ES6(ES进阶之路一)
简介
JavaScript是世界上发展最快的编程语言之一,不仅可以用于编写运行在浏览器的客户端程序,随着Node.js的发展,JavaScript也被广泛应用于编写服务端程序。而随着JavaScript这门语言的不断发展和完善,在2015年正式发布的ECMAScript6已经成为了JavaScript这门语言的下一代标准,使得JavaScript用来编写复杂的大型应用程序更加的得心应手。近几年几乎所有使用JavaScript这门语言开发的项目,都在使用ES的新特性来开发。
随着ES2015的发布,标准委员会决定在每年都会发布一个ES的新版本。但很多开发者并没有真正的理解ES2015+每个版本都具有哪些新特性,以及这些新特性与ES5语法的差别,更不清楚这些新特性在实际项目中的应用场景是怎么样的。
由于篇幅原因笔者将ES6~ES12分成了ES进阶之路一和ES进阶之路二两篇文章,如果对ES6已经很清楚了可以直接看ES7、ES8、ES9、ES10、ES11、ES12(ES进阶之路二)
我相信只要你们认真看完了笔者的ES系列文章,你一定会成为ES大神。
首先我们来看看ES6吧,篇幅有点长,建议收藏后再看,后期也可以当做字典查阅。

块级作用域
我们知道在js中有全局作用域和函数作用域,在ES6中又新增了一个块级作用域。那什么是块级作用域呢?
关于什么是块,只要认识 {} 就可以了,比如if后面的{},for循环后面的{}等等。
if (true) {
var a = 5;
console.log(a); // 5
}
console.log(a); // 5
if (true) {
let a = 5;
console.log(a); // 5
}
console.log(a);// Uncaught ReferenceError: a is not defined
上面的例子中我们可以看出,在使用var在块{}中定义的变量是全局变量,里外都能访问。但是在使用let在块{}中定义的变量是块级作用域变量,只有在块中才能访问到,外部是访问不到的。
const定义的变量也是同理,只有在块中才能访问到,外部是访问不到的。
if (true) {
const a = 5;
console.log(a); // 5
}
console.log(a);// Uncaught ReferenceError: a is not defined
所以ES6中的块级作用域概念其实还是需要和let、const配合使用的。那什么是let、const呢,各自又有什么特点呢?
let
ES6 新增了let命令,用来声明变量。
1. let 声明的全局变量不是全局对象window的属性
这就意味着,你不可以通过 window.变量名 的方式访问这些变量,而 var 声明的全局变量是 window 的属性,是可以通过 window.变量名 的方式访问的。
var a = 5
console.log(window.a) // 5
let a = 5
console.log(window.a) // undefined
2. 用let定义变量不允许重复声明
这个很容易理解,使用 var 可以重复定义,使用 let 却不可以。
var a = 5
var a = 6
console.log(a) // 6
如果是 let ,则会报错
let a = 5
let a = 6
// Uncaught SyntaxError: Identifier 'a' has already been declared
// at :1:1
3. let声明的变量不存在变量提升
function foo() {
console.log(a)
var a = 5
}
foo() //undefined
上述代码中, a 的调用在声明之前,所以它的值是 undefined,而不是 Uncaught ReferenceError。实际上因为 var 会导致变量提升,上述代码和下面的代码等同:
function foo() {
var a
console.log(a)
a = 5
}
foo() //undefined
而对于 let 而言,变量的调用是不能先于声明的,看如下代码:
function foo() {
console.log(a)
let a = 5
}
foo()
// Uncaught ReferenceError: Cannot access 'a' before initialization
在这个代码中, a 的调用是在声明之前,因为 let 没有发生变量提升,所有读取 a 的时候,并没有找到,而在调用之后才找到 let 对 a 的定义,所以会报错。
4. let声明的变量具有暂时性死区
只要块级作用域内存在 let 命令,它所声明的变量就绑定在了这个区域,不再受外部的影响。
var a = 5
if (true) {
a = 6
let a
}
// Uncaught ReferenceError: Cannot access 'a' before initialization
上面代码中,存在全局变量 a ,但是块级作用域内 let 又声明了一个局部变量 a ,导致后者绑定这个块级作用域,所以在let声明变量前,对 a 赋值会报错。
ES6 明确规定,如果区块中存在 let 和 const 命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
总之,在代码块内,使用 let 命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”
有时“暂时性死区”比较隐蔽,比如:
function foo(b = a, a = 2) {
console.log(a, b)
}
foo()
// Uncaught ReferenceError: Cannot access 'a' before initialization
5. let 声明的变量拥有块级作用域
let实际上为 JavaScript 新增了块级作用域
{
let a = 5
}
console.log(a) // undefined
a 变量是在代码块 {} 中使用 let 定义的,它的作用域是这个代码块内部,外部无法访问。
我们再看一个项目中很常见的 for 循环:
for (var i = 0; i < 3; i++) {
console.log('循环内:' + i) // 0、1、2
}
console.log('循环外:' + i) // 3
如果改为 let 会怎么样呢?
for (let i = 0; i < 3; i++) {
console.log('循环内:' + i) // 0、1、2
}
console.log('循环外:' + i) // ReferenceError: i is not defined
继续看下面两个例子的对比,这时 a 的值又是多少呢?
if (true) {
var a = 5
}
console.log(a) // 5
if (true) {
let a = 5
}
console.log(a)// Uncaught ReferenceError: a is not defined
const
const和let类似,但是使用const定义的变量是常量。如果变量是基本类型就不能改变值,如果是引用类型就不能改变引用地址。
1. const定义的变量是常量
基本数据类型
const a = 1
console.log(a) // 1
a = 2
console.log(a)// Uncaught TypeError: Assignment to constant variable.
引用数据类型
const user = { name: "randy" };
user.name = "demi"; // 不改变引用地址的修改是可以的
console.log(user); //{ name: "demi" }
user = { name: "jack" };
console.log(user); // Uncaught TypeError: Assignment to constant variable.
2. const 声明的全局变量不是全局对象window的属性
这就意味着,你不可以通过 window.变量名 的方式访问这些变量,而 var 声明的全局变量是 window 的属性,是可以通过 window.变量名 的方式访问的。
var a = 5
console.log(window.a) // 5
const a = 5
console.log(window.a) // undefined
3. 用const定义变量不允许重复声明
这个很容易理解,使用 var 可以重复定义,使用 const 却不可以。
var a = 5
var a = 6
console.log(a) // 6
如果是 const ,则会报错
const a = 5
const a = 6
// Uncaught SyntaxError: Identifier 'a' has already been declared
// at :1:1
4. const声明的变量不存在变量提升
function foo() {
console.log(a)
var a = 5
}
foo() //undefined
上述代码中, a 的调用在声明之前,所以它的值是 undefined,而不是 Uncaught ReferenceError。实际上因为 var 会导致变量提升,上述代码和下面的代码等同:
function foo() {
var a
console.log(a)
a = 5
}
foo() //undefined
而对于 const 而言,变量的调用是不能先于声明的,看如下代码:
function foo() {
console.log(a)
const a = 5
}
foo()
// Uncaught ReferenceError: Cannot access 'a' before initialization
在这个代码中, a 的调用是在声明之前,因为 const 没有发生变量提升,所有读取 a 的时候,并没有找到,而在调用之后才找到 const 对 a 的定义,所以会报错。
5. const声明的变量具有暂时性死区
只要块级作用域内存在 const 命令,它所声明的变量就绑定在了这个区域,不再受外部的影响。
var a = 5
if (true) {
a = 6
const a
}
// Uncaught ReferenceError: Cannot access 'a' before initialization
上面代码中,存在全局变量 a ,但是块级作用域内 const 又声明了一个局部变量 a ,导致后者绑定这个块级作用域,所以在const声明变量前,对 a 赋值会报错。
ES6 明确规定,如果区块中存在 let 和 const 命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
总之,在代码块内,使用 const 命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”
6. const 声明的变量拥有块级作用域
const实际上为 JavaScript 新增了块级作用域
{
const a = 5
}
console.log(a) // undefined
a 变量是在代码块 {} 中使用 const 定义的,它的作用域是这个代码块内部,外部无法访问。
解构赋值
在 ES6 中新增了变量赋值的方式:解构赋值。允许按照一定模式,从数组、对象、字符串中提取值,对变量进行赋值。
数组解构赋值
数组的解构是严格按照顺序来的,一一对应。
let [a, b, c] = ["a", "b", "c"]
console.log(a, b, c) // a b c
let [one, two, three] = new Set([1, 2, 3])
console.log(one, two, three) // 1 2 3
// 被赋值的变量还可以是对象的属性,不局限于单纯的变量。
let user = {}
[user.firstName, user.secondName] = 'Kobe Bryant'.split(' ')
console.log(user.firstName, user.secondName) // Kobe Bryant
// 可以跳过赋值元素
let [name, , title] = ['John', 'Jim', 'Sun', 'Moon']
console.log( title ) // Sun
// rest 参数,相当于把剩下的放在一个数组里
// 我们可以使用 rest 来接受赋值数组的剩余元素,不过要确保这个 rest 参数是放在被赋值变量的最后一个位置上。
let [name1, ...rest] = ["jack", "randy", "demi"];
console.log(name1); // jack
console.log(rest[0]); // randy
console.log(rest[1]); // demi
console.log(rest.length); // 2
// 默认值,取不到值得时候就会使用默认值
let [name = "randy", surname = "demi"] = ["jack"]
console.log(name) // jack
console.log(surname) // demi
对象解构赋值
对象的解构是按照属性名来的,跟顺序无关。
const user = { name: "randy", age: 24 };
const { age, name } = user;
console.log(name, age); // randy 24
// 取别名
const { name: n, age: a } = user;
console.log(n, a); // randy 24
// 默认值
const { name, age, sex = "male" } = user;
console.log(name, age, sex); // randy 24 male
// rest参数,相当于把剩下的放在一个对象里
const { name, ...rest } = user;
console.log(name); // randy
console.log(rest); // {age: 24}
// 嵌套对象,对于嵌套我们保证层级一样即可
const user2 = {
name: "demi",
age: 24,
address: { province: "湖南", city: "岳阳", area: "汨罗" },
likes: ["orange", "apple"],
};
const {
name,
age,
address: { province, city, area },
likes: [fruits1, fruits2],
} = user2;
console.log(name, age, province, city, area, fruits1, fruits2); // demi 24 湖南 岳阳 汨罗 orange apple
字符串解构赋值
字符串的解构跟数组有点类似,也是可以设置默认值、rest参数等这里笔者就不再细说了。
let str = 'randy'
let [a, b, c, d, e] = str
console.log(a, b, c, d, e) // r a n d y
String扩展
Unicode表示法
ES6 加强了对 Unicode 的支持,允许采用\uxxxx形式表示一个字符,其中xxxx表示字符的 Unicode 码点。
"\u0061"
// "a"
但是,这种表示法只限于码点在\u0000~\uFFFF之间的字符。超出这个范围的字符,必须用两个双字节的形式表示。
"\uD842\uDFB7"
// ""
"\u20BB7"
// " 7"
上面代码表示,如果直接在\u后面跟上超过0xFFFF的数值(比如\u20BB7),JavaScript 会理解成\u20BB+7。由于\u20BB是一个不可打印字符,所以只会显示一个空格,后面跟着一个7。
ES6 对这一点做出了改进,只要将码点放入大括号,就能正确解读该字符。
"\u{20BB7}"
// ""
有了这种表示法之后,JavaScript 共有 6 种方法可以表示一个字符。
'\z' === 'z' // true
'\172' === 'z' // true
'\x7A' === 'z' // true
'\u007A' === 'z' // true
'\u{7A}' === 'z' // true
遍历器接口
ES6 为字符串添加了遍历器接口,详见Iterator一节,使得字符串可以被for...of循环遍历。
for (let item of 'randy') {
console.log(item) // r a n d y
}
模板字符串
在 ES6 之前对字符串的处理是相当的麻烦,看如下场景:
1. 字符串很长要换行
字符串很长包括几种情形一个是开发时输入的文本内容,一个是接口数据返回的文本内容。如果对换行符处理不当,就会带来异常。
2. 字符串中有变量或者表达式
如果字符串不是静态内容,往往是需要加载变量或者表达式,这个也是很常见的需求。之前的做法是字符串拼接:
var a = 20
var b = 10
var c = 'JavaScript'
var str = 'My age is ' + (a + b) + ' and I love ' + c
console.log(str)
如果字符串有大量的变量和表达式,这个拼接简直是噩梦。
3. 字符串中有逻辑运算
我们通常写代码都是有逻辑运算的,对于字符串也是一样,它包含的内容不是静态的,通常是根据一定的规则在动态变化。
var retailPrice = 20
var wholesalePrice = 16
var type = 'retail'
var showTxt = ''
if (type === 'retail') {
showTxt += '您此次的购买单价是:' + retailPrice
} else {
showTxt += '您此次的批发价是:' + wholesalePrice
}
看到这样的代码一定会感到很熟悉,通常大家的做法是使用上述的字符串拼接+逻辑判断,或者采用字符串模板类库来操作。
看了上述的应用场景,就要引入 String Literals 话题,这个是用来解决字符串拼接问题,从 ES6 开始可以这样定义字符串了。
`string text`
`string text line 1
string text line 2`
`string text ${expression} string text`
在这里你可以任意插入变量或者表达式,只要用 ${}包起来就好。
注意
这里的符号是反引号,也就是数字键 1 左边的键,不是单引号或者双引号
这样就可以轻松解决字符串包含变量或者表达式的问题了,对于多行的字符串,之前是这样处理
console.log('string text line 1\n' +
'string text line 2')
// "string text line 1
// string text line 2"
现在可以这样做了
console.log(`string text line 1
string text line 2`)
// "string text line 1
// string text line 2"
完全不需要 \n 来参与。
前面的字符串字面量解决了字符串拼接的问题,对于包含复杂逻辑的字符串并不是简单的表达式能搞定的。所以需要另一种解决方案:Tag Literals,还是看上述那个例子:
var retailPrice = 20
var wholesalePrice = 16
var type = 'retail'
var showTxt = ''
if (type === 'retail') {
showTxt += '您此次的购买单价是:' + retailPrice
} else {
showTxt += '您此次的批发价是:' + wholesalePrice
}
现在可以定义一个 Tag 函数,然后用这个 Tag 函数来充当一个模板引擎:
function Price(strings, type) {
let s1 = strings[0]
const retailPrice = 20
const wholesalePrice = 16
let txt = ''
if (type === 'retail') {
txt = `购买单价是:${retailPrice}`
} else {
txt = `批发价是:${wholesalePrice}`
}
return `${s1}${txt}`
}
let showTxt = Price `您此次的${'retail'}`
console.log(showTxt) //您此次的购买单价是:20
strings 参数指的是 Tag 函数后面被变量分割开的字符串集合,type 参数是对应第一个变量,Tag 函数可以有多个 type 类似的参数。
新增方法
String.prototype.fromCodePoint()
用于从 Unicode 码点返回对应字符,并且可以识别大于0xFFFF的字符。
// ES5
console.log(String.fromCharCode(65)) // A
// ES6
console.log(String.fromCodePoint(65)) // A
String.prototype.includes()
ES5中可以使用indexOf方法来判断一个字符串是否包含在另一个字符串中,indexOf返回出现的下标位置,如果不存在则返回-1。
const str = 'randy'
console.log(str.indexOf('dy'))
ES6提供了includes方法来判断一个字符串是否包含在另一个字符串中,返回boolean类型的值。
const str = 'randy'
console.log(str.includes('dy'))
String.prototype.startsWith()
判断参数字符串是否在原字符串的头部, 返回boolean类型的值。
const str = 'randy'
console.log(str.startsWith('ra'))
String.prototype.endsWith()
判断参数字符串是否在原字符串的尾部, 返回boolean类型的值。
const str = 'randy'
console.log(str.endsWith('dy'))
String.prototype.repeat()
repeat方法返回一个新字符串,表示将原字符串重复n次。
const str = 'randy'
const newStr = str.repeat(10)
console.log(newStr)
Number扩展
二进制与八进制十六进制
请大家思考在JS中如何把十进制转化为二进制、八进制、十六进制?
const a = 50;
console.log(a.toString(2)); // 110010
console.log(a.toString(8)); // 62
console.log(a.toString(16)); // 32
如何把二进制转化为十进制?
const b = 101
console.log(parseInt(b, 2)) // 5
如何把八进制转化为十进制?
const b = 101
console.log(parseInt(b, 8)) // 65
如何把十六进制转化为十进制?
const d = 101
console.log(parseInt(d, 16)) // 257
ES6 提供了二进制、八进制、十六进制数值的新的写法,分别用前缀0b(或0B)、0o(或0O)、0x(或0X) 表示。
const a = 0b0101;
console.log(a); // 5
const b = 0o123;
console.log(b); // 83
const c = 0x123;
console.log(c); // 291
新增方法
Number.isFinite()
用来检查一个数值是否为有限的finite,即不是Infinity。
Number.isFinite(15) // true
Number.isFinite(0.8) // true
Number.isFinite(NaN) // false
Number.isFinite(Infinity) // false
Number.isFinite(-Infinity) // false
Number.isFinite('foo') // false
Number.isFinite('15') // false
Number.isFinite(true) // false
Number.isNaN()
用来检查一个值是否为NaN。
Number.isNaN(NaN) // true
Number.isNaN(15) // false
Number.isNaN('a') // false
Number.isNaN('15') // false
Number.isNaN(true) // false
Number.isNaN(9 / NaN) // true
Number.isNaN('true' / 0) // true
Number.isNaN('true' / 'true') // true
需要注意和Number.isNaN的区别
-
函数
isNaN接收参数后,会尝试将这个参数转换为数值,任何不能被转换为数值的的值都会返回true,因此非数字值传入也会返回true,会影响NaN的判断。 -
函数
Number.isNaN会首先判断传入参数是否为数字,如果是数字再继续判断是否为NaN,不会进行数据类型的转换,这种方法对于NaN的判断更为准确。也就是说只有是NaN才会返回true。
Number.parseInt()
ES6 将全局方法parseInt()移植到Number对象上面,行为完全保持不变。 这样做的目的,是逐步减少全局性方法,使得语言逐步模块化。
// ES5的写法
parseInt('12.34') // 12
// ES6的写法
Number.parseInt('12.34') // 12
Number.parseFloat()
ES6 将全局方法parseFloat()移植到Number对象上面,行为完全保持不变。这样做的目的,是逐步减少全局性方法,使得语言逐步模块化。
// ES5的写法
parseFloat('123.45#') // 123.45
// ES6的写法
Number.parseFloat('123.45#') // 123.45
Number.isInteger()
用来判断一个数值是否为整数。
Number.isInteger(25) // true
Number.isInteger(25.1) // false
Number.isInteger() // false
Number.isInteger(null) // false
Number.isInteger('15') // false
Number.isInteger(true) // false
Number.isSafeInteger()
JavaScript 能够准确表示的整数范围在-253到253之间(不含两个端点),超过这个范围,无法精确表示这个值。
Math.pow(2, 53) // 9007199254740992
Math.pow(2, 53) === Math.pow(2, 53) + 1 // true
console.log(Number.isSafeInteger(Math.pow(2, 53))) // false
console.log(Number.isSafeInteger(Math.pow(2, 53) - 1)) // true
新增属性
Number.MAX_SAFE_INTEGER
返回最大的安全整数。
Number.MAX_SAFE_INTEGER === Math.pow(2, 53) - 1 // true
Number.MAX_SAFE_INTEGER === 9007199254740991 // true
Number.MIN_SAFE_INTEGER
返回最小的安全整数。
Number.MIN_SAFE_INTEGER === -Number.MAX_SAFE_INTEGER // true
Number.MIN_SAFE_INTEGER === -9007199254740991 // true
Math扩展
Math.trunc()
方法用于去除一个数的小数部分,返回整数部分。
console.log(Math.trunc(5.5)) // 5
console.log(Math.trunc(-5.5)) // -5
console.log(Math.trunc(true)) // 1
console.log(Math.trunc(false)) // 0
console.log(Math.trunc(NaN)) // NaN
console.log(Math.trunc(undefined)) // NaN
console.log(Math.trunc()) // NaN
Math.sign()
方法用来判断一个数到底是正数、负数、还是零。对于非数值,会先将其转换为数值。
它会返回五种值。
- 参数为正数,返回+1
- 参数为负数,返回-1
- 参数为 0,返回0
- 参数为-0,返回-0
- 其他值,返回NaN
console.log(Math.sign(5)) // 1
console.log(Math.sign(-5)) // -1
console.log(Math.sign(0)) // 0
console.log(Math.sign(NaN)) // NaN
console.log(Math.sign(true)) // 1
console.log(Math.sign(false)) // 0
Math.cbrt()
方法用于计算一个数的立方根。
console.log(Math.cbrt(8)) // 2
console.log(Math.cbrt('randy')) // NaN
Symbol
ES6 引入了一种新的原始数据类型 Symbol ,表示独一无二的值。它是 JavaScript 语言的第七种数据类型,前六种是:undefined、null、布尔值(Boolean)、字符串(String)、数值(Number)、对象(Object)。
Symbol 值通过Symbol函数生成。这就是说,对象的属性名现在可以有两种类型,一种是原来就有的字符串,另一种就是新增的 Symbol 类型。凡是属性名属于 Symbol 类型,就都是独一无二的,可以保证不会与其他属性名产生冲突。
声明方式
// 不需要使用new
let s = Symbol()
typeof s
// "symbol"
变量s就是一个独一无二的值。typeof的结果说明s是 Symbol 数据类型。
既然是独一无二的,那么两个Symbol()就一定是不相等的:
let s1 = Symbol()
let s2 = Symbol()
console.log(s1) // Symbol()
console.log(s2) // Symbol()
console.log(s1 === s2) // false
虽然输出的结果是一样的但是就是不相等。
Symbol函数前不能使用new命令,否则会报错。这是因为生成的 Symbol 是一个原始类型的值,不是对象。也就是说,由于 Symbol 值不是对象,所以不能添加属性。基本上,它是一种类似于字符串的数据类型。
Symbol函数可以接受一个字符串作为参数,表示对 Symbol 实例的描述,主要是为了在控制台显示,或者转为字符串时,比较容易区分。
let s1 = Symbol('foo')
let s2 = Symbol('foo')
console.log(s1) // Symbol(foo)
console.log(s2) // Symbol(foo)
console.log(s1 === s2) // false
Symbol.for()
Symbol.for() 接受一个字符串作为参数,然后搜索有没有以该参数作为名称的 Symbol 值。如果有,就返回这个 Symbol 值,否则就新建一个以该字符串为名称的 Symbol 值,并将其注册到全局。
let s1 = Symbol.for('foo')
let s2 = Symbol.for('foo')
console.log(s1 === s2) // true
注意Symbol.for()与Symbol()这两种写法,都会生成新的 Symbol。它们的区别是,前者会被登记在全局环境中供搜索,后者不会。Symbol.for()不会每次调用就返回一个新的 Symbol 类型的值,而是会先检查给定的key是否已经存在,如果不存在才会新建一个值。
上面那段话怎么理解呢?笔者举个例子你就明白了
let s1 = Symbol("foo");
let s2 = Symbol.for("foo");
console.log(s1 === s2); // false
就是只有使用了Symbol.for()创建的symbol才会被登记在全局环境中供搜索。所以上面的例子就不会相等,因为第一个symbol没有被登记。
Symbol.keyFor()
Symbol.keyFor()方法返回一个已登记的 Symbol 类型值的key。也就是说只有使用了Symbol.for()创建的symbol才会有值。
const s1 = Symbol('foo')
console.log(Symbol.keyFor(s1)) // undefined
const s2 = Symbol.for('foo')
console.log(Symbol.keyFor(s2)) // foo
作为属性名
由于每一个 Symbol 值都是不相等的,这意味着 Symbol 值可以作为标识符,用于对象的属性名,就能保证不会出现同名的属性。这对于一个对象由多个模块构成的情况非常有用,能防止某一个键被不小心改写或覆盖。
比如在一个班级中,可能会有同学名字相同的情况,这时候使用对象来描述学生信息的时候,如果直接使用学生姓名作为key会有有问题。
const grade = {
张三: {
address: 'xxx',
tel: '111'
},
李四: {
address: 'yyy',
tel: '222'
},
李四: {
address: 'zzz',
tel: '333'
},
}
console.log(grade)
// 只会保留最后一个李四
如果使用Symbol,同名的学生信息就不会被覆盖:
const stu1 = Symbol('李四')
const stu2 = Symbol('李四')
const grade = {
[stu1]: {
address: 'yyy',
tel: '222'
},
[stu2]: {
address: 'zzz',
tel: '333'
},
}
console.log(grade)
console.log(grade[stu1])
console.log(grade[stu2])
属性遍历
我们需要使用Object.getOwnPropertySymbols()方法来获取键值是symbol的属性。
const c = Symbol('city')
class User {
constructor(name) {
this.name = name
this[c] = '上海'
}
getName() {
return this.name + this[c]
}
}
const user = new User('randy')
console.log(user.getName()) // randy上海
for (let key of Object.getOwnPropertySymbols(user)) {
console.log(key) // Symbol(city)
}
消除魔术字符串
魔术字符串指的是,在代码之中多次出现、与代码形成强耦合的某一个具体的字符串或者数值。风格良好的代码,应该尽量消除魔术字符串,改由含义清晰的变量代替。
function getArea(shape) {
let area = 0
switch (shape) {
case 'Triangle':
area = 1
break
case 'Circle':
area = 2
break
}
return area
}
console.log(getArea('Triangle'))
上面代码中,字符串Triangle和Circle就是魔术字符串。它多次出现,与代码形成“强耦合”,不利于将来的修改和维护。
使用Symbol就可以很好的解决这个问题:
const shapeType = {
triangle: Symbol(),
circle: Symbol()
}
function getArea(shape) {
let area = 0
switch (shape) {
case shapeType.triangle:
area = 1
break
case shapeType.circle:
area = 2
break
}
return area
}
console.log(getArea(shapeType.triangle))
Array扩展
for…of
在ES5中遍历的方法有很多了,其中有 forEach、for、for..in、filter、some、map、every 等等。那为什么还要有for of呢?
for of能用来遍历数组、Set、Map等等,只要你具有iterator就可以被for of遍历。也就是说不管你是什么数据,只要你实现了iterator就可以使用for of遍历。不了解iterator不要着急,笔者后面会讲。
keys()
keys()返回指定数组下标的数组
const arr = ['a', 'b', 'c']
console.log(arr.keys()) // 0 1 2
values()
values()返回指定数组值的数组
const arr = ['a', 'b', 'c']
console.log(arr.values()) // a b c
entries()
entries()返回指定数组下标和值的数组
const arr = ['a', 'b', 'c']
console.log(arr.entries()) // [[0, 'a'], [1, 'b'], [2, 'c']]
Array.from()
我们可以使用Array.from()方法来将伪数组转成真数组。
函数中的 arguments、DOM中的 NodeList等。看上去都像数组却不能直接使用数组的 API,因为它们是伪数组(Array-Like),这时我们就需要将其转换成真正的数组。
以前的做法
let args = [].slice.call(arguments);
let imgs = [].slice.call(document.querySelectorAll('img'));
使用Array.from()
let args = Array.from(arguments);
let imgs = Array.from(document.querySelectorAll('img'));
难道 Array.from 只能用来将伪数组转换成数组吗,还有其他用法吗?这要来看下 Array.from 的几个参数:
Array.from(arrayLike[, mapFn[, thisArg]])
| 参数 | 含义 | 必选 |
|---|---|---|
| arrayLike | 想要转换成数组的伪数组对象或可迭代对象 | Y |
| mapFn | 如果指定了该参数,新数组中的每个元素会执行该回调函数 | N |
| thisArg | 可选参数,执行回调函数 mapFn 时 this 对象 | N |
看了这几个参数至少能看到 Array.from 还具备 map 的功能,比如我们想初始化一个长度为 5 的数组,每个数组元素默认为 1,之前的做法是这样的:
let arr = Array(6).join(' ').split('').map(item => 1)
// [1,1,1,1,1]
这样写虽然也能实现,但是用起来比较繁琐,使用 Array.from 就会简洁很多。
Array.from({
length: 5
}, function() {
return 1
})
Array.of()
Array.of()主要用来创建新数组。Array.of() 和 Array 构造函数之间的区别在于处理整数参数:Array.of(7) 创建一个具有单个元素 7 的数组,而 Array(7) 创建一个长度为7的空数组(注意:这是指一个有7个空位(empty)的数组,而不是由7个undefined组成的数组)。
Array.of(7); // [7]
Array.of(1, 2, 3); // [1, 2, 3]
Array(7); // [ , , , , , , ]
Array(1, 2, 3); // [1, 2, 3]
Array.prototype.fill()
fill(填充值, startIndex, endIndex)方法用一个固定值填充一个数组中从起始索引到终止索引内的全部元素。不包括终止索引。
| 参数 | 含义 | 必选 |
|---|---|---|
| value | 用来填充数组元素的值 | Y |
| start | 起始索引,默认值为0 | N |
| end | 终止索引,默认值为 this.length | N |
比如我们想让数组第2和第3个值变为0。
let array = [1, 2, 3, 4]
array.fill(0, 1, 3)
console.log(array) // [1,0,0,4]
我们前面有提到用 Array.from 初始化为一个长度固定,元素为指定值的数组。如果用 fill 是否可以达到同样的效果呢?
Array(5).fill(1) // [1,1,1,1,1]
Array.prototype.find()
find(callback[, thisArg]) 方法返回数组中满足提供的测试函数的第一个元素的值,否则返回 undefined。
| 参数 | 含义 | 必选 |
|---|---|---|
| callback | 在数组每一项上执行的函数,接收 3 个参数,element、index、array | Y |
| thisArg | 执行回调时用作 this 的对象 | N |
let array = [5, 12, 8, 130, 44];
let found = array.find(function(element) {
return element > 10;
});
console.log(found);// 12 返回的是值
Array.prototype.findIndex()
findIndex(callback[, thisArg])方法返回数组中满足提供的测试函数的第一个元素的索引。否则返回-1。其实这个和 find() 是成对的,不同的是它返回的是索引而不是值。
| 参数 | 含义 | 必选 |
|---|---|---|
| callback | 在数组每一项上执行的函数,接收 3 个参数,element、index、array | Y |
| thisArg | 执行回调时用作 this 的对象 | N |
let array = [5, 12, 8, 130, 44];
let found = array.findIndex(function(element) {
return element > 10;
});
console.log(found);// 1 返回的是索引值
Array.prototype.copyWithin()
在当前数组内部,将指定位置的成员复制到其他位置(会覆盖原有成员),然后返回当前数组。也就是说,使用这个方法,会修改当前数组。
语法: arr.copyWithin(target, start = 0, end = this.length)
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 从该位置开始替换数据。如果为负值,表示倒数 | Y |
| start | 从该位置开始读取数据,默认为 0。如果为负值,表示从末尾开始计算 | N |
| end | 到该位置前停止读取数据,默认等于数组长度。如果为负值,表示从末尾开始计算 | N |
如下例子,arr.copyWithin(1, 3)就是从下标1处开始替换元素,替换成什么呢?就是从下标3开始到末尾的元素,也就是4, 5,所以就可以得到[1, 4, 5, 4, 5]
let arr = [1, 2, 3, 4, 5]
console.log(arr.copyWithin(1, 3))// [1, 4, 5, 4, 5]
console.log(arr)// [1, 4, 5, 4, 5] 会改变原数组
Function扩展
默认参数
function foo(x, y = "world") {
console.log(x, y); // hello world
}
foo("hello");
如果默认参数在参数列表的中间,并且我们想使用默认参数怎么办呢?我们可以使用undefined当做参数。
function foo2(x, y = 2, z) {
return x + y + z;
}
console.log(foo2(1, undefined, 3)); // 6
参数长度
在函数体内,有时候需要判断函数有几个实参,一共有2个办法。在 ES5 中可以在函数体内使用 arguments 来判断。
function foo3(a, b = 1, c) {
// arguments是伪数组,具有length属性
console.log(arguments.length)
}
foo3('a', 'b') //2
然而在 ES6 中不能再使用 arguments 来判断了,但可以借助 Function.length 来判断。
function foo4(a, b = 1, c) {
console.log(foo4.length)
}
foo4('a', 'b') // 1
细心的同学发现 Function.length 结果和 arguments 的结果不同!没错,Function.length 是统计第一个默认参数前面的变量数。
function foo5(a = 1, b = 2, c) {
console.log(foo5.length)
}
foo5('a', 'b') // 0
注意上面的方法都是判断的实参个数,而不是形参。
name属性
函数的name属性,返回该函数的函数名。
function foo() {}
foo.name // "foo"
Rest 参数
在写函数的时候,部分情况我们不是很确定参数有多少个就可以使用Rest 参数。
function sum(...nums) {
let num = 0
nums.forEach(function(item) {
num += item * 1
})
return num
}
console.log(sum(1, 2, 3)) // 6
console.log(sum(1, 2, 3, 4)) // 10
扩展运算符(Spread Operator)
Spread Operator 和 Rest 参数 是形似但相反意义的操作符,简单的来说 Rest 参数 是把不定的参数“收敛”到数组,而 Spread Operator 是把固定的数组内容“打散”到对应的参数。
function sum(x = 1, y = 2, z = 3) {
return x + y + z
}
console.log(sum(...[4])) // 9
console.log(sum(...[4, 5])) // 12
console.log(sum(...[4, 5, 6])) // 15
箭头函数
箭头函数的语法笔者就不再多讲了,下面我们来简单说说箭头函数一些特殊点。
// 没参数
let hello = () => {
console.log('say hello')
}
// 一个参数可以省略括号,多个参数就不能省略了
let hello2 = name => {
console.log(name)
}
// 简单返回可以省略{}
let hello3 = name => name
console.log(hello3("hello3")); // hello3
// 如果返回值是字面量对象,一定要用小括号包起来
let person = (name) => ({
age: 20,
addr: 'Beijing City'
})
使用箭头函数除了使用方便,更要注意的是它的this,很多小伙伴搞不清楚,关于箭头函数this,笔者在之前的文章都2022年了你不会还没搞懂this吧有详细说到,感兴趣的小伙伴可以看看。
箭头函数特点
-
箭头函数的
this是在定义函数时绑定的,不是在执行过程中绑定的。简单的说,函数在定义时,this就继承了定义函数的对象。 -
箭头函数中的
this只取决包裹箭头函数的第一个普通函数的this。 -
箭头函数不能通过
apply call bind改变this。 -
箭头函数不能使用
arguments,得使用reset参数。 -
箭头函数不能用于构造函数。
-
不可以使用
yield命令,因此箭头函数不能用作Generator函数。
Object扩展
属性简洁表示法
在 ES6 之前 Object 的属性必须是 key-value 形式,如下:
const name = 'randy'
const age = 27
const obj = {
name: name,
age: age,
study: function() {
console.log(this.name + '正在学习')
}
}
在 ES6 之后是可以用简写的形式来表达:
const name = 'randy'
const age = 27
const obj = {
name,
age,
study() {
console.log(this.name + '正在学习')
}
}
属性名表达式
在 ES6 可以直接用变量或者表达式来定义Object的 key。
const n = 'name'
const obj = {
foo: 'bar',
[n]: 'randy'
}
console.log(obj) // {foo: 'bar', name: 'randy'}
Object.is()
Object.is()判断基本数据类型比较的是值,判断引用数据类型判断的是地址是否一样,一般情况下和三等号的判断相同,它处理了一些特殊的情况,比如 -0 和 +0 不再相等,两个 NaN 是相等的。
Object.is(+0, -0); // 返回true
Object.is(NaN, NaN); // 返回true
关于js中数据类型可以看看笔者前面的文章都2022年了你不会还没搞懂JS数据类型吧。
Object.assign()
Object.assign() 方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象,它将返回目标对象。该方法会修改原有对象,并且同名属性值前面的会被后面的覆盖。
const target = {
a: 1,
b: 2
}
const source = {
b: 4,
c: 5
}
const returnedTarget = Object.assign(target, source)
console.log(target) // { a: 1, b: 4, c: 5 }
console.log(returnedTarget)// { a: 1, b: 4, c: 5 }
基本语法 Object.assign(target, ...sources)
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 目标对象 | Y |
| sources | 源对象 | N |
从语法上可以看出源对象的个数是不限制的(零个或多个),如果是零个直接返回目的对象,如果是多个相同属性的会被后边的源对象的属相覆盖。
let s = Object.assign({
a: 1
})
// {a: 1}
注意 如果目的对象不是对象,则会自动转换为对象
let t = Object.assign(2)
// Number {2}
let s = Object.assign(2, {
a: 2
})
// Number {2, a: 2}
如果对象属性具有多层嵌套,这时使用Object.assign()合并对象会怎么样呢?
let target = {
a: {
b: {
c: 1
},
e: 4,
f: 5,
g: 6
}
}
let source = {
a: {
b: {
c: 1
},
e: 2,
f: 3
}
}
Object.assign(target, source)
console.log(target)
我们惊奇的发现, g 属性消失了…
Object.assign()对于引用数据类型属于浅拷贝,判断到同名属性a,直接用后面的值替换前面的。
这里涉及到了浅拷贝,如果想了解更多js中拷贝相关知识点可以看看笔者前面写的都2022年了你不会还没搞懂JS赋值拷贝、浅拷贝、深拷贝吧
新增遍历方式
新增了Object.keys()、Object.values()、Object.entries()、 Object.getOwnPropertyNames()、Object.getOwnPropertySymbols()、Reflect.ownKeys(obj)方法,用来更方便的对对象进行遍历。
// 定义对象
const obj1 = Object.create(
{ msg: "原型属性值" },
{
name: {
value: "randy",
writable: true,
configurable: true,
enumerable: true,
},
age: {
value: 25,
writable: true,
configurable: true,
enumerable: false,
},
[Symbol("test")]: {
value: "symboltest",
writable: true,
configurable: true,
enumerable: true,
},
}
);
复制代码
Object.keys()
Object.keys()不能获取Symbol属性、不能获取不可枚举属性、不能获取原型链属性。
for (const key of Object.keys(obj1)) {
console.log("keys: ", key); // name
}
Object.getOwnPropertyNames()
Object.getOwnPropertyNames()能获取不可枚举属性、不能获取Symbol属性、不能获取原型链属性。
for (const name of Object.getOwnPropertyNames(obj1)) {
console.log("getOwnPropertyNames: ", name); // name age
}
Object.getOwnPropertySymbols()
Object.getOwnPropertySymbols()只能获取Symbol属性。并且不管该Symbol属性是否是可枚举,都能遍历出来。
for (const symbol of Object.getOwnPropertySymbols(obj1)) {
console.log("getOwnPropertySymbols: ", symbol); // Symbol(test)
}
Reflect.ownKeys()
Reflect.ownKeys()不但能获取自身不可枚举属性,还能获取Symbol类型的属性,但不能获取原型链上的属性。
for (const key of Reflect.ownKeys(obj1)) {
console.log("Reflect.ownKeys: ", key); // name age Symbol(test)
}
关于数组、对象的遍历可以看看笔者前面写的都2022年了你不会还没搞懂对象数组的遍历吧
关于Object更多API可以看看笔者前面写的JS Object API详解
Class
使用class关键字声明类
首先我们要先来说明在 JavaScript 世界里如何声明一个 “类”。在 ES6 之前大家都是这么做的:
let Animal = function(type) {
this.type = type
this.walk = function() {
console.log( `I am walking` )
}
}
let dog = new Animal('dog')
在上述代码中,我们定义了一个叫 Animal 的类,类中声明了一个属性 type、一个方法 walk;然后通过 new Animal 这个类生成实例,完成了类的定义和实例化。当然你也可以这样写:
let Animal = function(type) {
this.type = type
}
Animal.prototype.walk = function() {
console.log( `I am walking` )
}
let dog = new Animal('dog')
在 ES6 中把类的声明专业化了,不在用 function 的方式了,而是使用class
class Animal {
city = '上海'
constructor(type) {
this.type = type
this.say = () => {
console.log("say");
};
}
walk() {
console.log( `I am walking` )
}
}
let dog = new Animal('dog')
很明显,从定义上就很专业了,有构造函数、方法,但是 ES6 增加了新的数据类型 class 吗?
console.log(typeof Animal) //function
可以发现 class 的类型还是 function,和 ES5 貌似并没有什么区别,那么 class 中定义的方法在哪呢?我们来输出下上面例子中的dog。
console.log(dog);
输出
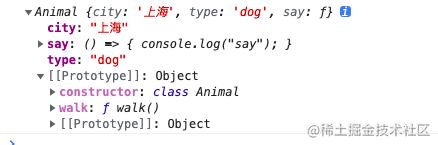
上面的例子city、type、say方法是实例属性,而walk方法却在原型上。
我们可以看出在构造函数或者class里面定义的属性都是实例属性,而定义的方法是在原型上。
这个表现也和 ES5 中直接使用 function 定义类的方式相同,所以得出一个结论:class 的方式是 function 方式的语法糖。
Setters & Getters
对于类中的属性,可以直接在 constructor 中通过 this 直接定义,还可以利用Setters & Getters直接在类的顶层来定义。Setters & Getters就是在方法名前加上get/set。
class Animal {
constructor(type, age) {
this.type = type
this._age = age
}
get age() {
return this._age
}
set age(val) {
this._age = val
}
}
这个代码演示了,通过 get/set 来给类定一个属性,不过貌似没有说服力。因为 age 和 _age 都是类的属性,而且是相同的含义这样做感觉没有实际用途。但是如果一个属性是个只读的呢?我们就可以只设置get方法就可以了。
class Animal {
constructor(type) {
this.type = type
}
get address() {
return '上海'
}
}
毋庸赘述,大家都能看出来含义。再来看下如下的应用场景:
class CustomHTMLElement {
constructor(element) {
this.element = element
}
get html() {
return this.element.innerHTML
}
set html(value) {
this.element.innerHTML = value
}
}
利用 set/get 实现了对 element.innerHTML 的简单封装。
可是,有时候我们真的需要设置一个私有属性,然后通过一定的规则来限制对它的修改,利用 set/get 就可以轻松实现。
class Animal {
_age = 0
constructor(type) {
this.type = type
}
get age() {
return this._age
}
set age(val) {
// 年龄在1-60岁之间才让他设置成功
if (val > 0 && val <= 60) {
this._age = val
}
}
}
let dog = new Animal("dog");
console.log(dog.age); // 0
dog.age = 60;
console.log(dog.age); // 60
dog.age = 61;
console.log(dog.age); // 60
静态属性和静态方法
静态方法是面向对象最常用的功能,在 ES5 中利用 function 实现的类是这样实现一个静态方法的。
let Animal = function(type) {
this.type = type
this.walk = function() {
console.log( `I am walking` )
}
}
// 静态方法
Animal.eat = function(food) {
console.log( `I am eating` )
}
Animal.city = "上海";
在 ES6 中使用 static 的标记是不是静态方法,代码如下:
class Animal {
// 静态属性
static city = "上海";
constructor(type) {
this.type = type;
}
walk() {
console.log(`I am walking`);
}
// 静态方法
static eat() {
console.log(`I am eating`);
}
}
let dog = new Animal("dog");
// 不能使用实例对象调用
// console.log(dog.city);
// dog.eat();
// 只能使用类调用
console.log(Animal.city);
Animal.eat();
对于静态属性和方法,只能使用类来调用,不能使用对象调用。
继承
面向对象只所以可以应对复杂的项目实现,很大程度上要归功于继承。如果对继承概念不熟悉的同学,可以看看笔者前面写的都2022年了你不会还没搞懂JS原型和继承吧。在 ES5 中怎么实现继承呢?我们以组合继承为例。
// 定义父类
let Animal = function(type) {
this.type = type
}
// 定义方法
Animal.prototype.walk = function() {
console.log( `I am walking` )
}
// 定义静态方法
Animal.eat = function(food) {
console.log( `I am eating` )
}
// 定义子类
let Dog = function() {
// 初始化父类
Animal.call(this, 'dog')
this.run = function() {
console.log('I can run')
}
}
// 继承
Dog.prototype = Animal.prototype
从代码上看,是不是很繁琐?而且阅读性也较差。再看看 ES6 是怎么解决这些问题的:
class Animal {
constructor(type) {
this.type = type;
}
walk() {
console.log(`I am walking`);
}
static eat() {
console.log(`I am eating`);
}
}
class Dog extends Animal {
constructor() {
super("dog");
}
run() {
console.log("I can run");
}
}
let dog = new Dog("dog");
console.log(dog.type); // dog
dog.run(); // I can run
dog.walk(); // I am walking
我们只需要简单使用extends关键字就能实现继承,是不是清晰易懂呢?
super关键字我们可以用来调用父类的构造函数或者父类的方法、属性。
虽然 ES6 在类的定义上仅是 ES5 定义类的语法糖,但是从开发者的角度而言,开发更有效率了,代码可阅读性大大提升。
Set
在 JavaScript 里通常使用 Array 或 Object 来存储数据。但是在频繁操作数据的过程中查找或者统计并需要手动来实现,并不能简单的直接使用。 比如如何保证 Array 是去重的,如何统计 Object 的数据总数等,必须自己去手动实现类似的需求,不是很方便。 在 ES6 中为了解决上述痛点,新增了数据结构 Set 和 Map,它们分别对应传统数据结构的“集合”和“字典”。首先,我们先来学习下 Set 数据结构。
ES6 提供了新的数据结构 Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
Set相关API
创建 Set
let s = new Set()
可以定义一个空的 Set 实例,也可以在实例化的同时传入默认的数据。
let s = new Set([1, 2, 3, 4])
注意,初始化的参数必须是可遍历的,可以是数组或者自定义遍历的数据结构。这里和创建数组有点点区别,创建数组传递的是参数列表。
const arr = new Array(1, 2, 3, 4)
添加数据
s.add('hello')
s.add('goodbye')
或者
s.add('hello').add('goodbye')
注意,Set 数据结构不允许数据重复,所以添加重复的数据是无效的
删除数据
删除数据分两种,一种是删除指定的数据,一种是删除全部数据。
// 删除指定数据
s.delete('hello') // true
// 删除全部数据
s.clear()
统计数据
Set 可以快速进行统计数据,如数据是否存在、数据的总数。
// 判断是否包含数据项,返回 true 或 false
s.has('hello') // true
// 计算数据项总数
s.size // 2
Set使用场景
数组去重
let arr = [1, 2, 3, 4, 2, 3]
let s = new Set(arr)
console.log(s) // Set(4) {1, 2, 3, 4}
合并去重
let arr1 = [1, 2, 3, 4]
let arr2 = [2, 3, 4, 5, 6]
let s = new Set([...arr1, ...arr2])
console.log(s) // Set(6) {1, 2, 3, 4, 5, …}
console.log([...s]) // [1, 2, 3, 4, 5, 6]
console.log(Array.from(s)) // [1, 2, 3, 4, 5, 6]
交集
let s1 = new Set(arr1)
let s2 = new Set(arr2)
let result = new Set(arr1.filter(item => s2.has(item)))
console.log(Array.from(result))
差集
let arr3 = new Set(arr1.filter(item => !s2.has(item)))
let arr4 = new Set(arr2.filter(item => !s1.has(item)))
console.log(arr3)
console.log(arr4)
console.log([...arr3, ...arr4])
遍历方式
- keys():返回键名的遍历器
- values():返回键值的遍历器
- entries():返回键值对的遍历器
- forEach():使用回调函数遍历每个成员
- for…of:可以直接遍历每个成员
const s = new Set(["randy", "demi"]);
console.log(s);
s.forEach((item) => {
console.log(item); // hello // goodbye
});
for (let item of s) {
console.log(item);
}
for (let item of s.keys()) {
console.log(item);
}
for (let item of s.values()) {
console.log(item);
}
for (let item of s.entries()) {
console.log(item[0], item[1]);
}
WeakSet
WeakSet 结构与 Set 类似,也是不重复的值的集合。但是,它与 Set 有三个区别。
WeakSet 的成员只能是对象
成员不能是其他类型的值。
const ws = new WeakSet()
ws.add(1)
// TypeError: Invalid value used in weak set
ws.add(Symbol())
// TypeError: invalid value used in weak set
let ws = new WeakSet()
const obj1 = {
name: 'randy'
}
const obj2 = {
age: 5
}
ws.add(obj1)
ws.add(obj2)
ws.delete(obj1)
console.log(ws)
console.log(ws.has(obj2))
WeakSet 没有size属性
所以没有办法遍历它的成员。
WeakSet 中的对象都是弱引用
即垃圾回收机制不考虑 WeakSet 对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于 WeakSet 之中。
Map
ES6 提供了 Map 数据结构。它类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。也就是说,Object 结构提供了“字符串—值”的对应,Map 结构提供了“值—值”的对应,是一种更完善的 Hash 结构实现。如果你需要“键值对”的数据结构,Map 比 Object 更合适。
Map相关API
创建Map
使用new Map([iterable])创建Map,iterable 可以是一个数组或者其他 iterable 对象,其元素为键值对(两个元素的数组,例如: [[ 1, ‘one’ ], [ 2, ‘two’ ]])。 每个键值对都会添加到新的 Map。null 会被当做 undefined。
let map = new Map([['name', 'randy'], ['age', 27]])
添加数据
let keyObj = {}
let keyFunc = function() {}
let keyString = 'a string'
// 添加键
map.set(keyString, "和键'a string'关联的值")
map.set(keyObj, '和键keyObj关联的值')
map.set(keyFunc, '和键keyFunc关联的值')
获取数据
- get() 方法返回某个 Map 对象中的一个指定元素
console.log(map.get(keyObj)) // 和键keyObj关联的值
删除数据
// 删除指定的数据
map.delete(keyObj)
// 删除所有数据
map.clear()
统计数据
// 统计所有 key-value 的总数
console.log(map.size) //2
// 判断是否有 key-value
console.log(map.has(keyObj)) // true
遍历方式
- keys() 返回一个新的 Iterator 对象。它包含按照顺序插入 Map 对象中每个元素的 key 值
- values() 方法返回一个新的 Iterator 对象。它包含按顺序插入Map对象中每个元素的 value 值
- entries() 方法返回一个新的包含 [key, value] 对的 Iterator 对象,返回的迭代器的迭代顺序与 Map 对象的插入顺序相同
- forEach() 方法将会以插入顺序对 Map 对象中的每一个键值对执行一次参数中提供的回调函数
- for…of 可以直接遍历每个成员
const map = new Map([
["name", "randy"],
["age", 27],
]);
map.forEach((value, key) => console.log(value, key));
for (let [key, value] of map) {
console.log(key, value); //
}
for (let key of map.keys()) {
console.log(key);
}
for (let value of map.values()) {
console.log(value);
}
for (let [key, value] of map.entries()) {
console.log(key, value);
}
Map和Object对比
其实 Object 也是按键值对存储和读取的,那么他俩之间除了我们之前说的区别以外还有其他的吗?
-
键的类型
一个
Object的键只能是字符串或者Symbol,但一个Map的键可以是任意值,包括函数、对象、基本类型。 -
键的顺序
Map中的键值是有序的,而添加到对象中的键则不是。因此,当对它进行遍历时,Map对象是按插入的顺序返回键值。 -
键值对的统计
你可以通过
size属性直接获取一个Map的键值对个数,而Object的键值对个数只能手动计算。 -
键值对的遍历
Map可直接进行迭代,而Object的迭代需要先获取它的键数组,然后再进行迭代。 -
性能
Map在涉及频繁增删键值对的场景下会有些性能优势。
WeekMap
WeakMap结构与Map结构类似,也是用于生成键值对的集合。
// WeakMap 可以使用 set 方法添加成员
const wm1 = new WeakMap()
const key = {
foo: 1
}
wm1.set(key, 2)
wm1.get(key) // 2
// WeakMap 也可以接受一个数组,
// 作为构造函数的参数
const k1 = [1, 2, 3]
const k2 = [4, 5, 6]
const wm2 = new WeakMap([
[k1, 'foo'],
[k2, 'bar']
])
wm2.get(k2) // "bar"
但是,它与 Map 有三个区别。
WeakMap只接受对象作为键名(null除外)
不接受其他类型的值作为键名。
const map = new WeakMap()
map.set(1, 2)
// TypeError: 1 is not an object!
map.set(Symbol(), 2)
// TypeError: Invalid value used as weak map key
map.set(null, 2)
// TypeError: Invalid value used as weak map key
WeakMap 没有size属性
所以没有办法遍历它的成员。
WeakMap的键对象都是弱引用
WeakMap的键名所指向的对象,不计入垃圾回收机制。
Proxy
在 ES6 标准中新增的一个非常强大的功能是 Proxy,它可以自定义一些常用行为如查找、赋值、枚举、函数调用等。通过 Proxy 这个名称也可以看出来它包含了“代理”的含义,只要有“代理”的诉求都可以考虑使用 Proxy 来实现。
基本语法
语法
let p = new Proxy(target, handler)
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 用 Proxy 包装的目标对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理) | Y |
| handler | 一个对象,其属性是当执行一个操作时定义代理的行为的函数 | Y |
MDN 给出的解释偏官方,通俗的讲第一个参数 target 就是用来代理的“对象”,被代理之后它是不能直接被访问的,而 handler 就是实现代理的过程。
拦截操作场景
proxy的语法我们清楚了,但是一般什么情况下我们需要使用到proxy呢?下面笔者说几个简单的场景。
场景
我们经常读取一个对象的 key-value:
let o = {
name: 'randy',
age: 20
}
console.log(o.name) // randy
console.log(o.age) // 20
console.log(o.from) // undefined
当我们读取 from 的时候返回的是 undefined,因为 o 这个对象中没有这个 key-value。想想看我们在读取数据的时候,这个数据经常是聚合的,当大家没有按照规范来的时候或者数据缺失的情况下,经常会出现这种“乌龙”现象。
如果我们不想在调用 key 的时候返回 undefined,之前的做法是这样的:
console.log(o.from || '')
如果我们对所有代码都是这种写法,那阅读性和观赏性就不得而知了。值得庆幸的是,ES6 的 Proxy 可以让我们轻松的解决这一问题:
let o = {
name: 'randy',
age: 20
}
let handler = {
get(obj, key) {
return Reflect.has(obj, key) ? obj[key] : ''
}
}
let p = new Proxy(o, handler)
console.log(p.from)
这个代码是想表达如果 o 对象有这个 key-value 则直接返回,如果没有一律返回 '' ,当然这里是自定义,大家可以根据自己的需要来写适合自己业务的规则。
刚才对数据的“读操作”进行了拦截,接下来我们描述下“写操作”进行拦截。
场景 1
从服务端获取的数据希望是只读,不允许在任何一个环节被修改。
// response.data 是 JSON 格式的数据,来自服务端的响应
// 在 ES5 中只能通过遍历把所有的属性设置为只读
for (let [key] of Object.entries(response.data)) {
Object.defineProperty(response.data, key, {
writable: false
})
}
如果我们使用 Proxy 就简单很多了:
let data = new Proxy(response.data, {
set(obj, key, value) {
return false
}
})
场景 2
对于数据交互而言,校验是不可或缺的一个环境,传统的做法是将校验写在了业务逻辑里,导致代码耦合度较高。如果大家使用 Proxy 就可以将代码设计的非常灵活。
// Validator.js
export default (obj, key, value) => {
if (Reflect.has(key) && value > 20) {
obj[key] = value
}
}
import Validator from './Validator'
let data = new Proxy(response.data, {
set: Validator
})
场景 3
如果对读写进行监控,可以这样写:
let validator = {
set(target, key, value) {
if (key === 'age') {
if (typeof value !== 'number' || Number.isNaN(value)) {
throw new TypeError('Age must be a number')
}
if (value <= 0) {
throw new TypeError('Age must be a positive number')
}
}
return true
}
}
const person = {
age: 27
}
const proxy = new Proxy(person, validator)
proxy.age = 'foo'
// <- TypeError: Age must be a number
proxy.age = NaN
// <- TypeError: Age must be a number
proxy.age = 0
// <- TypeError: Age must be a positive number
proxy.age = 28
console.log(person.age)
// <- 28
// 添加监控
window.addEventListener(
'error',
e => {
console.log(e.message) // Uncaught TypeError: Age must be a number
},
true
)
这里笔者只介绍了几个常用的场景,其实使用场景还有很多,下面笔者再来详细介绍下proxy相关的API。
常用API
get
拦截对象属性的读取,比如proxy.foo和proxy['foo']。
get(target, prop) , target是被代理对象,prop是键。
let arr = [7, 8, 9]
arr = new Proxy(arr, {
get(target, prop) {
// console.log(target, prop)
return prop in target ? target[prop] : 'error'
}
})
console.log(arr[1]) // 8
console.log(arr[10]) // error
let dict = {
'hello': '你好',
'world': '世界'
}
dict = new Proxy(dict, {
get(target, prop) {
return prop in target ? target[prop] : prop
}
})
console.log(dict['world']) // 世界
console.log(dict['name']) // name
set
拦截对象属性的设置,比如proxy.foo = v或proxy['foo'] = v,返回一个布尔值。
set(target, prop, val) , target是被代理对象,prop是键,val是值。
let arr = []
arr = new Proxy(arr, {
set(target, prop, val) {
if (typeof val === 'number') {
target[prop] = val
return true
} else {
return false
}
}
})
arr.push(5)
arr.push(6)
console.log(arr[0], arr[1], arr.length) // 5 6 2
has
拦截propKey in proxy的操作,返回一个布尔值。
has(target, prop), target是被代理对象,prop是键。
let user = {
name: 'randy',
age: 27
}
user = new Proxy(user, {
has(target, prop) {
if(prop === 'name') {
return true
}
return false
}
})
console.log('name' in user) // true
console.log('age' in user) // false
ownKeys
拦截Object.getOwnPropertyNames(proxy)、Object.getOwnPropertySymbols(proxy)、Object.keys(proxy)、for...in循环等循环操作,返回一个数组。因此我们可以借助该方法过滤掉一些不想被外界知道的属性。
let obj = {
name: 'randy',
[Symbol('es')]: 'es6'
}
console.log(Object.getOwnPropertyNames(obj))
console.log(Object.getOwnPropertySymbols(obj))
console.log(Object.keys(obj))
for (let key in obj) {
console.log(key)
}
let userinfo = {
username: 'randy',
age: 27,
_password: '***'
}
userinfo = new Proxy(userinfo, {
ownKeys(target) {
return Object.keys(target).filter(key => !key.startsWith('_'))
}
})
for (let key in userinfo) {
console.log(key) // username age
}
console.log(Object.keys(userinfo)) // ['username', 'age']
deleteProperty
拦截delete proxy[propKey]的操作,返回一个布尔值。
let user = {
name: 'randy',
age: 27,
_password: '***'
}
user = new Proxy(user, {
get(target, prop) {
if (prop.startsWith('_')) {
throw new Error('不可访问')
} else {
return target[prop]
}
},
set(target, prop, val) {
if (prop.startsWith('_')) {
throw new Error('不可访问')
} else {
target[prop] = val
return true
}
},
deleteProperty(target, prop) { // 拦截删除
if (prop.startsWith('_')) {
throw new Error('不可删除')
} else {
delete target[prop]
return true
}
},
ownKeys(target) {
return Object.keys(target).filter(key => !key.startsWith('_'))
}
})
console.log(user.age) // 27
console.log(user._password) // 会报错
user.age = 18
console.log(user.age) // 18
try {
user._password = 'xxx'
} catch (e) {
console.log(e.message) // 不可访问
}
try {
// delete user.age
delete user._password
} catch (e) {
console.log(e.message) // 不可删除
}
console.log(user.age) // 18
for (let key in user) {
console.log(key) // name age
}
apply
拦截 Proxy 实例作为函数调用的操作,比如proxy(...args)、proxy.call(object, ...args)、proxy.apply(...)。
let sum = (...args) => {
let num = 0
args.forEach(item => {
num += item
})
return num
}
sum = new Proxy(sum, {
apply(target, ctx, args) {
console.log(target, ctx, args)
return target(...args) * 2
}
})
console.log(sum(1, 2))
console.log(sum.call(null, 1, 2, 3))
console.log(sum.apply(null, [1, 2, 3]))
construct
拦截 Proxy 实例作为构造函数调用的操作,比如new proxy(...args)。
let User = class {
constructor(name) {
this.name = name
}
}
User = new Proxy(User, {
construct(target, args, newTarget) {
console.log(target, args, newTarget)
return new target(...args)
}
})
console.log(new User('randy'))
Reflect
Reflect对象与Proxy对象一样,也是 ES6 为了操作对象而提供的新 API。
设计目的
- 将
Object属于语言内部的方法放到Reflect上
let obj = {}
let newVal = ''
Reflect.defineProperty(obj, 'name', {
get() {
return newVal
},
set(val) {
console.log('set')
// this.name = val
newVal = val
}
})
obj.name = 'es'
console.log(obj.name)
- 修改某些
Object方法的返回结果,让其变得更合理
// 老写法
try {
Object.defineProperty(target, property, attributes)
// success
} catch (e) {
// failure
}
// 新写法
if (Reflect.defineProperty(target, property, attributes)) {
// success
} else {
// failure
}
- 让
Object操作变成函数行为
// 老写法
'assign' in Object // true
// 新写法
Reflect.has(Object, 'assign') // true
Reflect对象的方法与Proxy对象的方法一一对应,只要是Proxy对象的方法,就能在Reflect对象上找到对应的方法。
Proxy(target, {
set: function(target, name, value, receiver) {
var success = Reflect.set(target, name, value, receiver)
if (success) {
console.log('property ' + name + ' on ' + target + ' set to ' + value)
}
return success
}
})
Reflect 是一个内置的对象,它提供拦截 JavaScript 操作的方法,这些方法与处理器对象的方法相同。Reflect不是一个函数对象,因此它是不可构造的。
与大多数全局对象不同,Reflect没有构造函数。你不能将其与一个new运算符一起使用,或者将Reflect对象作为一个函数来调用。Reflect的所有属性和方法都是静态的(就像Math对象)
常用方法
Reflect.apply()
语法
Reflect.apply(target, thisArgument, argumentsList)
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 目标函数 | Y |
| thisArgument | target函数调用时绑定的this对象 | N |
| argumentsList | target函数调用时传入的实参列表,该参数应该是一个类数组的对象 | N |
示例
Reflect.apply(Math.floor, undefined, [1.75])
// 1
Reflect.apply(String.fromCharCode, undefined, [104, 101, 108, 108, 111])
// "hello"
Reflect.apply(RegExp.prototype.exec, /ab/, ['confabulation']).index
// 4
Reflect.apply(''.charAt, 'ponies', [3])
// "i"
ES5 对比
该方法与ES5中Function.prototype.apply()方法类似:调用一个方法并且显式地指定this变量和参数列表(arguments) ,参数列表可以是数组,或类似数组的对象。
Function.prototype.apply.call(Math.floor, undefined, [1.75])
Reflect.construct()
Reflect.construct() 方法的行为有点像 new 操作符 构造函数 , 相当于运行 new target(...args).
语法
Reflect.construct(target, argumentsList[, newTarget])
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 被运行的目标函数 | Y |
| argumentsList | 调用构造函数的数组或者伪数组 | Y |
| newTarget | 该参数为构造函数, 参考 new.target 操作符,如果没有newTarget参数, 默认和target一样 | N |
如果target或者newTarget不是构造函数,抛出TypeError
Reflect.construct允许你使用可变的参数来调用构造函数
var obj = new Foo(...args)
var obj = Reflect.construct(Foo, args)
示例
var d = Reflect.construct(Date, [1776, 6, 4])
d instanceof Date // true
d.getFullYear() // 1776
如果使用 newTarget 参数,则表示继承了 newTarget 这个超类:
function someConstructor() {}
var result = Reflect.construct(Array, [], someConstructor)
Reflect.getPrototypeOf(result) // 输出:someConstructor.prototype
Array.isArray(result) // true
Reflect.defineProperty()
静态方法 Reflect.defineProperty() 基本等同于 Object.defineProperty() 方法,唯一不同是返回 Boolean 值。
语法
Reflect.defineProperty(target, propertyKey, attributes)
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 目标对象 | Y |
| propertyKey | 要定义或修改的属性的名称 | Y |
| attributes | 要定义或修改的属性的描述 | Y |
示例
const student = {}
Reflect.defineProperty(student, 'name', {
value: 'Mike'
}) // true
student.name // "Mike"
Reflect.deleteProperty()
Reflect.deleteProperty() 允许你删除一个对象上的属性。返回一个 Boolean 值表示该属性是否被成功删除。它几乎与非严格的 delete operator 相同。
语法
Reflect.deleteProperty(target, propertyKey)
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 删除属性的目标对象 | Y |
| propertyKey | 将被删除的属性的名称 | Y |
示例
var obj = {
x: 1,
y: 2
}
Reflect.deleteProperty(obj, "x") // true
obj // { y: 2 }
var arr = [1, 2, 3, 4, 5]
Reflect.deleteProperty(arr, "3") // true
arr // [1, 2, 3, , 5]
// 如果属性不存在,返回 true
Reflect.deleteProperty({}, "foo") // true
// 如果属性不可配置,返回 false
Reflect.deleteProperty(Object.freeze({
foo: 1
}), "foo") // false
Reflect.get()
Reflect.get() 方法的工作方式,就像从 object中获取属性值,但它是作为一个函数执行的。
语法
Reflect.get(target, propertyKey[, receiver])
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 需要取值的目标对象 | Y |
| propertyKey | 需要获取的值的键值 | Y |
| receiver | 如果遇到 getter,此值将提供给目标调用 | N |
示例
// Object
var obj = {
x: 1,
y: 2
}
Reflect.get(obj, 'x') // 1
// Array
Reflect.get(['zero', 'one'], 1) // "one"
// Proxy with a get handler
var x = {
p: 1
}
var obj = new Proxy(x, {
get(t, k, r) {
return k + 'bar'
}
})
Reflect.get(obj, 'foo') // "foobar"
Reflect.getOwnPropertyDescriptor()
静态方法 Reflect.getOwnPropertyDescriptor() 与 Object.getOwnPropertyDescriptor() 方法相似。如果在对象中存在,则返回给定的属性的属性描述符,否则返回 undefined。
语法
Reflect.getOwnPropertyDescriptor(target, propertyKey)
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 需要寻找属性的目标对象 | Y |
| propertyKey | 获取自己的属性描述符的属性的名称 | N |
示例
Reflect.getOwnPropertyDescriptor({
x: 'hello'
}, 'x')
// {value: "hello", writable: true, enumerable: true, configurable: true}
Reflect.getOwnPropertyDescriptor({
x: 'hello'
}, 'y')
// undefined
Reflect.getOwnPropertyDescriptor([], 'length')
// {value: 0, writable: true, enumerable: false, configurable: false}
对比
如果该方法的第一个参数不是一个对象(一个原始值),那么将造成 TypeError 错误。而对于 Object.getOwnPropertyDescriptor,非对象的第一个参数将被强制转换为一个对象处理。
Reflect.getOwnPropertyDescriptor("foo", 0)
// TypeError: "foo" is not non-null object
Object.getOwnPropertyDescriptor("foo", 0)
// { value: "f", writable: false, enumerable: true, configurable: false }
Reflect.getPrototypeOf()
静态方法 Reflect.getPrototypeOf() 与 Object.getPrototypeOf() 方法是一样的。都是返回指定对象的原型(即,内部的 [[Prototype]] 属性的值)。
语法
Reflect.getPrototypeOf(target)
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 获取原型的目标对象 | Y |
Reflect.has()
Reflect.has 用于检查一个对象是否拥有某个属性, 相当于 in 操作符
语法
Reflect.has(target, propertyKey)
解释
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 获取原型的目标对象 | Y |
| propertyKey | 属性名,需要检查目标对象是否存在此属性 | Y |
Reflect.isExtensible()
Reflect.isExtensible 判断一个对象是否可扩展 (即是否能够添加新的属性),它与 Object.isExtensible() 方法一样。
语法
Reflect.isExtensible(target)
解释*
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 获取原型的目标对象 | Y |
Reflect.ownKeys()
Reflect.ownKeys 方法返回一个由目标对象自身的属性键组成的数组。它的返回值等同于 Object.getOwnPropertyNames(target).concat(Object.getOwnPropertySymbols(target))。即既能获取不可枚举的还能获取symbol属性。
语法
Reflect.ownKeys(target)
解释*
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 获取原型的目标对象 | Y |
示例
Reflect.ownKeys({
z: 3,
y: 2,
x: 1
}) // [ "z", "y", "x" ]
Reflect.ownKeys([]) // ["length"]
var sym = Symbol.for("comet")
var sym2 = Symbol.for("meteor")
var obj = {
[sym]: 0,
"str": 0,
"773": 0,
"0": 0,
[sym2]: 0,
"-1": 0,
"8": 0,
"second str": 0
}
Reflect.ownKeys(obj)
// [ "0", "8", "773", "str", "-1", "second str", Symbol(comet), Symbol(meteor) ]
Reflect.preventExtensions()
Reflect.preventExtensions 方法阻止新属性添加到对象 例如:防止将来对对象的扩展被添加到对象中)。该方法与 Object.preventExtensions() 方法一致
语法
Reflect.preventExtensions(target)
解释*
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 获取原型的目标对象 | Y |
示例
var empty = {}
Reflect.isExtensible(empty) // === true
Reflect.preventExtensions(empty)
Reflect.isExtensible(empty) // === false
但是还是有些许区别的,Object会先转成Object再阻止扩展,而Reflect不会,会直接报错。
Reflect.preventExtensions(1)
// TypeError: 1 is not an object
Object.preventExtensions(1)
// 1
Reflect.set()
Reflect.set 方法允许你在对象上设置属性。它的作用是给属性赋值并且就像 property accessor 语法一样,但是它是以函数的方式。
语法
Reflect.set(target, propertyKey, value[, receiver])
解释*
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 获取原型的目标对象 | Y |
| propertyKey | 设置的属性的名称 | Y |
| value | 设置的值 | Y |
| receiver | 如果遇到 setter,this 将提供给目标调用 | N |
示例
// Object
var obj = {}
Reflect.set(obj, "prop", "value") // true
obj.prop // "value"
// Array
var arr = ["duck", "duck", "duck"]
Reflect.set(arr, 2, "goose") // true
arr[2] // "goose"
// It can truncate an array.
Reflect.set(arr, "length", 1) // true
arr // ["duck"]
// With just one argument, propertyKey and value are "undefined".
var obj = {}
Reflect.set(obj) // true 所以obj现在等于{undefined: undefined}
Reflect.getOwnPropertyDescriptor(obj, "undefined")
// { value: undefined, writable: true, enumerable: true, configurable: true }
Reflect.setPrototypeOf()
Reflect.setPrototypeOf 方法改变指定对象的原型 (即,内部的 [[Prototype]] 属性值)
语法
Reflect.setPrototypeOf(target, prototype)
解释*
| 参数 | 含义 | 必选 |
|---|---|---|
| target | 获取原型的目标对象 | Y |
| prototype | 对象的新原型 (一个对象或 null) | Y |
示例
Reflect.setPrototypeOf({}, Object.prototype) // true
// 可以把原型设置为null
Reflect.setPrototypeOf({}, null) // true
// 如果对象是不可扩展的会返回false
Reflect.setPrototypeOf(Object.freeze({}), null) // false
// 循环引用也会返回false
var target = {}
var proto = Object.create(target)
Reflect.setPrototypeOf(target, proto) // false
Iterator
Iterator也叫迭代器,在js中只要实现了迭代器就能使用for..of就行循环了。
let authors = {
allAuthors: {
fiction: [
'Agatha Christie',
'J. K. Rowling',
'Dr. Seuss'
],
scienceFiction: [
'Neal Stephenson',
'Arthur Clarke',
'Isaac Asimov',
'Robert Heinlein'
],
fantasy: [
'J. R. R. Tolkien',
'J. K. Rowling',
'Terry Pratchett'
]
}
}
这个数据结构是汇总了所有作者,每个作者按创作性质进行了分类。如果我们想获取所有作者的名单,该怎么做呢?
for (let author of authors) {
console.log(author)
}
你发现这个遍历遇到了报错:Uncaught TypeError: authors is not iterable
有的同学会说可以这样做:
for (let key in authors) {
let r = []
for (let k in authors[key]) {
r = r.concat(authors[key][k])
}
console.log(r)
// ["Agatha Christie", "J. K. Rowling", "Dr. Seuss", "Neal Stephenson", "Arthur Clarke", "Isaac Asimov", "Robert Heinlein", "J. R. R. Tolkien", "J. K. Rowling", "Terry Pratchett"]
}
这个做法确实可以,实际上也是手动实现的遍历加数据合并,这其实不算是遍历。这个小节就是讲述如何给这种自定义的数据结构进行遍历。
基本语法
Iterator 就是 ES6 中用来实现自定义遍历的接口,按照上述的示例,我们来实现下这个接口,实现Iterator就是实现[Symbol.iterator]方法
authors[Symbol.iterator] = function() {
let allAuthors = this.allAuthors
let keys = Reflect.ownKeys(allAuthors)
let values = []
return {
next() {
if (!values.length) {
if (keys.length) {
values = allAuthors[keys[0]]
keys.shift()
}
}
return {
done: !values.length,
value: values.shift()
}
}
}
}
这个代码在数据结构上部署了 Iterator 接口,我们就可以用 for...of 来遍历代码了:
for (let value of authors) {
console.log( `${value}` )
}
从代码上我们看到了自定义遍历器的强大,但是我们怎么理解 Iterator 呢?首先,要理解几个概念:可迭代协议和迭代器协议。
迭代器协议
| 属性 | 值 | 必选 |
|---|---|---|
| next | 返回一个对象的无参函数,被返回对象拥有两个属性:done 和 value | Y |
通俗的讲,迭代器协议要求符合以下条件:
- 首先,它是一个对象
- 其次,这个对象包含一个无参函数 next
- 最后,next 返回一个对象,对象包含 done 和 value 属性。其中 done 表示遍历是否结束,value 返回当前遍历的值。
如果 next 函数返回一个非对象值(比如false和undefined) 会展示一个 TypeError (“iterator.next() returned a non-object value”) 的错误
可迭代协议
可迭代协议允许 JavaScript 对象去定义或定制它们的迭代行为, 例如(定义)在一个 for..of 结构中什么值可以被循环(得到)。一些内置类型都是内置的可迭代类型并且有默认的迭代行为, 比如 Array or Map, 另一些类型则不是 (比如Object) 。
为了变成可迭代对象, 一个对象必须实现 iterator 方法, 意思是这个对象(或者它原型链 prototype chain 上的某个对象)必须有一个名字是 Symbol.iterator 的属性:
| 属性 | 值 | 必选 |
|---|---|---|
| [Symbol.iterator] | 返回一个对象的无参函数,被返回对象符合迭代器协议 | Y |
如果让一个对象是可遍历的,就要遵守可迭代协议,该协议要求对象要部署一个以 Symbol.iterator 为 key 的键值对,而 value 就是一个无参函数,这个函数返回的对象要遵守迭代器协议。
Promise
在ES2015 (ES6)中引入了Promise对象,它主要用来解决异步问题。
Promise特点
Promise对象代表一个异步操作,它有三种状态
- 进行中 (Pending)
- 已完成 (Resolved/Fulfilled)
- 已失败 (Rejected)
只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。
Promise对象状态一旦改变,就不会再变,Promise对象的状态改变,只有两种可能
- 从Pending变为Resolved
- 从Pending变为Rejected
只要这两种情况发生,状态就凝固,不会再变了,会一直保持这个结果。
Promise相关API
new Promise()
Promise是一个构造函数,我们可以通过new关键字来创建一个Promise实例,也可以直接使用Promise的一些静态方法。
new Promise((resolve, reject) => {...});
处理器函数接收两个参数分别是resolve和reject,这两个参数也是两个回调函数
resolve 函数在异步操作成功时调用,并将异步操作的结果,作为参数传递出去
reject 函数在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去
简单理解就是一个是成功回调,一个是失败回调。
比如下面的例子,当随机数小于5我们就返回成功,否则就返回失败。
function fun1() {
return new Promise((resolve, reject) => {
const num = Math.ceil(Math.random()*10)
if(num < 5){
resolve(num)
}else{
reject('数字太大')
}
})
}
我们还可以使用Promise的一些静态方法来创建Promise对象,上面的例子我们可以改写为
function fun2() {
const num = Math.ceil(Math.random()*10)
if(num < 5){
return Promise.resolve(num)
}else{
return Promise.reject('数字太大')
}
}
Promise.prototype.then()
Promise实例生成以后,可以用then方法指定resolved状态和reject状态的回调函数。
Promise.prototype.then(onFulfilled[, onRejected])
第一个参数是resolved状态的回调函数,第二个参数是reject状态的回调函数(一般我们不使用而是使用catch方法)。
fun1().then(
(res) => {
// res是fun1方法resolve的参数,即小于5的随机数
console.log(res);
},
(err) => {
// res是fun1方法reject的参数,即数字太大
console.log(err);
}
);
前面说到我们一般不使用而是使用then方法的第二个参数,而是使用catch方法,所以上面的例子我们还可以改写为
fun1()
.then((res) => {
console.log(res);
})
.catch((err) => {
console.log(err);
});
说到这,很多小伙伴会好奇,为什么不使用then方法的第二个参数而是使用catch方法来处理错误呢?我们知道Promise是链式调用的,实际使用过程中可能会有很多的then方法一直调用下去,所以如果我们把错误处理都写在then方法中的话就需要在每个then中对错误进行处理了。而使用catch方法的话我们只需要在链式调用的最末尾加上一个catch方法就可以啦,就可以捕捉到第一个错误啦。这样会大大简化我们的代码。
then 方法必须返回一个 promise 对象
- 如果
then方法中返回的是一个普通值(如Number、String等)就使用此值包装成一个新的Promise对象返回。
function fun3() {
return Promise.resolve(1);
}
fun3()
.then((res) => {
console.log(res); // 1
return "success"; // 返回的是一个普通值(如Number、String等)
})
.then((res) => {
console.log(res); // success
});
- 如果
then方法中返回了一个Promise对象,那就以这个对象为准,返回它的结果。
function fun4() {
return Promise.resolve(1);
}
fun4()
.then((res) => {
console.log(res); // 1
return Promise.resolve("success2");
})
.then((res) => {
console.log(res); // success2
});
- 如果
then方法中没有return语句,就返回一个用undefined包装的Promise对象。
function fun5() {
return Promise.resolve(1);
}
fun5()
.then((res) => {
console.log(res); // 1
})
.then((res) => {
console.log(res); // undefined
});
- 如果
then方法中出现异常,则会流转到下一个then的onRejected或者最末尾的catch方法中。
function fun6() {
return Promise.resolve("fun6");
}
fun6()
.then(
(res) => {
console.log("then1 resolve方法" + res);
return Promise.reject("error1");
},
(err) => {
console.log("then1 reject方法" + err);
}
)
.then(
(res) => {
console.log("then2 resolve方法" + res);
},
(err) => {
console.log("then2 reject方法" + err);
}
);
上面的例子会输出 then1 resolve方法 fun6、then2 reject方法 error1
function fun6() {
return Promise.resolve("fun6");
}
fun6()
.then((res) => {
console.log("then1 resolve方法" + res);
return Promise.reject("error1");
})
.then((res) => {
console.log("then2 resolve方法" + res);
return Promise.reject("error2");
})
.catch((err) => {
console.log("catch方法" + err);
});
上面的例子会输出 then1 resolve方法 fun6、catch方法 error1
- 如果
then方法没有传入任何回调,则继续向下传递(即所谓的值穿透)
function fun7() {
return Promise.resolve("fun7");
}
fun7()
.then()
.then()
.then((res) => {
console.log(res); // fun7
});
Promise.prototype.catch()
catch方法前面也有介绍到,主要是用来捕获错误的。此方法也会返回一个新Promise对象。
如果catch方法里再有错误则通过 catch 返回的Promise是一个rejected实例,否则它就是一个成功的resolved实例。
function fun8() {
return Promise.reject("fun8");
}
fun8()
.catch((err) => {
console.log(err); // fun8
// 如果不抛错则会进入下一个then方法的resolve回调方法,否则会进入reject回调方法
// throw new Error("11");
})
.then(
(res) => {
console.log("resolve" + res);
},
(err) => {
console.log("reject" + err);
}
);
相较于使用then的第二个参数,笔者还是推荐使用catch方法来获取错误。
Promise.resolve()
这个方法是一个静态方法,前面在介绍new Promise()构造函数的时候我们也简单介绍了下,该方法接收一个参数并转换为Promise对象。
Promise.resolve(value)
// 类似于
new Promise((resolve, reject) => {
resolve(value)
})
Promise.reject()
这个方法是一个静态方法,前面在介绍new Promise()构造函数的时候我们也简单介绍了下,该方法接收一个参数并转换为Promise对象。
Promise.reject(value)
// 类似于
new Promise((resolve, reject) => {
reject(value)
})
Promise.all()
Promise.all(iterable) 参数为一组 Promise 实例组成的数组,用于将多个Promise实例包装成一个新的 Promise实例。
当数组中的Promise实例都为都 Resolved 的时候,Promise.all() 的状态才会 Resolved,否则为Rejected。并且Rejected是第一个被Rejected 的 Promise 的返回值。
function fun10() {
return Promise.resolve("fun10");
}
function fun11() {
return Promise.resolve("fun11");
}
function fun12() {
return Promise.resolve("fun12");
}
Promise.all([fun10(), fun11(), fun12()])
.then((res) => {
console.log(res); // ['fun10', 'fun11', 'fun12']
})
.catch((err) => {
console.log(err);
});
function fun10() {
return Promise.resolve("fun10");
}
function fun11() {
return Promise.reject("fun11");
}
function fun12() {
return Promise.reject("fun12");
}
Promise.all([fun10(), fun11(), fun12()])
.then((res) => {
console.log(res);
})
.catch((err) => {
console.log(err); // 输出fun11,第一个被`Rejected` 的 `Promise` 的返回值
});
Promise.race()
race方法与all方法不同,race方法中只要对象中有一个状态改变了,它的状态就跟着改变,并将那个改变状态实例的返回值传递给回调函数。
也就是不管失败与成功第一个Promise的返回值就是race方法的返回值。resolve就会进入then方法,否则进入catch方法
function fun13() {
return new Promise(function (resolve, reject) {
setTimeout(() => {
return resolve("fun13");
}, 2000);
});
}
function fun14() {
return new Promise(function (resolve, reject) {
setTimeout(() => {
return resolve("fun14");
}, 1000);
});
}
Promise.race([fun13(), fun14()])
.then((res) => {
console.log("race resolve" + res); // race resolvefun14
})
.catch((err) => {
console.log("race error" + err);
});
异步回调中抛错catch捕捉不到
首先我们看在Promise对象的处理器函数中直接抛出错误,这种情况是能捕捉到错误的。
function fun15() {
return new Promise(function (resolve, reject) {
throw new Error("这是一个错误");
});
}
fun15()
.then((res) => {
console.log(res);
})
.catch((err) => {
console.log(err); // Error: 这是一个错误
});
在下面代码,在Promise对象的处理器函数中模拟一个异步抛错,这种情况就捕获不到错误了,就会报Uncaught Error。原因是什么呢?这里就涉及到微任务和宏任务了,不清楚的可以看看笔者js执行上下文和执行机制一文说透这篇文章。
function fun16() {
return new Promise(function (resolve, reject) {
setTimeout(() => {
throw new Error("这是一个错误");
}, 1000);
});
}
fun16()
.then((res) => {
console.log(res);
})
.catch((err) => {
console.log(err); // Uncaught Error: 这是一个错误
});
那要怎么解决呢?这就需要我们再使用try catch进行处理啦,catch到错误后再手动reject。
function fun17() {
return new Promise(function (resolve, reject) {
setTimeout(() => {
try {
throw new Error("这是一个错误");
} catch (err) {
reject(err);
}
}, 1000);
});
}
fun17()
.then((res) => {
console.log(res);
})
.catch((err) => {
console.log(err); // Error: 这是一个错误
});
Generator
Generator也是在在ES2015 (ES6)中引入的,它也是用来解决异步问题的。最大的特点就是可以交出函数的执行权。
Generator函数需要和yield关键字配合使用。
语法
*用来表示函数为 Generator 函数,并且只能使用在function函数,不能用在箭头函数中。
函数内部有yield字段,yield用来定义函数内部的状态,并让出执行权,这个关键字只能出现在生成器函数体内,但是生成器中也可以没有 yield 关键字,函数遇到 yield 的时候会暂停,并把 yield 后面的表达式结果抛出去。
调用 Generator 函数和调用普通函数一样,在函数名后面加上()即可,但是Generator 函数不会像普通函数一样立即执行,而是返回一个指向内部状态对象的指针,类似迭代器对象 Iterator 的 next 方法,我们需要手动调用next方法来进行下一步操作,指针就会从函数头部或者上一次停下来的地方开始执行。
这里可能会涉及到迭代器(Iterator),不了解的可以先看看笔者前面写的对象数组遍历 Iterator章节
// 写法很多,function* fn()、function*fn()和function *fn()都可以
function* generatorFn() {
console.log("a");
yield "1";
console.log("b");
yield "2";
console.log("c");
return "3";
}
const generatorIt = generatorFn();
console.log(generatorIt.next()); // {value: '1', done: false}
console.log(generatorIt.next()); // {value: '2', done: false}
console.log(generatorIt.next()); // {value: '3', done: true}
分析Generator函数的执行过程
上面的代码会依次输出a、{value: '1', done: false}、 b、 {value: '2', done: false}、 c、 {value: '3', done: true}下面我们来分析下Generator 函数的执行过程
-
首先
Generator函数执行,返回了一个指向内部状态对象的指针generatorIt,此时没有任何输出。 -
第一次调用
next方法,从Generator函数的头部开始执行,先是打印了a,执行到yield就停下来,并执行紧跟着yield后边的表达式,将表达式的值'1'作为返回对象的value属性值,此时函数还没有执行完,返回对象的done属性值是false。 -
第二次调用
next方法,从第一个yield下面开始运行,先是打印了b,执行到第二个yield就停下来,并执行紧跟着yield后边的表达式,将表达式的值'2'作为返回对象的value属性值,此时函数还没有执行完,返回对象的done属性值是false。 -
第三次调用
next方法,从第二个yield下面开始运行,先是打印了c,然后执行了函数的返回操作,并将return后面的表达式的值,作为返回对象的value属性值,此时函数已经结束,所以done属性值为true。在这一步如果函数没有返回值这里就会返回{value: undefined, done: true}。
说到这里关于Generator函数是不是有了初步的理解呢?简单的理解就是Generator函数yield放到哪里它就停到哪里(注意 紧跟在yield后面的语句是会执行的,并且其返回值是作为迭代对象的value),调用时使用next方法一步一步往后走。
再次分析Generator函数的执行过程
关于yield后面的语句是在当次执行还是next后执行呢?很多小伙伴分不清楚,所以笔者再举个例子来分析下。
function* generatorFn2() {
console.log("a");
yield console.log("a2");
console.log("b");
yield console.log("b2");
console.log("c");
}
const generatorIt2 = generatorFn2();
console.log(generatorIt2.next()); // {value: undefined, done: false}
console.log(generatorIt2.next()); // {value: undefined, done: false}
console.log(generatorIt2.next()); // {value: undefined, done: true}
上面的代码会依次输出a、a2、{value: undefined, done: false}、 b、b2、 {value: undefined, done: false}、 c、 {value: undefined, done: true},所以通过这里例子我们可以看出,紧跟在yield后面的语句是在当次执行的。
for…of 遍历Generator
在对象数组遍历 Iterator章节里面笔者已经说过了,只要实现了迭代器方法就能使用for of遍历,所以我们可以使用for of来运行我们的Generator函数,所以不再需要我们手动调用next方法啦,一旦next方法的返回对象的done属性为true,for...of循环就会中止,且不包含该返回对象。怎么理解这里的且不包含该返回对象呢? 就是当done为true时就会终止循环所以最后一项是不会输出出来的。
function* generatorFn() {
console.log("a");
yield "1";
console.log("b");
yield "2";
console.log("c");
return "3";
}
for (const iterator of generatorFn()) {
console.log(iterator); // a、1、b、2、c
}
上面的例子会依次输出a、1、b、2、c,并没有输出3,所以就印证了当done为true时就会终止循环所以最后一项是不会输出出来的。
所以Generator函数可以通过for of自动执行,不再需要手动调用next方法,但是最后一项是不会输出来的,这里需要注意下。
Generator函数传参
有小伙伴说既然yield有返回值,是不是我们在代码中通过const res = yield "1";输出res就能得到{value: '1', done: false}呢?下面我们再来分析下
function* generatorFn3() {
console.log("a");
const res = yield "1";
console.log(res); // undefined
}
const generatorIt3 = generatorFn3();
generatorIt3.next()
generatorIt3.next()
上面的代码会依次输出a、undefined,并没有跟我们想象的一样输出a、{value: '1', done: false}而是输出了a、undefined。那我们需要怎样传参呢?这就需要用到next方法啦。我们把上面的例子再改下。
function* generatorFn3() {
console.log("a");
const res = yield "1";
console.log(res); // randy
}
const generatorIt3 = generatorFn3();
generatorIt3.next()
generatorIt3.next('randy') // 通过next方法传参
上面的代码会依次输出a、randy。所以参数可以通过下一次的next来传递,也就是说当 next 传入参数的时候,该参数会作为上一步yield的返回值。
yield* 表达式
在yield命令后面加上星号,表明它返回的是一个遍历器,这被称为yield*表达式。
function *foo(){
yield "foo1"
yield "foo2"
}
function *bar(){
yield "bar1"
yield* foo()
yield "bar2"
}
for(let val of bar()){
console.log(val)
}
// bar1 foo1 foo2 bar2
yield命令后面如果不加星号,返回的是整个数组,加了星号就表示返回的是数组的遍历器
function* gen1(){
yield ["a", "b", "c"]
}
for(let val of gen1()){
console.log(a)
}
// ["a", "b", "c"]
function* gen2(){
yield* ["a", "b", "c"]
}
for(let val of gen2()){
console.log(a)
}
// a b c
Generator中的return
return 方法返回给定值,并结束遍历 Generator 函数,当 return 无没有传值时,就返回 undefined。
function* foo() {
yield 1;
yield 2;
yield 3;
}
var f = foo();
console.log(f.next());
// 输出{value: 1, done: false}
console.log(f.return("hahaha"));
// 由于调用了return方法,所以遍历已结束,done变为true 输出{value: "hahaha", done: true}
console.log(f.next());
// 再次调用也只能输出{value: undefined, done: true}
Generator函数优雅的流程控制方式,可以让函数在指定位置可中断执行,但是实际开发过程中我们很少单独Generator函数,因为手动一次次运行next方法十分麻烦,一般我们都会搭配执行器(如 co 库)来运行Generator函数,所以对于单纯解决异步问题还是不太好用。
Generator中的throw
可以通过 throw 方法在 Generator 外部控制内部执行的“终断”。也就是我们常说的抛出异常。
function* gen() {
while (true) {
try {
yield 42
} catch (e) {
console.log(e.message)
}
}
}
let g = gen()
console.log(g.next()) // { value: 42, done: false }
console.log(g.next()) // { value: 42, done: false }
console.log(g.next()) // { value: 42, done: false }
// 中断操作
g.throw(new Error('break'))
console.log(g.next()) // {value: undefined, done: true}
Module
模块化的发展
技术的诞生是为了解决某个问题,模块化也是。 随着前端的发展,web技术日趋成熟,js功能越来越多,代码量也越来越大。之前一个项目通常各个页面公用一个js,但是js逐渐拆分,项目中引入的js越来越多. 在js模块化诞生之前,开发者面临很多问题:
- 全局变量污染:各个文件的变量都是挂载到window对象上,污染全局变量。
- 变量重名:不同文件中的变量如果重名,后面的会覆盖前面的,造成程序运行错误。
- 文件依赖顺序:多个文件之间存在依赖关系,需要保证一定加载顺序问题严重。
模块化是指解决一个复杂问题时自顶向下逐层把系统划分成若干模块的过程, 有多种属性,分别反映其内部特性。百度百科中,模块化的定义是: 模块化是一种处理复杂系统分解为更好的可管理模块的方式。 简单的说,把一个复杂的东西分解成多个甚至多层次的组成部分,以一种良好的机制管理起来,就可以认为是模块化。而对于软件开发来说,函数(过程)就是最常见也是最基本的模块之一。
我觉得用乐高积木来比喻模块化再好不过了。每个积木都是固定的颜色形状,想要组合积木必须使用积木凸起和凹陷的部分进行连接,最后多个积木累积成你想要的形状。
模块化其实是一种规范,一种约束,这种约束会大大提升开发效率。将每个js文件看作是一个模块,每个模块通过固定的方式引入,并且通过固定的方式向外暴露指定的内容。 按照js模块化的设想,一个个模块按照其依赖关系组合,最终插入到主程序中。
我们梳理一下模块化的发展情况:
无模块化–>CommonJS规范–>AMD规范–>CMD规范–>ES6模块化
1、CommonJS规范 Node中模块化规范
Commonjs的诞生给js模块化发展有了重要的启发,Commonjs非常受欢迎, 但是局限性很明显:Commonjs基于Node原生api在服务端可以实现模块同步加载, 但是仅仅局限于服务端,客户端如果同步加载依赖的话时间消耗非常大,所以需要一个 在客户端上基于Commonjs但是对于加载模块做改进的方案,于是AMD规范诞生了。
2、AMD规范, 异步模块定义, 允许指定回调函数,AMD 是 RequireJS 在推广过程中对模块定义的规范化产出。它采用异步方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到所有依赖加载完成之后(前置依赖),这个回调函数才会运行。
3、CMD规范,同样是受到Commonjs的启发,国内(阿里)诞生了一个CMD(Common Module Definition)规范。该规范借鉴了Commonjs的规范与AMD规范,在两者基础上做了改进。
CMD 是 SeaJS 在推广过程中对模块定义的规范化产出。
AMD 推崇依赖前置、提前执行 CMD推崇依赖就近、延迟执行。
4、 到了2015年,ES6规范中,终于将模块化纳入JavaScript标准,从此js模块化被官方扶正,也是未来js的标准. 在ES6中,我们可以使用 import 关键字引入模块,通过 exprot 关键字导出模块,功能较之于前几个方案更为强大,也是我们所推崇的,但是由于ES6目前无法在浏览器中执行,所以,我们只能通过babel将不被支持的import编译为当前受到广泛支持的 require。
下面笔者着重讲解下ES6中的模块化。
export
模块功能主要由两个命令构成:export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
一个模块就是一个独立的文件。该文件内部的所有变量,外部无法获取。如果你希望外部能够读取模块内部的某个变量,就必须使用export关键字输出该变量。
1.导出变量或者常量
export const name = 'hello'
export let addr = 'BeiJing City'
export var list = [1, 2, 3]
或者以对象的方式导出
const name = 'hello'
let addr = 'BeiJing City'
var list = [1, 2, 3]
export {
name,
addr,
list
}
2.导出函数
export function say() {
console.log('say')
}
export const run = () => {
console.log("run");
};
或者以对象的方式导出
const say = () => {
console.log('say')
}
const run = () => {
console.log('run')
}
export {
say,
run
}
- 导出 Object
let data = {
code: 0,
message: 'success'
}
export {
data
}
- 导出 Class
class Test {
constructor() {
this.id = 2
}
}
export {
Test
}
或者
export class Test {
constructor() {
this.id = 2
}
}
as
如果想为输入的变量重新取一个名字,import或export命令要使用as关键字,将变量重命名。
const name = 'hello'
let addr = 'BeiJing City'
var list = [1, 2, 3]
export {
name,
addr,
list as _list
}
// 使用
import {name as cname} from 'xxx'
export default
使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。但是,用户肯定希望快速上手,未必愿意阅读文档,去了解模块有哪些属性和方法。
为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
var list = [1, 2, 3]
export default list
// 使用,不需要知道引入文件里怎么命名的
import arr from 'xxx'
相较于export,export default有如下特点
- export default只能有一个,而export可以有多个。
export const name1 = "randy";
const name2 = "demi";
export { name2 };
- export能直接导出变量表达式,export default不行。
// 这样会报错
// export default const name3 = 'jack'
// 需要先定义再导出
const name3 = "jack";
export default name3;
- export在导出变量的时候需要以对象的形式,而 export default则不需要
const name3 = "jack";
// 这样会报错
// export name3
// 需要这样
export {name3}
// 可以
export default name3;
- 通过export方式导出,在导入时要加{ },export default则不需要
export const name3 = 'jack'
const name4 = "tom";
export default name4;
// 导入
import name4, {name3} from xxx
import
使用export命令定义了模块的对外接口以后,其他 JS 文件就可以通过import命令加载这个模块。
- 直接导入
假设导出模块 A 是这样的:
const name = 'hello'
let addr = 'BeiJing City'
var list = [1, 2, 3]
export {
name as cname,
addr as caddr
}
export default list
则导入:
import list, {
cname,
caddr
} from A
- 修改导入名称
import list, {
cname as name,
caddr
} from A
- 批量导入
import list, * as mod from A
console.log(list)
console.log(mod.cname)
console.log(mod.caddr)
总结
笔者用一张图来总结ES6所有知识点。
后记
感谢小伙伴们的耐心观看,本文为笔者个人学习笔记,如有谬误,还请告知,万分感谢!如果本文对你有所帮助,还请点个关注点个赞~,您的支持是笔者不断更新的动力!