图(graph)的遍历-----广度优先遍历(BFS)
目录
前言
广度优先遍历(BFS)
1.基本概念
2.算法过程
图的广度优先遍历
1.邻接矩阵
2.邻接表
3.算法比较
前言
上一期学习了图的深度优先遍历,(深度优先遍历:图(graph)的遍历----深度优先(DFS)遍历-CSDN博客)那这一期我们接着学习图的广度优先遍历(BFS),对于图的广度优先遍历我们也不陌生,在二叉树的层序遍历也就是广度优先遍历的一种了。那对于图的广度优先遍历有有什么不同呢?我们接着往下看。
二叉树的层序遍历(广度优先遍历)

广度优先遍历(BFS)
1.基本概念
广度优先搜索(Breadth First Search)简称广搜或者 BFS,是遍历图存储结构的一种算法,既适用于无向图(网),也适用于有向图(网)。
广度优先遍历是一种图和树的遍历策略,它的核心思想是从一个起始节点开始,访问其所有邻近节点,然后再按照相同的方式访问这些邻近节点的邻近节点。这种遍历方式类似于波纹在水面上扩散的过程。
在广度优先遍历中,我们通常使用一个队列(Queue)来存储待访问的节点。初始时,将起始节点放入队列。然后,执行以下操作直到队列为空:
- 从队列中取出一个节点。
- 访问该节点,并将其标记为已访问。
- 将该节点的所有未被访问的邻近节点加入队列。
2.算法过程
下面给大家看一个示例就知道了。
对于上图这么一个图,从顶点V1出发开始进行广度优先遍历,其过程如下:
开始访问V1,然后V1入队进行访问操作。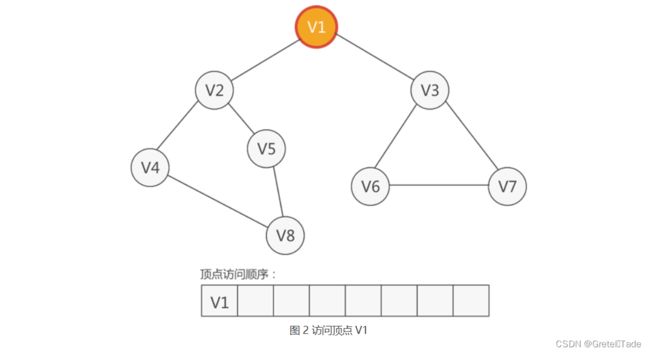
接着就是访问与顶点V1连接的顶点V2和V3,依次入队。
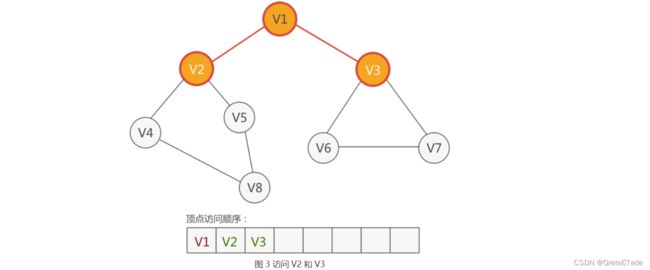
然后就是访问与V3相连的顶点V4,V5依次入队访问。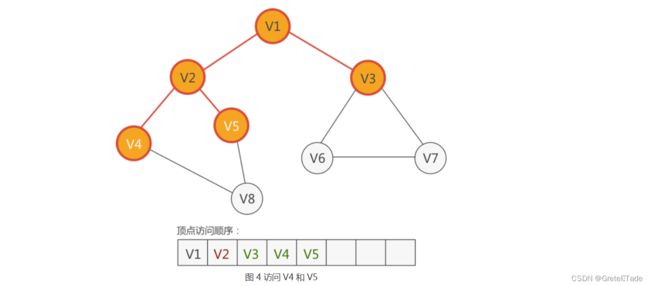
再然后就是与顶点V3相连的顶点V6,V7,执行同样的操作。
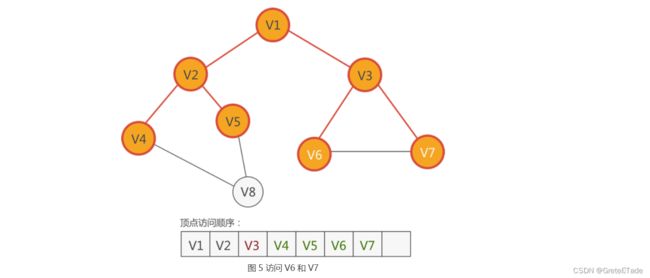 最后就是V8顶点进行访问
最后就是V8顶点进行访问

整体结果如下:
看了上面这几个图,我相信大家都理解了广度优先遍历的次序了吧,无非就是一层一层去访问而已。前面我们说过图的两种存储方式,分别是邻接矩阵和邻接表,那下面我们就去学习邻接矩阵和邻接表的广度优先遍历算法,看看同一个图不同的两种存储方式的遍历结果会有那些不同呢?
图的广度优先遍历
广度优先遍历 (Breadth-First-Search,BFS) 要点:
- 找到与一个顶点相邻的所有顶点
- 标记哪些顶点被访问过,需要一个辅助数组
- 需要一个辅助队列
辅助数组visited作用:
是用来标记访问过的节点,初始化全为0,表示都没有访问过,每次访问了一个节点,下标对应的辅助数组的位置设置为1表示已经访问,下次访问之前先去通过visited数组判断这个节点是否访问过,如果访问过就跳过这个节点,反之就进行访问操作。
辅助队列的作用:
用于储存当前访问节点所连接的节点,然后进行入队操作,要去访问的时候就进行出队的操作。
辅助队列代码如下:
头文件(queue.h)代码:
#pragma once
#include
#include
#include
#include
#include
//数据类型
typedef struct datatype {
char id[10];
//……
}
ElemType;
//定义节点
typedef struct node {
ElemType data;
struct node* next;
}Node;
//定义队列
typedef struct queue {
int count; //计数
Node* front;//指向队头指针
Node* rear;//指向队尾指针
}Queue;
void Queue_init(Queue* queue);//初始化
bool isEmpty(Queue* queue);//判空
void enQueue(Queue* queue, ElemType data);//入队
Node* deQueue(Queue* queue);//出队
ElemType head_data(Queue queue);//获取队头数据
queue.c代码:
#include"queue.h"
//初始化
void Queue_init(Queue* queue) {
assert(queue);
queue->front = NULL;
queue->rear = NULL;
queue->count=0;
}
//创建节点
Node* create_node(ElemType data) {
Node* new_node = (Node*)malloc(sizeof(Node));
if (new_node) {
new_node->data = data;
new_node->next = NULL;
return new_node;
}
else
{
printf("ERRPR\n");
}
}
//判断是否空队列
bool isEmpty(Queue* queue) {
assert(queue);
if (queue->count == 0)
{
return true;
}
return false;
}
//入队
void enQueue(Queue* queue, ElemType data) {
assert(queue);
Node* new_node = create_node(data);
if (queue->rear == NULL) {
queue->front = new_node;
queue->rear = new_node;
queue->count++;
}
else
{
queue->rear->next = new_node;
queue->rear = new_node;
queue->count++;
}
}
//出队
Node* deQueue(Queue* queue) {
assert(queue);
if (!isEmpty(queue)) {
Node* deNode = queue->front;
queue->front = deNode->next;
queue->count--;
return deNode;
}
printf("error\n");
return NULL;
}
//获取队头数据
ElemType head_data(Queue queue) {
return queue.front->data;
}
1.邻接矩阵
广度优先遍历代码如下:
//01--邻接矩阵
#include"queue.h"//导入头文件
#define Maxint 32767
#define Maxnum 100//最大顶点数
ElemType;
//图的邻接数组
typedef struct graph {
ElemType vexs[Maxnum];//图数据
int matrix[Maxnum][Maxnum];//二维数组矩阵
int vexnum;//点数
int arcnum;//边数
}Graph;
//节点id查找下标
int Locate_vex(Graph G, char* id) {
for (int i = 0; i < G.vexnum; i++)
if (strcmp(G.vexs[i].id,id)==0)
return i;
return -1;
}
//节点id查找这个数据体节点
ElemType Locate_data(Graph G, char* id) {
for (int i = 0; i < G.vexnum; i++)
if (strcmp(G.vexs[i].id, id) == 0)
return G.vexs[i];
}
//构造邻接矩阵(无向图,对称矩阵)(有向图)赋权图
void Create_graph(Graph* G) {
printf("请输入顶点个数和边的个数:\n");
scanf("%d %d", &G->vexnum, &G->arcnum);//输入点数边数
printf("请输入顶点数据:\n");
for (int i = 0; i < G->vexnum; i++) {
scanf("%s", G->vexs[i].id);
}
for (int x = 0; x < G->vexnum; x++) {
for (int y = 0; y < G->vexnum; y++) {
if (x == y)
G->matrix[x][y] = 0;//对角线初始化为0
else
G->matrix[x][y] = Maxint;//其他初始化为Maxint
}
}
printf("请输入边相关数据:\n");
for (int k = 0; k < G->arcnum; k++) {
char a[10], b[10];
int w;
scanf("%s %s %d", a, b, &w);
//a->b
int i = Locate_vex(*G, a);
int j = Locate_vex(*G, b);
//矩阵赋值
G->matrix[i][j] = w;
G->matrix[j][i] = w;//删掉这个,表示有向图
}
}
//输出矩阵
void print_matrix(Graph G) {
printf("矩阵为:\n");
for (int i = 0; i < G.vexnum; i++) {
for (int j = 0; j < G.vexnum; j++) {
if (G.matrix[i][j] == Maxint)
printf("∞\t");
else
printf("%d\t", G.matrix[i][j]);
}
printf("\n");
}
printf("图的顶点个数和边数:%d,%d\n", G.vexnum, G.arcnum);
}
//访问输出
void visit(Graph G,int loca) {
printf("%s ", G.vexs[loca].id);
}
//广度优先遍历BFS
void BFS(Graph G, char* id) {
//辅助数组,标记是否访问过
int* visited = (int*)malloc(sizeof(int) * G.vexnum);
memset(visited, 0, sizeof(int) * G.vexnum);//初始化为0表示未访问过
ElemType begin = Locate_data(G, id);//通过输入的id找到这个数据节点
Queue q;//定义队列
Queue_init(&q);//初始化队列
enQueue(&q, begin);//把第一个节点进行入队操作
visited[Locate_vex(G,id)] = 1;//visited对应的位置标记为1,表示这个节点已经入队,将进行访问操作
while (!isEmpty(&q)) {//进入到循环
int location = Locate_vex(G, head_data(q).id);//找到队头节点在图中的位置(下标)
//把当前队头节点相连的节点依次入队操作
for (int i = 0; i < G.vexnum; i++) {
if (G.matrix[location][i] != 0 && !visited[i]) {
enQueue(&q, G.vexs[i]);
visited[i] = 1;//入队后标记为1,
}
}
Node*v = deQueue(&q);//进行出队操作
location = Locate_vex(G, v->data.id);
visit(G, location);//访问
}
free(visited);
visited = NULL;
}
main函数,测试代码:
int main() {
Graph G;
Create_graph(&G);
print_matrix(G);
printf("\nBFS:\n");
BFS(G, "B");
}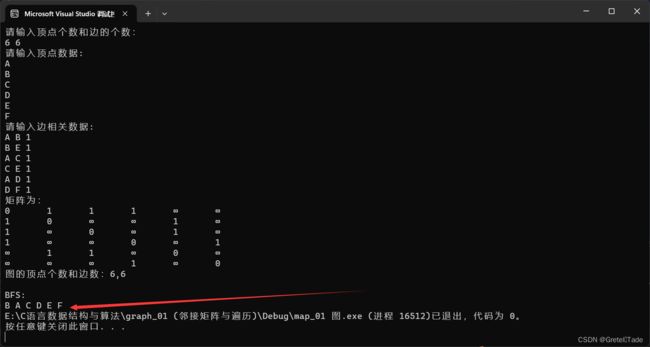
输入的图结构如图所示:
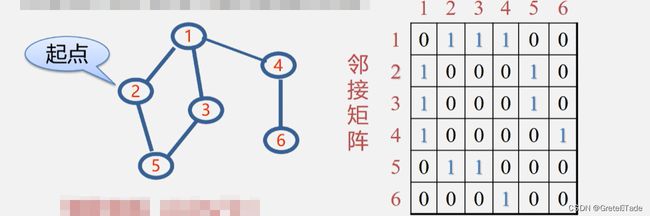
2.邻接表
代码如下:
//02--邻接表
#include"queue.h"
//边节点存储结构
typedef struct arcnode {
int index;//指向顶点的位置
int weight;//权
struct arcnode* nextarc;//指向下一个边节点
}Anode;
//顶点结点存储结构
typedef struct vexnode {
ElemType data;
Anode* firstarc;
}Vhead;
//图结构
typedef struct {
Vhead* vertices;
int vexnum;
int arcnum;
}Graph;
//顶点id查找下标
int Locate_vex(Graph G, char* id) {
for (int i = 0; i < G.vexnum; i++)
if (strcmp(G.vertices[i].data.id,id)==0)
return i;
return -1;
}
//顶点编号查找整个数据
ElemType Locate_data(Graph G, char* id) {
int index;
for (int i = 0; i < G.vexnum; i++) {
if (strcmp(G.vertices[i].data.id, id) == 0) {
index = i;
break;
}
}
return G.vertices[index].data;
}
//创建头节点
void Create_vexhead(Graph *G,int n) {
G->vertices = (Vhead*)malloc(sizeof(Vhead) *n);
if (!G->vertices) {
printf("ERROR\n");
exit(-1);
}
else {
for (int i = 0; i < n ; i++) {
scanf("%s", G->vertices[i].data.id);
G->vertices[i].firstarc = NULL;
}
}
}
//创建一个边节点
Anode* Create_arcnode(int loca, int w) {
Anode* arc = (Anode*)malloc(sizeof(Anode));
if (!arc)
{
printf("ERROR\n");
exit(-1);
}
arc->index = loca;
arc->nextarc = NULL;
arc->weight = w;
return arc;
}
//创建邻接表(无向图)(有向图)
void Create_graph(Graph* G) {
printf("输入顶点数和边数:\n");
scanf("%d %d", &G->vexnum, &G->arcnum);
printf("输入顶点数据:\n");
Create_vexhead(G, G->vexnum);
printf("输入边数据:\n");
for (int k = 0; k arcnum; k++) {
ElemType a, b;
int w;
scanf("%s%s%d", a.id, b.id, &w);
int i = Locate_vex(*G, a.id);
int j = Locate_vex(*G, b.id);
//头插法
//a->b
Anode* p = Create_arcnode(j, w);
p->nextarc = G->vertices[i].firstarc;
G->vertices[i].firstarc = p;
//如果创建有向图的话,直接把下面的代码删掉即可
//b->a
Anode* q = Create_arcnode(i, w);
q->nextarc = G->vertices[j].firstarc;
G->vertices[j].firstarc = q;
}
}
//访问
void visit(Graph G, int index) {
printf("%s ", G.vertices[index].data.id);
}
//输出图
void print(Graph G) {
printf("以下是图的顶点连接关系:\n");
for (int i = 0; i < G.vexnum; i++) {
printf("%s:", G.vertices[i].data.id);
Anode* cur= G.vertices[i].firstarc;
while (cur) {
visit(G, cur->index);
cur = cur->nextarc;
}
printf("\n");
}
printf("顶点和边数分别是:%d %d\n", G.vexnum, G.arcnum);
}
//广度优先遍历BFS
void BFS(Graph G, char* begin_id) {
//visited 标记是否访问
int* visited = (int*)malloc(sizeof(int) * G.vexnum);
memset(visited, 0, sizeof(int) * G.vexnum);//初始化0
ElemType begin = Locate_data(G, begin_id);
//初始化队列
Queue qu;
Queue_init(&qu);
//起点入队
enQueue(&qu, begin);
visited[Locate_vex(G, begin_id)] = 1;
while (!isEmpty(&qu)) {
int index=Locate_vex(G,head_data(qu).id);//获取当前队头元素的图位置
Anode* cur = G.vertices[index].firstarc;//获取队头连接的顶点位置
while (cur) {
if (visited[cur->index] == 0) {
//如果是未访问过的话,就进行入队操作
enQueue(&qu, G.vertices[cur->index].data);
visited[cur->index] = 1;
}
cur = cur->nextarc;
}
//出队列,遍历
Node* p = deQueue(&qu);
visit(G, Locate_vex(G, p->data.id));
}
free(visited);
visited = NULL;
}
int main() {
Graph G;
Create_graph(&G);
print(G);
printf("广度优先遍历结果:\n");
BFS(G, "A");
} 测试结果:

3.算法比较
时间复杂度
邻接矩阵
如果使用邻接矩阵,则BFS对于每一个被访问到的顶点,都要循吓检测矩阵中的整整一行( n个元素),总的时间代价为O(n^2)。
邻接表
用邻接表来表示图,虽然有2e个表结点,但只需扫描e个结点即可完成遍历,加上访问n个头结点的时间,时间复杂度为O(n+e)。
空间复杂度
空间复杂度相同,都是O(n)(借用了堆栈或队列) 。
以上就是本期的全部内容了,我们下次见咯!
分享一张壁纸: