C++多态与虚函数
文章目录
- C++多态和虚函数快速入门教程
-
- 借助引用也可以实现多态
- 多态的用途
- C++虚函数注意事项以及构成多态的条件
-
- 构成多态的条件
- 什么时候声明虚函数
- C++虚析构函数的必要性
- C++纯虚函数和抽象类详解
-
-
-
- 关于纯虚函数的几点说明
-
-
- C++虚函数表精讲教程,直戳多态的实现机制
- C++ typeid运算符:获取类型信息
-
-
-
- 1) 原型:const char* name() const;
- 2) 原型:bool before (const type_info& rhs) const;
- 3) 原型:bool operator== (const type_info& rhs) const;
- 4) 原型:bool operator!= (const type_info& rhs) const;
-
- 判断类型是否相等
-
-
- 1) 内置类型的比较
- 2) 类的比较
-
- type_info 类的声明
-
- C++ RTTI机制精讲(C++运行时类型识别机制)
- C++静态绑定和动态绑定,彻底理解多态
-
- 函数绑定
- C++ RTTI机制下的对象内存模型(透彻)
来自于http://c.biancheng.net/cplus/
C++多态和虚函数快速入门教程
在《C++将派生类赋值给基类(向上转型)》一节中讲到,基类的指针也可以指向派生类对象,请看下面的例子:
#include
using namespace std;
//基类People
class People{
public:
People(char *name, int age);
void display();
protected:
char *m_name;
int m_age;
};
People::People(char *name, int age): m_name(name), m_age(age){}
void People::display(){
cout< display();
p = new Teacher("赵宏佳", 45, 8200);
p -> display();
return 0;
}
运行结果:
王志刚今年23岁了,是个无业游民。
赵宏佳今年45岁了,是个无业游民。
我们直观上认为,如果指针指向了派生类对象,那么就应该使用派生类的成员变量和成员函数,这符合人们的思维习惯。但是本例的运行结果却告诉我们,当基类指针 p 指向派生类 Teacher 的对象时,虽然使用了 Teacher 的成员变量,但是却没有使用它的成员函数,导致输出结果不伦不类(赵宏佳本来是一名老师,输出结果却显示人家是个无业游民),不符合我们的预期。
换句话说,通过基类指针只能访问派生类的成员变量,但是不能访问派生类的成员函数。
为了消除这种尴尬,让基类指针能够访问派生类的成员函数,C++ 增加了虚函数(Virtual Function)。使用虚函数非常简单,只需要在函数声明前面增加 virtual 关键字。
更改上面的代码,将 display() 声明为虚函数:
#include
using namespace std;
//基类People
class People{
public:
People(char *name, int age);
virtual void display(); //声明为虚函数
protected:
char *m_name;
int m_age;
};
People::People(char *name, int age): m_name(name), m_age(age){}
void People::display(){
cout< display();
p = new Teacher("赵宏佳", 45, 8200);
p -> display();
return 0;
}
运行结果:
王志刚今年23岁了,是个无业游民。
赵宏佳今年45岁了,是一名教师,每月有8200元的收入。
和前面的例子相比,本例仅仅是在 display() 函数声明前加了一个virtual关键字,将成员函数声明为了虚函数(Virtual Function),这样就可以通过 p 指针调用 Teacher 类的成员函数了,运行结果也证明了这一点(赵宏佳已经是一名老师了,不再是无业游民了)。
有了虚函数,基类指针指向基类对象时就使用基类的成员(包括成员函数和成员变量),指向派生类对象时就使用派生类的成员。换句话说,基类指针可以按照基类的方式来做事,也可以按照派生类的方式来做事,它有多种形态,或者说有多种表现方式,我们将这种现象称为多态(Polymorphism)。
上面的代码中,同样是p->display();这条语句,当 p 指向不同的对象时,它执行的操作是不一样的。同一条语句可以执行不同的操作,看起来有不同表现方式,这就是多态。
多态是面向对象编程的主要特征之一,C++中虚函数的唯一用处就是构成多态。
C++提供多态的目的是:可以通过基类指针对所有派生类(包括直接派生和间接派生)的成员变量和成员函数进行“全方位”的访问,尤其是成员函数。如果没有多态,我们只能访问成员变量。
前面我们说过,通过指针调用普通的成员函数时会根据指针的类型(通过哪个类定义的指针)来判断调用哪个类的成员函数,但是通过本节的分析可以发现,这种说法并不适用于虚函数,虚函数是根据指针的指向来调用的,指针指向哪个类的对象就调用哪个类的虚函数。
但是话又说回来,对象的内存模型是非常干净的,没有包含任何成员函数的信息,编译器究竟是根据什么找到了成员函数呢?我们将在《C++虚函数表精讲教程,直戳多态的实现机制》一节中给出答案。
借助引用也可以实现多态
引用在本质上是通过指针的方式实现的,这一点已在《C++引用在本质上是什么,它和指针到底有什么区别?》中进行了讲解,既然借助指针可以实现多态,那么我们就有理由推断:借助引用也可以实现多态。
修改上例中 main() 函数内部的代码,用引用取代指针:
int main(){
People p("王志刚", 23);
Teacher t("赵宏佳", 45, 8200);
People &rp = p;
People &rt = t;
rp.display();
rt.display();
return 0;
}
运行结果:
王志刚今年23岁了,是个无业游民。
赵宏佳今年45岁了,是一名教师,每月有8200元的收入。
由于引用类似于常量,只能在定义的同时初始化,并且以后也要从一而终,不能再引用其他数据,所以本例中必须要定义两个引用变量,一个用来引用基类对象,一个用来引用派生类对象。从运行结果可以看出,当基类的引用指代基类对象时,调用的是基类的成员,而指代派生类对象时,调用的是派生类的成员。
不过引用不像指针灵活,指针可以随时改变指向,而引用只能指代固定的对象,在多态性方面缺乏表现力,所以以后我们再谈及多态时一般是说指针。本例的主要目的是让读者知道,除了指针,引用也可以实现多态。
多态的用途
通过上面的例子读者可能还未发现多态的用途,不过确实也是,多态在小项目中鲜有有用武之地。
接下来的例子中,我们假设你正在玩一款军事游戏,敌人突然发动了地面战争,于是你命令陆军、空军及其所有现役装备进入作战状态。具体的代码如下所示:
#include
using namespace std;
//军队
class Troops{
public:
virtual void fight(){ cout<<"Strike back!"<fight();
//陆军
p = new Army;
p ->fight();
p = new _99A;
p -> fight();
p = new WZ_10;
p -> fight();
p = new CJ_10;
p -> fight();
//空军
p = new AirForce;
p -> fight();
p = new J_20;
p -> fight();
p = new CH_5;
p -> fight();
p = new H_6K;
p -> fight();
return 0;
}
运行结果:
Strike back!
–Army is fighting!
----99A(Tank) is fighting!
----WZ-10(Helicopter) is fighting!
----CJ-10(Missile) is fighting!
–AirForce is fighting!
----J-20(Fighter Plane) is fighting!
----CH-5(UAV) is fighting!
----H-6K(Bomber) is fighting!
这个例子中的派生类比较多,如果不使用多态,那么就需要定义多个指针变量,很容易造成混乱;而有了多态,只需要一个指针变量 p 就可以调用所有派生类的虚函数。
从这个例子中也可以发现,对于具有复杂继承关系的大中型程序,多态可以增加其灵活性,让代码更具有表现力。
C++虚函数注意事项以及构成多态的条件
C++ 虚函数对于多态具有决定性的作用,有虚函数才能构成多态。上节《C++多态和虚函数快速入门教程》我们已经介绍了虚函数的概念,这节我们来重点说一下虚函数的注意事项。
-
只需要在虚函数的声明处加上 virtual 关键字,函数定义处可以加也可以不加。
-
为了方便,你可以只将基类中的函数声明为虚函数,这样所有派生类中具有遮蔽关系的同名函数都将自动成为虚函数。关于名字遮蔽已在《C++继承时的名字遮蔽》一节中进行了讲解。
-
当在基类中定义了虚函数时,如果派生类没有定义新的函数来遮蔽此函数,那么将使用基类的虚函数。
-
只有派生类的虚函数覆盖基类的虚函数(函数原型相同)才能构成多态(通过基类指针访问派生类函数)。例如基类虚函数的原型为
virtual void func();,派生类虚函数的原型为virtual void func(int);,那么当基类指针 p 指向派生类对象时,语句p -> func(100);将会出错,而语句p -> func();将调用基类的函数。 -
构造函数不能是虚函数。对于基类的构造函数,它仅仅是在派生类构造函数中被调用,这种机制不同于继承。也就是说,派生类不继承基类的构造函数,将构造函数声明为虚函数没有什么意义。
-
析构函数可以声明为虚函数,而且有时候必须要声明为虚函数,这点我们将在下节中讲解。
构成多态的条件
站在“学院派”的角度讲,封装、继承和多态是面向对象的三大特征,封装、继承分别在《C++类成员的访问权限以及类的封装》《C++继承和派生简明教程》中进行了讲解,而多态是指通过基类的指针既可以访问基类的成员,也可以访问派生类的成员。
下面是构成多态的条件:
- 必须存在继承关系;
- 继承关系中必须有同名的虚函数,并且它们是覆盖关系(函数原型相同)。
- 存在基类的指针,通过该指针调用虚函数。
下面的例子对各种混乱情形进行了演示:
#include
using namespace std;
//基类Base
class Base{
public:
virtual void func();
virtual void func(int);
};
void Base::func(){
cout<<"void Base::func()"< func(); //输出void Derived::func()
p -> func(10); //输出void Base::func(int)
p -> func("http://c.biancheng.net"); //compile error
return 0;
}
在基类 Base 中我们将void func()声明为虚函数,这样派生类 Derived 中的void func()就会自动成为虚函数。p 是基类 Base 的指针,但是指向了派生类 Derived 的对象。
语句p -> func();调用的是派生类的虚函数,构成了多态。
语句p -> func(10);调用的是基类的虚函数,因为派生类中没有函数覆盖它。
语句p -> func("http://c.biancheng.net");出现编译错误,因为通过基类的指针只能访问从基类继承过去的成员,不能访问派生类新增的成员。
什么时候声明虚函数
首先看成员函数所在的类是否会作为基类。然后看成员函数在类的继承后有无可能被更改功能,如果希望更改其功能的,一般应该将它声明为虚函数。如果成员函数在类被继承后功能不需修改,或派生类用不到该函数,则不要把它声明为虚函数。
C++虚析构函数的必要性
上节我们讲到,构造函数不能是虚函数,因为派生类不能继承基类的构造函数,将构造函数声明为虚函数没有意义。
这是原因之一,另外还有一个原因:C++ 中的构造函数用于在创建对象时进行初始化工作,在执行构造函数之前对象尚未创建完成,虚函数表尚不存在,也没有指向虚函数表的指针,所以此时无法查询虚函数表,也就不知道要调用哪一个构造函数。下节将会讲解虚函数表的概念。
析构函数用于在销毁对象时进行清理工作,可以声明为虚函数,而且有时候必须要声明为虚函数。
为了说明虚析构函数的必要性,请大家先看下面一个例子:
#include
using namespace std;
//基类
class Base{
public:
Base();
~Base();
protected:
char *str;
};
Base::Base(){
str = new char[100];
cout<<"Base constructor"< 运行结果:
Base constructor
Derived constructor
Base destructor
-------------------
Base constructor
Derived constructor
Derived destructor
Base destructor
本例中定义了两个类,基类 Base 和派生类 Derived,它们都有自己的构造函数和析构函数。在构造函数中,会分配 100 个 char 类型的内存空间;在析构函数中,会把这些内存释放掉。
pb、pd 分别是基类指针和派生类指针,它们都指向派生类对象,最后使用 delete 销毁 pb、pd 所指向的对象。
从运行结果可以看出,语句delete pb;只调用了基类的析构函数,没有调用派生类的析构函数;而语句delete pd;同时调用了派生类和基类的析构函数。
在本例中,不调用派生类的析构函数会导致 name 指向的 100 个 char 类型的内存空间得不到释放;除非程序运行结束由操作系统回收,否则就再也没有机会释放这些内存。这是典型的内存泄露。
- 为什么
delete pb;不会调用派生类的析构函数呢?
因为这里的析构函数是非虚函数,通过指针访问非虚函数时,编译器会根据指针的类型来确定要调用的函数;也就是说,指针指向哪个类就调用哪个类的函数,这在前面的章节中已经多次强调过。pb 是基类的指针,所以不管它指向基类的对象还是派生类的对象,始终都是调用基类的析构函数。
- 为什么
delete pd;会同时调用派生类和基类的析构函数呢?
pd 是派生类的指针,编译器会根据它的类型匹配到派生类的析构函数,在执行派生类的析构函数的过程中,又会调用基类的析构函数。派生类析构函数始终会调用基类的析构函数,并且这个过程是隐式完成的,这在《C++析构函数》一节中已经讲到了。
更改上面的代码,将基类的析构函数声明为虚函数:
class Base{
public:
Base();
virtual ~Base();
protected:
char *str;
};
运行结果:
Base constructor
Derived constructor
Derived destructor
Base destructor
-------------------
Base constructor
Derived constructor
Derived destructor
Base destructor
将基类的析构函数声明为虚函数后,派生类的析构函数也会自动成为虚函数。这个时候编译器会忽略指针的类型,而根据指针的指向来选择函数;也就是说,指针指向哪个类的对象就调用哪个类的函数。pb、pd 都指向了派生类的对象,所以会调用派生类的析构函数,继而再调用基类的析构函数。如此一来也就解决了内存泄露的问题。
在实际开发中,一旦我们自己定义了析构函数,就是希望在对象销毁时用它来进行清理工作,比如释放内存、关闭文件等,如果这个类又是一个基类,那么我们就必须将该析构函数声明为虚函数,否则就有内存泄露的风险。也就是说,大部分情况下都应该将基类的析构函数声明为虚函数。
注意,这里强调的是基类,如果一个类是最终的类,那就没必要再声明为虚函数了。
C++纯虚函数和抽象类详解
在C++中,可以将虚函数声明为纯虚函数,语法格式为:
virtual 返回值类型 函数名 (函数参数) = 0;
纯虚函数没有函数体,只有函数声明,在虚函数声明的结尾加上=0,表明此函数为纯虚函数。
最后的
=0并不表示函数返回值为0,它只起形式上的作用,告诉编译系统“这是纯虚函数”。
包含纯虚函数的类称为抽象类(Abstract Class)。之所以说它抽象,是因为它无法实例化,也就是无法创建对象。原因很明显,纯虚函数没有函数体,不是完整的函数,无法调用,也无法为其分配内存空间。
抽象类通常是作为基类,让派生类去实现纯虚函数。派生类必须实现纯虚函数才能被实例化。
纯虚函数使用举例:
#include
using namespace std;
//线
class Line{
public:
Line(float len);
virtual float area() = 0;
virtual float volume() = 0;
protected:
float m_len;
};
Line::Line(float len): m_len(len){ }
//矩形
class Rec: public Line{
public:
Rec(float len, float width);
float area();
protected:
float m_width;
};
Rec::Rec(float len, float width): Line(len), m_width(width){ }
float Rec::area(){ return m_len * m_width; }
//长方体
class Cuboid: public Rec{
public:
Cuboid(float len, float width, float height);
float area();
float volume();
protected:
float m_height;
};
Cuboid::Cuboid(float len, float width, float height): Rec(len, width), m_height(height){ }
float Cuboid::area(){ return 2 * ( m_len*m_width + m_len*m_height + m_width*m_height); }
float Cuboid::volume(){ return m_len * m_width * m_height; }
//正方体
class Cube: public Cuboid{
public:
Cube(float len);
float area();
float volume();
};
Cube::Cube(float len): Cuboid(len, len, len){ }
float Cube::area(){ return 6 * m_len * m_len; }
float Cube::volume(){ return m_len * m_len * m_len; }
int main(){
Line *p = new Cuboid(10, 20, 30);
cout<<"The area of Cuboid is "<area()<volume()<area()<volume()< 运行结果:
The area of Cuboid is 2200
The volume of Cuboid is 6000
The area of Cube is 1350
The volume of Cube is 3375
本例中定义了四个类,它们的继承关系为:Line --> Rec --> Cuboid --> Cube。
Line 是一个抽象类,也是最顶层的基类,在 Line 类中定义了两个纯虚函数 area() 和 volume()。
在 Rec 类中,实现了 area() 函数;所谓实现,就是定义了纯虚函数的函数体。但这时 Rec 仍不能被实例化,因为它没有实现继承来的 volume() 函数,volume() 仍然是纯虚函数,所以 Rec 也仍然是抽象类。
直到 Cuboid 类,才实现了 volume() 函数,才是一个完整的类,才可以被实例化。
可以发现,Line 类表示“线”,没有面积和体积,但它仍然定义了 area() 和 volume() 两个纯虚函数。这样的用意很明显:Line 类不需要被实例化,但是它为派生类提供了“约束条件”,派生类必须要实现这两个函数,完成计算面积和体积的功能,否则就不能实例化。
在实际开发中,你可以定义一个抽象基类,只完成部分功能,未完成的功能交给派生类去实现(谁派生谁实现)。这部分未完成的功能,往往是基类不需要的,或者在基类中无法实现的。虽然抽象基类没有完成,但是却强制要求派生类完成,这就是抽象基类的“霸王条款”。
抽象基类除了约束派生类的功能,还可以实现多态。请注意第 51 行代码,指针 p 的类型是 Line,但是它却可以访问派生类中的 area() 和 volume() 函数,正是由于在 Line 类中将这两个函数定义为纯虚函数;如果不这样做,51 行后面的代码都是错误的。我想,这或许才是C++提供纯虚函数的主要目的。
关于纯虚函数的几点说明
-
一个纯虚函数就可以使类成为抽象基类,但是抽象基类中除了包含纯虚函数外,还可以包含其它的成员函数(虚函数或普通函数)和成员变量。
-
只有类中的虚函数才能被声明为纯虚函数,普通成员函数和顶层函数均不能声明为纯虚函数。如下例所示:
//顶层函数不能被声明为纯虚函数
void fun() = 0; //compile error
class base{
public :
//普通成员函数不能被声明为纯虚函数
void display() = 0; //compile error
};
C++虚函数表精讲教程,直戳多态的实现机制
前面我们一再强调,当通过指针访问类的成员函数时:
- 如果该函数是非虚函数,那么编译器会根据指针的类型找到该函数;也就是说,指针是哪个类的类型就调用哪个类的函数。其原理已在《C++函数编译原理和成员函数的实现》中讲到。
- 如果该函数是虚函数,并且派生类有同名的函数遮蔽它,那么编译器会根据指针的指向找到该函数;也就是说,指针指向的对象属于哪个类就调用哪个类的函数。这就是多态。
编译器之所以能通过指针指向的对象找到虚函数,是因为在创建对象时额外地增加了虚函数表。
如果一个类包含了虚函数,那么在创建该类的对象时就会额外地增加一个数组,数组中的每一个元素都是虚函数的入口地址。不过数组和对象是分开存储的,为了将对象和数组关联起来,编译器还要在对象中安插一个指针,指向数组的起始位置。这里的数组就是虚函数表(Virtual function table),简写为vtable。
我们以下面的继承关系为例进行讲解:
#include
#include
using namespace std;
//People类
class People{
public:
People(string name, int age);
public:
virtual void display();
virtual void eating();
protected:
string m_name;
int m_age;
};
People::People(string name, int age): m_name(name), m_age(age){ }
void People::display(){
cout<<"Class People:"< display();
p = new Student("王刚", 16, 84.5);
p -> display();
p = new Senior("李智", 22, 92.0, true);
p -> display();
return 0;
}
运行结果:
Class People:赵红今年29岁了。
Class Student:王刚今年16岁了,考了84.5分。
Class Senior:李智以92的成绩从大学毕业了,并且顺利找到了工作,Ta今年22岁。
各个类的对象内存模型如下所示:

图中左半部分是对象占用的内存,右半部分是虚函数表 vtable。在对象的开头位置有一个指针 vfptr,指向虚函数表,并且这个指针始终位于对象的开头位置。
仔细观察虚函数表,可以发现基类的虚函数在 vtable 中的索引(下标)是固定的,不会随着继承层次的增加而改变,派生类新增的虚函数放在 vtable 的最后。如果派生类有同名的虚函数遮蔽(覆盖)了基类的虚函数,那么将使用派生类的虚函数替换基类的虚函数,这样具有遮蔽关系的虚函数在 vtable 中只会出现一次。
当通过指针调用虚函数时,先根据指针找到 vfptr,再根据 vfptr 找到虚函数的入口地址。以虚函数 display() 为例,它在 vtable 中的索引为 0,通过 p 调用时:
p -> display();
编译器内部会发生类似下面的转换:
( *( *(p+0) + 0 ) )§;
下面我们一步一步来分析这个表达式:
0是 vfptr 在对象中的偏移,p+0是 vfptr 的地址;*(p+0)是 vfptr 的值,而 vfptr 是指向 vtable 的指针,所以*(p+0)也就是 vtable 的地址;- display() 在 vtable 中的索引(下标)是 0,所以
( *(p+0) + 0 )也就是 display() 的地址; - 知道了 display() 的地址,
( *( *(p+0) + 0 ) )(p)也就是对 display() 的调用了,这里的 p 就是传递的实参,它会赋值给 this 指针。
可以看到,转换后的表达式是固定的,只要调用 display() 函数,不管它是哪个类的,都会使用这个表达式。换句话说,编译器不管 p 指向哪里,一律转换为相同的表达式。
转换后的表达式没有用到与 p 的类型有关的信息,只要知道 p 的指向就可以调用函数,这跟名字编码(Name Mangling)算法有着本质上的区别。
再来看一下 eating() 函数,它在 vtable 中的索引为 1,通过 p 调用时:
p -> eating();
编译器内部会发生类似下面的转换:
( *( *(p+0) + 1 ) )§;
对于不同的虚函数,仅仅改变索引(下标)即可。
以上是针对单继承进行的讲解。当存在多继承时,虚函数表的结构就会变得复杂,尤其是有虚继承时,还会增加虚基类表,更加让人抓狂,这里我们就不分析了,有兴趣的读者可以自行研究。
C++ typeid运算符:获取类型信息
typeid 运算符用来获取一个表达式的类型信息。类型信息对于编程语言非常重要,它描述了数据的各种属性:
- 对于基本类型(int、float 等C++内置类型)的数据,类型信息所包含的内容比较简单,主要是指数据的类型。
- 对于类类型的数据(也就是对象),类型信息是指对象所属的类、所包含的成员、所在的继承关系等。
类型信息是创建数据的模板,数据占用多大内存、能进行什么样的操作、该如何操作等,这些都由它的类型信息决定。
typeid 的操作对象既可以是表达式,也可以是数据类型,下面是它的两种使用方法:
typeid( dataType )
typeid( expression )
dataType 是数据类型,expression 是表达式,这和 sizeof 运算符非常类似,只不过 sizeof 有时候可以省略括号( ),而 typeid 必须带上括号。
typeid 会把获取到的类型信息保存到一个 type_info 类型的对象里面,并返回该对象的常引用;当需要具体的类型信息时,可以通过成员函数来提取。typeid 的使用非常灵活,请看下面的例子(只能在 VC/VS 下运行):
#include
#include
using namespace std;
class Base{ };
struct STU{ };
int main(){
//获取一个普通变量的类型信息
int n = 100;
const type_info &nInfo = typeid(n);
cout< 运行结果:
int | .H | 529034928
double | .N | 667332678
class Base | .?AVBase@@ | 1035034353
class Base | .?AVBase@@ | 1035034353
struct STU | .?AUSTU@@ | 734635517
char | .D | 4140304029
double | .N | 667332678
从本例可以看出,typeid 的使用非常灵活,它的操作数可以是普通变量、对象、内置类型(int、float等)、自定义类型(结构体和类),还可以是一个表达式。
本例中还用到了 type_info 类的几个成员函数,下面是对它们的介绍:
- name() 用来返回类型的名称。
- raw_name() 用来返回名字编码(Name Mangling)算法产生的新名称。关于名字编码的概念,我们已在《C++函数编译原理和成员函数的实现》中讲到。
- hash_code() 用来返回当前类型对应的 hash 值。hash 值是一个可以用来标志当前类型的整数,有点类似学生的学号、公民的身份证号、银行卡号等。不过 hash 值有赖于编译器的实现,在不同的编译器下可能会有不同的整数,但它们都能唯一地标识某个类型。
遗憾的是,C++ 标准只对 type_info 类做了很有限的规定,不仅成员函数少,功能弱,而且各个平台的实现不一致。例如上面代码中的 name() 函数,nInfo.name()、objInfo.name()在 VC/VS 下的输出结果分别是int和class Base,而在 GCC 下的输出结果分别是i和4Base。
C++ 标准规定,type_info 类至少要有如下所示的 4 个 public 属性的成员函数,其他的扩展函数编译器开发者可以自由发挥,不做限制。
1) 原型:const char* name() const;
返回一个能表示类型名称的字符串。但是C++标准并没有规定这个字符串是什么形式的,例如对于上面的objInfo.name()语句,VC/VS 下返回“class Base”,但 GCC 下返回“4Base”。
2) 原型:bool before (const type_info& rhs) const;
判断一个类型是否位于另一个类型的前面,rhs 参数是一个 type_info 对象的引用。但是C++标准并没有规定类型的排列顺序,不同的编译器有不同的排列规则,程序员也可以自定义。要特别注意的是,这个排列顺序和继承顺序没有关系,基类并不一定位于派生类的前面。
3) 原型:bool operator== (const type_info& rhs) const;
重载运算符“==”,判断两个类型是否相同,rhs 参数是一个 type_info 对象的引用。
4) 原型:bool operator!= (const type_info& rhs) const;
重载运算符“!=”,判断两个类型是否不同,rhs 参数是一个 type_info 对象的引用。
关于运算符重载,我们将在《C++运算符重载》一章中详细讲解。
raw_name() 是 VC/VS 独有的一个成员函数,hash_code() 在 VC/VS 和较新的 GCC 下有效。
可以发现,不像 Java、C# 等动态性较强的语言,C++ 能获取到的类型信息非常有限,也没有统一的标准,如同“鸡肋”一般,大部分情况下我们只是使用重载过的“==”运算符来判断两个类型是否相同。
判断类型是否相等
typeid 运算符经常被用来判断两个类型是否相等。
1) 内置类型的比较
例如有下面的定义:
char *str;
int a = 2;
int b = 10;
float f;
类型判断结果为:
| 类型比较 | 结果 | 类型比较 | 结果 |
|---|---|---|---|
| typeid(int) == typeid(int) | true | typeid(int) == typeid(char) | false |
| typeid(char*) == typeid(char) | false | typeid(str) == typeid(char*) | true |
| typeid(a) == typeid(int) | true | typeid(b) == typeid(int) | true |
| typeid(a) == typeid(a) | true | typeid(a) == typeid(b) | true |
| typeid(a) == typeid(f) | false | typeid(a/b) == typeid(int) | true |
typeid 返回 type_info 对象的引用,而表达式typeid(a) == typeid(b)的结果为 true,可以说明,一个类型不管使用了多少次,编译器都只为它创建一个对象,所有 typeid 都返回这个对象的引用。
需要提醒的是,为了减小编译后文件的体积,编译器不会为所有的类型创建 type_info 对象,只会为使用了 typeid 运算符的类型创建。不过有一种特殊情况,就是带虚函数的类(包括继承来的),不管有没有使用 typeid 运算符,编译器都会为带虚函数的类创建 type_info 对象,我们将在《C++ RTTI机制精讲(C++运行时类型识别机制)》中展开讲解。
2) 类的比较
例如有下面的定义:
class Base{};
class Derived: public Base{};
Base obj1;
Base *p1;
Derived obj2;
Derived *p2 = new Derived;
p1 = p2;
类型判断结果为:
| 类型比较 | 结果 | 类型比较 | 结果 |
|---|---|---|---|
| typeid(obj1) == typeid(p1) | false | typeid(obj1) == typeid(*p1) | true |
| typeid(&obj1) == typeid(p1) | true | typeid(obj1) == typeid(obj2) | false |
| typeid(obj1) == typeid(Base) | true | typeid(*p1) == typeid(Base) | true |
| typeid(p1) == typeid(Base*) | true | typeid(p1) == typeid(Derived*) | false |
表达式typeid(*p1) == typeid(Base)和typeid(p1) == typeid(Base*)的结果为 true 可以说明:即使将派生类指针 p2 赋值给基类指针 p1,p1 的类型仍然为 Base*。
type_info 类的声明
最后我们再来看一下 type_info 类的声明,以进一步了解它所包含的成员函数以及这些函数的访问权限。type_info 类位于typeinfo头文件,声明形式类似于:
class type_info {
public:
virtual ~type_info();
int operator==(const type_info& rhs) const;
int operator!=(const type_info& rhs) const;
int before(const type_info& rhs) const;
const char* name() const;
const char* raw_name() const;
private:
void *_m_data;
char _m_d_name[1];
type_info(const type_info& rhs);
type_info& operator=(const type_info& rhs);
};
它的构造函数是 private 属性的,所以不能在代码中直接实例化,只能由编译器在内部实例化(借助友元)。而且还重载了“=”运算符,也是 private 属性的,所以也不能赋值。
C++ RTTI机制精讲(C++运行时类型识别机制)
一般情况下,在编译期间就能确定一个表达式的类型,但是当存在多态时,有些表达式的类型在编译期间就无法确定了,必须等到程序运行后根据实际的环境来确定。下面的例子演示了这种情况:
#include
using namespace std;
//基类
class Base{
public:
virtual void func();
protected:
int m_a;
int m_b;
};
void Base::func(){ cout<<"Base"<>n;
if(n <= 100){
p = new Base();
}else{
p = new Derived();
}
cout< 输入 45,运行结果为:
45↙
class Base
输入 130,运行结果为:
130↙
class Derived
基类 Base 包含了一个虚函数,派生类 Derived 又定义了一个原型相同的函数遮蔽了它,这就构成了多态。p 是基类的指针,可以指向基类对象,也可以指向派生类对象;*p表示 p 指向的对象。
从代码中可以看出,用户输入的数字不同,*p表示的对象就不同,typeid 获取到的类型也就不同,编译器在编译期间无法预估用户的输入,所以无法确定*p的类型,必须等到程序真的运行了、用户输入完毕了才能确定*p的类型。
根据前面讲过的知识,C++ 的对象内存模型主要包含了以下几个方面的内容:
- 如果没有虚函数也没有虚继承,那么对象内存模型中只有成员变量。
- 如果类包含了虚函数,那么会额外添加一个虚函数表,并在对象内存中插入一个指针,指向这个虚函数表。
- 如果类包含了虚继承,那么会额外添加一个虚基类表,并在对象内存中插入一个指针,指向这个虚基类表。
现在我们要补充的一点是,如果类包含了虚函数,那么该类的对象内存中还会额外增加类型信息,也即 type_info 对象。以上面的代码为例,Base 和 Derived 的对象内存模型如下图所示:

编译器会在虚函数表 vftable 的开头插入一个指针,指向当前类对应的 type_info 对象。当程序在运行阶段获取类型信息时,可以通过对象指针 p 找到虚函数表指针 vfptr,再通过 vfptr 找到 type_info 对象的指针,进而取得类型信息。下面的代码演示了这种转换过程:
**(p->vfptr - 1)
程序运行后,不管 p 指向 Base 类对象还是指向 Derived 类对象,只要执行这条语句就可以取得 type_info 对象。
编译器在编译阶段无法确定 p 指向哪个对象,也就无法获取*p的类型信息,但是编译器可以在编译阶段做好各种准备,这样程序在运行后可以借助这些准备好的数据来获取类型信息。这些准备包括:
- 创建 type_info 对象,并在 vftable 的开头插入一个指针,指向 type_info 对象。
- 将获取类型信息的操作转换成类似
**(p->vfptr - 1)这样的语句。
这样做虽然会占用更多的内存,效率也降低了,但这是没办法的事情,编译器实在是无能为力了。
这种在程序运行后确定对象的类型信息的机制称为运行时类型识别(Run-Time Type Identification,RTTI)。在 C++ 中,只有类中包含了虚函数时才会启用 RTTI 机制,其他所有情况都可以在编译阶段确定类型信息。
下面是 RTTI 机制的一个具体应用,可以让代码根据不同的类型进行不同的操作:
#include
using namespace std;
//基类
class People{
public:
virtual void func(){ }
};
//派生类
class Student: public People{ };
int main(){
People *p;
int n;
cin>>n;
if(n <= 100){
p = new People();
}else{
p = new Student();
}
//根据不同的类型进行不同的操作
if(typeid(*p) == typeid(People)){
cout<<"I am human."< 可能的运行结果:
83↙
I am human.
多态(Polymorphism)是面向对象编程的一个重要特征,它极大地增加了程序的灵活性,C++、C#、Java 等“正统的”面向对象编程语言都支持多态。但是支持多态的代价也是很大的,有些信息在编译阶段无法确定下来,必须提前做好充足的准备,让程序运行后再执行一段代码获取,这会消耗更多的内存和 CPU 资源。
C++静态绑定和动态绑定,彻底理解多态
C/C++ 用变量来存储数据,用函数来定义一段可以重复使用的代码,它们最终都要放到内存中才能供 CPU 使用。CPU 通过地址来取得内存中的代码和数据,程序在执行过程中会告知 CPU 要执行的代码以及要读写的数据的地址。
CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址。
假设变量 a、b、c 在内存中的地址分别是 0X1000、0X2000、0X3000,那么加法运算c = a + b;将会被转换成类似下面的形式:
0X3000 = (0X1000) + (0X2000);
( )表示取值操作,整个表达式的意思是,取出地址 0X1000 和 0X2000 上的值,将它们相加,把相加的结果赋值给地址为 0X3000 的内存。
变量名和函数名为我们提供了方便,让我们在编写代码的过程中可以使用易于阅读和理解的英文字符串,不用直接面对二进制地址,那场景简直让人崩溃。
我们不妨将变量名和函数名统称为符号(Symbol),找到符号对应的地址的过程叫做符号绑定。本节只讨论函数名和地址的绑定,变量名也是类似的道理。
函数绑定
我们知道,函数调用实际上是执行函数体中的代码。函数体是内存中的一个代码段,函数名就表示该代码段的首地址,函数执行时就从这里开始。说得简单一点,就是必须要知道函数的入口地址,才能成功调用函数。
找到函数名对应的地址,然后将函数调用处用该地址替换,这称为函数绑定。
一般情况下,在编译期间(包括链接期间)就能找到函数名对应的地址,完成函数的绑定,程序运行后直接使用这个地址即可。这称为静态绑定(Static binding)。
但是有时候在编译期间想尽所有办法都不能确定使用哪个函数,必须要等到程序运行后根据具体的环境或者用户操作才能决定。这称为动态绑定(dynamic binding)。
C++ 是一门静态性的语言,会尽力在编译期间找到函数的地址,以提高程序的运行效率,但是有时候实在没办法,只能等到程序运行后再执行一段代码(很少的代码)才能找到函数的地址。
上节我们讲到,通过p -> display();语句调用 display() 函数时会转换为下面的表达式:
( *( *(p+0) + 0 ) )§;
这里的 p 有可能指向 People 类的对象,也可能指向 Student 或 Senior 类的对象,编译器不能提前假设 p 指向哪个对象,也就不能确定调用哪个函数,所以编译器干脆不管了,p 爱指向哪个对象就指向哪个对象,等到程序运行后执行一下这个表达式自然就知道了。
有读者可能会问,对于下面的语句:
p = new Senior("李智", 22, 92.0, true);
p -> display();
p 不是已经确定了指向 Senior 类的对象吗,难道编译器不知道吗?对,编译器编译到第二条语句的时候如果向前逆推一下,确实能够知道 p 指向 Senior 类的对象。但是,如果是下面的情况呢?
int n;
cin>>n;
if(n > 100){
p = new Student("王刚", 16, 84.5);
}else{
p = new Senior("李智", 22, 92.0, true);
}
p -> display();
如果用户输入的数字大于 100,那么 p 指向 Student 类的对象,否则就指向 Senior 类的对象,这种情况编译器如何逆推呢?鬼知道用户输入什么数字!所以编译器干脆不会向前逆推,因为编译器不知道前方是什么情况,可能会很复杂,它也无能为力。
这就是动态绑定的本质:编译器在编译期间不能确定指针指向哪个对象,只能等到程序运行后根据具体的情况再决定。
C++ RTTI机制下的对象内存模型(透彻)
上节所示的 Base 和 Derived 的对象内存模型非常简单,读者也很容易理解,它满足了 typeid 运算符在程序运行期间动态地获取表达式的类型信息的需求。在 C++ 中,除了 typeid 运算符,dynamic_cast 运算符和异常处理也依赖于 RTTI 机制,并且要能够通过派生类获取基类的信息,或者说要能够判断一个类是否是另一个类的基类,这样上节讲到的内存模型就不够用了,我们必须要在基类和派生类之间再增加一条绳索,把它们连接起来,形成一条通路,让程序在各个对象之间游走。在面向对象的编程语言中,我们称此为继承链(Inheritance Chain)。
关于 dynamic_cast 运算符和异常处理我们将在后续章节中讲解,这里读者只需要知道它们依赖于 RTTI 机制。
将基类和派生类连接起来很容易,只需要在基类对象中增加一个指向派生类对象的指针,然而考虑到多继承、降低内存使用等诸多方面的因素,真正的对象内存模型比上节讲到的要复杂很多,并且不同的编译器有不同的实现(C++ 标准并没有对对象内存模型的细节做出规定)。
我们以下面的代码为例来展示 Visual C++ 下真正的对象内存模型:
class A{
protected:
int a1;
public:
virtual int A_virt1();
virtual int A_virt2();
static void A_static1();
void A_simple1();
};
class B{
protected:
int b1;
int b2;
public:
virtual int B_virt1();
virtual int B_virt2();
};
class C: public A, public B{
protected:
int c1;
public:
virtual int A_virt2();
virtual int B_virt2();
};
最终的内存模型如下所示(猛击图片可查看大图):
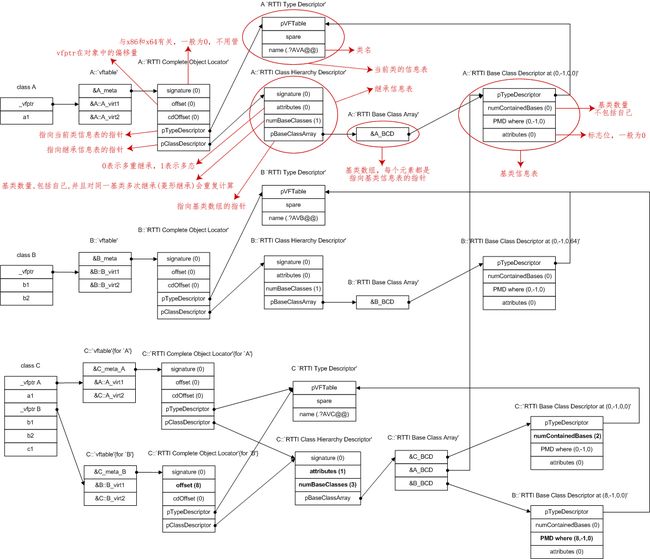
图片来源于 http://www.openrce.org/articles/full_view/23,红色是我加的说明。
从图中可以看出,对于有虚函数的类,内存模型中除了有虚函数表,还会额外增加好几个表,以维护当前类和基类的信息,空间上的开销不小。typeid(type).name() 方法返回的类名就来自“当前类的信息表”。
如果你希望深入了解上图的结构,请查看下面几篇文章:
- VC++逆向:类、方法和 RTTI
- RTTI结构详细分析(VC++)
- C++中RTTI机制剖析
- C++ dynamic_cast实现原理
- dynamic_cast, RTTI, 整理
typeid 经过固定次数的间接转换返回 type_info 对象,间接次数不会随着继承层次的增加而增加,对效率的影响很小,读者可以放心使用。而 dynamic_cast 运算符和异常处理不仅要经过数次间接转换,还要遍历继承链,如果继承层次较深,那么它们的性能堪忧,读者应当谨慎使用!
类型是表达式的一个属性,不同的类型支持不同的操作,例如class Student类型的表达式可以调用 display() 方法,int类型的表达式就不行。类型对于编程语言来说非常重要,编译器内部有一个类型系统来维护表达式的各种信息。
在 C/C++ 中,变量、函数参数、函数返回值等在定义时都必须显式地指明类型,并且一旦指明类型后就不能再更改了,所以大部分表达式的类型都能够精确的推测出来,编译器在编译期间就能够搞定这些事情,这样的编程语言称为静态语言(Static Language)。除了 C/C++,典型的静态语言还有 Java、C#、Haskell、Scala 等。
静态语言在定义变量时通常需要显式地指明类型,并且在编译期间会拼尽全力来确定表达式的类型信息,只有在万不得已时才让程序等到运行后动态地获取类型信息(例如多态),这样做可以提高程序运行效率,降低内存消耗。
与静态语言(Static Language)相对的是动态语言(Dynamic Language)。动态语言在定义变量时往往不需要指明类型,并且变量的类型可以随时改变(赋给它不同类型的数据),编译器在编译期间也不容易确定表达式的类型信息,只能等到程序运行后再动态地获取。典型的动态语言有 JavaScript、Python、PHP、Perl、Ruby 等。
动态语言为了能够使用灵活,部署简单,往往是一边编译一边执行,模糊了传统的编译和运行的过程。例如 JavaScript 主要用来给网页添加各种特效(这是一种简单的理解),浏览器访问一个页面时会从服务器上下载 JavaScript 源文件,并负责编译和运行它。如果我们提前将 JavaScript 源码编译成可执行文件,那么这个文件就会比较大,下载就会更加耗时,结果就是网页打开速度非常慢,这在网络不发达的早期是不能忍受的。
总起来说,静态语言由于类型的限制会降低编码的速度,但是它的执行效率高,适合开发大型的、系统级的程序;动态语言则比较灵活,编码简单,部署容易,在 Web 开发中大显身手。