java中LinkedList的实现
上一篇博客用java代码简单实现了ArrayList,现在我将实现LinkedList,有什么不妥之处,请留言相互探讨一下。
LinkedList的实现我会迭代几个版本,因为不像ArrayList的实现主要是在数组这个轮子上操作即可以实现,而LinkedList没有轮子,只能自己慢慢创造,而且LinkedList是双向链表,所以在实现过程中经过不断调试并优化了几个版本的MyLinkedList。
惯例,首先还是介绍一下LinkedList的概念以及特点(对比ArrayList)还有我实现的一些思路。
概念:链表是一个由节点构成的列表,每个包含信息和指向另一个节点。可以创建一个链表,使用递归搜索,排序和删除。
特点与区别:linkedlist的特点是在找到需要插入或者删除的节点的情况下,插入,删除所花的代价非常小,在这方面形成鲜明对比的就是arraylist,arraylist插入和删除在极好的情况是在末位插入或者删除所花代价极小 ,但是如果在及其恶劣的位置-首位插入或删除,代价极大。Linkedlist不论在哪里插入或者删除效果都非常好。
但是对于get操作,linkedlist的查找效率非常低,因为linkedlist需要根据节点一个一个查找(针对双向链表,必须从开始节点或结束节点一次查询),但是arraylist是基于数组完成的,且全部放在内存连续的内存区域,所以查找非常快,但是linkedlist在内存中地址不是连续的,只能一个一个去索引。
我的实现思路如下:
作为一个linkedlist,必须要有增删改查的功能还有表的长度
必须声明一个节点类,这个类不能被外部访问,所以应该是私有的内部类,然后考虑node节点类因为没必要访问linkedlist的成员,所以设计位静态的。
linkedlist实现Iterable接口,用于返回能遍历数据的iterator,所以在内部我实现了Iterator接口。
下面是linkedlist的代码部分,对某些部分重要的代码给些分析:
package swu.comput;
import java.util.Iterator;
/**
* 实现一个简单的LinkedList
*
* @author shen-pc
*
* @param
*/
public class MyLinkedList implements Iterable {
// 记录链表的长度
private int mSize = 0;
// private int mActionCount = 0;
// 开始和结束节点
private Node mBeginNode, mLastNode;
public MyLinkedList() {
// TODO Auto-generated constructor stub
init();
}
/**
* 初始化一个只有开始节点和结束节点的空链表
*/
private void init() {
// 将首位节点链接起来
mBeginNode = new Node(null, null, null);
mLastNode = new Node(null, mBeginNode, null);
mBeginNode.nextNode = mLastNode;
mSize = 0;
// mActionCount++;
}
public int size() {
return mSize;
}
public boolean isEmpty() {
return mSize == 0 ? true : false;
}
/**
* 在链表的pos位置之前放置t_node这个节点
*
* @param t_node
* 需要放置的节点
* @param pos
* 放置节点在pos之前
*/
private void add(Node newNode, int pos) {
// 抛出不合法的位置
if (pos < 0 || pos > mSize) {
throw new IndexOutOfBoundsException();
}
// else if (pos == mSize) {
// t_node.preNode = mLastNode.preNode;
// t_node.nextNode = mLastNode;
// mLastNode.preNode.nextNode = t_node;
// mLastNode.preNode = t_node;
// } else if (pos == 0) {
// t_node.preNode = mBeginNode;
// t_node.nextNode = mBeginNode.nextNode;
// mBeginNode.nextNode = t_node;
// mBeginNode.nextNode.preNode = t_node;
// } else
// 链接新节点
newNode.preNode = getNode(pos - 1);
newNode.nextNode = getNode(pos);
getNode(pos - 1).nextNode = newNode;
getNode(pos).preNode = newNode;
// mActionCount++;
mSize++;
// Node node = mBeginNode;
// if (mSize == 4) {
// for (int i = 0; i < mSize; i++) {
// System.out.println((node = node.nextNode).t);
// }
// }
}
/**
* t 供外部调用,直接在链表的末尾添加,即在mLastNode节点之前
*
* @param
*/
public void add(T t) {
add(new Node(t, null, null), mSize);
}
/**
* 往链表pos位置之前添加数据t
*
* @param t
* 添加的数据
* @param pos
* 添加在pos位置之前
*/
public void add(T t, int pos) {
add(new Node(t, null, null), pos);
}
/**
*
* @param pos
* 链表中的某个位置
* @return 翻去pos位置的节点 (此处的pos的范围是[-1,mSize],此方法是私有方法,外部访问不了,只共此类中呢个访问)
*/
private Node getNode(int pos) {
Node node;
int currentPos;
if (pos == -1) {
// -1的位置是开始节点
return mBeginNode;
} else if (pos == mSize) {
// mSize的位置是结束的节点
return mLastNode;
}
// 因为这是双向节点,所以判断一下能提高搜索效率
if (pos < mSize / 2) {
currentPos = 0;
node = mBeginNode.nextNode;
while (currentPos < pos) {
node = node.nextNode;
currentPos++;
}
} else {
node = mLastNode.preNode;
currentPos = mSize - 1;
while (currentPos > pos) {
node = node.preNode;
currentPos--;
}
}
return node;
}
public T get(int pos) {
return getNode(pos).t;
}
public void set(T t, int pos) {
if (pos < 0 || pos >= mSize) {
throw new IndexOutOfBoundsException();
}
getNode(pos).t = t;
}
/**
* 删除特定位置的节点
*
* @param t_node
* 需要删除节点的位置
* @return
*/
private T remove(Node t_node) {
// 这是第一个节点
// if (t_node.preNode == mBeginNode) {
// getNode(1).preNode = mBeginNode;
// mBeginNode.nextNode = getNode(1);
// }
// 这是最后一个节点
// else if (t_node.nextNode == mLastNode) {
// getNode(mSize - 2).nextNode = mLastNode;
// mLastNode.preNode = getNode(mSize - 2);
// } else
t_node.preNode.nextNode = t_node.nextNode;
t_node.nextNode.preNode = t_node.preNode;
// 最好在此处给其设置为空,不要其链接到其他节点,因为已经被销毁,不再持有其他的节点的引用
t_node.nextNode = null;
t_node.preNode = null;
mSize--;
// mActionCount++;
return t_node.t;
}
public T remove(int pos) {
if (pos < 0 || pos >= mSize) {
throw new IndexOutOfBoundsException();
}
Node tempNode = getNode(pos);
remove(tempNode);
return tempNode.t;
}
@Override
public Iterator iterator() {
// TODO Auto-generated method stub
return new MyLinkedListIterator();
}
private class MyLinkedListIterator implements Iterator {
private int currentPos = 0;
@Override
public boolean hasNext() {
// TODO Auto-generated method stub
if (currentPos < mSize) {
return true;
}
return false;
}
@Override
public T next() {
// TODO Auto-generated method stub
return (T) getNode(currentPos++).t;
}
@Override
public void remove() {
// TODO Auto-generated method stub
MyLinkedList.this.remove(getNode(--currentPos));
;
}
}
// 静态内部类,定义的节点,双向链表,需要一个指向前面一项的引用域和一个指向后面一项的引用域,方便查找
private static class Node {
public T t;
public Node preNode;
public Node nextNode;
public Node(T t, Node preNode, Node nextNode) {
this.preNode = preNode;
this.nextNode = nextNode;
this.t = t;
}
}
}
对52行的add方法进行说明:
/**
* 在链表的pos位置之前放置t_node这个节点
*
* @param t_node
* 需要放置的节点
* @param pos
* 放置节点在pos之前
*/
private void add(Node newNode, int pos) {
// 抛出不合法的位置
if (pos < 0 || pos > mSize) {
throw new IndexOutOfBoundsException();
}
// 链接新节点
newNode.preNode = getNode(pos - 1);
newNode.nextNode = getNode(pos);
getNode(pos - 1).nextNode = newNode;
getNode(pos).preNode = newNode;
// mActionCount++;
mSize++;
}

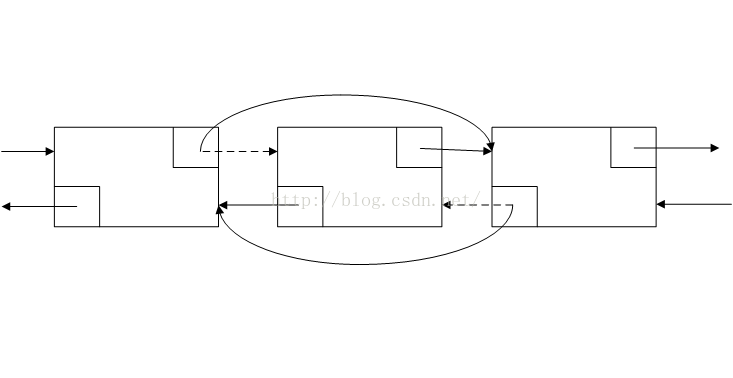
添加节点的示意图如上,虚线是以前链表链接情况,现在要添加一个新节点newNode,代码执行如上图的顺序执行,就可以把一个新节点添加到指定位置之前了。
下面对159行处的方法remove进行分析:
/**
* 删除特定位置的节点
*
* @param t_node
* 需要删除节点的位置
* @return
*/
private T remove(Node t_node) {
t_node.preNode.nextNode = t_node.nextNode;
t_node.nextNode.preNode = t_node.preNode;
// 最好在此处给其设置为空,不要其链接到其他节点,因为已经被销毁,不再持有其他的节点的引用
t_node.nextNode = null;
t_node.preNode = null;
mSize--;
// mActionCount++;
return t_node.t;
} 
中间的节点即是要被删除的节点,删除流程请结合代码。
上面的代码似乎已经实现了LinkedList,但是如果我们在获得了这个iterator对这个链表遍历的时候,如果我们对它又进行了一些删除或者添加的操作,会发生什么异常情况呢?
所以基于此,我们要对linkedlist加上一个mActionCount域来解决这个情况,一旦有添加或者删除或者初始化的操作就对他加上一,然后获取Iterator的时候把这个变量传过去,如果我们在遍历的时候又有些改变的操作,那么mActionCount有变化,拿变化后的mActionCount和以前传到Iterator的mActionCount值一比较,只要不等,就表示这个Iterator可能就无效了。
所以我要在add和remove方法中对这个变量mActionCount+1
然后我自己实现的iterator类的代码如下:
private class MyLinkedListIterator implements Iterator {
private int currentPos = 0;
private int nowActionCount = mActionCount;
@Override
public boolean hasNext() {
// TODO Auto-generated method stub
if (currentPos < mSize) {
return true;
}
return false;
}
@Override
public T next() {
// TODO Auto-generated method stub
if (nowActionCount !=mActionCount) {
throw new ConcurrentModificationException();
}
return (T) getNode(currentPos++).t;
}
@Override
public void remove() {
// TODO Auto-generated method stub
MyLinkedList.this.remove(getNode(--currentPos));
;
}
}
自此,我的linkedlist就分析完毕。