TTS | 轻量级VITS2的项目实现以及API设置
本文主要是实现了MB-iSTFT-VITS2语音合成模型的训练,相比于VITS模型,MB-iSTFT-VITS模型相对来说会小一点,最重要的是在合成结果来看,MB-iSTFT-VITS模型推理更快,更加自然(个人经验).项目地址如下:
FENRlR/MB-iSTFT-VITS2: Application of MB-iSTFT-VITS components to vits2_pytorch (github.com)
目前项目还未来得及发表论文,且项目还在完善中(截止到2023.10.18)。
目录
0.环境设置
1.项目设置及数据处理
2.训练
3.设置API
过程中遇到的问题及解决(PS)
[PS1]训练时出现cuda out of m
[PS2]训练后出现线程相关错误
[PS3]API设置时出现,RuntimeError: Invalid device, must be cuda device
[PS4]RuntimeError: Error(s) in loading state_dict for SynthesizerTrn: size mismatch for enc_q.pre.weight: copying a param with shape torch.Size([192, 80, 1]) from checkpoint, the shape in current model is torch.Size([192, 513, 1]).
[PS5]TypeError: load_checkpoint() got an unexpected keyword argument 'skip_optimizer'
0.环境设置
docker镜像容器(Linux20.04+Pytorch1.13.1+torchvision0.14.1+cuda11.7+python3.8),
1.项目设置及数据处理
# 克隆项目到本地
git clone https://github.com/FENRlR/MB-iSTFT-VITS2
cd MB-iSTFT-VITS2
#安装所需要的库
pip install -r requirements.txt
apt-get install espeak
# 文本预处理
## 选择1 : 单人数据集
python preprocess.py --text_index 1 --filelists PATH_TO_train.txt --text_cleaners CLEANER_NAME
python preprocess.py --text_index 1 --filelists PATH_TO_val.txt --text_cleaners CLEANER_NAME
## 选择2 : 多人数据集
python preprocess.py --text_index 2 --filelists PATH_TO_train.txt --text_cleaners CLEANER_NAME
python preprocess.py --text_index 2 --filelists PATH_TO_val.txt --text_cleaners CLEANER_NAME
# 设置MAS
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplace
前期设置与vits/vits2基本相同
编辑配置文件
2.训练
# 选择1 : 单人数据集训练
python train.py -c configs/mb_istft_vits2_base.json -m models/test
# 选择2 : 多人数据集训练
python train_ms.py -c configs/mb_istft_vits2_base.json -m models/test训练后生成
训练过程

3.设置API
webui.py
import sys, os
import logging
import re
logging.getLogger("numba").setLevel(logging.WARNING)
logging.getLogger("markdown_it").setLevel(logging.WARNING)
logging.getLogger("urllib3").setLevel(logging.WARNING)
logging.getLogger("matplotlib").setLevel(logging.WARNING)
logging.basicConfig(
level=logging.INFO, format="| %(name)s | %(levelname)s | %(message)s"
)
logger = logging.getLogger(__name__)
import torch
import argparse
import commons
import utils
from models import SynthesizerTrn
from text.symbols import symbols
#from text import cleaned_text_to_sequence, get_bert
from text import text_to_sequence
#from text.cleaner import clean_text
import gradio as gr
import webbrowser
import numpy as np
net_g = None
if sys.platform == "darwin" and torch.backends.mps.is_available():
device = "mps"
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
else:
device = "cuda"
def get_text(text, hps):
text_norm = text_to_sequence(text, hps.data.text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
def langdetector(text): # from PolyLangVITS
try:
lang = langdetect.detect(text).lower()
if lang == 'ko':
return f'[KO]{text}[KO]'
elif lang == 'ja':
return f'[JA]{text}[JA]'
elif lang == 'en':
return f'[EN]{text}[EN]'
elif lang == 'zh-cn':
return f'[ZH]{text}[ZH]'
else:
return text
except Exception as e:
return text
def infer(text, sdp_ratio, noise_scale, noise_scale_w, length_scale, sid):
global net_g
fltstr = re.sub(r"[\[\]\(\)\{\}]", "", text)
stn_tst = get_text(fltstr, hps)
speed = 1
output_dir = 'output'
sid = 0
with torch.no_grad():
x_tst = stn_tst.to(device).unsqueeze(0)
x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(device)
audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1 / speed)[0][
0, 0].data.cpu().float().numpy()
return audio
def tts_fn(
text, speaker, sdp_ratio, noise_scale, noise_scale_w, length_scale
):
slices = text.split("|")
audio_list = []
with torch.no_grad():
for slice in slices:
audio = infer(
slice,
sdp_ratio=sdp_ratio,
noise_scale=noise_scale,
noise_scale_w=noise_scale_w,
length_scale=length_scale,
sid=speaker,
)
audio_list.append(audio)
silence = np.zeros(hps.data.sampling_rate) # 生成1秒的静音
audio_list.append(silence) # 将静音添加到列表中
audio_concat = np.concatenate(audio_list)
return "Success", (hps.data.sampling_rate, audio_concat)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"-m", "--model", default="/workspace/tts/MB-iSTFT-VITS2/logs/models/G_94000.pth", help="path of your model"
)
parser.add_argument(
"-c",
"--config",
default="/workspace/tts/MB-iSTFT-VITS2/logs/models/config.json",
help="path of your config file",
)
parser.add_argument(
"--share", default=False, help="make link public", action="store_true"
)
parser.add_argument(
"-d", "--debug", action="store_true", help="enable DEBUG-LEVEL log"
)
args = parser.parse_args()
if args.debug:
logger.info("Enable DEBUG-LEVEL log")
logging.basicConfig(level=logging.DEBUG)
hps = utils.get_hparams_from_file(args.config)
if "use_mel_posterior_encoder" in hps.model.keys() and hps.model.use_mel_posterior_encoder == True:
print("Using mel posterior encoder for VITS2")
posterior_channels = 80 # vits2
hps.data.use_mel_posterior_encoder = True
else:
print("Using lin posterior encoder for VITS1")
posterior_channels = hps.data.filter_length // 2 + 1
hps.data.use_mel_posterior_encoder = False
device = (
"cuda:0"
if torch.cuda.is_available()
else (
"mps"
if sys.platform == "darwin" and torch.backends.mps.is_available()
else "cpu"
)
)
net_g = SynthesizerTrn(
len(symbols),
posterior_channels,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers, #- >0 for multi speaker
**hps.model
).to(device)
_ = net_g.eval()
#_ = utils.load_checkpoint(args.model, net_g, None, skip_optimizer=True)
_ = utils.load_checkpoint(path_to_model, net_g, None)
#speaker_ids = hps.data.spk2id
#speakers = list(speaker_ids.keys())
speakers = hps.data.n_speakers
languages = ["KO"]
with gr.Blocks() as app:
with gr.Row():
with gr.Column():
text = gr.TextArea(
label="Text",
placeholder="Input Text Here",
value="测试文本.",
)
'''speaker = gr.Dropdown(
choices=speakers, value=speakers[0], label="Speaker"
)'''
speaker = gr.Slider(
minimum=0, maximum=speakers-1, value=0, step=1, label="Speaker"
)
sdp_ratio = gr.Slider(
minimum=0, maximum=1, value=0.2, step=0.1, label="SDP Ratio"
)
noise_scale = gr.Slider(
minimum=0.1, maximum=2, value=0.6, step=0.1, label="Noise Scale"
)
noise_scale_w = gr.Slider(
minimum=0.1, maximum=2, value=0.8, step=0.1, label="Noise Scale W"
)
length_scale = gr.Slider(
minimum=0.1, maximum=2, value=1, step=0.1, label="Length Scale"
)
language = gr.Dropdown(
choices=languages, value=languages[0], label="Language"
)
btn = gr.Button("Generate!", variant="primary")
with gr.Column():
text_output = gr.Textbox(label="Message")
audio_output = gr.Audio(label="Output Audio")
btn.click(
tts_fn,
inputs=[
text,
speaker,
sdp_ratio,
noise_scale,
noise_scale_w,
length_scale,
],
outputs=[text_output, audio_output],
)
webbrowser.open("http://127.0.0.1:7860")
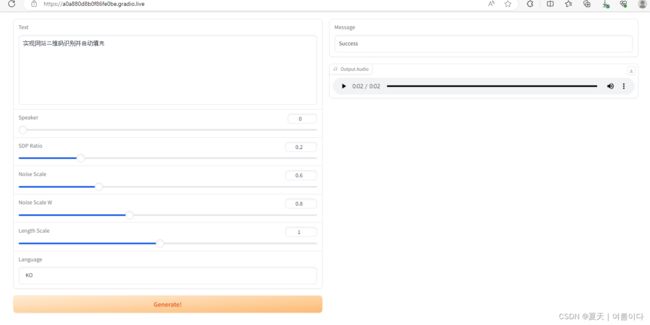
app.launch(share=True)运行后实现
过程中遇到的问题及解决(PS)
[PS1]训练时出现cuda out of m
解决办法:
- 修改batch size
- 修改num_workers=0
[PS2]训练后出现线程相关错误
Traceback (most recent call last):
File "/opt/miniconda3/envs/vits/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 69, in _wrap
fn(i, *args)
File "/workspace/tts/MB-iSTFT-VITS2/train.py", line 240, in run
train_and_evaluate(rank, epoch, hps, [net_g, net_d, net_dur_disc], [optim_g, optim_d, optim_dur_disc],
File "/workspace/tts/MB-iSTFT-VITS2/train.py", line 358, in train_and_evaluate
scaler.scale(loss_gen_all).backward()
File "/opt/miniconda3/envs/vits/lib/python3.8/site-packages/torch/_tensor.py", line 488, in backward
torch.autograd.backward(
File "/opt/miniconda3/envs/vits/lib/python3.8/site-packages/torch/autograd/__init__.py", line 197, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Detected mismatch between collectives on ranks. Rank 1 is running collective: CollectiveFingerPrint(OpType=ALLREDUCE, TensorShape=[5248002], TensorDtypes=Float, TensorDeviceTypes=TensorOptions(dtype=float (default), device=cuda, layout=Strided (default), requires_grad=false (default), pinned_memory=false (default), memory_format=(nullopt))), but Rank 0 is running collective: CollectiveFingerPrint(OpType=ALLREDUCE).
原因分析:
在jupyter lab时调用gpu后出现的错误。
解决方案:
重新再次训练后就解决了,再次训练时,会加载上次训练的权重文件。
[PS3]API设置时出现,RuntimeError: Invalid device, must be cuda device
Traceback (most recent call last):
File "aoi.py", line 55, in
model.build_wav(0, "안녕하세요", "./test.wav")
File "aoi.py", line 50, in build_wav
audio = self.net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()
File "/workspace/tts/MB-iSTFT-VITS-multilingual/models.py", line 718, in infer
o, o_mb = self.dec((z * y_mask)[:,:,:max_len], g=g)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/workspace/tts/MB-iSTFT-VITS-multilingual/models.py", line 344, in forward
pqmf = PQMF(x.device)
File "/workspace/tts/MB-iSTFT-VITS-multilingual/pqmf.py", line 78, in __init__
analysis_filter = torch.from_numpy(h_analysis).float().unsqueeze(1).cuda(device)
RuntimeError: Invalid device, must be cuda device
原因分析
1.在不支持cuda(GPU)的机器上,把模型或者数据放到GPU中。
2.因为在训练别的程序,大概率是把卡所有的显存都用上了,所以导致显存不足。
解决办法,停掉正在训练的程序,改小batch size,减少显存占用量。
[PS4]RuntimeError: Error(s) in loading state_dict for SynthesizerTrn:
size mismatch for enc_q.pre.weight: copying a param with shape torch.Size([192, 80, 1]) from checkpoint, the shape in current model is torch.Size([192, 513, 1]).
解决办法
将
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model,
).to(device)改为
net_g = SynthesizerTrn(
len(symbols),
posterior_channels,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers, #- >0 for multi speaker
**hps.model).to(device)[PS5]TypeError: load_checkpoint() got an unexpected keyword argument 'skip_optimizer'
解决办法
将原本的
_ = utils.load_checkpoint(args.model, net_g, None, skip_optimizer=True)
改为
_ = utils.load_checkpoint(args.model, net_g, None)
[PS6]api设置后运行是空白,编写gradio程序时候,发现任何代码运行起来都是一直显示Loading也不报错。

解决方案:
pip install gradio==3.12.0
或
pip install gradio==3.23.0