数据结构:顺序表,链表,双向链表
顺序表,链表以及双向链表都属于线性表,线性顾名思义,就像一根绳子一样按照一定的顺序将数据连接起来,线性表是我们日常存储数据常用的结构,在不同的场景下有着不同的应用。事实上,线性表还包括栈和队列,不过篇幅原因,这篇文章将只详细讲述顺序表,单向链表,双向链表这三种线性表,主要有存储形式,实现步骤,及它们之间的区别。
目录
顺序表
顺序表的存储形式
顺序表的动态实现
顺序表的数据插入
顺序表数据的删除
顺序表的查改
单向链表
单向链表的存储形式
单向链表数据的插入
单向链表数据的删除
双向链表
双向链表的存储形式
带头双向循环链表数据的插入和删除
顺序表与链表的区别
顺序表与链表的优缺点
何为cpu高速缓存命中率
顺序表
顺序表的存储形式
顺序表是在内存中按照顺序存放的数据形式,要求内存地址的连续,因此顺序表要靠数组来实现,但实现方法又分为静态实现和动态实现。静态实现是给定了数组的大小,数据的增删查改只能在这么大的空间里进行,多应用在明确给定了空间的大小对数据进行维护。而动态实现则可以根据需要扩大数据的容量,实现对数据的维护,静态的实现是比较容易的,设立指定大小的数据类型的数组即可,我们重点探讨动态实现。
顺序表的动态实现
实现数据容量的动态扩增,要了解动态内存开辟函数,在C语言中分别是malloc,calloc,realloc具体的功能大家自行查询,这里我们要用到realloc。要实现对已开辟空间的管理,以及当空间满了自动开辟更大的空间的功能,我们需要至少三个变量。第一个是数据类型的指针变量,设为DataType * p,用来维护已经开辟好的空间,第二个变量用来指明当前已存放了多少个数据,设为int size,第三个变量用来指明总共能存放多少个数据,将其设立为 int capacity,当size == capacity时,说明容量满了,需要扩大容量,然后利用realloc函数开辟一块更大的空间再把指针交给DataType * p来维护,为了方便传值使用,我们将这三个变量全部封装到一个结构体里。
代码实现
typedef int DateType;
typedef struct SeqList
{
SLDateType * a; //用来维护已开辟的空间
int size; //表中存放了多少个数据
int capacity; //表中实际能存放的数据
}SL;
void SeqListInit(SL* ps) //将封装后的结构体的值进行初始化
{
ps->a = NULL;
ps->size = 0;
ps->capacity = 0;
}
void SeqListAddCapacity(SL* ps) //实现顺序表的容量的动态开辟
{
if (ps->capacity == ps->size)
{
int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;
SLDateType* tmp = (SLDateType*)realloc(ps->a, newcapacity * sizeof(SLDateType));
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
ps->a = tmp;
ps->capacity = newcapacity;
tmp = NULL;
}
}
顺序表的数据插入
顺序表数据的插入有三种形式,第一种是头插,也就是在数组首元素位置处插入数据,这就要求之前已存储的所有的数据都要向后移动一位,给新插入的数据腾个位置,第二种是尾插,在顺序表的末尾进行数据的插入,第三种是指定位置的插入,那就要求要插入的这个位置及其后面的元素都要向后移动一位,腾出一个位置。由此可见,头插数据是牵一发而动全身,这样插入数据的效率是很低的,想要插入一个数据还要遍历整个数组,而指定位置的插入也没有好到哪去,按照最坏的情况是和头插一样的,时间复杂度都是O(n),只有尾插的效率是最高的,时间复杂度为O(1)
三种插入方式的代码实现
//前插
void SeqLIstPushFront(SL* ps, SLDateType x)
{
SeqListAddCapacity(ps);
for (int i = ps->size; i >0; i--)
{
ps->a[i] = ps->a[i-1];
}
ps->a[0] = x;
ps->size++;
}
//任意位置插入
void SeqListInsert(SL* ps, SLDateType x, SLDateType y)
{
SeqListAddCapacity(ps);
for (int i = ps->size; i >= x; i--)
{
ps->a[i] = ps->a[i - 1];
}
ps->a[x - 1] = y;
ps->size++;
}
//尾插
void SeqListPushBack(SL* ps, SLDateType x)
{
SeqListAddCapacity(ps);
ps->a[ps->size] = x;
ps->size++;
}顺序表数据的删除
顺序表的删除可以通过直接覆盖要删除的元素来实现删除,同样也分为三种删除方式,前删,指定位置删,尾删。前删就是把首元素后面的元素都往前走一步,把首元素覆盖掉,然后size--,就完成了删除,指定位置的删除和前删比较类似,都是后面的元素把要删除的元素覆盖掉,尾删就是比较简单的,只需要将size--,就表示该元素已经删掉了
三种删除方式的代码实现
//前删
void SeqListPopFront(SL* ps)
{
for (int i = 0; i < ps->size; i++)
{
ps->a[i] = ps->a[i + 1];
}
if (ps->size > 0)
{
ps->size--;
}
}
//任意位置删除
void SeqListPop(SL* ps, SLDateType x)
{
for (int i = x; i < ps->size; i++)
{
ps->a[i-1] = ps->a[i];
}
ps->size--;
}
//尾删
void SeqListPopBack(SL* ps)
{
if (ps->size > 0) //这里防止空表要删除会使size变为负数
{
ps->size--;
}
}顺序表的查改
顺序表的查看是比较简单的,通过size控制循环,对比要查看的元素是否存在
代码实现
void SeqListCheck(SL* ps, SLDateType x)
{
for (int i = 0; i < ps->size; i++)
{
if (ps->a[i] == x)
{
putchar('\n');
printf("got it, the subscript is %d", i);
return 0;
}
}
printf("not found\n");
}
//通过这个查看和修改都能实现单向链表
单向链表的存储形式
单向链表可以解决顺序表存在的一些问题,我们分析一下刚才顺序表存在的一些问题
1.头部\任意位置插入删除数据时,时间复杂度是O(n)
2.增容需要申请新的空间, 拷贝数据,释放旧空间,会有不小的消耗
3.每次增容扩展地空间会造成很大地浪费
单向链表分为很多种,循环的,有指向头和尾的两个指针的等等,这里只叙述最为经典和基础的单向链表,基础的掌握,其他的看看就了解了
单链表的存储形式通常包含要存的数据类型DataType,指向下一个节点的指针变量Linck*next
struct ListNode
{
DataStyle val;
struct ListNode* next;
}Linck;
单向链表数据的插入
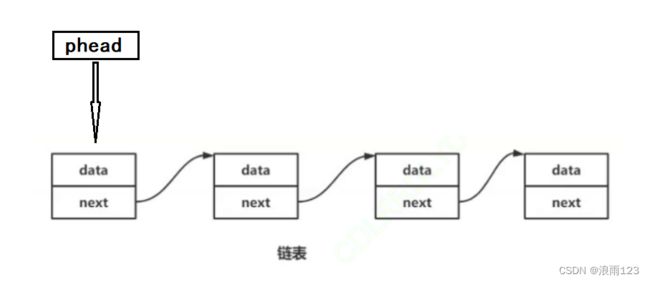
在使用单向链表时,我们需要一个指针变量始终指向链表的第一个节点,这个指针用来维护这串链表,通过解引用这个指针能找到链表的第一个节点,然后就能找到其他节点,数据的插入同样有三种形式,头插,指定位置插入,尾插。
尾插是最为简便的,只需要将链表最后节点指向下一个节点的指针指向新创建的节点,简单归简单但是想要找到最后一个节点的位置是不轻松的,链表的存储形式在内存地址上是不连续的,无法做到数组那样任意访问,可不是得从头节点开始,遍历一遍链表,这样时间复杂度就上来了。
头插较为麻烦,主要是因为头插一个新元素,就要挪动指向头节点的指针phead,而要改变指针变量phead的值,那就得靠传二级指针来实现,比如变量 int a; 想要在另一个函数里改变a的值,那就要传a的指针过去,同理,想要改变指针变量指向的地址,那就得用二级指针才能达到修改的目的,很多初学者可能会在这里犯迷糊,二级指针可能会有点绕,在以后的文章里,我将列举三个可以回避使用二级指针的方法
指定位置插入需要考虑的情况比较多,因为头插和尾插也可是指定位置,要同时兼顾这两种情况,在中间某个位置前插入,就需要记住该位置的前一个节点的next指针的值,其实是一个很简单的过程,但要叙述起来就比较难理解,简单来说就是为了保持链表的连贯,不能直接将前一个节点的next指针指向新节点就完事了,还要将新节点的next指针将后面的链表连贯起来
代码实现
//创建一个新节点的函数实现,后面创建直接调用
struct ListNode* Buynewnode(DataStyle Data)
{
struct ListNode* newnode = (struct ListNode*)malloc(sizeof(struct ListNode));
if (NULL == newnode)
{
printf("malloc fail\n");
return NULL;
}
newnode->val = Data;
newnode->next = NULL;
return newnode;
}
//头插的实现,注意,这里传二级指针是为了改变phead的值
void Linckpushfront(struct ListNode** pphead, DataStyle Data)
{
assert(pphead);
struct ListNode* newnode = Buynewnode(Data);
newnode->next = *pphead;
*pphead = newnode;
}
//尾插的实现
void Linckpushback(struct ListNode** pphead, DataStyle Data)
{
assert(pphead);
struct ListNode* tmp = *pphead;
if (*pphead == NULL)
{
tmp = Buynewnode(Data);
*pphead = tmp;
}
else
{
while (tmp->next != NULL)
{
tmp = tmp->next;
}
tmp->next = Buynewnode(Data);
}
}
//指定位置插入的实现
//pos是指定节点的指针
void LinckpushInsert(Linck** pphead, Linck * pos, DataStyle Data)
{
assert(pphead);
assert(*pphead);
assert(pos);
Linck* tmp = *pphead;
while (tmp->next != pos)
{
tmp = tmp->next;
}
Linck* newnode = Buynewnode(Data);
if ((*pphead)->next == NULL)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
tmp->next = newnode;
newnode->next = pos;
}
}单向链表数据的删除
单向链表的数据删除同样也分为头删,尾删,指定位置删,道理大家都懂,不过多重复,接下来直接上代码
//头删
void Linckpopfront(Linck** pphead)
{
if (*pphead == NULL)
{
assert(*pphead != NULL);
}
Linck* tmp = *pphead;
*pphead = (*pphead)->next;
free(tmp);
}
//尾删
void Linckpopback(Linck** pphead)
{
assert(pphead);
assert(*pphead != NULL);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
return;
}
Linck* tmp = *pphead;
while (tmp->next->next != NULL)
{
tmp = tmp->next;
}
free(tmp->next);
tmp->next = NULL;
}
//指定位置删
void LinckpopErase(Linck** pphead, Linck* pos)
{
assert(pphead);
assert(*pphead);
Linck* tmp = *pphead;
if (*pphead == pos)
{
Linckpopfront(pphead);
}
else
{
while (tmp->next != pos)
{
tmp = tmp->next;
assert(pos);//检测pos是否传错了
}
tmp->next = pos->next;
free(pos);
}
}双向链表
双向链表的存储形式
我们在引入单向链表时,很好的解决了顺序表的占用空间浪费,头插/指定位置插入数据效率低的问题,但这又带来了一个新的问题,单向链表在尾插数据时,要遍历一遍链表,时间复杂度是O(n),而带头双向循环链表的出现就更好的解决了顺序表的问题,且没造成其他问题。带头双向循环链表是链表结构中最复杂的,但易于理解和使用,带头指的是下图中的哨兵卫节点head,这个节点不存储数据,只作为引导头使用
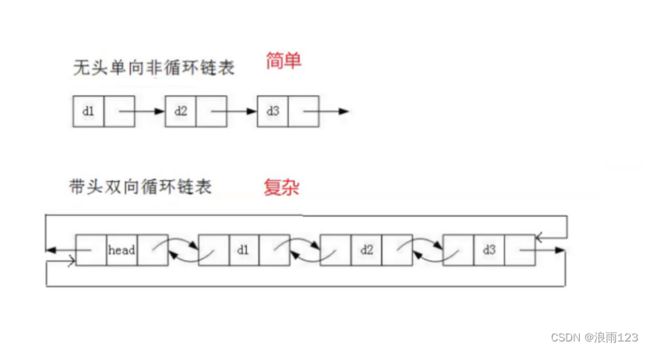
为何说带头双向循环链表能很好的解决问题,拿单向链表尾插遍历来说,带头双向循环链表就不存在这种问题,头节点head不存放任何数据,但指向了尾节点的位置,也就是说想要尾插可直接通过head找到尾节点完成插入,不需要遍历了,效率就提高了,但因为每个节点存了前后两个节点的指针,消耗的空间更多,也就是拿空间换取时间
typedef int DLinckDataType;
typedef struct DLincked
{
struct DLincked* previous; //指向前一个节点
struct DLincked* next; //指向后一个节点
DLinckDataType Data; //存放数据
} DLinck; 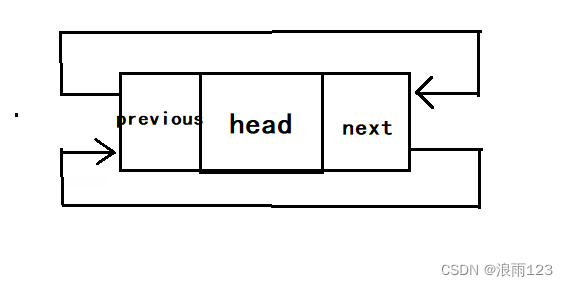
上面代码是带头双向循环链表节点的定义
上图带头双向循环链表为空时,前后指针都分别指向自己
带头双向循环链表数据的插入和删除
带头双向循环链表的插入和删除,本质上和单向链表的思想是一样的,这里不过多赘述,直接上代码吧
//创建新节点
DLinck* Buynewnode(DLinckDataType Data)
{
DLinck* newnode = (DLinck*)malloc(sizeof(DLinck));
if (newnode == NULL)
{
assert(newnode);
return -1;
}
newnode->previous = NULL;
newnode->next = NULL;
newnode->Data = Data;
return newnode;
}
//尾插
void DLinckpushback(DLinck* phead, DLinckDataType Data)
{
DLinck* newnode = Buynewnode(Data);
newnode->previous = phead->previous;
phead->previous->next = newnode;
phead->previous = newnode;
newnode->next = phead;
}
//首插
void DLinckpushfront(DLinck* phead, DLinckDataType Data)
{
DLinck* newnode = Buynewnode(Data);
newnode->next = phead->next;
newnode->previous = phead;
phead->next->previous = newnode;
phead->next = newnode;
}
//指定位置插
void DLinckpush(DLinck* phead, DLinck* pos, DLinckDataType Data)
{
assert(pos);
DLinck* newnode = Buynewnode(Data);
newnode->next = pos;
newnode->previous = pos->previous;
pos->previous->next = newnode;
pos->previous = newnode;
}
//指定位置删
void DLinckpop(DLinck* phead, DLinck* pos)
{
assert(phead->next != phead);
assert(pos);
DLinck* posprevious = pos->previous;
DLinck* posnext = pos->next;
posprevious->next = pos->next;
posnext->previous = pos->previous;
free(pos);
}
//头删
void DLinckpopfront(DLinck* phead)
{
assert(phead->next != phead);
DLinck* tmp = phead->next;
phead->next = tmp->next;
tmp->next->previous = phead;
free(tmp);
}
//尾删
void DLinckpopback(DLinck* phead)
{
assert(phead->next != phead );
DLinck* tmp = phead->previous;
phead->previous = tmp->previous;
tmp->previous->next = phead;
free(tmp);
}顺序表与链表的区别
顺序表与链表的优缺点

顺序表的优点:
1.尾插尾删效率高
2.靠数组随机访问
3.cpu高速缓存命中率更高(相比于链表)
缺点:
头部和中间的插入效率低
空间浪费情况较为严重
链表的优点:
1.指定位置插入数据效率高
2.按需申请内存
3.能解决顺序表的一些问题
缺点:
不支持随机访问
何为cpu高速缓存命中率
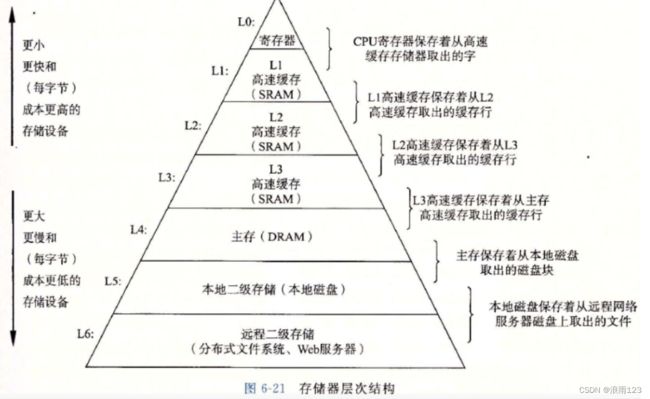
接下来的内容要参考上面这张图
CPU处理速度与内存不是一个量级的,CPU执行指令,不会直接访问内存,而是先看数据在不在L1,L2,L3高速缓存里,如果在的话(即命中),那就直接访问,如果不在的话(即未命中),那就将内存中的数据加载到高速缓存里,然后再访问
为了提高访问效率,内存加载信息到高速缓存中时,并不是一个一个加载的,而是会多加载其周边的一些数据,加载多少取决于硬件,数组的数据存储是连续的,如果加载的数据是数组,那么会将数组周边的元素都加载进去,这样再访问数组里其他数据时,直接就能在高速缓存里找到,命中率很高。
而链表呢,每个节点在内存中的存放地址是随机的,基本不会是连续的,这就导致访问链表某个节点时,从内存加载到高速缓存,其多加载的周边数据并不会包含该链表的其他节点,再想访问链表其他元素时就要从内存中重新导入到高速缓存,命中率明显没有顺序表的高