【大数据】Hadoop
文章目录
-
- 概述
- Hadoop组成
- HDFS
- MapReduce
-
- 写MapReduce程序(Hadoop streaming)
- YARN
-
- Hadoop 启动
- 工作方式
-
- Hadoop的主从工作方式
- Hadoop的守护进程
- 运行模式
-
- 本地运行模式
- 伪分布式运行模式
- 完全分布式运行模式
- Hadoop高可用的解决方案
-
- ZooKeeper quorum
- ZKFC
- 环境搭建
-
- 虚拟机环境准备
- 安装 jdk
- 安装 Hadoop
- FIFO 调度器
- 容量调度器(Capacity Scheduler)
- 公平调度器(Fair Scheduler)
- 分布式缓存
-
- 分布式缓存优点
- 分布式缓存的使用
- 分布式缓存的大小
- 命令
-
- 常规选项
- 从本地模式到分布式集群计算
- 来源
概述
Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会开发和维护。
Hadoop 为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集,并且支持在单台计算机到几千台计算机之间进行扩展。
Hadoop 使用 Java 开发,所以可以在多种不同硬件平台的计算机上部署和使用。其核心部件包括分布式文件系统 (Hadoop DFS,HDFS) 和 MapReduce。
大数据生态体系:
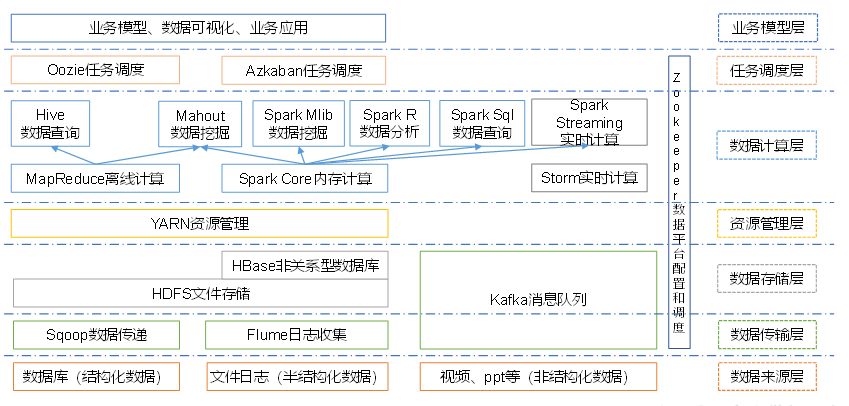
Hadoop组成

以上的各个组件都是属于Hadoop的生态系统的,如果想入门大数据,都是需要学习,它们分别是:
- Hadoop HDFS(核心):Hadoop 分布式存储系统;
- Yarn(核心):Hadoop 2.x版本开始才有的资源管理系统;
- MapReduce(核心):并行处理框架;
- HBase:基于HDFS的列式存储数据库,它是一种 NoSQL 数据库,非常适用于存储海量的稀疏的数据集;
- Hive:Apache Hive是一个数据仓库基础工具,它适用于处理结构化数据。它提供了简单的 sql 查询功能,可以将sql语句转换为MapReduce任务进行运行;
- Pig:它是一种高级脚本语言。利用它不需要开发Java代码就可以写出复杂的数据处理程序;
- Flume:它可以从不同数据源高效实时的收集海量日志数据;
- Sqoop:适用于在 Hadoop 和关系数据库之间抽取数据;
- Oozie:这是一种 Java Web 系统,用于Hadoop任务的调度,例如设置任务的执行时间和执行频率等;
- Zookeeper:用于管理配置信息,命名空间。提供分布式同步和组服务;
- Mahout:可扩展的机器学习算法库。
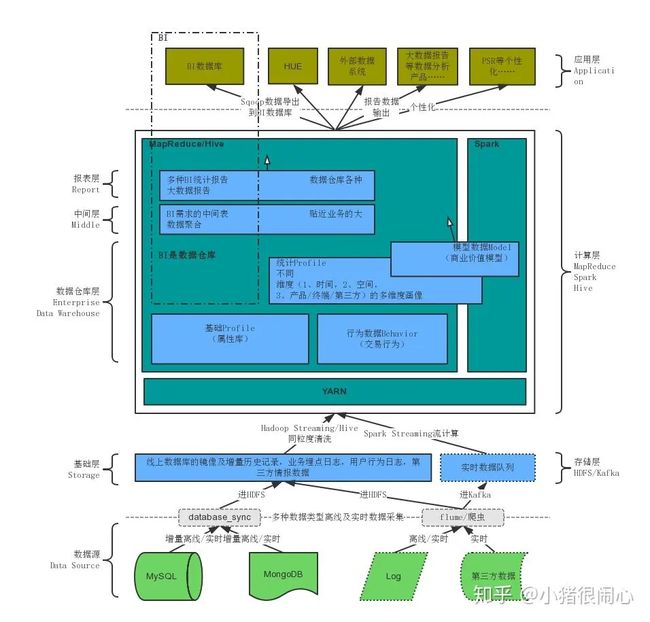
HDFS
HDFS :即 Hadoop 分布式文件系统(Hadoop Distribute File System),以分布式存储的方式存储数据。
HDFS 也是一种 Master-slave 架构,NameNode 是运行 master 节点的进程,它负责命名空间管理和文件访问控制。DataNode 是运行在 slave 节点的进程,它负责存储实际的业务数据,如下图:

Namenode:
即master,有以下功能
*管理文件系统命名空间;
*控制client对数据的读取和写入请求;
*管理数据块到datanode的映射关系;
*管理副本策略。
Datanode:
即slave,主要是存储文件块数据,接受来自namenode的指令,并执行指令对数据块的创建,删除,复制等操作。
Client:
即客户端,有以下功能:
*对文件的切分,HDFS上传数据时,client将文件切分成多个block再进行上传;
*与namenode交互,获取文件的索引信息;
*与datanode交互,对数据的读取和写入;
*在客户端中提供相关HDFS的命令,比如对HDFS的管理,格式化namenode,对HDFS对数据操作,比如上传文件到HDFS等。
Secondary namenode:
并非namenode的热备,当namenode挂掉的时候,并不能立马替换namenode并提供服务,只是在定时的对namenode进行备份,存在一定的时间误差,secondary会备份namenode的Fsimage和Edits,在紧急情况下,可以适用secondarynamenode来恢复部分的namenode。
关于大数据学习,Hadoop HDFS存储入门,以上就为大家做了简单的介绍了。在Hadoop大数据框架当中,HDFS作为分布式文件系统,始终是重要的核心组件,学习当中也自然需要深入理解掌握。
MapReduce
Hadoop MapReduce 是一种编程模型,它是 Hadoop 最重要的组件之一。它用于计算海量数据,并把计算任务分割成许多在集群并行计算的独立运行的 task。
MapReduce 是 Hadoop的核心,它会把计算任务移动到离数据最近的地方进行执行,因为移动大量数据是非常耗费资源的。
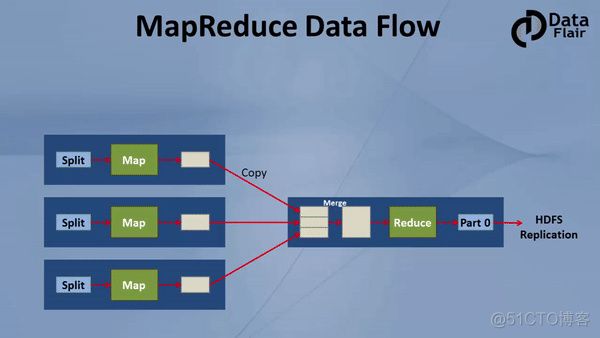
MapReduce运行过程,通常涉及到input、split、map、shuffle、reduce、output几个阶段,其中shuffle过程包括sort、copy、combine操作,reduce之前有时涉及二次排序。
MapReduce编程,主要有三种方式:
1、Hadoop streaming执行mapreduce
2、Hive执行mapreduce
3、Java MR编程
①Hadoop streaming执行MapReduce
优点:
可以用大多数语言开发;
代码量少,开发速度快;
方便本地调试。
不足:
只能通过参数控制MR框架,控制性较弱,比如定制partitioner、combiner;
支持的数据类型和数据结构有限,不适合做复杂处理,处理字符型较多;
②Hive执行MapReduce
将类SQL转换成MapReduce,定位于数据仓库。
优点:
开发速度快,易调试,易理解;
易于构建数据仓库模型;
内置函数功能齐全,比如rownumber等窗口函数;
可扩展性好,比如自定义存储格式、自定义函数UDF;
多接口,比如JDBC、Thrift、Rest等。
缺点:
不能用于复杂计算,比如涉及时序处理的数据;
可控制性较弱,比如partition、关联等操作。
③Java MR编程
用Java编写MR,可以说是最“原始”的一种方式,Java面向对象编程,设计模式成熟,通用性好,并且Java方面第三方类库非常丰富。
优点:
定制性强,比如定制partitioner、定制combiner等;
数据类型和数据结构丰富,队列、堆栈、自定义类等使用方便;
控制性非常高,包括MR运行过程的一些控制,Map端join等;
可以方便使用Hadoop组件类库中的类或工具,比如HDFS文件操作类等。
缺点:
相比Hive、Hadoop streaming或Pyspark,开发代码量较大,对开发环境要求高且不易调试;
通常每个操作都要写一个MR类;
不如Spark执行效率高。
写MapReduce程序(Hadoop streaming)
Hadoop Streaming使用Unix标准流作为Hadoop和应用程序之间的接口,允许程序员用多种语言写MapReduce程序。
Streaming天生适合于文本处理。map的输入数据通过标准输入传递给map函数,并且是一行一行地传输,并且将结果行写到标准输出。map输出的键-值对是以一个制表符分隔的行,reduce输入格式与之相同。reduce函数从标准输入流中读取输入行,该输入已经由Hadoop框架根据键排过序,最后将结果写入标准输出。
接下里我们用Streaming重写按年份查找最高气温的MapReduce程序。
Map函数
import re
import sys
for line in sys.stdin:
val = line.strip()
(year,temp,q) = (val[15:19],val[87:92],val[92:93])
if (temp != "+9999" and re.match("[01459]",q)
print ("%s\t%s" % (year,temp))
Reduce函数
import sys
(last_key,max_val) = (None,-sys.maxint)
for line in sys.stdin:
(key,val) = line.strip().split("\t")
if last_key and last_key != key:
print ("%s\t%s" % (last_key,max_val))
(last_key,max_val) = (key,int(val))
else:
(last_key,max_val = (key,max(max_val,int(val)))
if last_key:
print("%s\t%s" % (last_key,max_val))
YARN
Yarn :是一个资源管理系统,其作用就是把资源管理和任务调度/监控功分割成不同的进程,Yarn 有一个全局的资源管理器叫 ResourceManager,每个 application 都有一个 ApplicationMaster 进程。一个 application 可能是一个单独的 job 或者是 job 的 DAG (有向无环图)。
Yarn 具有下面这些特性:
- 多租户:Yarn允许在同样的 Hadoop数据集使用多种访问引擎。这些访问引擎可能是批处理,实时处理,迭代处理等;
- 集群利用率:在资源自动分配的情况下,跟早期的Hadoop 版本相比,Yarn拥有更高的集群利用率;
- 可扩展性:Yarn可以根据实际需求扩展到几千个节点,多个独立的集群可以联结成一个更大的集群;
在 Yarn 内部有两个守护进程:
- ResourceManager :负责给 application 分配资源
- NodeManager :负责监控容器使用资源情况,并把资源使用情况报告给
ResourceManager。这里所说的资源一般是指CPU、内存、磁盘、网络等。
ApplicationMaster 负责从 ResourceManager 申请资源,并与 NodeManager 一起对任务做持续监控工作。
Container
容器(Container)这个东西是 Yarn 对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn 对资源的管理也是用到了这种思想。
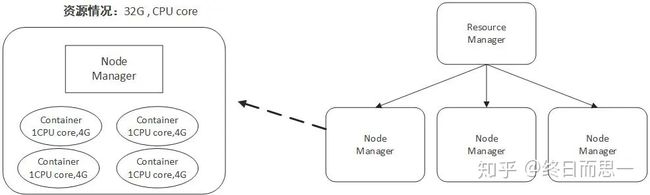
如上所示,Yarn 将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
- 容器由 NodeManager 启动和管理,并被它所监控。
- 容器被 ResourceManager 进行调度。
ResourceManager(RM)
从名字上我们就能知道这个组件是负责资源管理的,整个系统有且只有一个 RM ,来负责资源的调度。它也包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
- 定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当 Client
提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。 - 应用管理器(ApplicationManager):应用管理器就是负责管理 Client
用户提交的应用。定时调度器(Scheduler)不对用户提交的程序监控,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
ApplicationMaster
每当 Client 提交一个 Application 时候,就会新建一个 ApplicationMaster 。由这个 ApplicationMaster 去与 ResourceManager 申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
NodeManager
NodeManager 是 ResourceManager 在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler 提供这些资源使用报告。
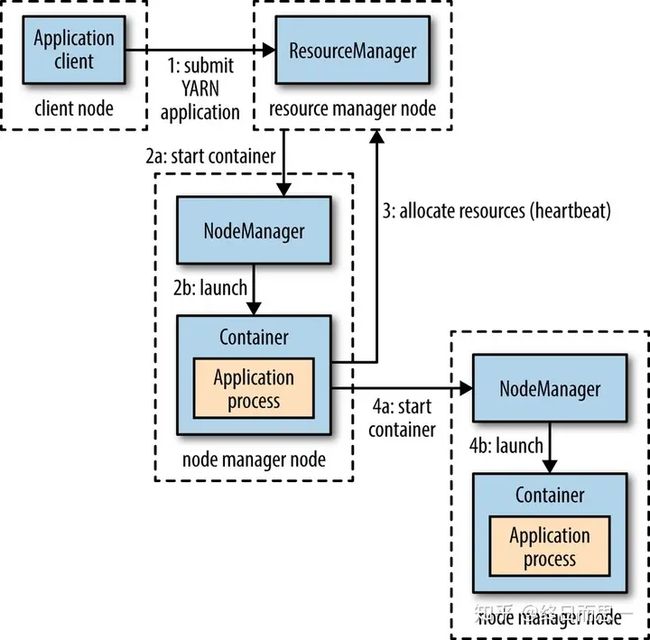
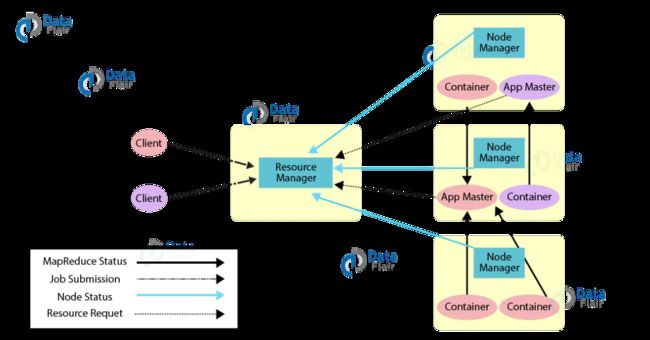
这张图简单地标明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程。
- Client 向 Yarn 提交 Application,这里我们假设是一个 MapReduce 作业。
- ResourceManager 向 NodeManager 通信,为该 Application分配第一个容器。并在这个容器中运行这个应用程序对应的 ApplicationMaster。
- ApplicationMaster 启动以后,对 作业(也就是 Application) 进行拆分,拆分 task 出来,这些 task可以运行在一个或多个容器中。然后向 ResourceManager 申请要运行程序的容器,并定时向 ResourceManager发送心跳。
- 申请到容器后,ApplicationMaster 会去和容器对应的 NodeManager 通信,而后将作业分发到对应的NodeManager 中的容器去运行,这里会将拆分后的 MapReduce 进行分发,对应容器中运行的可能是 Map 任务,也可能是Reduce 任务。
- 容器中运行的任务会向 ApplicationMaster 发送心跳,汇报自身情况。当程序运行完成后, ApplicationMaster再向 ResourceManager 注销并释放容器资源。
Hadoop 启动
格式化namenode
hadoop namenode -format
启动hdfs
start-all.sh

查看相应进程
jps
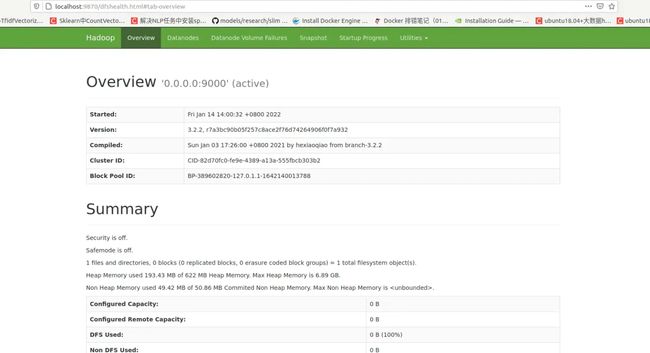
浏览器访问
localhost:9870
工作方式
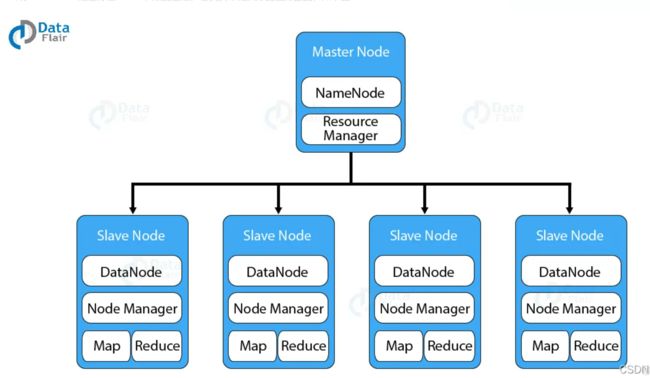
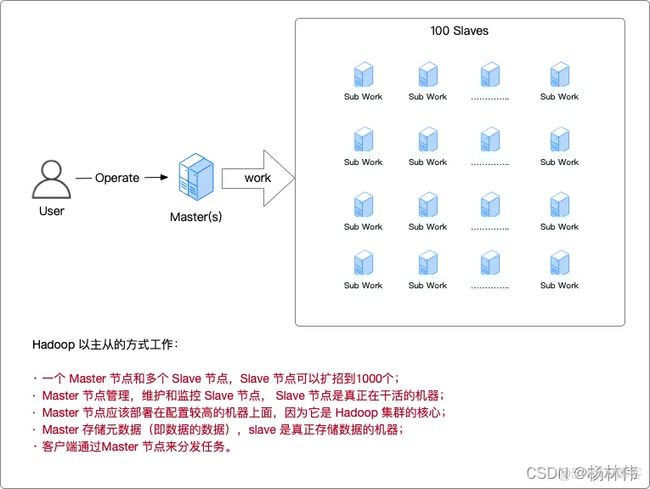
Hadoop的主从工作方式
Hadoop 以主从的方式工作(如下图):
Hadoop的守护进程

Hadoop 主要有4个守护进程:
- NameNode :它是HDFS运行在Master节点守护进程。
- DataNode:它是 HDFS 运行在Slave节点守护进程。
- ResourceManager:它是 Yarn 运行在 Master 节点守护进程。
- NodeManager:它是 Yarn 运行在 Slave 节点的守护进程。
除了这些,可能还会有 secondary NameNode,standby NameNode,Job HistoryServer 等进程。
运行模式
Hadoop 的运行模式包括:本地模式、伪分布式模式、完全分布式模式。
本地运行模式
官方 Grep 案例
在 hadoop-2.7.7 文件下面创建一个 input 文件夹
mkdir input
将 Hadoop 的 xml 配置文件复制到 input
cp etc/hadoop/*.xml input
在 hadoop-2.7.7 目录下,执行 share 目录下的 MapReduce 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input/ output 'dfs[a-z.]+'
查看输出结果

官方 WordCount 案例
在 hadoop-2.7.7 文件下面创建一个 wcinput 文件夹
mkdir wcinput
在 wcinput 文件下创建一个 wc.input 文件
vim wc.input
在文件中输入以下内容:
hadoop yarn
hadoop mapreduce
spark
spark
在 hadoop-2.7.7 目录下,执行 share 目录下的 MapReduce 程序
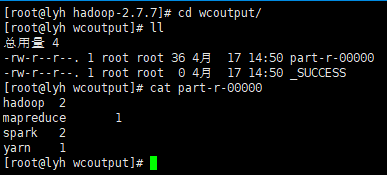
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput/ wcoutput
查看结果
伪分布式运行模式
启动 HDFS 并运行 MapReduce 程序
配置集群,修改 Hadoop 的配置文件(/hadoop/hadoop-2.7.7/etc/hadoop 目录下)
① core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://lyh:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/hadoop/hadoop-2.7.7/data/tmpvalue>
property>
configuration>
② hadoop-env.sh
修改 JAVA_HOME 路径:
# The java implementation to use.
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
③ hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
启动集群
① 格式化 NameNode(第一次启动时格式化,以后就不要总格式化)
hdfs namenode -format
② 启动 NameNode
hadoop-daemon.sh start namenode
③ 启动 DataNode
hadoop-daemon.sh start datanode
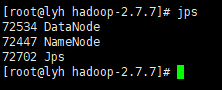
查看集群
① 查看是否启动成功
② web 端查看 HDFS 文件系统
http://192.168.217.129:50070
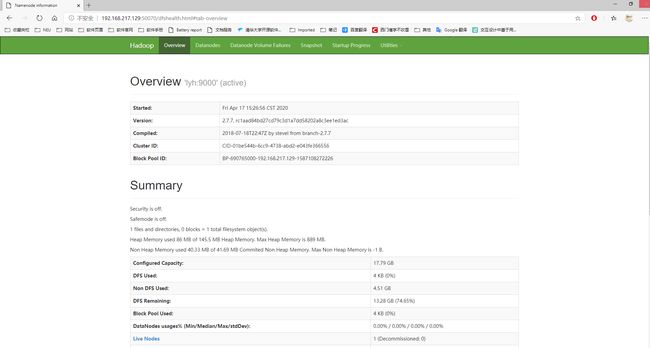
操作集群
① 在 HDFS 文件系统上创建一个 input 文件夹
hdfs dfs -mkdir -p /user/lyh/input
② 将测试文件内容上传到文件系统上
hdfs dfs -put wcinput/wc.input /user/lyh/input/
③ 在 hadoop-2.7.7 目录下,运行 MapReduce 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/lyh/input/ /user/lyh/output
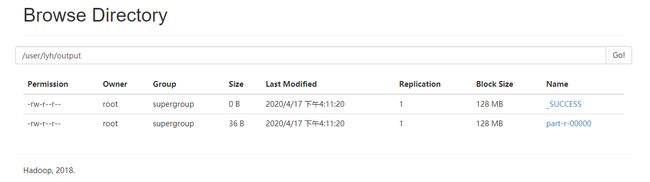
④ 查看输出结果
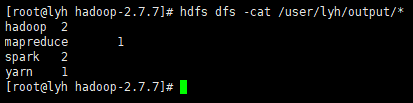
命令行查看:
hdfs dfs -cat /user/atguigu/output/*
浏览器页面查看:
启动 YARN 并运行 MapReduce 程序
配置集群,修改 Hadoop 的配置文件(/hadoop/hadoop-2.7.7/etc/hadoop 目录下)
① yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>lyhvalue>
property>
configuration>
② yarn-env.sh
修改 JAVA_HOME 路径:
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
③ mapred-env.sh
修改 JAVA_HOME 路径:
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
④ 将 mapred-site.xml.template 重新命名为 mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
启动集群
① 启动前必须保证 NameNode 和 DataNode 已经启动
② 启动 ResourceManager
yarn-daemon.sh start resourcemanager
③ 启动NodeManager
yarn-daemon.sh start nodemanager
查看集群
① 查看是否启动成功
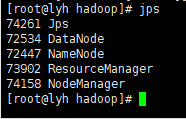
② web 端查看 YARN 页面
http://192.168.217.129:8088
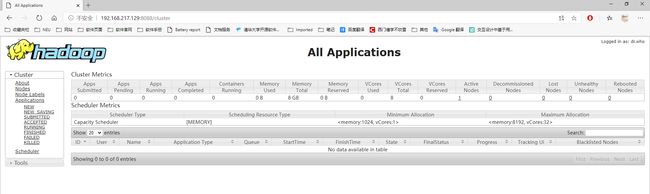
操作集群
① 删除 HDFS 文件系统上的 output 文件
hdfs dfs -rm -R /user/lyh/output
② 在 hadoop-2.7.7 目录下,运行 MapReduce 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/lyh/input /user/lyh/output
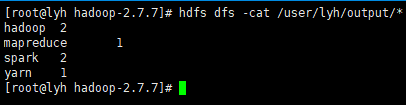
③ 查看运行结果
命令行查看:
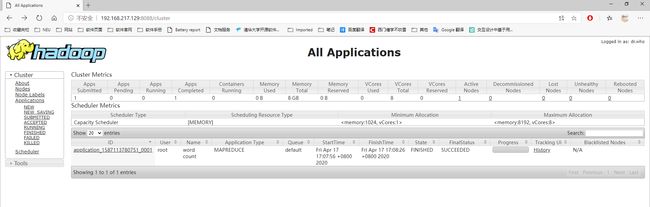
hdfs dfs -cat /user/lyh/output/*
浏览器页面查看:
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。
配置 mapred-site.xml
在该文件里面增加以下配置:
<property>
<name>mapreduce.jobhistory.addressname>
<value>lyh:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>lyh:19888value>
property>
启动历史服务器
mr-jobhistory-daemon.sh start historyserver
查看历史服务器是否启动
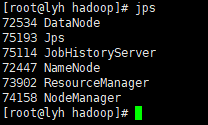
查看 JobHistory
http://192.168.217.129:19888/
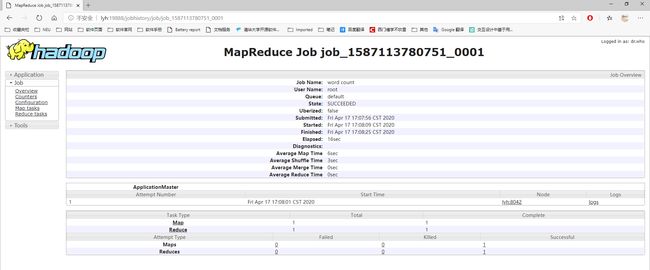
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和 HistoryManager。
关闭 NodeManager 、ResourceManager 和 HistoryManager
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver
配置 yarn-site.xml
在该文件里面增加以下配置:
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
启动 NodeManager 、ResourceManager 和 HistoryManager
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver
删除HDFS上已经存在的输出文件
hdfs dfs -rm -R /user/lyh/output
在 hadoop-2.7.7 目录下,执行 WordCount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/lyh/input /user/lyh/output
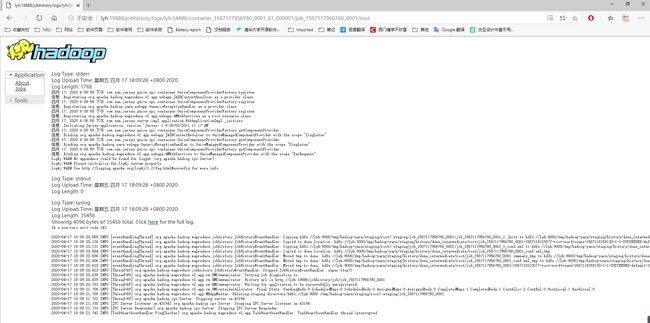
查看日志
完全分布式运行模式
虚拟机准备
| 主机名称 | IP地址 |
|---|---|
| master | 192.168.217.130 |
| slave1 | 192.168.217.131 |
| slave2 | 192.168.217.132 |
每台机器分别修改 /etc/hosts 文件,将每个机器的 hostname 和 ip 对应
vim /etc/hosts
192.168.217.130 master
192.168.217.131 slave1
192.168.217.132 slave2
编写集群分发脚本 xsync
scp(secure copy)安全拷贝
① scp 定义:
scp 可以实现服务器与服务器之间的数据拷贝。
② 基本语法:
scp -r 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
rsync(remote synchronize)远程同步工具
① rsync 定义:
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更新。scp 是把所有文件都复制过去。
② 基本语法:
rsync -rvl 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
说明:-v:显示复制过程 、-l:拷贝符号链接
xsync 集群分发脚本
需求:循环复制文件到所有节点的相同目录下
① 在 /usr/local/bin 目录下创建 xsync 文件
vim xsync
在文件中输入以下内容:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for i in master slave1 slave2
do
echo "****************** $i *********************"
rsync -rvl $pdir/$fname $user@$i:$pdir
done
② 修改脚本 xsync 具有执行权限
chmod 777 xsync
③ 调用脚本形式:xsync 文件名称
集群配置
集群部署规划
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNodeDataNode |
| YARN | NodeManager | ResourceManagerNodeManager | NodeManager |
配置集群
⑴ 配置核心文件
配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/hadoop/hadoop-2.7.7/data/tmpvalue>
property>
configuration>
⑵ HDFS 配置文件
① 配置 hadoop-env.sh
修改 JAVA_HOME 路径:
# The java implementation to use.
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
② 配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>slave2:50090value>
property>
configuration>
⑶ YARN 配置文件
① 配置 yarn-env.sh
修改 JAVA_HOME 路径:
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
② 配置 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>slave1value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
⑷ MapReduce 配置文件
① 配置 mapred-env.sh
修改 JAVA_HOME 路径:
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
② 配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
configuration>
在集群上分发配置好的 Hadoop 目录
xsync /hadoop/
集群单点启动
如果集群是第一次启动,需要格式化 NameNode
hadoop namenode -format
在 master上启动 NameNode
hadoop-daemon.sh start namenode
在 master、slave1 和 slave2 上分别启动 DataNode
hadoop-daemon.sh start datanode
配置 SSH 无密登录
免密登录原理
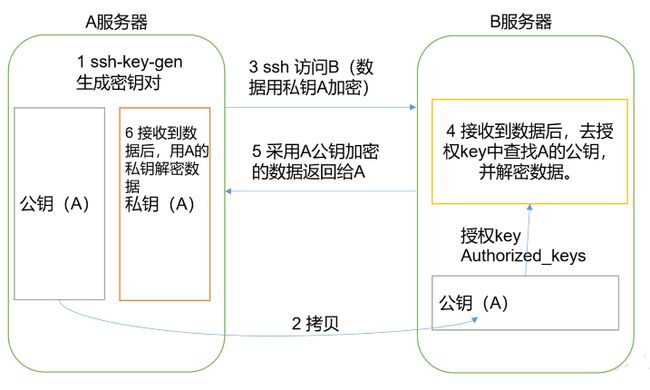
生成公钥和私钥
在 /root 目录下输入:
ssh-keygen -t rsa
然后敲(三个回车),就会在 .ssh 目录下生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
在另两台机器上也做 2、3 操作
群起集群
配置 slaves(/hadoop/hadoop-2.7.7/etc/hadoop/slaves)
① 在该文件中增加如下内容:
master
slave1
slave2
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
② 同步所有节点配置文件
xsync slaves
启动集群
① 如果集群是第一次启动,需要格式化 NameNode (注意格式化之前,一定要先停止上次启动的所有 namenode 和 datanode 进程,然后再删除 data 和 log 数据)
hdfs namenode -format
② 启动 HDFS
start-dfs.sh
③ 启动 YARN(slave1 上)
注意:NameNode 和 ResourceManger 如果不是同一台机器,不能在 NameNode 上启动 YARN,应该在 ResouceManager 所在的机器上启动 YARN。
start-yarn.sh
编写查看集群所有节点 jps 脚本 alljps
① 在 /usr/local/bin 目录下创建文件 alljps
vim alljps
在文件中输入以下内容:
#!/bin/bash
for i in master slave1 slave2
do
echo "****************** $i *********************"
ssh $i "source /etc/profile && jps"
done
② 修改脚本 alljps 具有执行权限
chmod 777 alljps
③ 调用脚本形式:alljps
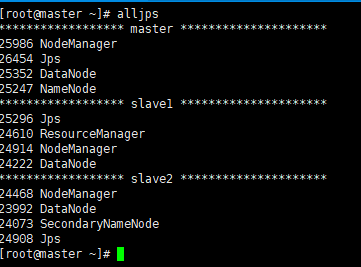
集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
时间服务器配置(必须 root 用户)
① 安装 ntp
yum install ntp
② 修改 ntp 配置文件
vim /etc/ntp.conf
修改内容如下:
⑴ 授权 192.168.1.0-192.168.1.255 网段上的所有机器可以从这台机器上查询和同步时间
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
⑵ 集群在局域网中,不使用其他互联网上的时间
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
⑶ 当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
server 127.127.1.0
fudge 127.127.1.0 stratum 10
③ 修改/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd
添加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
④ 重新启动 ntpd 服务
systemctl restart ntpd.service
⑤ 设置 ntpd 服务开机启动
systemctl enable ntpd.service
其他机器配置(必须root用户)
在其他机器配置10分钟与时间服务器同步一次
crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate master
Hadoop高可用的解决方案
Hadoop 实现自动故障切换需要用到下面的组件:
- ZooKeeper quorum
- ZKFailoverController 进程(ZKFC)
ZooKeeper quorum
ZooKeeper quorum 是一种集中式服务,主要为分布式应用提供协调、配置、命名空间等功能。它提供组服务和数据同步服务,它让客户端可以实时感知数据的更改,并跟踪客户端故障,HDFS故障自动切换的实现依赖下面两个方面:
- 故障监测:ZooKeeper维护一个和NameNode之间的会话。如果NameNode发生故障,该会话就会过期,会话一旦失效了,ZooKeeper将通知其他NameNode启动故障切换进程。
- 活动NameNode选举:ZooKeeper提供了一种活动节点选举机制,只要活动的NameNode发生故障失效了,其他NameNode将从ZooKeeper获取一个排它锁,并把自身声明为活动的NameNode。
ZKFC
ZKFC 是 ZooKeeper 的监控和管理 namenode 的一个客户端,所以每个运行 namenode 的机器上都会有 ZKFC。
那ZKFC具体作用是什么?主要有以下3点:
- 状态监控:ZKFC 会定期用 ping 命令监测活动的 NameNode,如果 NameNode 不能及时响应ping 命令,那么ZooKeeper 就会判断该活动的 NameNode 已经发生故障了。
- ZooKeeper会话管理:如果 NameNode 是正常的,那么它和ZooKeeper会保持一个会话,并持有一个znode锁。如果会话失效了,那么该锁将自动释放。
- 基于ZooKeeper的选举:如果 NameNode 是正常的,ZKFC 知道当前没有其他节点持有 znode 锁,那么 ZKFC自己会试图获取该锁,如果锁获取成功,那么它将赢得选举,并负责故障切换工作。这里的故障切换过程其实和手动故障切换过程是类似的;先把之前活动的节点进行隔离,然后把ZKFC 所在的机器变成活动的节点。
环境搭建
虚拟机环境准备
-
克隆虚拟机
-
修改克隆虚拟机的静态IP
① vim /etc/sysconfig/network-scripts/ifcfg-网卡名称
终端上输入 ifconfig 或 ip addr,找出网卡名称
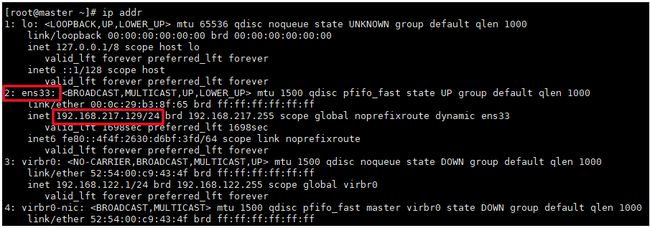
② 将 BOOTPROTO=dhcp 改成 BOOTPROTO=static、ONBOOT=no 改成 ONBOOT=yes
③ 并在文件尾部添加以下内容
IPADDR=192.168.217.129
NETMASK=255.255.255.0
GATEWAY=192.168.217.2
DNFS1=192.168.217.2
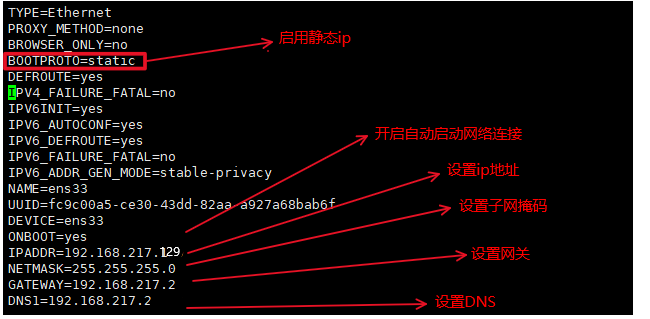
④ 重启网关服务
systemctl restart network
修改主机名
hostnamectl set-hostname lyh
关闭防火墙
① 关闭防火墙
systemctl stop firewalld
② 禁止防火墙开机启动
systemctl disable firewalld
③ 关闭 Selinux
vim /etc/sysconfig/selinux
将 SELINUX=enforcing 改成 SELINUX=disabled
安装 jdk
- 将 jdk-8u151-linux-x64.tar.gz 安装包通过 xftp 传到 CentOS 7 上
- 创建 /usr/local/java 文件夹
mkdir /usr/local/java
将 jdk 压缩包解压到 /usr/local/java 目录下
tar -zxvf jdk-8u151-linux-x64.tar.gz -C /usr/local/java/
配置 jdk 的环境变量
vim /etc/profile
添加以下内容:
# JAVAHOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
让配置文件生效
source /etc/profile
输入 java、javac、java -version 命令检验 jdk 是否安装成功
注意:如果之前安装过 jdk 或 系统自带 jdk,我们需要卸载这些 jdk
① 查询已安装的 jdk 列表
rpm -qa | grep jdk
② 删除已经安装的 jdk
yum -y remove XXX(上面查询到的 jdk 名称)
注意:如果终端出现以下错误:/var/run/yum.pid 已被锁定,PID 为 1610 的另一个程序正在运行。则输入以下命令:
rm -f /var/run/yum.pid
之后再执行以上删除 jdk 的命令
③ 重新让配置文件生效
source /etc/profile
④ 输入 java、javac、java -version 命令检验 jdk 是否安装成功
安装 Hadoop
- 将 hadoop-2.7.7.tar.gz 安装包通过 xftp 传到 CentOS 7 上
- 创建 /hadoop 文件夹
mkdir /hadoop
将 hadoop 压缩包解压到 /haddop 的目录下
tar -zxvf hadoop-2.7.7.tar.gz -C /hadoop/
配置 hadoop 环境变量
① 在 /etc/profile 文件的尾部添加以下内容:
#HADOOP
export HADOOP_HOME=/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
② 使配置文件生效
source /etc/profile
测试是否安装成功
hadoop version

FIFO 调度器
FIFO 调度器也就是平时所说的先进先出(First In First Out)调度器。可以简单的将其理解为一个 Java 队列,它的含义在于集群中同时只能有一个作业在运行。
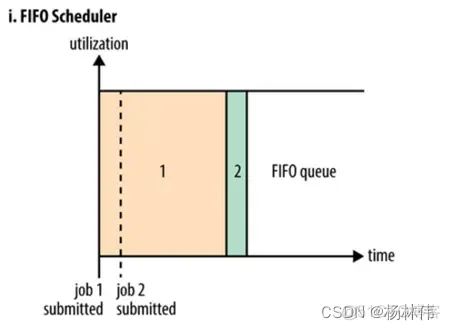
队列形式会有什么问题?
- FIFO调度器以集群资源独占的方式来运行作业,这样的好处是一个作业可以充分利用所有的集群资源,但是对于运行时间短,重要性高或者交互式查询类的MR作业就要等待排在序列前的作业完成才能被执行,这也就导致了如果有一个非常大的Job在运行,那么后面的作业将会被阻塞。
因此,虽然单一的 FIFO调度实现简单,但是对于很多实际的场景并不能满足要求。这也就催生了 Capacity 调度器和 Fair调度器的出现。
容量调度器(Capacity Scheduler)
Capacity 调度器也就是日常说的容器调度器,可以将它理解成一个个的资源队列,这个资源队列是用户自己去分配的:

举例:如上图,因为工作所需要把整个集群分成了AB两个队列,A队列下面还可以继续分,比如将A队列再分为1和2两个子队列。那么队列的分配就可以参考下面的树形结构:
|___A[60%]
|_____A.1[40%]
|_____A.2[60%]
|___B[40%]
上述的树形结构可以理解为:
- A队列占用整个资源的60%,B队列占用整个资源的40%。
- A队列里面又分了两个子队列,A.1占据40%,A.2占据60%,也就是说此时A.1和A.2分别占用A队列的40%和60%的资源。
- 虽然此时已经具体分配了集群的资源,但是并不是说A提交了任务之后只能使用它被分配到的60%的资源,而B队列的40%的资源就处于空闲。只要是其它队列中的资源处于空闲状态,那么有任务提交的队列可以使用空闲队列所分配到的资源,使用的多少是依据配来决定
调度器特性特性:
- 层次化的队列设计:这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源;
- 容量保证:队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源;
- 安全:每个队列又严格的访问控制。
- 弹性分配:空闲的资源可以被分配给任何队列。
- 多租户租用:通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
- 操作性:Yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。
- 基于资源的调度:协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
相关参数配置:
| 参数 | 描述 |
|---|---|
capacity |
队列的资源容量(百分比) |
maximum-capacity |
队列的资源使用上限(百分比) |
user-limit-factor |
每个用户最多可使用的资源量(百分比) |
maximum-applications |
集群或者队列中同时处于等待和运行状态的应用程序数目上限 |
maximum-am-resource-percent |
集群中用于运行应用程序ApplicationMaster的资源比例上限 |
maximum-am-resource-percent |
设置适合自己的值 |
state |
队列状态可以为STOPPED或者RUNNING |
acl_submit_applications |
限定哪些Linux用户/用户组可向给定队列中提交应用程序 |
acl_administer_queue |
为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等 |
公平调度器(Fair Scheduler)
Fair调度器也就是日常说的公平调度器。Fair调度器是一个队列资源分配方式,在整个时间线上,所有的Job平均的获取资源。默认情况下,Fair调度器只是对内存资源做公平的调度和分配。
当集群中只有一个任务在运行时,那么此任务会占用整个集群的资源。当其他的任务提交后,那些释放的资源将会被分配给新的Job,所以每个任务最终都能获取几乎一样多的资源。
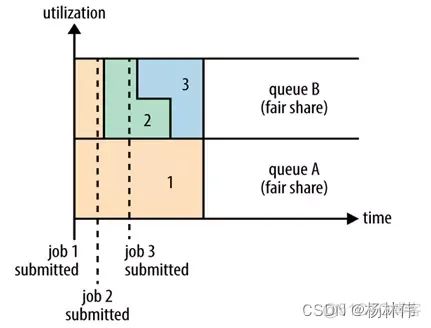
如上图所示,例如有两个用户A和B,他们分别拥有一个队列:
- 当A启动一个Job而B没有任务提交时,A会获得全部集群资源;
- 当B启动一个Job后,A的任务会继续运行,不过队列A会慢慢释放它的一些资源,一会儿之后两个任务会各自获得一半的集群资源。
- 如果此时B再启动第二个Job并且其它任务也还在运行时,那么它将会和B队列中的的第一个Job共享队列B的资源,也就是队列B的两个Job会分别使用集群四分之一的资源,
- 而队列A的Job仍然会使用集群一半的资源,结果就是集群的资源最终在两个用户之间平等的共享。
相关参数配置:
| 参数 | 描述 |
|---|---|
yarn.scheduler.fair.allocation.file |
allocation”文件是一个用来描述queue以及它们的属性的配置文件 |
yarn.scheduler.fair.user-as-default-queue |
是否将与allocation有关的username作为默认的queue name |
yarn.scheduler.fair.preemption |
是否使用“preemption”(优先权,抢占),默认为fasle |
yarn.scheduler.fair.assignmultiple |
是在允许在一个心跳中,发送多个container分配信息 |
yarn.scheduler.fair.max.assign |
如果assignmultuple为true,那么在一次心跳中,最多发送分配container的个数 |
yarn.scheduler.fair.locality.threshold.node |
一个float值,在0~1之间,表示在等待获取满足node-local条件的containers时,最多放弃不满足node-local的container的机会次数,放弃的nodes个数为集群的大小的比例。默认值为-1.0表示不放弃任何调度的机会 |
yarn.scheduler.fair.locality.threashod.rack |
同上,满足rack-local |
yarn.scheduler.fair.sizebaseweight |
是否根据application的大小(Job的个数)作为权重 |
分布式缓存
分布式缓存:是 Hadoop MapReduce 框架提供的一种数据缓存机制,它可以缓存只读文本文件,压缩文件,jar包等文件,一旦对文件执行缓存操作,那么每个执行 map/reduce 任务的节点都可以使用该缓存的文件。
分布式缓存优点
存储复杂的数据:它分发了简单、只读的文本文件和复杂类型的文件,如jar包、压缩包。这些压缩包将在各个slave节点解压。
数据一致性:Hadoop分布式缓存追踪了缓存文件的修改时间戳。然后当job在执行时,它也会通知这些文件不能被修改。使用hash 算法,缓存引擎可以始终确定特定键值对在哪个节点上。所以,缓存cluster只有一个状态,它永远不会是不一致的。
单点失败:分布式缓存作为一个跨越多个节点独立运行的进程。因此单个节点失败,不会导致整个缓存失败。
分布式缓存的使用
旧版本的 DistributedCache已经被注解为过时,以下为 Hadoop-2.2.0以上的新API接口。
Job job = Job.getInstance(conf);
//将hdfs上的文件加入分布式缓存
job.addCacheFile(new URI("hdfs://url:port/filename#symlink"));
由于新版 API 中已经默认创建符号连接,所以不需要再调用 setSymlink(true)方法了,可以下面代码来查看是否开启了创建符号连接。
System.out.println(context.getSymlink());
之后在 map/reduce 函数中可以通过 context 来访问到缓存的文件,一般是重写 setup 方法来进行初始化:
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
if (context.getCacheFiles() != null && context.getCacheFiles().length > 0) {
String path = context.getLocalCacheFiles()[0].getName();
File itermOccurrenceMatrix = new File(path);
FileReader fileReader = new FileReader(itermOccurrenceMatrix);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String s;
while ((s = bufferedReader.readLine()) != null) {
//TODO:读取每行内容进行相关的操作
}
bufferedReader.close();
fileReader.close();
}
}
得到的path为本地文件系统上的路径。
这里的 getLocalCacheFiles方法也被注解为过时了,只能使用 context.getCacheFiles方法,和 getLocalCacheFiles 不同的是,getCacheFiles得到的路径是 HDFS上的文件路径,如果使用这个方法,那么程序中读取的就不再试缓存在各个节点上的数据了,相当于共同访问 HDFS 上的同一个文件 ,可以直接通过符号连接来跳过getLocalCacheFiles 获得本地的文件。
分布式缓存的大小
可以在文件 mapred-site.xml 中设置,默认为10GB。
注意事项:
- 需要分发的文件必须是存储在HDFS 上了;
- 文件只读;
- 不缓存太大的文件,执行task之前对文件进行分发,影响task的启动速度。
命令
所有的 Hadoop 命令均由 bin/hadoop 脚本引发。不指定参数运行hadoop脚本会打印所有命令的描述。
用法:
hadoop [--config confdir] [COMMAND] [GENERIC_OPTIONS] [COMMAND_OPTIONS]
Hadoop 有一个选项解析框架用于解析一般的选项和运行类。
| 命令选项 | 描述 |
|---|---|
--config confdir |
覆盖缺省配置目录。缺省是${HADOOP_HOME}/conf。 |
GENERIC_OPTIONS |
多个命令都支持的通用选项。 |
COMMAND 命令选项 |
各种各样的命令和它们的选项会在下面提到。这些命令被分为用户命令和管理命令两组。 |
常规选项
| GENERIC_OPTION | 描述 |
|---|---|
| -conf | 指定应用程序的配置文件。 |
| -D | 为指定property指定值value。 |
| -fs | 指定namenode。 |
| -jt | 指定job tracker。只适用于job。 |
| -files <逗号分隔的文件列表> | 指定要拷贝到map reduce集群的文件的逗号分隔的列表。 只适用于job。 |
| -libjars <逗号分隔的jar列表> | 指定要包含到classpath中的jar文件的逗号分隔的列表。 只适用于job。 |
| -archives <逗号分隔的archive列表> | 指定要被解压到计算节点上的档案文件的逗号分割的列表。 只适用于job。 |
从本地模式到分布式集群计算
处理少量输入数据并不能体现MapReduce计算框架的优势,当有大量输入的数据流时,我们需要分布式文件系统(HDFS)和Hadoop资源管理系统(YARN)实现集群分布式计算。
一、术语
- Job:MapReduce作业,是客户端需要执行的一个工作单元:包括输入数据、MapReduce程序和配置信息
- Task:Hadoop会将作业job分成若干个任务(task)执行,其中包括两类任务:map任务和Reduce任务
- Input split:输入分片,Hadoop会将MapReduce的输入数据划分成等长的小数据块,称为“分片”,Hadoop为每个分片构建一个map任务,并由该任务运行用户自定义的map函数从而处理分片中的每条记录。
二、分片
1、分片的意义
处理单个分片的时间小于处理整个输入数据花费的时间,因此并行处理每个分片且每个分片数据比较小的话,则整个处理过程会获得更好的负载平衡(因为一台较快的计算机能够处理的数据分片比一台较慢的计算机更多,且成一定比例)。
2、分片的大小
尽管随着分片切分得更细,负载平衡的质量也会更高。但是分片切分得太小的时候,管理分片的总时间和构建map任务的总时间将决定整个作业的执行时间。
对于大多数作业来说,一个合理的分片大小趋于HDFS一个块的大小,默认是128MB。
三、数据本地化优化(map任务)
Hadoop在存储有输入数据(HDFS中的数据)的节点上运行map任务,可以获得最佳性能(因为无需使用宝贵的集群带宽资源),这就是“数据本地化优化”(data locality optimization)。
1、本地数据、本地机架与跨机架map任务
有时候存储该分片的HDFS数据块复本的所有节点可能正在运行其他map任务,此时作业调度需要从某一数据块所在的机架中一个节点寻找一个空闲的map槽(slot)来运行该map任务分片。特别偶然的情况下(几乎不会发生)会使用其他机架中的节点运行该map任务,这将导致机架与机架之间的网络传输。下图显示了这三种可能性。
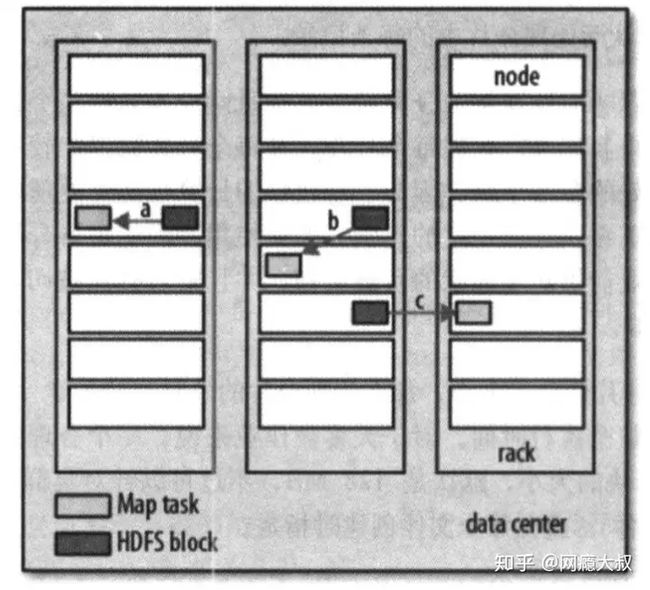
2、数据本地化原则决定了最佳分片大小
数据本地化的原则解释了为什么最佳分片大小应该与HDFS块大小相同:因为这是确保可以存储在单个节点上最大输入块的大小。
3、reduce任务不具备数据本地化的优势
单个reduce任务的输入通常来自于所有mapper的输出。排过序的map输出需通过网络传输发送到运行reduce任务的节点,数据在reduce端合并并由用户定义的reduce函数处理。
四、MapReduce任务数据流
reduce任务的数量并非由输入数据的大小决定,而是独立指定的。
真实的应用中,几乎所有作业都会把reducer的个数设置成较大的数字,否则由于所有中间数据都会放到一个reduce任务中,作业的处理效率就会及其低下。
增加reducer的数量能缩短reduce进程;但是reducer数量过多又会导致小文件过多而不够优化。一条经验法则是:目标reducer保持每个运行在5分钟左右,且产生至少一个HDFS块的输出比较合适。
1、单个reduce任务的MapReduce数据流

虚线框表示节点,虚线箭头表示节点内部的数据传输,实线箭头表示不同节点之间的数据传输。
2、多个reduce任务的MapReduce数据流

map任务到reduce任务的数据流称为shuffle(混洗,类似洗牌的意思),每个reduce任务的输入都来自许多map任务。shuffle比图示的更加复杂而且调整shuffle参数对作业总执行时间的影响非常大。
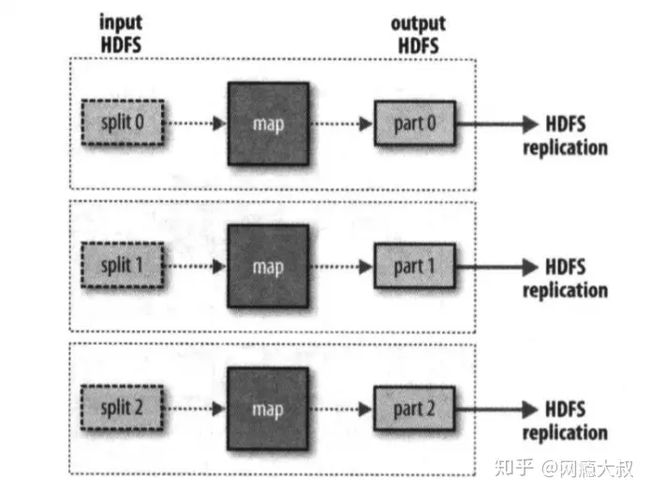
3、无reduce任务
当数据完全可以并行处理时可能会出现无reduce任务的情况,唯一的非本地节点数据传输是map任务将结果写入HDFS。
五、combiner函数(减少map和reduce之间的数据传输)
由前面的描述我们知道数据传输会占用集群上的可用带宽资源,从而限制了MapReduce作业的数量,因此我们应该尽量避免map和reduce任务之间的数据传输。combiner作为一个中间函数简化map任务的输出从而减少了map任务和reduce任务之间的数据传输。
来源
Hadoop 入门教程(超详细)[通俗易懂]
Hadoop
Hadoop入门(一篇就够了)