HashMap的扩容源码分析
hashmap扩容
| oldCap | newCap |
|---|---|
| oldCap=0 && threshold ==0(没有指定容量) | 16 |
| oldCap=0 && threshold >0 (指定了容量) | cap = threshold |
| 0 < oldCap < MAXIMUM_CAPACITY (一般情况) | 原容量2倍 |
| oldCap>= MAXIMUM_CAPACITY(长度超过规定最大值) | 不扩容 |
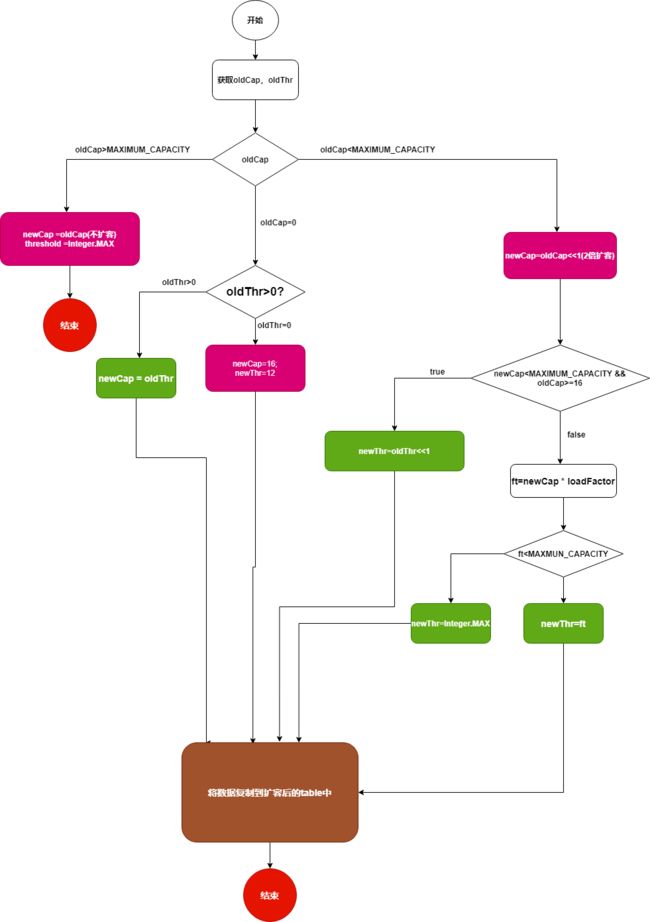
我们可以看到即使进入到resize方法也未必会扩容,如果 oldCap>= MAXIMUM_CAPACITY时,即使超过扩容阈值也不会对原数组扩容;;
下面我们看源码实现:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {//当oldCap >= MAXIMUM_CAPACITY(1<<30)时,不扩容;
threshold = Integer.MAX_VALUE;//阈值设置为最大整数
return oldTab;
}
//oldCap < MAXIMUM_CAPACITY 时,扩容:newCap = oldCap << 1;
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 2倍oldThr
}
else if (oldThr > 0) //创建对象时,指定了容量大小;
newCap = oldThr;
else { // 初始化时newCap = 16;newThr = 16 * 0.75 = 12;
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {//设置新阈值newThr,
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {//将oldTab的数据复制到newTab中
}
看到上面有一段逻辑
if (oldCap > 0) {
....
}
else if(oldThr >0){
.....
}
为什么会有这样的判断?原因是什么?因为我们知道thr = cap * loadFactor;如果cap=0,那thr也就等于0;那为什么还要做这种判断呢?
原因:在HashMap的构造方法中可以指定HashMap的容量,在这个时候会初始化threshold的值,并且不会创建table,因此会出现oldCap=0,而oldThr!=0的情况;
总结resize的流程图:
---------------------------------------------------------------------------------UPDATE---------------------------------------------------------------------
HashMap数据迁移
HashMap中,table的长度 :len 是 2n ,并且计算下标 使用的是: hash & (len - 1) ;并且每次扩容都是 2 倍扩容;newLen = 2 * oldLen;综合以上这些信息使得被迁移的数据有一个特点:每一个node的坐标只有2种取值: i(不变),(i + len);

我们仔细观察,扩容前后的坐标;可以看出来同一个hash值,在扩容前后的坐标变化,扩容后只有高位多了一位 ,其余位置上没有变化;高位 x 只有 0 ,1 这两种取值;
- 最高位 x=0;和扩容前坐标一样: i;
- 最高位 x=1;比 扩容前坐标 增加 16(len)值为:(i + len) ;

经过上面的分析,我们知道同一个node扩容后,下标的取值只有2种;而同一条链表上的节点,对应的数组下标都是一样的;因此,同一条链表在扩容之后可能会 分出2条链表;只需要遍历链表就可以将其分离成2条链表然后分别将2条链表 的表头迁移到新数组这样就完成了这条链表的数据迁移了;
红黑树也是一样的,红黑树也会分化出2条TreeNode链表;这个必须要清楚一点的是,TreeNode同时维护了 双向链表 和 红黑树 这2种结构;也就是说TreeNode也可以看作是链表;这样扩容的处理就和链表一样了;
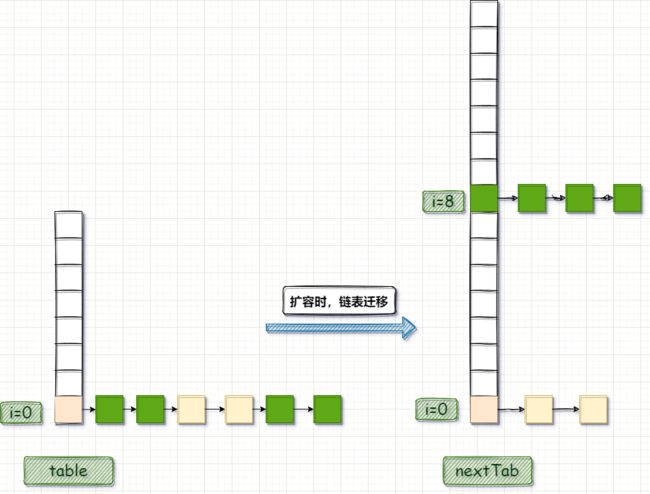
有了上面的理解之后再看扩容过程就简单很多了;从下标位置: 0 -> len -1 ;开始迁移数据:
- 首先要检查下标位置上是否有数据;
- 没有数据,就继续下个位置的数据迁移;
- 有数据,就检查是TreeNode红黑树还是 普通Node链表;
- 分别遍历 TreeNode ,Node链表;TreeNode分离开后还要检查下TreeNode链表的长度;如果大于8,还要将TreeNode链表重新转换成红黑树;小于 8 ,就将TreeNode链表转换成 Node链表;
前面分析到使用扩容后长度可以计算扩容后的node坐标;坐标值大于 n,就是坐标更改了;小于 n,坐标值就没变;但是hashMap没有使用这种方法,而是使用了另一种方法,计算出下标的偏移量:hash & len(旧数组长度) ;偏移量也只会有2种取值:0,len;偏移量等于 0 ,说明下标没变;不等于 0 ,说明下标为 :i + len ;

上图可以很直观的看出来hash & len:的结果只有 2种取值;
- 高位 x = 0 ;偏移量 等于 0 ;
- 高位 x = 1;偏移量等于 16(len);
因此只需要判断偏移量的值是否为0,就可以分辨出node节点扩容后坐标是否改变;在源码中,使用2条新链表来接收原链表的数据:
- loHead(表头) ,loTail(表尾) :由扩容后坐标不变的节点组成;
- hiHead (表头), hiTail(表尾):由扩容后坐标更改(i + n)的节点组成;
扩容源码:
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {//旧数组
for (int j = 0; j < oldCap; ++j) {//从下标 0 开始迁移数据
Node<K,V> e;
if ((e = oldTab[j]) != null) {//判断下标 i 位置上是否有数据
oldTab[j] = null;
if (e.next == null)//这个位置上没有形成Node链表,只有一个Node节点
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)//红黑树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // Node链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {//循环遍历Node链表,分离出2条链表:loTail是坐标不变的链表表头;hiTail是下标为 i + n的表头;
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//分别将loTail ,hiTail 插入到新数组
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
- 1.遍历链表,将原链表分离成2条链表:loHead,hiHead

- 分别将2条链表插入到新数组中:

红黑树的扩容源码就不贴出来分析了,都是一样的;最后会判断分离出来的TreeNode链表长度:
- 大于等于 8 ,要将TreeNode链表重新转换成红黑树;
- 小于 8 ,就将TreeNode链表转换成Node链表;