爬虫入门实战(标价400的单子-1)
记录了我本人在工作室接爬虫单的几个经典的真实案例,干货满满,这可是吃饭的家伙,还不关注一波。
写在前面
这里想做这个专栏很久了,不仅是想把自己在工作时接触到一些比较棘手的问题和解决方法记录下来,而且也想帮助初学者了解一个爬虫的完整流程。
我目前的想法是更新一个简单的表格爬虫(一个基本没有反扒手段的网站)来入门。然后搞个selinunm自动化爬一下淘宝的商品类目、价格等信息来帮助大家进阶爬虫之路。最后我会分享我的终极爬虫技巧,大巧不工。
其实,我的爬虫技术也是业余的,野路子。写这些文章只能帮助初学者进行爬虫一个了解,能接一些小点的单子。但是真正要应聘爬虫工程师是远远不够的。后面有时间的话我也会进行学习爬虫(如selinum伪装成正常请求,安卓模拟器app爬虫)
爬虫概览
其实我们或多或少都是听说过爬虫这个概念,这个东西的技术栈其实也比较成熟了。
其实在我的理解中,爬虫嘛,就是给自己伪装一下,装成是正常的访问请求,然后获取到网站或者APP中的数据资源的一种技术手段。
当然目前大部分爬虫都是python写的,毕竟python丰富的第三方库资源还有语言优势摆在这里。所以,我们这里也是通过python进行爬虫的编写。
一、项目需求
一个香港的老板应该是,他给个网址
里面大概是这样的

点进去那个箭头的之后是个超链接,然后,要把这个信息爬下来。

需求挺明确的,而且这个网站,连一些基础的反爬手段都没有,非常适合用来入门实战。
二、分析网页
搞到所有律师的信息的流程清晰的分为两个步骤:1.搞到所有律师的个人介绍的超链接;2.然后再对所有链接进行访问。
 可以看到哈,这个记录还是有点多的,11339条,30个记录一页。要全部拿下来不是一件简单的事,
可以看到哈,这个记录还是有点多的,11339条,30个记录一页。要全部拿下来不是一件简单的事,
1.找到所有页面的链接:
这个是第一页。 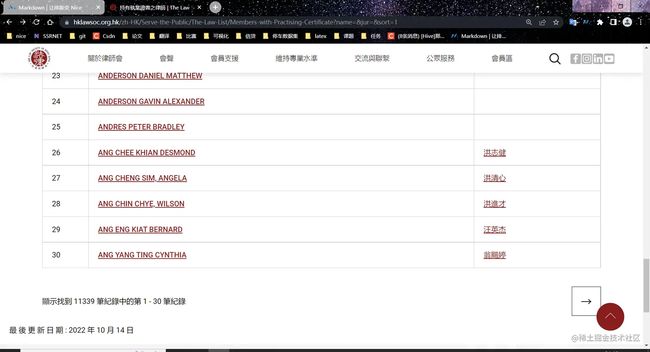
这个是第二页。 
让我们来看看他的链接:
第一页:www.hklawsoc.org.hk/zh-HK/Serve…
第二页:www.hklawsoc.org.hk/zh-HK/Serve…
找到不同了嘛.第二页多出了一个字段:&pageIndex=2#tips 可以把这个数字换成1和3,试一下.
&pageIndex=1#tips 
&pageIndex=3#tips 
所以所有页面的规律就找到了,用来访问的链接如下:
for i in range(1, 11339//30):
print(i/(11339//30),end=' ')
url = "https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1&pageIndex="+str(i)+"#tips"
这个规律真的很简单,所以就用来爬虫的入门了.
2.找到所有律师的个人页面链接:
这个就是一个页面分析的任务了。
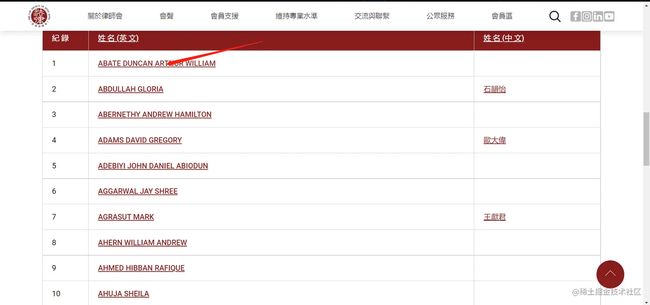
还记得我们刚才是点这个链接访问的这个律师个人信息界面吧,这里面必然有着个人界面的超链接,我们需要的就是把它扒出来出来就可以了。下面我们在这个页面,按F12,查看,操作如下:
- 点击F12,进入下面的界面
 2. 点箭头指向的按钮
2. 点箭头指向的按钮
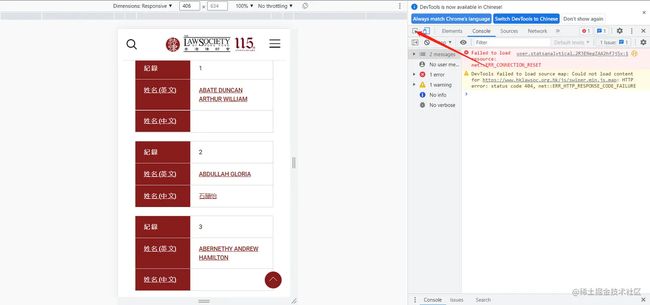
- 然后点击你想扒出超链接的元素

点击后:

这个超链接很显眼了吧。点进去,正好是我们想要的链接。
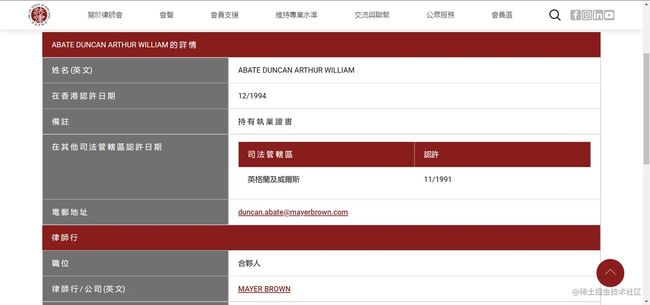
三、开始爬取
还记得我们开始说的嘛,爬虫是封装成正常的请求去访问页面然后下载我们想要的资源,对吧所以,这里细化为两个步骤请求页面资源和解析页面资源找到我们想要的数据**(这里我们想要的是律师个人页面的超链接)**
- 这里先进行第一步:请求页面资源
爬虫的技术获取网页的手段最基础的就是python的requests方法了。我们这里用的也是这个方法。
requests的请求在这里也比较简单,就是简单的get请求,其实也有post的请求,网络上有很多资料,我这里就不赘述了。
简单的requests的get请求代码如下:
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
for i in range(1, 11339//30):
print(i/(11339//30),end=' ')
url = "https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1&pageIndex="+str(i)+"#tips"
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8', 'ignore')
这里response就是我们请求下来的页面资源了,经过源码解析获取到了html源码。

当然,你可能会有疑问这个headers从哪来的,哪里规定的。
每个浏览器都有自己的headers,因为headers要模仿你自己的浏览器向网页发送信息。如果使用Python进行爬取页面时,使用了别人的headers可能会导致爬取不到任何数据(因为代码在你自己的电脑运行,所以无法模拟别人的浏览器)
当然其实用别人也可以,有的网站他可能安全做的没有那么好,就都还可以正常访问。当然,所以如何查找自己headers也很重要,具体步骤如下:
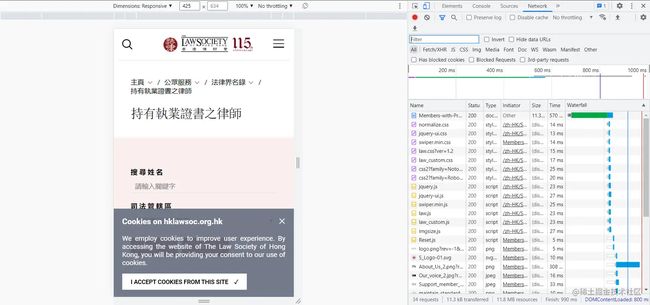
- 随便打开一个网页,例如打开我们这个页面,右键点击‘检查’或者按F12,出现下图页面。

- 点击network

- F5刷新
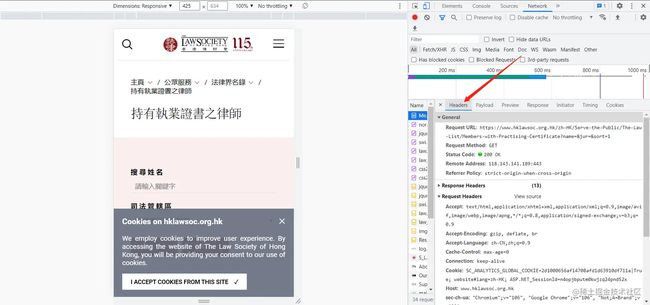
 4. 在name框随便点一个选项,在右侧点击‘headers’选项,在最下方找到‘User-Agent:’,粘贴到自己代码即可。如下图
4. 在name框随便点一个选项,在右侧点击‘headers’选项,在最下方找到‘User-Agent:’,粘贴到自己代码即可。如下图

个人总结:
这里主要是介绍一个爬虫的基本流程,能够帮助我们爬下来我们想要的页面源码。当然光爬下来源码是远远不够的,还需要各种规则(lxml、beautifulsoup以及正则表达式)的解析才能获取到从整个源码中获取我们想要的数据。
题外话
当下这个大数据时代不掌握一门编程语言怎么跟的上脚本呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
CSDN大礼包:gift::[全网最全《Python学习资料》免费赠送:free:!](https://blog.csdn.net/weixin_68789096/article/details/132275547?spm=1001.2014.3001.5502) (安全链接,放心点击)
若有侵权,请联系删除