Java中的内存分配
Java 程序运行时,需要在内存中分配空间。为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
一、栈:储存局部变量
- 局部变量:在方法的定义中或者在方法声明上的变量称为局部变量。
- 特点:栈内存的数据用完就释放。
二、堆:储存 new 出来的东西
- 特点:
- 每一个 new 出来的东西都有地址值;
- 每个变量都有默认值 (byte, short, int, long 的默认值为 0;float, double 的默认值为 0.0;char 的默认值为 “\u0000”;boolean 的默认值为 false;引用类型为 null);
- 使用完毕就变成垃圾,但是并没有立即回收。会有垃圾回收器空闲的时候回收。

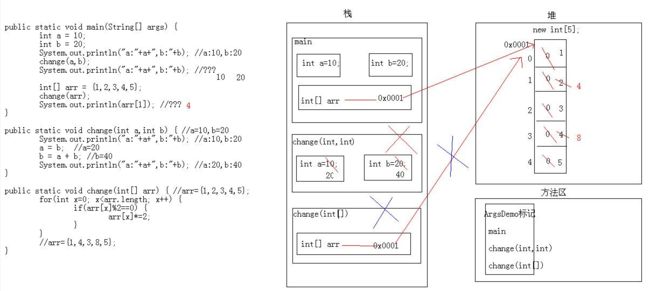
三、方法区:
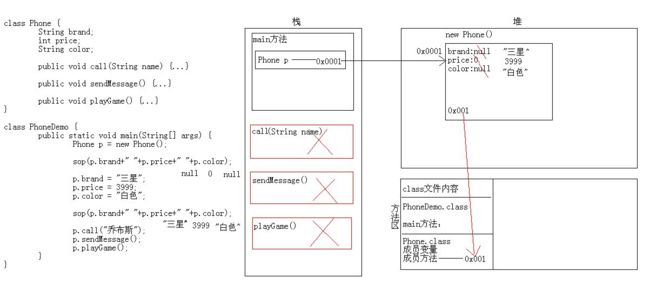
一个对象的运行过程:
- 程序从 main 方法中进入;运行到 Phone p 时,在栈中开辟了一个空间;
- new Phone() 时,在队中开了一个内存空间,此时会有一个内存值为 0x0001;此时会找到对应的 Phone 的 class 文件,发现有三个变量和三个方法,于是将三个成员变量放在了堆中,但是此时的值为默认值(具体默认值见上)。注意,在方法区里也有一个地址值,假设为 0x001,可以认为在堆中也有一个位置,在堆中的位置,可以找到方法区中相对应的方法;
- 继续运行,p.brand = "三星";将三星赋值给 p.brand,通过栈中的 p 找到了堆中的 brand,此时的 null 值变为“三星”。剩下的类似;
- 当运行到 p.call("乔布斯") 时,通过栈中的 p 找到堆中存在的方法区的内存地址,从而指引到方法区中的 Phone.class 中的方法。从而将 call 方法加载到栈内存中,注意:当执行完毕后,call 方法就从栈内存中消失!剩余的如上。
- 最后,main 方法消失!
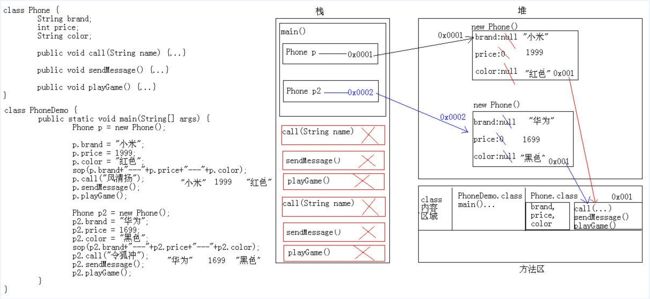
两个对象的运行过程:
- 程序从 main() 方法进入,运行到 Phone p 时,栈内存中开内存空间;
- new Phone() 时,在队中开了一个内存空间,内存值为 0x0001;此时会找到对应的 Phone 类,发现有三个变量,于是将三个成员变量放在了堆中,但是此时的值为默认值。又发现该类还存在方法,于是将该方法的内存值留在了堆中,在方法区里也有一个地址值,假设为 0x001,这个值与堆中的值相对应;
- 程序继续运行,到 p.brand 时,进行了负值,同上;
- 当程序运行到 Phone p2 时;到 new Phone() 时,在堆内存中开辟了内存空间 0x0002,赋值给 Phone p2;
- 剩下跟一个对象的内存相同。
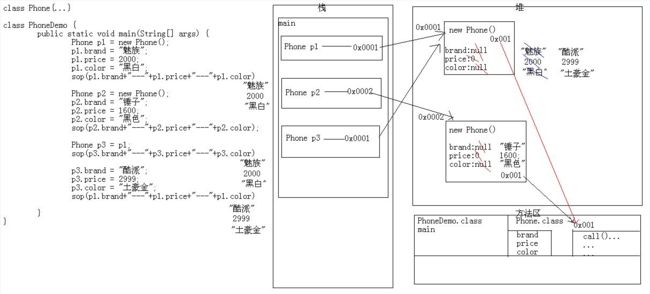
三个对象的运行过程:
- 基本流程跟前两个无差别;
- 但是当运行到 Phone p3 时,在栈内存中分配了一个空间,然后将 p1 的内存赋值给了 p3,即此时 Phone p3 的内存是指向 0x0001 的;
- 继续给变量赋值,会将原来已经赋值的变量给替换掉。
四、本地方法区(和系统相关)
五、寄存器(给 CPU 使用)
注意:
Java中的对象都分配在堆中?
Java中的对象可以不分配在堆中,因为还存在栈上分配、同步省略和标量替换
上述三种技术都需要使用:逃逸分析(是一种可有效减少Java程序中同步负载和堆分配压力的跨函数全局数据流分析的算法)
Java 中对象的创建一般会由堆内存去分配内存空间来进行存储,在堆内存空间不足的时候,GC 便会对堆内存进行垃圾回收,如果 GC 运行的次数过多,便会影响程序的性能,
所以 “逃逸分析” 由此诞生,它的目的就是判断哪些对象是可以存储在栈内存中而不用存储在堆内存中的,
从而让其随着线程的消逝而消逝,进而减少了 GC 发生的频率,这也是常见的 JVM 优化技巧之一。当一个对象在方法中被定义后,对象如果只在方法内部使用,则任务没有发生逃逸;如果对象被外部引用,则认为发生逃逸。通过逃逸分析,HotSpot编译器能够分析出一个新对象的使用范围,从而决定是否将这个对象分配到堆上。
未逃逸的实例:
void m(){
//obj仅在方法中使用,没有发生逃逸
Object obj = new Object();
}逃逸示例:
Object m(){
Object obj = new Object();
return obj;//对象可能被外部对象引用,发生了逃逸
}栈上分配
栈上分配所指的栈,是Java方法对应的栈帧。
没有发生逃逸的对象可能被优化分配到栈上,因为随着方法的执行结束,栈空间就被移除。
在JDK6中,HotSpot就默认开启了逃逸分析,也可以通过-XX:+DoEscapeAnalysis显示开启逃逸分析,-XX:+PrintEscapeAnalysis可以查看逃逸分析的筛选结果。
当对象没有发生逃逸时,该对象就可以通过标量替换分解成成员标量分配在栈内存中,和方法的生命周期一致,随着栈帧出栈时销毁,减少了 GC 压力,提高了应用程序性能。
所以在开发中,能使用局部变量的,就不要在方法外定义。
同步省略
如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
在动态编译同步代码块时,JIT编译器借助逃逸分析来判断所使用的的锁对象是否只能被一个线程访问而没有发布到其他线程,如果没有,JIT编译器会在编译这个同步块时,取消对这部分代码的同步。这个过程也叫做锁消除
示例代码如下:
void m(){
Object lockObj = new Object();
synchronized(lockObj){
//lockObj对象,只能在当前线程访问,所以会被取消同步。
System.out.print("hello");
}
}
复制代码最终代码
void m(){
Object lockObj = new Object();
System.out.print("hello");//锁被消除了
}
复制代码标量替换
标量替换也叫分离对象
标量是指一个无法再分解的数据,Java中的基本数据类型就是标量,相应的,如Java对象,就是可以再分解的聚合量。在JIT编译时,经过逃逸分析,发现一个对象不会被外界访问,那么就会把这个对象拆分成若干个其中的包含成员变量来代替。
有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(全部)可以不存储在内存,而是存储在CPU的寄存器中。
可以通过-XX:+EliminateAllocations开启标量替换(默认开启),允许将对象打散到栈上。
实例代码如下:
class Location {
int x;
int y;
}
void m(){
Location loc = new Location();
loc.x = 1;
loc.y = 2;
System.out.print("x:"+loc.x+",y:"+loc.y);
}
复制代码最终代码:
void m(){
int x = 1;
int y = 2;
System.out.print("x:"+x+",y:"+y);
}
复制代码存在的问题
逃逸分析自身也需要一系列复杂的分析,开销较大,无法保证是正优化。如经过分析后,发现所有对象是不逃逸的,那么这个分析过程就浪费了。。所以在HotSpot中并未使用栈上分配,所以可以明确,所有的对象实例都是创建在堆上的。
总结:
逃逸分析的原理理解起来其实很简单,但 JVM 在实际应用过程中,还是有诸多因素需要考虑的。
比如,逃逸分析不能在静态编译时进行,必须在 JIT 里完成。原因大致是:与 Java 的动态性有冲突。因为你可以在运行时,通过动态代理改变一个类的行为,此时,逃逸分析是无法得知类已经变化了。总之就是:因为只有当收集到足够的运行数据时,JVM 才可以更好地判断对象是否发生了逃逸。
当然,逃逸分析并不是没有劣势的,因为逃逸分析是需要消耗一定的性能去执行分析的,所以说如果方法中的对象全都是处于逃逸状态,那么就没有起到优化的作用,从而就白白损失了这部分的性能消耗。
参考资料:
https://segmentfault.com/a/1190000038262877