Redis原理篇——五种基本数据类型
一、Redis底层数据结构
1. SDS
获取字符串长度耗时: 由于Redis底层是C语言编写的,C语言中没有字符串这个概念,本质上都是字符数组,获取字符串长度就是遍历数组获取长度(遍历到 '\0'结束标识结束 )时间复杂度O(N)比较耗时
非二进制安全: 不能出现特殊字符 比如转义字符 '\0'
不可修改: 直接通过字面值定义的字符串,字符数组的长度固定,如果要修改需要重新申请空间,比较麻烦
Redis构建了一个新的字符串结果,称为简单动态字符串SDS
struct __attribute__((__packed__)) sdshdr8{
uint8_t len; // buf已保存的字符串字节数,不包含结束标示
uint8_t alloc; //buf 申请的总的字节数,不包含结束标示
unsigned char flags; // 不同SDS的头类型,用来控制SDS的头大小(8 16 32 64位 不同sds)
char buf[]; // 字符数组
};
uint8_t 无符号整型8位 范围(0 ~ 255)
注: Redis实现SDS使用了多个此格式的结构体 来表示不同编码格式的字符串
如:一个"name" 的sds结构:

动态扩容:
如果给一个SDS追加一段字符串,首先会申请新的内存空间
- 假如新字符串小于1M,则新空间为扩展后字符串长度的两倍+1
- 如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。
+1 是给结束标识的 '\0'
内存预分配 :减少内存分配的频率,(申请内存需要从用户态切换用户态)提高性能
优点:
- 获取字符串长度的时间复杂度为O(1)
- 支持动态扩容
- 减少内存分配次数
- 二进制安全(支持 图片、音频、视频存储)
2.IntSet
IntSet是Redis中Set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、元素唯一有序特性。
typedef struct intset{
uint32_t encoding; // 编码方式,支持16位、32位、64位
uint32_t length; // 元素个数
int8_t contents[]; // 整数数组,保存集合数据
}intset;
为方便查找,Intset中的所有整数按照升序依次保存在contents数组中
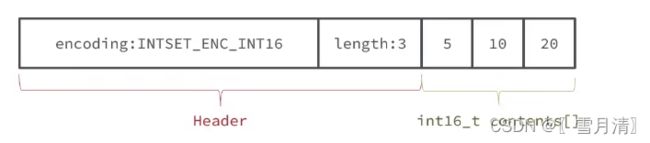
如果元素所占总空间超过编码范围,Intset会自动升级编码方式,并按照新的编码方式及元素个数扩容数组。
倒序依次将数组中的语速拷贝到扩容后的正确位置(防止覆盖)
适用于数量少的情况
3.Dict
键值映射关系,Dict由三部分组成:哈希表(DictHashTable)、哈希结点(DictEntry)、字典(Dict)
typedef struct dictht {
// entry数组 数组中保存的是指向entry的指针
dictEntry **table;
// 哈希表的大小 2的n次方
unsigned long size;
// 哈希表大小的掩码,size -1
unsigned long sizemask;
// entry 个数
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key; //键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值
// 下一个Entry的指针
struct dictEntry *next;
} dictEntry;
当向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用h & sizemask 来计算元素应该存储到数组中的哪个索引位置
typedef struct dict {
dictType *type; // dict 类型,内置不同hash函数
void *privdata; // 私有数据,在做特殊hash运算时使用
dictht ht[2]; // 一个Dict包含两个哈希表,其中一个时当前数据,另一个一般是空,rehash时使用
long rehashidx; /* rehash的进度, -1表示未进行 0表示开始rehash */
int16_t pauserehash; /* rehash是否暂停,1暂停,0继续 */
} dict;
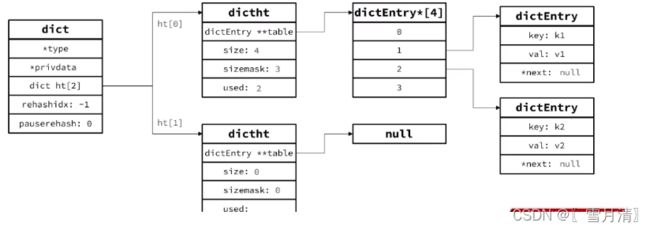
Dict的扩容
Dict中的HashTable就是数组+单向链表实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长则查询效率大大降低
Dict在每次新增键值对都会检查负载因子 (LoadFactor = used / size),以下两种情况会进行哈希扩容
- 哈希表的
LoadFactor >= 1, 并且服务器没有执行BGSAVE或者BGREWRITEAOF等后台进程 (CPU空闲) - 哈希表的
LoadFactor > 5
当删除元素时,也会对负载因子做检查,小于0.1时,会做哈希表收缩
扩缩容策略:渐进式rehash
- 计算新hash表的size,值取决于当前要做的是扩容还是收缩:
-
如果是扩容,则新size为第一个大于等于
dict.ht[0].used + 1的2^n -
如果是收缩, 则新size为第一个大于等于
dict.ht[0].used的2^n(不得小于4)
-
按照新的size申请内存空间, 创建dictht, 并赋值给dict.ht[1]
-
设置
dict.rehashidx = 0,标示开始rehash -
每次执行新增、查询、修改、删除操作时,都检查一下
dict.rehashidx是否大于-1, 如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++。直至dict.ht[0]的所有数据都rehash到dict.ht[1] -
将dict.ht[1]赋值给dict.ht[0], 给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
-
将rehashidx赋值为-1, 代表rehash结束
-
在rehash过程中, 新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1 ]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
字典使用指针,内存不连续,可能产生大量内存锁片,且大量指针比较浪费空间
4.ZipList
是一种双端链表,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/ 弹出操作,并且该操作的时间复杂度为O(1)

ZipList中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用
previous_ entry_ length encoding contents
-
previous_ entry_ length: 前一 节点的长度,占1个或5个字节。- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为
0xfe,后四个字节才是真实长度数据
-
encoding: 编码属性,记录content的数据类型( 字符串还是整数)以及长度,占用1个、2个或5个字节 -
contents: 负责保存节点的数据,可以是字符串或整数
通过这三个属性来进行遍历

ZipList的连锁更新问题,因为每个节点都会保存前一个结点的长度,如果新加的一个节点长度大于254字节,那么后面的结点记录的前一个结点长度占5个字节,此时假如这个结点+5字节后 超过了254字节,继续影响下一个结点,产生连锁更新问题。频繁申请空间了,影响性能
5.QuickList
ZipList虽然节省了内存,但是申请内存必须是连续空间,如果内存占用较多,申请内存效率很低
使用多个ZipList来分片存储数据
QuickList相当于使用一个双端链表将多个ZipList 挂起
list-max-ziplist-size 来限制ZipList中entry的个数 (参数为正表示个数,负表示占用内存)
- -1 每个ziplist的内存占用不超过4kb
- -2 每个ziplist的内存占用不超过8kb
- -3 每个ziplist的内存占用不超过16kb
- -4 每个ziplist的内存占用不超过32kb
- -5 每个ziplist的内存占用不超过64kb
list-compress-depth 来控制对节点ziplist压缩
-
0不压缩
-
1 首位各有1个节点不压缩,中间节点压缩
-
2 首位各有2个节点不压缩,中间节点压缩
typedef struct quicklist {
quicklistNode *head; // 头结点指针
quicklistNode *tail; // 尾结点指针
unsigned long count; /* 所有ziplist中entry的数量 */
unsigned long len; /* ziplist的总数量 */
int fill : QL_FILL_BITS; /* ziplist的entry上限,默认-2 */
unsigned int compress : QL_COMP_BITS; /* 首位不压缩的节点数量 */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {
// 前一个节点指针
struct quicklistNode *prev;
// 后一个节点指针
struct quicklistNode *next;
// 当前节点的ziplist指针
unsigned char *zl;
unsigned int sz; // 当前节点的ziplist的字节大小
unsigned int count : 16; /* 当前ziplist的entry个数 */
unsigned int encoding : 2; /* 编码方式 1 ziplist 2 lzf压缩模式 */
unsigned int container : 2; /* 数据容器类型 1其他 2 ziplist */
unsigned int recompress : 1; /* 是否被解压缩,1表示被解压了,将来要重新压缩 */
unsigned int attempted_compress : 1; /* */
unsigned int extra : 10; /* 预留字段 */
} quicklistNode;
6.SkipList
跳表
元素按照升序排序存储(分数,分数若相同就按ele字典排序)节点可能包含多个指针,指针跨度不同
最多32级指针
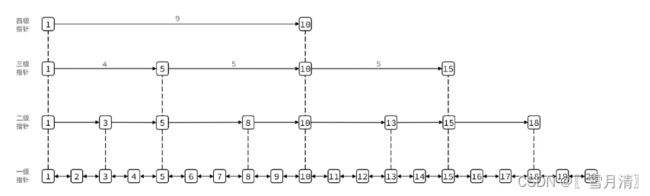
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; // 节点存储的值
double score; // 分数,排序、查找用
struct zskiplistNode *backward; // 前一个节点指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 下一个节点指针
unsigned long span; // 索引跨度
} level[]; // 多级索引数组
} zskiplistNode;
typedef struct zskiplist {
// 头尾节点指针
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 最大的索引层级,默认是1
int level;
} zskiplist;
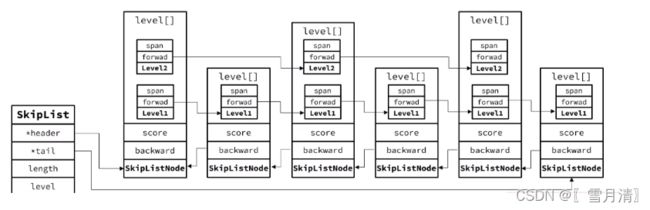
与红黑树对比:增删改查效率基本一致,实现却更简单
7.RedisObject
Redis中的任意数据类型的key和value都会被封装为一个RedisObject(Redis对象)
typedef struct redisObject {
unsigned type:4; // 对象类型,分别为五种基本数据类型 占4个bit位
unsigned encoding:4; // 编码方式 11 中 占4个bit位
unsigned lru:LRU_BITS; /*LRU表示对象最后一次被访问的时间,占24个bit位。便于判断空闲时间太久的key*/
int refcount; // 引用计数器 0表示对象无人引用 可以被回收
void *ptr; // 指针,指向存放实际数据的空间
} robj;
共16字节 相当于Redis中key或者value的头部分
Redis中会根据存储的数据类型不同,选择不同的编码方式。

二、Redis中五种基本数据结构
1. String
底层实现:
-
基本编码方式是
RAW,基于简单动态字符串(SDS)实现,存储上限为512mb

-
如果存储的SDS长度小于44字节,则会采用
embstr编码,此时object head与SDS是一段连续空间。申请内存时只需要调用依次内存分配函数,效率更高

(SDS长度为44字节 使用8位格式的sds 头部占3个字节尾部1个字节,而RedisObject占16字节,总共64字节 便于分配内存空间)
- 如果存储的字符串是整数值,大小在
LONG_MAX范围内,会采用Int编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),无需SDS

应用场景:
-
json字符串格式的对象
-
常规计数 (redis单线程,执行命令的过程是原子的)
-
分布式锁
SET 命令 NX参数可以实现 key不存在才插入,EX设置过期时间,防止客户端异常造成锁无法释放
-
如果key不存在,则显示插入成功,可以表示加锁成功 -
如果key存在,显示插入失败,可以用来表示加锁失败
解锁就是删除 key ,在删除前需要判断是否是自己的锁,防误删。因此解锁就是两步操作,使用Lua脚本保证原子性
共享session问题
在分布式系统中,用户的session由于存储在单个服务器上,当用户第二次访问,系统(负载均衡)把请求分配到其他的服务器上由于没有session,出现重复登录的问题。
一种比较高效的方案就是: 将session存入Redis中,以key的过期时间代表session的过期时间。服务器验证用户是否登录时,从redis中取session进行验证。
2. List
底层实现
底层实现QuickList:LinkedList+ZipList 可以双端访问,内存占用低,包含多个ZipList,存储上限高
参考QuickList
应用场景:
消息队列
通过lpush+Rpop 或者 Rpush+Lpop 命令来实现消息队列,按照消息的先进先出特性可以保证消息的有序,
Brpop命令阻塞式读取,消费者没有读到数据时会自动阻塞,防止消费者不断尝试取消息(没有通知机制)
重复消费问题:
使用 自定义全局ID标记消息,在消费者中维护一个记录已经消息的消息ID
可靠性:
消费者在处理消息时如果宕机就造成了消息丢失,List中提供一个BRPOPLPUSH 命令,作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息放入到另一个 List(可以叫作备份 List)留存
缺陷: 不支持多个消费者消费同一条消息
3. Set
底层实现
单列集合,元素唯一,对查询效率要求极高,不一定元素有序
- 为了查询效率和唯一性,set底层使用HT编码(Dict)。Dict中的key用来存储元素,value统一位null
- 当存储数据都是整数,且不超过
set-max-intset-entries时(默认512),Set采用IntSet编码,节省内存
robj *setTypeCreate(sds value) {
// 判断value是否 是数值类型 longlong
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
// 如果是数值类型,采用IntSet编码
return createIntsetObject();
// 否则采用默认编码HT
return createSetObject();
}
应用场景:
点赞:key可以是帖子、blog、评论, value是用户id列表,也方便求点赞总数
共同关注:交集运算 key为用户id,value为关注的id列表
抽奖:key为活动名称,value为参与人 SRANDMEMBER 允许重复中奖 SPOP 不允许重复中奖
4. ZSet
底层实现
也就是SortedSet,其中每一个元素都需要指定一个score值和member值
- 可以根据score值排序
- member必须唯一
- 根据member查询分数
底层实现为 SkipList跳表(排序) + Dict(键值存储、唯一)
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,需要同时满足两个条件:
-
元素数量小于
zset_max_ziplist_entries,默认128 -
每个元素都小于
zset_max_ziplist_value字节,默认值64
ZipList本身无排序功能,没有键值对概念,zipList 将score和element紧挨着放一起,ele在前score在后。score越小越接近链表头部
应用场景
排行榜:
根据评分对帖子进行排行
获取指定评分范围内的数据,或者指定排名范围内的数据
ZRANGE key min max : 按照score排序后,获取指定排名范围内的元素
ZRANGEBYSCORE key min max: 按照score排序后,获取执行score范围内的元素
5. Hash
-
键值存储
-
根据键获取值
-
键必须唯一
底层实现
-
Hash结构默认采用ZipList编码,用以节省内存。ZipList中两个相邻的entry分别保存field和value
-
当数据量较大时,Hash结构会转为HT编码,也就是Dict
- ZipList中的元素数量超过了
hash-max-ziplist-entries(默认512) - ZipList中的任意entry大小超过了
hash-max-ziplist-value(默认64字节)
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
// 判断是否时ZipList编码
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
// 查询 头指针
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) { // 头指针不为NULL ziplist不为空,开始查key
fptr = ziplistFind(zl, fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) { // 判断key是否存在 如果存在直接更新覆盖
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Replace value */
zl = ziplistReplace(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
// 不存在,直接 插入ziplist尾部
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* 插入了新元素 检查 list长度是否超出,超出则转为HT */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
// HT编码 直接插入新元素或者覆盖旧值
dictEntry *de = dictFind(o->ptr,field);
if (de) {
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
/* Free SDS strings we did not referenced elsewhere if the flags
* want this function to be responsible. */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}
应用场景:
存储对象类型的数据很方便,可以关联同一个对象的不同属性
购物车,以用户id为key,商品id为field,商品数量为value