源和成熟的数据迁移工具选型
-
- Logstash组件同步数据机制
-
- Logstash是什么
- 配置过程
-
- **配置Logstash的input插件**
- **配置Logstash的filter插件**
- **配置Logstash的output插件**
- 启动Logstash并确认同步
- Elasticsearch JDBC同步数据
-
- Elasticsearch JDBC插件
-
- 安装Elasticsearch和JDBC插件
-
- 安装JDBC插件
- 验证插件安装
- 配置JDBC插件
-
- JDBC配置选项
- 配置Elasticsearch的mapping和index
- 启动JDBC插件并同步数据
- Elasticsearch JDBC插件同步的问题
- 使用Canal进行数据同步
-
- Canal的原理分析
- 主要流程如下
- 配置安装流程
-
- 安装Canal和Elasticsearch
- 配置Canal
-
- 创建Canal的实例
- 配置Canal的规则
- 配置Canal的filter插件
-
- 配置Canal的步骤
-
- 设置数据库的正则表达式,用于匹配需要同步的数据库
- 设置表的正则表达式,用于匹配需要同步的表
- 配置Canal的output插件
-
- 配置流程
- 使用Debezium同步数据
-
- 配置Debezium的同步体系的流程
-
- 配置Debezium
- 配置Kafka
- 配置Logstash
- 配置Elasticsearch
- 配置Debezium连接到MySQL
- 配置Debezium发送到Kafka
- 配置Logstash发送到Elasticsearch(可选)
前提介绍
在现代数据处理中,将MySQL数据同步到Elasticsearch(ES)是一项常见的任务。本文将深入分析MySQL数据同步到ES的四种常见解决方案,并为您提供详细的解释和比较。无论您是使用Logstash、MySQL binlog、MySQL插件还是开源工具,我们将为您提供深入的技术分析和实现细节。通过本文,您将了解每种方案的优缺点、适用场景以及如何选择最适合您需求的方案。让我们一起探索如何实现高效的MySQL数据同步到Elasticsearch!

MySQL和ElasticSearch的同步双写
MySQL数据同步到Elasticsearch(ES)的双写机制是一种常见的数据处理方式,用于确保MySQL和ES之间的数据一致性。通过这种双写机制,可以确保MySQL和ES之间的数据保持一致性,使得应用程序可以同时从MySQL和ES中获取准确的数据。

-
第一步:数据写入MySQL:应用程序将数据写入MySQL数据库,确保数据在MySQL中持久化。
-
第二步:数据同步到ES:触发器或存储过程将数据同步到ES,可以使用适当的工具或自定义脚本来实现数据同步,通过调用ES的API将数据插入、更新或删除到ES中。
注意,由于异步的特性,可能会导致主备数据不一致的情况发生。
优点
- 业务逻辑简单:MySQL数据同步到Elasticsearch的双写机制相对简单,易于实现和维护。
- 实时性高:通过双写机制,可以实现MySQL和Elasticsearch之间的实时数据同步,保持数据的及时性。
缺点
- 硬编码:需要在每个需要写入MySQL的地方都添加写入Elasticsearch的代码,导致代码的耦合性增加。
- 业务强耦合:双写机制使得业务与Elasticsearch强耦合,增加了系统的复杂性和维护成本。
- 存在双写失败丢数据风险:如果写入MySQL成功但写入Elasticsearch失败,可能会导致数据不一致或丢失的风险。
- 性能较差:由于双写机制需要同时写入MySQL和Elasticsearch,会增加系统的负载和延迟,导致性能下降。
针对于缺点补充优化方案
- 解耦业务:将MySQL和Elasticsearch的写入操作解耦,使用消息队列或异步任务来处理Elasticsearch的写入,减少对业务代码的侵入。
- 性能优化:通过优化MySQL和Elasticsearch的配置、增加硬件资源或使用缓存等手段,提升系统的性能,减少性能下降的影响。
MySQL和ElasticSearch的异步双写
通过上面说的解耦业务,因此我们可以通过消息队列(MQ)来实现异步的多源写入,就作为了异步双写。异步双写是指在主库上进行数据修改操作时,将数据异步写入备库。这种方式可以降低主库的写入延迟,并且备库出现问题时不会影响主库的性能。
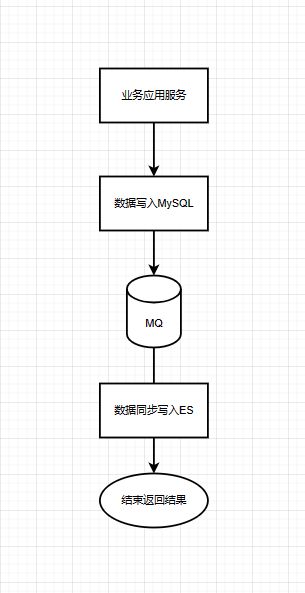
通过借助消息队列实现异步的多源写入,可以提高系统的性能、可扩展性和可靠性,同时降低数据源之间的耦合度。这种方案适用于需要将数据写入到多个数据源的场景,如日志记录、数据同步和数据分发等。
优点
-
高性能:通过使用消息队列,应用程序可以将数据异步地发送到消息队列中,而不需要等待数据写入到多个数据源。通过使用消息队列(MQ)进行异步写入,可以提高系统的吞吐量和响应速度
-
解耦和扩展性:使用消息队列可以将数据源之间的耦合度降低,使得应用程序更加灵活和可扩展。可以根据需要增加或减少数据源,而不需要修改应用程序的代码。
-
容错和可靠性:消息队列通常具有持久化和消息重试机制,可以确保数据的可靠传输和处理。即使某个数据源不可用,数据仍然可以在消息队列中等待处理。
-
异构数据源支持:通过使用消息队列,可以将数据写入到不同类型的数据源,如关系型数据库、NoSQL数据库或其他存储系统,从而实现异构数据源的支持。
注意,使用消息队列进行异步写入需要考虑一些因素,如消息队列的性能、消息的顺序性和一致性等。此外,需要确保消息队列和数据源之间的数据一致性,并处理可能出现的错误和异常情况。
缺点
-
硬编码问题:接入新的数据源需要实现新的消费者代码,这可能增加开发和维护的复杂性。
-
系统复杂度增加:引入了消息中间件,增加了系统的复杂性和部署的难度。
-
延时控制:由于MQ是异步消费模型,用户写入的数据不一定能立即在ES中看到,可能会造成一定的延时。
定时延时写入ElasticSearch数据库机制
上面两种方案在处理MySQL数据同步到Elasticsearch,开发以及硬编码问题会导致代码的侵入性过强。如果对实时性要求不高,可以考虑使用定时器来处理数据同步。

-
在数据库表中添加一个名为timestamp的字段,该字段会在任何CURD操作发生时自动更新。
-
原有的程序中的CURD操作保持不变。
-
添加一个定时器程序,定期扫描指定的表,并提取在指定时间段内发生变化的数据。
-
将提取的数据逐条写入到Elasticsearch中,以保持数据的同步性。
注意,由于定时器的方式是异步的,所以对于实时性要求较高的场景可能不适用。但对于一些不需要实时同步的情况,定时器方案可以提供一种简单有效的数据同步方式。
优点
通过这种方式,可以避免对原有程序进行大量修改,减少硬编码的问题。定时器程序可以根据需求设置合适的时间周期,将变化的数据同步到Elasticsearch中。
缺点
定时任务是指在固定的时间点或时间间隔内将主库中的数据同步到备库中。这种方式可以避免主库的写入延迟,同时保证备库中的数据与主库中的数据一致,但是可能会存在备库中数据的滞后问题。
开源和成熟的数据迁移工具选型
当开发时间比较紧张,以及针对于开发的进度要求必须快速落地的时候,那么我们是没有那么多的时间去设计和开发迁移组件的,那么这个时候我们就需要寻找站在巨人的肩膀上去实现和使用了,我们去
Logstash组件同步数据机制
Logstash是什么
Logstash是一种出色的开源数据收集引擎,能够从各种不同的来源(如MySQL)高效地采集数据,并将其转换为Elasticsearch可索引的格式。
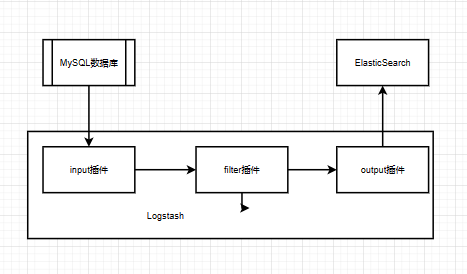
配置过程
首先,你需要根据你的操作系统,下载并安装Logstash和Elasticsearch。可以从官方网站或软件包管理器获取安装程序。配置对应的Logstash的插件配置信息:input插件、filter插件和output插件。
配置Logstash的input插件
在Logstash的配置文件中,你需要指定一个input插件,用于从MySQL读取数据。例如,可以使用jdbc插件来连接MySQL数据库。在配置文件中,你需要提供数据库的连接信息,例如主机、端口、数据库名称、用户名和密码,以及要读取的数据表和字段。
配置Logstash的filter插件
接下来,你需要配置filter插件来转换数据格式。可以通过添加filter插件来实现各种转换规则和筛选条件。例如,你可以使用mutate过滤器来对字段进行重命名、删除或重新格式化。还可以使用grok过滤器来解析复杂的日志行。根据你的需求,可以添加多个filter插件到配置文件中。
配置Logstash的output插件
最后,你需要配置output插件,以将转换后的数据发送到Elasticsearch。为此,你需要指定Elasticsearch的连接信息,如主机、端口和索引名称。可以使用elasticsearch插件作为output插件。根据需要,你还可以设置其他选项,例如数据批处理大小、并发请求数量等。
启动Logstash并确认同步
保存并关闭Logstash的配置文件后,可以通过运行Logstash来启动同步过程。可以使用命令bin/logstash -f 来运行Logstash,其中
Elasticsearch JDBC同步数据
Elasticsearch JDBC插件
Elasticsearch JDBC插件是一种强大的工具,可以将MySQL数据导入到Elasticsearch中实现数据同步。该插件通过JDBC连接器从MySQL数据库中提取数据,并将其转换为Elasticsearch文档格式,然后将这些文档插入到Elasticsearch索引中。

安装Elasticsearch和JDBC插件
首先,确保你已经安装了Elasticsearch,并根据操作系统配置好相关环境。接下来,通过Elasticsearch的插件管理命令来安装JDBC插件,以便能够使用JDBC连接器。
安装JDBC插件
使用插件管理命令来安装JDBC插件。命令可能类似于elasticsearch-plugin install ,其中
验证插件安装
完成插件安装后,可以通过运行以下命令来验证插件是否成功安装:
bin/elasticsearch-plugin list
此命令将显示已安装的插件列表,你应该能够在列表中找到刚刚安装的JDBC插件。
配置JDBC插件
在Elasticsearch的配置文件中,你需要指定JDBC插件的连接信息,如MySQL数据库的主机、端口、数据库名称、用户名和密码。此外,你还可以配置其他JDBC插件选项,如表过滤、列选择等。通过这些配置,JDBC插件将能够从MySQL读取数据。
JDBC配置选项
一旦配置完成并重启Elasticsearch,JDBC插件将会使用你指定的连接信息从MySQL数据库中读取数据,并将其同步到Elasticsearch中。
-
打开Elasticsearch的配置文件:使用文本编辑器打开Elasticsearch的配置文件,其路径通常为
/config/elasticsearch.yml -
配置JDBC插件的连接信息:在配置文件中找到JDBC插件相关的配置项,一般以
jdbc.开头。根据你的MySQL数据库的连接信息,进行如下配置:jdbc.driver: 设置MySQL的JDBC驱动类名,例如com.mysql.cj.jdbc.Driver。jdbc.url: 设置MySQL数据库的连接URL,包含主机、端口和数据库名称等信息。jdbc.user和jdbc.password: 设置连接MySQL数据库所需的用户名和密码。
-
配置其他选项(可选):根据你的需求,还可以配置其他选项来进一步调整JDBC插件的行为。例如,你可以设置表过滤器(
jdbc.sql)来选择你要读取的特定表,或者指定列选择(jdbc.columns)来限制读取的数据列。
注意,重启Elasticsearch,在修改配置文件后,重启Elasticsearch以使配置生效。你可以通过运行相应的启动命令或使用启动脚本来重启。
配置Elasticsearch的mapping和index
在Elasticsearch中,定义Mapping和Index是为了正确地索引从MySQL读取的数据。Mapping用于定义数据字段的类型和属性,而Index则用于定义数据索引的方式。根据数据的结构,你需要创建并配置适当的Mapping和Index,以确保数据被正确地索引到Elasticsearch中。
启动JDBC插件并同步数据
启动Elasticsearch后,你可以通过运行JDBC插件来启动同步过程。
JDBC插件将连接到MySQL数据库,并将数据以Elasticsearch可索引的形式发送到Elasticsearch。你可以使用JDBC插件的命令行工具或API来启动同步,并监视同步的进展和状态。
Elasticsearch JDBC插件同步的问题
使用Elasticsearch JDBC插件同步MySQL和ES的好处是它非常易于设置,并且能够高效地处理大量数据。然而,需要注意的是它可能会对MySQL的性能产生一定的影响,并且无法处理复杂的数据转换。
使用Canal进行数据同步
Canal是阿里巴巴开源的一个MySQL数据库增量数据同步工具。通过解析MySQL的binlog日志,Canal能够捕获并获取增量数据,然后将这些数据发送到指定的位置,包括Elasticsearch(ES)。
使用Canal同步MySQL和Elasticsearch的好处在于它能够处理大量数据,并且提供灵活的数据转换能力。
Canal的原理分析
Canal是一种基于数据库增量日志解析的工具,它提供了增量数据的订阅和消费功能,并主要支持MySQL数据库。Canal的工作原理是通过伪装成MySQL的从节点,来订阅并获取MySQL主节点的Binlog日志。
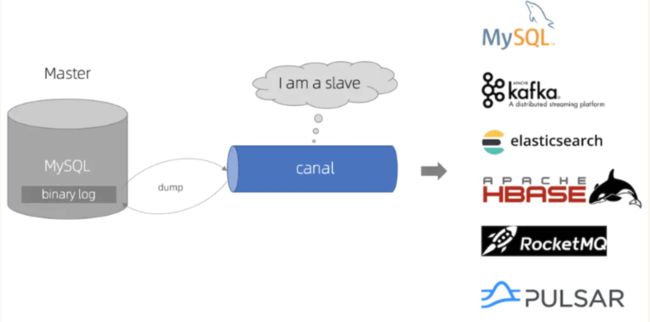
主要流程如下
-
Canal服务端与MySQL的主节点建立连接,并发送dump协议请求。
-
MySQL的主节点接收到dump请求后,开始将Binlog日志推送给Canal服务端。Canal服务端会解析这些Binlog日志,将其转换成可读的JSON格式。
-
Canal客户端通过TCP协议或消息队列(MQ)的形式监听Canal服务端,并从中同步获取数据。一旦数据被获取,它可以被进一步处理和存储,例如同步到Elasticsearch(ES)中。
配置安装流程
安装Canal和Elasticsearch
开始之前,请确保Canal和Elasticsearch已经正确地安装并配置在你的系统中。
配置Canal
在Canal的配置中,你需要提供MySQL的连接信息以及增量日志同步的规则。通过这些配置,Canal能够与MySQL建立连接并读取增量日志。
创建Canal的实例
在Canal的服务端中,执行canal.deployAll.sh脚本命令,根据实际需求设置Canal的实例名称、MySQL主节点的IP地址和端口等参数。
配置Canal的规则
在Canal的实例目录中,打开instance.properties文件,根据你的MySQL数据库实例进行配置,包括MySQL的连接信息(主机、端口、用户名、密码等)。
配置Canal的filter插件
Canal的filter插件可以将增量日志转换为JSON格式。你可以根据需求设置过滤规则,选择需要同步的特定数据,并将其转换为符合你需求的JSON格式。
配置Canal的步骤
-
打开Canal的配置文件:使用文本编辑器打开Canal的配置文件,其路径通常为
-
查找并配置filter插件:在配置文件中找到名为 canal.instance.filter.* 的相关配置项。这些配置项控制着filter插件的行为,可以根据你的需求进行配置。
-
配置过滤规则:根据你需要过滤的数据,可以使用正则表达式来设置过滤规则。可用的过滤规则包括数据库名、表名、字段名等。
设置数据库的正则表达式,用于匹配需要同步的数据库
canal.instance.filter.database.regex=^(db1|db2)$
设置表的正则表达式,用于匹配需要同步的表
canal.instance.filter.table.regex=^(tbl1|tbl2)$
根据上面的案例,只有数据库名为db1或db2,且表名为tbl1或tbl2的数据才会被同步到Elasticsearch。
注意,配置filter插件需要谨慎操作,确保符合你的具体需求,并避免过滤掉必要的数据。记得重启Canal服务以使配置生效。
配置Canal的output插件
通过配置Canal的output插件,你可以将转换后的JSON格式增量日志发送到Elasticsearch。在配置output插件时,你需要提供Elasticsearch的连接信息以及索引的名称,确保增量日志能够准确地发送到Elasticsearch中。
配置流程
-
打开Canal的配置文件:使用文本编辑器打开Canal的配置文件,通常可以在
-
查找并配置output插件:在配置文件中,找到名为 canal.instance.customize.properties 的配置项,并在这里添加output插件的相关配置。如果该配置项不存在,可以手动添加。
添加以下配置项来启用Elasticsearch的output插件:
canal.instance.customize.properties = esIndex:my_index, esType:my_type, esClusterName:my_cluster, esAddresses:localhost:9200
在上面的示例中,配置了如下参数:
- esIndex:要发送数据的Elasticsearch索引名称。
- esType:要发送数据的Elasticsearch类型名称。(ElasticSearch6以上可以忽略)
- esClusterName:Elasticsearch集群的名称。
- esAddresses:Elasticsearch集群的地址,以逗号分隔。
注意,配置output插件需要确保能够正确连接到Elasticsearch集群,并确保所配置的索引、类型等参数与Elasticsearch的配置相匹配。
使用Debezium同步数据
Debezium是一种开源的分布式平台,用于捕获数据库更改并将其以流式传输的方式发送到消息代理或存储。对于MySQL数据库,Debezium可以捕获其变更,并将其发送到Kafka消息代理,最后可以使用Logstash或其他工具将数据发送到Elasticsearch。
配置Debezium的同步体系的流程
安装Debezium、Kafka、Logstash和Elasticsearch:首先,确保你已经正确地安装和配置了Debezium、Kafka、Logstash和Elasticsearch。根据你的系统环境,选择适合的版本进行安装。
配置Debezium
配置Debezium:在Debezium的配置文件中,设置连接到MySQL数据库的相关信息。配置Debezium的任务,指定要捕获的数据库和表,以及要发送到Kafka的主题。
配置Kafka
配置Kafka的相关参数,包括主题、分区数和副本数等。确保Debezium可以将捕获的MySQL更改发送到Kafka中。
配置Logstash
在Logstash的配置文件中,设置从Kafka中读取Debezium数据并将其转换为Elasticsearch可索引的格式。根据数据结构,可以定义映射和字段类型等配置。
配置Elasticsearch
在Elasticsearch中,创建适当的索引,并定义字段映射。确保索引的设置符合数据的结构和需求。
之后启动服务并监控同步过程:启动Debezium、Kafka、Logstash和Elasticsearch服务,并监控同步过程,确保MySQL的更改能够同步到Elasticsearch中。
配置Debezium连接到MySQL
在Debezium的配置文件中,你需要提供MySQL的连接信息,例如主机名、端口、用户名和密码等。这样,Debezium可以与MySQL数据库建立连接,并实时捕获数据库的变更。
配置Debezium发送到Kafka
将配置修改为将捕获的数据库变更发送到Kafka消息代理。你需要指定Kafka的连接信息,包括主机名、端口和topic等。这将使得数据库变更以更易处理的方式被发送到Kafka上。
配置Logstash发送到Elasticsearch(可选)
如果你想要将数据从Kafka发送到Elasticsearch,你可以使用Logstash或其他ETL工具来实现。在Logstash配置文件中,你需要指定Kafka和Elasticsearch的连接信息,并定义数据的处理和映射规则。
本文旨在介绍MySQL和其他多维数据同步方案,并提供一些常用的数据迁移工具,以帮助你做出更合适的选择。