Phython—实训day5—爬虫相关知识
1爬虫练习(urllib+xpath)
爬取某公司官网新闻中心板块(“http://www.tipdm.com/xwzx/index.jhtml”)中的新闻标题和新闻内容,爬取页数为5页。 要求:使用urllib库实现HTTP请求的发送,使用Xpath进行网页解析,最后将爬取到的内容保存至Excel文件中。
1.1第一页数据的爬取
#导入相应库
from urllib import request
from lxml import etree
import pandas as pd #安装命令:pip install pandas -i http://pypi.douban.com/simple
url = 'http://www.tipdm.com/xwzx/index.jhtml' #第一页的网页链接
#发送请求
req = request.Request(url)
#打开响应的对象
response = request.urlopen(req)
#获取响应的内容
html = response.read()
#解析网页
html = etree.HTML(html)
#获取数据
title = html.xpath('//*[@id="t505"]/div/div[3]/h1/a/text()') #新闻标题
content = html.xpath('//*[@id="t505"]/div/div[3]/div/text()') #新闻内容
#将数据存储为数据框DataFrame
data = pd.DataFrame({'新闻标题':title, '新闻内容':content})
#将数据保存为Excel文件
data.to_excel(r'F:\Desktop\data.xlsx')1.2多页数据的爬取
思路:首先把所有的网页链接存放到一个列表中,然后循坏这一个网页链接列表中的每一个链接,向每一个链接发送请求、网页解析、获取数据。此时获取到的数据只是单个页面的数据,所以需要在循坏外构建一个空的DataFrame用于存放所有页面的数据。最后将这个包含有总数据的DataFrame保存为excel文件。
#导入相应的库
from urllib import request
from lxml import etree
import pandas as pd
#获取前5页网页链接
urls = [] #构建空列表存放网页链接
for i in range(1, 6):
u = 'http://www.tipdm.com/xwzx/index_'+ str(i) + '.jhtml'
urls.append(u) #向列表添加一个一个的链接
urls
#获取前5页的网页内容
all_data = pd.DataFrame() #构建空的DataFrame
for j in urls:
#发送请求
req = request.Request(j)
#打开响应的对象
response = request.urlopen(req)
#获取响应的内容
html = response.read()
#解析网页
html = etree.HTML(html)
#获取数据
title = html.xpath('//*[@id="t505"]/div/div[3]/h1/a/text()') #新闻标题
content = html.xpath('//*[@id="t505"]/div/div[3]/div/text()') #新闻内容
#将数据存储为数据框DataFrame
data = pd.DataFrame({'新闻标题':title, '新闻内容':content})
#数据纵向合并
all_data = pd.concat([all_data, data], axis=0)
#将全部数据保存为Excel文件
all_data.to_excel(r'F:\Desktop\all_data.xlsx')2requests库实现HTTP请求
requests库生成请求的代码非常便利,其使用的request方法的语法格式如下:
requests.get(url,**kwargs)

2.1发送请求
import requests #安装命令:pip install requests -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
rq = requests.get('http://www.tipdm.com/')
print('响应码:', rq.status_code) #返回200,表示访问成功
print('编码:', rq.encoding)
print('获取内容:', rq.text)
print('获取内容:', rq.content) #二进制文本呈现2.2乱码情况
#设置乱码
rq.encoding = 'gbk'
print('获取内容:', rq.text)
print('获取内容:', rq.content)2.2.1乱码修改第一种方法:手动指定
可以直接查看网页源码中的charset属性得到该网页的编码。
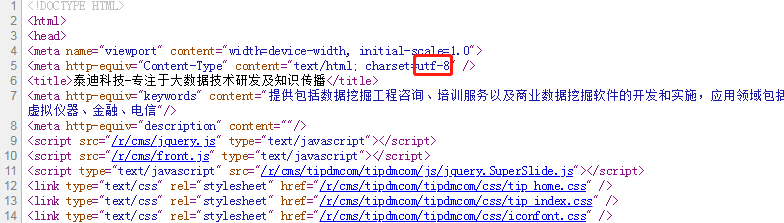
##针对text输出
rq.encoding = 'UTF-8'
print('获取内容:', rq.text)
##针对content输出,需要使用decode进行解码
print('获取内容:', rq.content.decode('utf-8'))2.2.2乱码修改第二种方法:自动检测
chardet库是一个非常优秀的字符串∕文件编码检测模块。chardet库使用detect方法检测给定字符串的编码,detect方法常用的参数及其说明如下。

#重新设置以乱码形式呈现
rq.encoding = 'gbk'
print('获取内容:', rq.text)import chardet #安装命令:pip install chardet -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
rq.encoding = chardet.detect(rq.content)['encoding'] #chardet.detect(rq.content)返回的是字典形式的数据
print('获取内容:', rq.text) #修改成功2.3爬虫练习requests+xpath
import requests
from lxml import etree
import pandas as pd
#获取前5页网页链接
urls = [] #构建空列表存放网页链接
for i in range(1, 6):
u = 'http://www.tipdm.com/xwzx/index_'+ str(i) + '.jhtml'
urls.append(u) #向列表添加一个一个的链接
#获取前5页的网页内容
all_data = pd.DataFrame() #构建空的DataFrame
for j in urls:
#发送请求
rq = requests.get(j)
#解析网页
html = etree.HTML(rq.text)
#获取数据
title = html.xpath('//*[@id="t505"]/div/div[3]/h1/a/text()') #新闻标题
content = html.xpath('//*[@id="t505"]/div/div[3]/div/text()') #新闻内容
#将数据存储为数据框DataFrame
data = pd.DataFrame({'新闻标题':title, '新闻内容':content})
#数据纵向合并
all_data = pd.concat([all_data, data], axis=0)
#将全部数据保存为Excel文件
all_data.to_excel(r'F:\Desktop\all_data.xlsx')3使用Beautiful Soup解析网页
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库。目前Beautiful Soup 3已经停止开发,大部分的爬虫选择使用Beautiful Soup 4开发。Beautiful Soup不仅支持Python标准库中的HTML解析器,还支持一些第三方的解析器,具体语法如下。
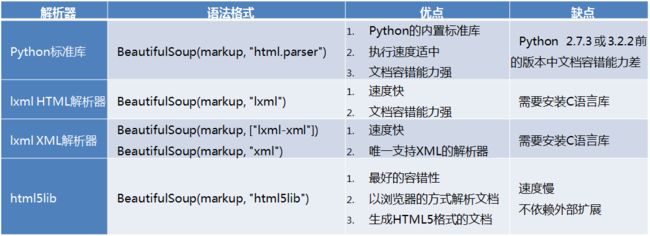
lxml解析器比较常用。
3.1创建BeautifulSoup对象
要使用Beautiful Soup库解析网页首先需要创建BeautifulSoup对象,将字符串或HTML文件传入。
创建一个BeautifulSoup对象,使用格式如下。
BeautifulSoup("data") #通过字符串创建
BeautifulSoup(open("index.html")) #通过HTML文件创建
import requests
from bs4 import BeautifulSoup #pip install beautifulsoup4 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
#requests发送请求
rq = requests.get('http://www.tipdm.com/')
#BeautifulSoup实现网页解析
soup = BeautifulSoup(rq.text, 'lxml') #'lxml'表解析器3.2对象类型
3.2.1Tag对象类型
(1)Tag对象为HTML文档中的标签,形如
“The Dormouse's story ”或“The Dormouse's story
”等HTML标签再加上其中包含的内容便是Beautiful Soup中的Tag对象。
(2)通过Tag的名称属性可以很方便的在文档树中获取需要的Tag对象,通过该方法只能获取文档树中第一个同名的Tag对象,而通过多次调用可获取某个Tag对象下的分支Tag对象。通过find_all方法可以获取文档树中的全部同名Tag对象。
soup.head #返回head标签内容
soup.title #返回title标签内容
soup.body.li #返回的是第一个li标签
soup.find_all('li') #可返回所有li标签
type(soup.head) #bs4.element.Tag(3)Tag有两个非常重要的属性:name和attributes。name属性可通过name方法来获取和修改,修改过后的name属性将会应用至BeautifulSoup对象生成的HTML文档。
a = soup.link
a.name #name属性返回的是标签名称
a.attrs #attrs属性返回的是该标签下面的属性和属性值3.2.2NavigableString对象类型NavigableString对象为包含在Tag中的文本字符串内容,如
“The Dormouse‘s story ”中的“The Dormouse’s story”使用string的方法获取,NavigableString对象无法被编辑,但可以使用replace_with的方法进行替换。
soup.title.string #可获取到title标签的文本内容
type(soup.title.string) #bs4.element.NavigableString
#更改标签里的文本内容
a = soup.title.string
a.replace_with('广东泰迪科技股份有限公司') #替换
soup.title.string 3.2.3BeautifulSoup对象类型
BeautifulSoup对象表示的是一个文档的全部内容。大部分时候,可以把它当作Tag对象。 BeautifulSoup对象并不是真正的HTML或XML的tag,所以并没有tag的name和attribute属性,但其包含了一个值为“[document]”的特殊属性name。
type(soup) #bs4.BeautifulSoup
soup.name #只返回[document]值
soup.attrs #BeautifulSoup对象类型没有attribute属性3.2.4Comment对象类型
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象,文档的注释部分是最容易与Tag中的文本字符串混淆的部分。Beautiful Soup库中将文档的注释部分识别为Comment类型,Comment对象是一个特殊类型的NavigableString对象,但是当其出现在HTML文档中时,Comment对象会使用特殊的格式输出,需调用prettify方法。
markup = ''
markup_soup = BeautifulSoup(markup, 'lxml')
markup_soup.c.string
type(markup_soup.c.string) #bs4.element.Comment 3.3搜索特定节点并获取其中的链接及文本
Beautiful Soup定义了很多搜索方法,其中常用的有find方法和find_all方法,两者的参数一致,区别为find_all方法的返回结果是值包含一个元素的列表,而find直接返回的是结果。find_all方法用于搜索文档树中的Tag非常方便,其语法格式如下。
BeautifulSoup.find_all(name,attrs,recursive,string,**kwargs)
find_all方法的常用参数及其说明如下。
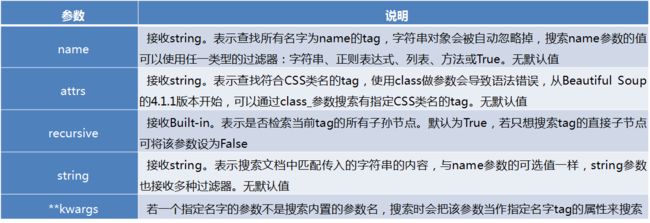
find_all方法
(1)可通过多种参数遍历搜索文档树中符合条件的所有子节点。
(2)可通过name参数搜索同名的全部子节点,并接收多种过滤器。
(3)按照CSS类名可模糊匹配或完全匹配。完全匹配class的值时,如果CSS类名的顺序与实际不符,将搜索不到结果。
(4)若tag的class属性是多值属性,可以分别搜索tag中的每个CSS类名。
(5)通过字符串内容进行搜索符合条件的全部子节点,可通过过滤器操作。
(6)通过传入关键字参数,搜索匹配关键字的子节点。
import requests
from bs4 import BeautifulSoup #pip install beautifulsoup4
#requests发送请求
rq = requests.get('http://www.tipdm.com/')
#BeautifulSoup实现网页解析
soup = BeautifulSoup(rq.text, 'lxml') #'lxml'表解析器
soup.find_all('title') #返回的是列表
soup.find('title') #直接返回结果
#获取标签内容,使用get_text()方法
soup.find_all('title')[0].get_text()
soup.find('title').get_text()
soup.find('nav', class_="nav").find('ul', id="menu").find_all('li')[0].find('a').get_text() #class_ 这里加一个下划线是因为避免与python关键字冲突所以用一个下划线.