大模型相关概念
什么是大模型?
通常至少具备两个要素:
1.跨任务的通用性;
2.跨领域的通用性;
大模型的强大之处,正是来自于这种令人惊喜的通用性,统一了诸多任务的形式并具有强大的泛化能力,可以处理多个不同领域的问题。而训练数据、参数规模、计算量的“大”是大模型的一个必要而不充分条件,是为了涌现出强大通用能力所必要的Scaling Up。
行业大模型?
若是基于以上对大模型的认识,我们可以理解为什么行业大模型会受到人们的质疑。
因为,使用垂直领域数据所训练出来的行业大模型,大都在某种程度上牺牲了其在诸多领域上的通用性,换来在特定领域上的优异效果,也就不再符合大模型的定义了。
所以,行业大模型,更准确的说法或许是通用大模型在垂直领域的应用,也就是在通用大模型的基础上基于行业数据进行训练、微调,用于解决行业问题,从概念上讲已经一定程度不再属于大模型。
通过这种新的定义角度来看,就可以更好地理解行业大模型究竟是什么。
为了保持行文的一致性,以下继续采用行业大模型的称呼。
1.向量召回
向量召回(Vector Retrieval)是一种信息检索技术,通常应用于大规模文本或内容检索系统,以快速有效地检索相关的文档或内容。它基于向量空间模型(Vector Space Model)和相似性度量来实现检索,其中文档和查询都被表示为向量,并通过计算它们之间的相似度来找到最相关的文档。
以下是一个示例来说明向量召回的工作方式:
示例:新闻文章检索
假设你正在构建一个新闻文章检索系统,用户可以输入一个关键词或查询,系统将返回最相关的新闻文章。这是向量召回如何应用的一个例子:
建立文档向量:
首先,需要为每篇新闻文章构建一个文档向量。这可以通过将文章中的关键词或短语映射到一个高维向量空间中的位置来完成。这些向量通常被称为文档向量。
建立查询向量:
当用户输入一个查询时,该查询也被映射为一个向量,通常称为查询向量。这个查询向量包含了查询中的关键词或短语在向量空间中的位置。
计算相似度:
接下来,系统会计算查询向量与每个文档向量之间的相似度。常见的相似度度量包括余弦相似度(Cosine Similarity)。
召回:
系统会按相似度的降序排列文档向量,然后返回与查询向量相似度最高的文档,通常是前几篇。这些文档就是向量召回的结果。
例如,如果用户在搜索框中输入了查询 “技术新闻”,系统会将这个查询映射为一个查询向量,然后与存储在系统中的所有新闻文章的文档向量计算相似度。系统将返回与查询向量相似度最高的新闻文章,这些文章通常包括了与技术相关的新闻。
向量召回是一种高效的检索方法,尤其适用于处理大规模的文本或内容检索任务。它能够快速找到与查询相关的文档,以满足用户信息检索的需求。
2.什么是奖励模型
奖励模型:
奖励模型是强化学习中的一个关键概念。它代表了一个问题的目标或任务。在强化学习中,一个代理(agent)尝试通过与环境互动来学习最佳的行为策略。这个学习的过程是通过最大化获得的累积奖励来实现的。奖励模型定义了环境对代理行为的评估方式,给出了代理在不同状态下采取不同动作的反馈信号。奖励通常是一个数值,代理的目标是找到一种策略,最大化长期累积奖励。
假设我们正在考虑一个经典的强化学习问题:训练一个智能代理来玩一个迷宫游戏。在这个游戏中,代理会从起始位置开始,然后根据它的行动选择来移动,直到到达目标位置或者走入陷阱。
在这个例子中,奖励模型将是一个定义了在每个状态下采取不同行动的奖励信号。
起始状态:
奖励模型会为起始状态(比如迷宫的初始位置)分配一个初始奖励值,通常为0。
目标状态:
当代理到达目标位置时,奖励模型会给予一个正奖励,比如+10分,表示代理成功完成了任务。
陷阱:
如果代理走入了陷阱,奖励模型会给予一个负奖励,比如-5分,表示代理走入了一个不好的状态。
中间状态:
对于中间的状态,奖励模型会根据当前状态和采取的行动来分配奖励。例如,如果代理选择了向前移动,并且没有走入陷阱,奖励模型可能会给予一个小正奖励,比如+1分,以鼓励代理朝着目标前进。
奖励模型的目的是引导代理在每个状态下采取最佳行动,以最大化长期累积奖励。代理的目标是通过学习一个策略来选择动作,以使得在每个状态下的期望累积奖励最大化。
这只是一个简单的例子,实际上,奖励模型可能会更加复杂,包括连续的状态空间、大量的行动选择等等。不过,这个例子可以帮助你理解奖励模型是如何在强化学习中起作用的。
3.预训练和微调
深度学习中常用的两个阶段,用于训练神经网络模型,特别是在自然语言处理领域中非常流行。这两个阶段通常结合使用,以获得更好的模型性能。
预训练(Pretraining):
预训练是指在大规模的数据集上,使用一个深度神经网络模型(通常是一个较大的模型)进行初始训练。这个初始训练的目标通常是学习到数据的通用表示。在自然语言处理中,这意味着模型学习了大量文本数据的语言知识,包括词汇、语法、语义等。
在计算机视觉中,预训练可以包括对大量图像数据的特征学习。
预训练的模型通常是一个自编码器或一个Transformer架构,其中最著名的包括BERT、GPT(Generative Pre-trained Transformer)、ResNet等。这些模型在预训练阶段,通常使用大规模的无标签数据,如维基百科、互联网文本或图像,来学习通用的特征表示。
微调(Fine-tuning):
微调是在预训练模型的基础上,使用特定任务的有标签数据进行进一步训练的过程。在微调阶段,模型的权重被调整以适应特定任务,如文本分类、命名实体识别、图像分类等。微调的目标是将模型的通用知识与特定任务的知识结合起来,从而提高模型在该任务上的性能。
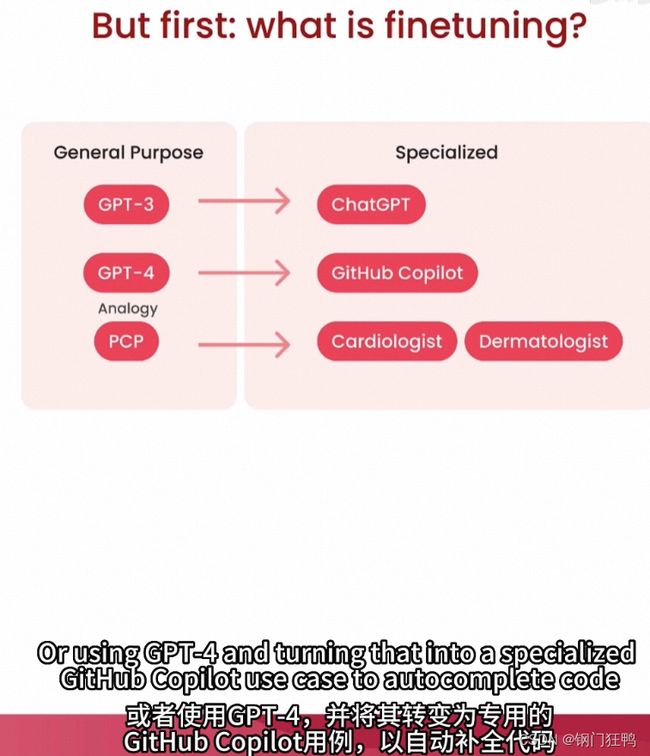
预训练和微调区别?1、费用差距巨大。2、时间成本差异巨大。
推理
在机器学习中,模型的推理是指在训练完成后,将输入数据输入到模型中,以生成预测结果或执行特定任务。
NL TO SQL
将自然语言(NL)转换为SQL(Structured Query Language)是一项自然语言处理(NLP)任务,其中系统尝试从用户提供的自然语言问题或指令中生成相应的数据库查询语句。这个任务通常涉及到文本理解、语法分析、语义理解和数据库查询生成。
以下是一个简单的示例,将一个自然语言问题转化为SQL查询:
自然语言问题: “找出所有年龄小于30岁的学生的名字和课程名称。”
对应的SQL查询:
sql
SELECT Students.name, Courses.name
FROM Students
JOIN Enrollments ON Students.student_id = Enrollments.student_id
JOIN Courses ON Enrollments.course_id = Courses.course_id
WHERE Students.age < 30;
这个SQL查询使用了SQL语法来从数据库中检索所需的信息。它涉及到了以下几个步骤:
SELECT Students.name, Courses.name:这是选择要返回的列的部分,它要求返回学生的名字和他们所选课程的名称。
FROM Students:这是指定要从哪个表中检索数据,即"Students"表。
JOIN:这是连接不同表的方式,它连接了"Students"表、"Enrollments"表和"Courses"表。
ON:这是指定连接条件的部分,它告诉数据库如何将这些表连接在一起,通常基于共享的键(在这种情况下是学生ID和课程ID)。
WHERE Students.age < 30:这是一个筛选条件,它限制了只返回年龄小于30岁的学生的信息。
需要注意的是,NL to SQL任务是一个复杂的自然语言处理任务,需要强大的自然语言理解和数据库查询生成技术。实际的系统可能会涉及更复杂的查询,多表连接,聚合函数等。通常,这种任务需要训练大规模的模型来实现。
参考:https://developer.aliyun.com/article/1353018